 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBihoT: A Large-Scale Dataset and Benchmark for Hyperspectral Camouflaged Object Tracking
Aug 22, 2024



Hyperspectral object tracking (HOT) has exhibited potential in various applications, particularly in scenes where objects are camouflaged. Existing trackers can effectively retrieve objects via band regrouping because of the bias in existing HOT datasets, where most objects tend to have distinguishing visual appearances rather than spectral characteristics. This bias allows the tracker to directly use the visual features obtained from the false-color images generated by hyperspectral images without the need to extract spectral features. To tackle this bias, we find that the tracker should focus on the spectral information when object appearance is unreliable. Thus, we provide a new task called hyperspectral camouflaged object tracking (HCOT) and meticulously construct a large-scale HCOT dataset, termed BihoT, which consists of 41,912 hyperspectral images covering 49 video sequences. The dataset covers various artificial camouflage scenes where objects have similar appearances, diverse spectrums, and frequent occlusion, making it a very challenging dataset for HCOT. Besides, a simple but effective baseline model, named spectral prompt-based distractor-aware network (SPDAN), is proposed, comprising a spectral embedding network (SEN), a spectral prompt-based backbone network (SPBN), and a distractor-aware module (DAM). Specifically, the SEN extracts spectral-spatial features via 3-D and 2-D convolutions. Then, the SPBN fine-tunes powerful RGB trackers with spectral prompts and alleviates the insufficiency of training samples. Moreover, the DAM utilizes a novel statistic to capture the distractor caused by occlusion from objects and background. Extensive experiments demonstrate that our proposed SPDAN achieves state-of-the-art performance on the proposed BihoT and other HOT datasets.
Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising
Mar 15, 2024



Hyperspectral image (HSI) denoising is critical for the effective analysis and interpretation of hyperspectral data. However, simultaneously modeling global and local features is rarely explored to enhance HSI denoising. In this letter, we propose a hybrid convolution and attention network (HCANet), which leverages both the strengths of convolution neural networks (CNNs) and Transformers. To enhance the modeling of both global and local features, we have devised a convolution and attention fusion module aimed at capturing long-range dependencies and neighborhood spectral correlations. Furthermore, to improve multi-scale information aggregation, we design a multi-scale feed-forward network to enhance denoising performance by extracting features at different scales. Experimental results on mainstream HSI datasets demonstrate the rationality and effectiveness of the proposed HCANet. The proposed model is effective in removing various types of complex noise. Our codes are available at \url{https://github.com/summitgao/HCANet}.
SSF-Net: Spatial-Spectral Fusion Network with Spectral Angle Awareness for Hyperspectral Object Tracking
Mar 09, 2024



Hyperspectral video (HSV) offers valuable spatial, spectral, and temporal information simultaneously, making it highly suitable for handling challenges such as background clutter and visual similarity in object tracking. However, existing methods primarily focus on band regrouping and rely on RGB trackers for feature extraction, resulting in limited exploration of spectral information and difficulties in achieving complementary representations of object features. In this paper, a spatial-spectral fusion network with spectral angle awareness (SST-Net) is proposed for hyperspectral (HS) object tracking. Firstly, to address the issue of insufficient spectral feature extraction in existing networks, a spatial-spectral feature backbone ($S^2$FB) is designed. With the spatial and spectral extraction branch, a joint representation of texture and spectrum is obtained. Secondly, a spectral attention fusion module (SAFM) is presented to capture the intra- and inter-modality correlation to obtain the fused features from the HS and RGB modalities. It can incorporate the visual information into the HS spectral context to form a robust representation. Thirdly, to ensure a more accurate response of the tracker to the object position, a spectral angle awareness module (SAAM) investigates the region-level spectral similarity between the template and search images during the prediction stage. Furthermore, we develop a novel spectral angle awareness loss (SAAL) to offer guidance for the SAAM based on similar regions. Finally, to obtain the robust tracking results, a weighted prediction method is considered to combine the HS and RGB predicted motions of objects to leverage the strengths of each modality. Extensive experiments on the HOTC dataset demonstrate the effectiveness of the proposed SSF-Net, compared with state-of-the-art trackers.
SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification
Nov 08, 2023



