 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-OrIU: Towards Better Forgetting via Feature-Gradient Orthogonality for Incremental Unlearning
Jan 20, 2026Incremental unlearning (IU) is critical for pre-trained models to comply with sequential data deletion requests, yet existing methods primarily suppress parameters or confuse knowledge without explicit constraints on both feature and gradient level, resulting in \textit{superficial forgetting} where residual information remains recoverable. This incomplete forgetting risks security breaches and disrupts retention balance, especially in IU scenarios. We propose FG-OrIU (\textbf{F}eature-\textbf{G}radient \textbf{Or}thogonality for \textbf{I}ncremental \textbf{U}nlearning), the first framework unifying orthogonal constraints on both features and gradients level to achieve deep forgetting, where the forgetting effect is irreversible. FG-OrIU decomposes feature spaces via Singular Value Decomposition (SVD), separating forgetting and remaining class features into distinct subspaces. It then enforces dual constraints: feature orthogonal projection on both forgetting and remaining classes, while gradient orthogonal projection prevents the reintroduction of forgotten knowledge and disruption to remaining classes during updates. Additionally, dynamic subspace adaptation merges newly forgetting subspaces and contracts remaining subspaces, ensuring a stable balance between removal and retention across sequential unlearning tasks. Extensive experiments demonstrate the effectiveness of our method.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025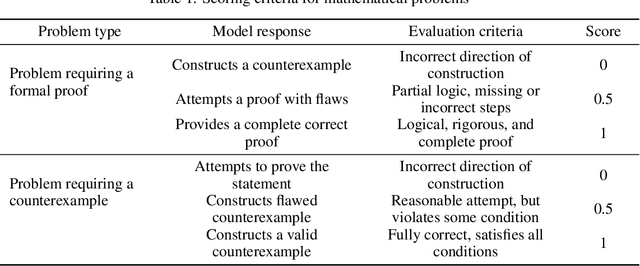
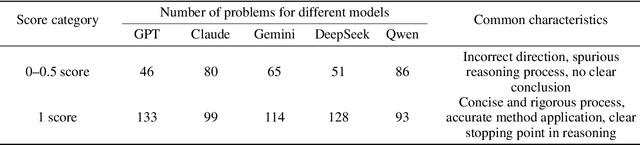
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
LensDFF: Language-enhanced Sparse Feature Distillation for Efficient Few-Shot Dexterous Manipulation
Mar 05, 2025Learning dexterous manipulation from few-shot demonstrations is a significant yet challenging problem for advanced, human-like robotic systems. Dense distilled feature fields have addressed this challenge by distilling rich semantic features from 2D visual foundation models into the 3D domain. However, their reliance on neural rendering models such as Neural Radiance Fields (NeRF) or Gaussian Splatting results in high computational costs. In contrast, previous approaches based on sparse feature fields either suffer from inefficiencies due to multi-view dependencies and extensive training or lack sufficient grasp dexterity. To overcome these limitations, we propose Language-ENhanced Sparse Distilled Feature Field (LensDFF), which efficiently distills view-consistent 2D features onto 3D points using our novel language-enhanced feature fusion strategy, thereby enabling single-view few-shot generalization. Based on LensDFF, we further introduce a few-shot dexterous manipulation framework that integrates grasp primitives into the demonstrations to generate stable and highly dexterous grasps. Moreover, we present a real2sim grasp evaluation pipeline for efficient grasp assessment and hyperparameter tuning. Through extensive simulation experiments based on the real2sim pipeline and real-world experiments, our approach achieves competitive grasping performance, outperforming state-of-the-art approaches.
CE-SDWV: Effective and Efficient Concept Erasure for Text-to-Image Diffusion Models via a Semantic-Driven Word Vocabulary
Jan 26, 2025



Large-scale text-to-image (T2I) diffusion models have achieved remarkable generative performance about various concepts. With the limitation of privacy and safety in practice, the generative capability concerning NSFW (Not Safe For Work) concepts is undesirable, e.g., producing sexually explicit photos, and licensed images. The concept erasure task for T2I diffusion models has attracted considerable attention and requires an effective and efficient method. To achieve this goal, we propose a CE-SDWV framework, which removes the target concepts (e.g., NSFW concepts) of T2I diffusion models in the text semantic space by only adjusting the text condition tokens and does not need to re-train the original T2I diffusion model's weights. Specifically, our framework first builds a target concept-related word vocabulary to enhance the representation of the target concepts within the text semantic space, and then utilizes an adaptive semantic component suppression strategy to ablate the target concept-related semantic information in the text condition tokens. To further adapt the above text condition tokens to the original image semantic space, we propose an end-to-end gradient-orthogonal token optimization strategy. Extensive experiments on I2P and UnlearnCanvas benchmarks demonstrate the effectiveness and efficiency of our method.