Masked image modeling (MIM) is a highly popular and effective self-supervised learning method for image understanding. Existing MIM-based methods mostly focus on spatial feature modeling, neglecting spectral feature modeling. Meanwhile, existing MIM-based methods use Transformer for feature extraction, some local or high-frequency information may get lost. To this end, we propose a spatial-spectral masked auto-encoder (SS-MAE) for HSI and LiDAR/SAR data joint classification. Specifically, SS-MAE consists of a spatial-wise branch and a spectral-wise branch. The spatial-wise branch masks random patches and reconstructs missing pixels, while the spectral-wise branch masks random spectral channels and reconstructs missing channels. Our SS-MAE fully exploits the spatial and spectral representations of the input data. Furthermore, to complement local features in the training stage, we add two lightweight CNNs for feature extraction. Both global and local features are taken into account for feature modeling. To demonstrate the effectiveness of the proposed SS-MAE, we conduct extensive experiments on three publicly available datasets. Extensive experiments on three multi-source datasets verify the superiority of our SS-MAE compared with several state-of-the-art baselines. The source codes are available at \url{https://github.com/summitgao/SS-MAE}.
Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection
Sep 21, 2023



Synthetic aperture radar (SAR) image change detection is a critical task and has received increasing attentions in the remote sensing community. However, existing SAR change detection methods are mainly based on convolutional neural networks (CNNs), with limited consideration of global attention mechanism. In this letter, we explore Transformer-like architecture for SAR change detection to incorporate global attention. To this end, we propose a convolution and attention mixer (CAMixer). First, to compensate the inductive bias for Transformer, we combine self-attention with shift convolution in a parallel way. The parallel design effectively captures the global semantic information via the self-attention and performs local feature extraction through shift convolution simultaneously. Second, we adopt a gating mechanism in the feed-forward network to enhance the non-linear feature transformation. The gating mechanism is formulated as the element-wise multiplication of two parallel linear layers. Important features can be highlighted, leading to high-quality representations against speckle noise. Extensive experiments conducted on three SAR datasets verify the superior performance of the proposed CAMixer. The source codes will be publicly available at https://github.com/summitgao/CAMixer .
Multi-scale Adaptive Fusion Network for Hyperspectral Image Denoising
Apr 19, 2023



Removing the noise and improving the visual quality of hyperspectral images (HSIs) is challenging in academia and industry. Great efforts have been made to leverage local, global or spectral context information for HSI denoising. However, existing methods still have limitations in feature interaction exploitation among multiple scales and rich spectral structure preservation. In view of this, we propose a novel solution to investigate the HSI denoising using a Multi-scale Adaptive Fusion Network (MAFNet), which can learn the complex nonlinear mapping between clean and noisy HSI. Two key components contribute to improving the hyperspectral image denoising: A progressively multiscale information aggregation network and a co-attention fusion module. Specifically, we first generate a set of multiscale images and feed them into a coarse-fusion network to exploit the contextual texture correlation. Thereafter, a fine fusion network is followed to exchange the information across the parallel multiscale subnetworks. Furthermore, we design a co-attention fusion module to adaptively emphasize informative features from different scales, and thereby enhance the discriminative learning capability for denoising. Extensive experiments on synthetic and real HSI datasets demonstrate that the proposed MAFNet has achieved better denoising performance than other state-of-the-art techniques. Our codes are available at \verb'https://github.com/summitgao/MAFNet'.
Physical Knowledge Enhanced Deep Neural Network for Sea Surface Temperature Prediction
Apr 19, 2023



Traditionally, numerical models have been deployed in oceanography studies to simulate ocean dynamics by representing physical equations. However, many factors pertaining to ocean dynamics seem to be ill-defined. We argue that transferring physical knowledge from observed data could further improve the accuracy of numerical models when predicting Sea Surface Temperature (SST). Recently, the advances in earth observation technologies have yielded a monumental growth of data. Consequently, it is imperative to explore ways in which to improve and supplement numerical models utilizing the ever-increasing amounts of historical observational data. To this end, we introduce a method for SST prediction that transfers physical knowledge from historical observations to numerical models. Specifically, we use a combination of an encoder and a generative adversarial network (GAN) to capture physical knowledge from the observed data. The numerical model data is then fed into the pre-trained model to generate physics-enhanced data, which can then be used for SST prediction. Experimental results demonstrate that the proposed method considerably enhances SST prediction performance when compared to several state-of-the-art baselines.
Nearest Neighbor-Based Contrastive Learning for Hyperspectral and LiDAR Data Classification
Jan 09, 2023The joint hyperspectral image (HSI) and LiDAR data classification aims to interpret ground objects at more detailed and precise level. Although deep learning methods have shown remarkable success in the multisource data classification task, self-supervised learning has rarely been explored. It is commonly nontrivial to build a robust self-supervised learning model for multisource data classification, due to the fact that the semantic similarities of neighborhood regions are not exploited in existing contrastive learning framework. Furthermore, the heterogeneous gap induced by the inconsistent distribution of multisource data impedes the classification performance. To overcome these disadvantages, we propose a Nearest Neighbor-based Contrastive Learning Network (NNCNet), which takes full advantage of large amounts of unlabeled data to learn discriminative feature representations. Specifically, we propose a nearest neighbor-based data augmentation scheme to use enhanced semantic relationships among nearby regions. The intermodal