LW2G: Learning Whether to Grow for Prompt-based Continual Learning
Sep 27, 2024Continual Learning (CL) aims to learn in non-stationary scenarios, progressively acquiring and maintaining knowledge from sequential tasks. Recent Prompt-based Continual Learning (PCL) has achieved remarkable performance with Pre-Trained Models (PTMs). These approaches grow a prompt sets pool by adding a new set of prompts when learning each new task (\emph{prompt learning}) and adopt a matching mechanism to select the correct set for each testing sample (\emph{prompt retrieval}). Previous studies focus on the latter stage by improving the matching mechanism to enhance Prompt Retrieval Accuracy (PRA). To promote cross-task knowledge facilitation and form an effective and efficient prompt sets pool, we propose a plug-in module in the former stage to \textbf{Learn Whether to Grow (LW2G)} based on the disparities between tasks. Specifically, a shared set of prompts is utilized when several tasks share certain commonalities, and a new set is added when there are significant differences between the new task and previous tasks. Inspired by Gradient Projection Continual Learning, our LW2G develops a metric called Hinder Forward Capability (HFC) to measure the hindrance imposed on learning new tasks by surgically modifying the original gradient onto the orthogonal complement of the old feature space. With HFC, an automated scheme Dynamic Growing Approach adaptively learns whether to grow with a dynamic threshold. Furthermore, we design a gradient-based constraint to ensure the consistency between the updating prompts and pre-trained knowledge, and a prompts weights reusing strategy to enhance forward transfer. Extensive experiments show the effectiveness of our method. The source codes are available at \url{https://github.com/RAIAN08/LW2G}.
DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
Jul 24, 2024We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.
FFHFlow: A Flow-based Variational Approach for Multi-fingered Grasp Synthesis in Real Time
Jul 21, 2024Synthesizing diverse and accurate grasps with multi-fingered hands is an important yet challenging task in robotics. Previous efforts focusing on generative modeling have fallen short of precisely capturing the multi-modal, high-dimensional grasp distribution. To address this, we propose exploiting a special kind of Deep Generative Model (DGM) based on Normalizing Flows (NFs), an expressive model for learning complex probability distributions. Specifically, we first observed an encouraging improvement in diversity by directly applying a single conditional NFs (cNFs), dubbed FFHFlow-cnf, to learn a grasp distribution conditioned on the incomplete point cloud. However, we also recognized limited performance gains due to restricted expressivity in the latent space. This motivated us to develop a novel flow-based d Deep Latent Variable Model (DLVM), namely FFHFlow-lvm, which facilitates more reasonable latent features, leading to both diverse and accurate grasp synthesis for unseen objects. Unlike Variational Autoencoders (VAEs), the proposed DLVM counteracts typical pitfalls such as mode collapse and mis-specified priors by leveraging two cNFs for the prior and likelihood distributions, which are usually restricted to being isotropic Gaussian. Comprehensive experiments in simulation and real-robot scenarios demonstrate that our method generates more accurate and diverse grasps than the VAE baselines. Additionally, a run-time comparison is conducted to reveal its high potential for real-time applications.
PECTP: Parameter-Efficient Cross-Task Prompts for Incremental Vision Transformer
Jul 04, 2024



Incremental Learning (IL) aims to learn deep models on sequential tasks continually, where each new task includes a batch of new classes and deep models have no access to task-ID information at the inference time. Recent vast pre-trained models (PTMs) have achieved outstanding performance by prompt technique in practical IL without the old samples (rehearsal-free) and with a memory constraint (memory-constrained): Prompt-extending and Prompt-fixed methods. However, prompt-extending methods need a large memory buffer to maintain an ever-expanding prompt pool and meet an extra challenging prompt selection problem. Prompt-fixed methods only learn a single set of prompts on one of the incremental tasks and can not handle all the incremental tasks effectively. To achieve a good balance between the memory cost and the performance on all the tasks, we propose a Parameter-Efficient Cross-Task Prompt (PECTP) framework with Prompt Retention Module (PRM) and classifier Head Retention Module (HRM). To make the final learned prompts effective on all incremental tasks, PRM constrains the evolution of cross-task prompts' parameters from Outer Prompt Granularity and Inner Prompt Granularity. Besides, we employ HRM to inherit old knowledge in the previously learned classifier heads to facilitate the cross-task prompts' generalization ability. Extensive experiments show the effectiveness of our method. The source codes will be available at \url{https://github.com/RAIAN08/PECTP}.
Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Jun 29, 2024Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
Evaluating Uncertainty-based Failure Detection for Closed-Loop LLM Planners
Jun 01, 2024Recently, Large Language Models (LLMs) have witnessed remarkable performance as zero-shot task planners for robotic manipulation tasks. However, the open-loop nature of previous works makes LLM-based planning error-prone and fragile. On the other hand, failure detection approaches for closed-loop planning are often limited by task-specific heuristics or following an unrealistic assumption that the prediction is trustworthy all the time. As a general-purpose reasoning machine, LLMs or Multimodal Large Language Models (MLLMs) are promising for detecting failures. However, However, the appropriateness of the aforementioned assumption diminishes due to the notorious hullucination problem. In this work, we attempt to mitigate these issues by introducing a framework for closed-loop LLM-based planning called KnowLoop, backed by an uncertainty-based MLLMs failure detector, which is agnostic to any used MLLMs or LLMs. Specifically, we evaluate three different ways for quantifying the uncertainty of MLLMs, namely token probability, entropy, and self-explained confidence as primary metrics based on three carefully designed representative prompting strategies. With a self-collected dataset including various manipulation tasks and an LLM-based robot system, our experiments demonstrate that token probability and entropy are more reflective compared to self-explained confidence. By setting an appropriate threshold to filter out uncertain predictions and seek human help actively, the accuracy of failure detection can be significantly enhanced. This improvement boosts the effectiveness of closed-loop planning and the overall success rate of tasks.