semantic alignments can be captured more accurately. In addition, we design a bilinear attention module to exploit the second-order and even high-order feature interactions between the HSI and LiDAR data. Extensive experiments on four public datasets demonstrate the superiority of our NNCNet over state-of-the-art methods. The source codes are available at \url{https://github.com/summitgao/NNCNet}.
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery
Sep 27, 2022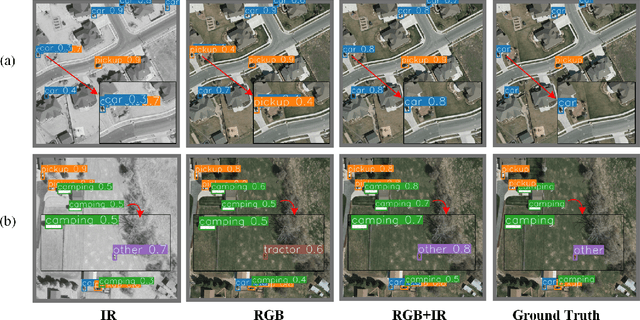
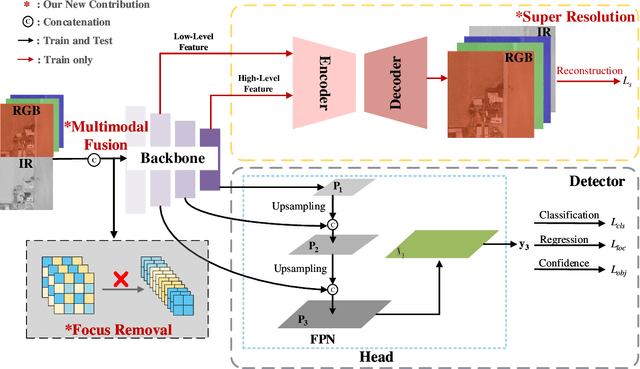
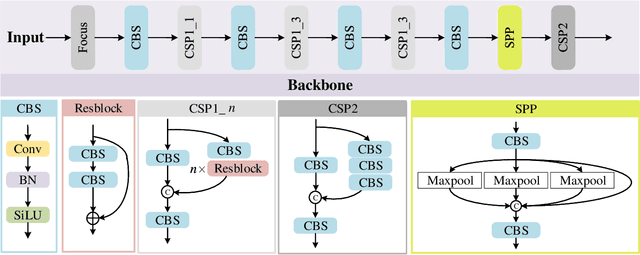
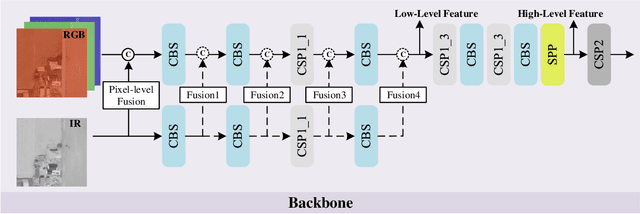
In this paper, we propose an accurate yet fast small object detection method for RSI, named SuperYOLO, which fuses multimodal data and performs high resolution (HR) object detection on multiscale objects by utilizing the assisted super resolution (SR) learning and considering both the detection accuracy and computation cost. First, we construct a compact baseline by removing the Focus module to keep the HR features and significantly overcomes the missing error of small objects. Second, we utilize pixel-level multimodal fusion (MF) to extract information from various data to facilitate more suitable and effective features for small objects in RSI. Furthermore, we design a simple and flexible SR branch to learn HR feature representations that can discriminate small objects from vast backgrounds with low-resolution (LR) input, thus further improving the detection accuracy. Moreover, to avoid introducing additional computation, the SR branch is discarded in the inference stage and the computation of the network model is reduced due to the LR input. Experimental results show that, on the widely used VEDAI RS dataset, SuperYOLO achieves an accuracy of 73.61% (in terms of mAP50), which is more than 10% higher than the SOTA large models such as YOLOv5l, YOLOv5x and RS designed YOLOrs. Meanwhile, the GFOLPs and parameter size of SuperYOLO are about 18.1x and 4.2x less than YOLOv5x. Our proposed model shows a favorable accuracy-speed trade-off compared to the state-of-art models. The code will be open sourced at https://github.com/icey-zhang/SuperYOLO.
Single-source Domain Expansion Network for Cross-Scene Hyperspectral Image Classification
Sep 04, 2022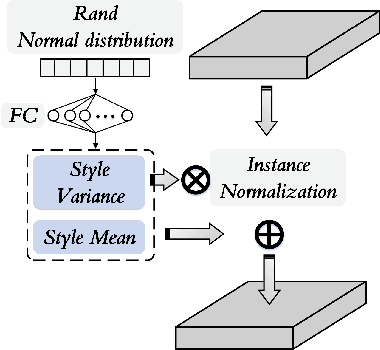
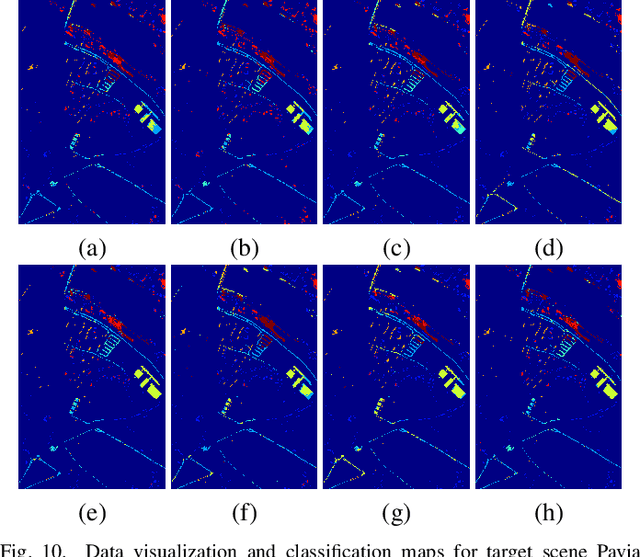
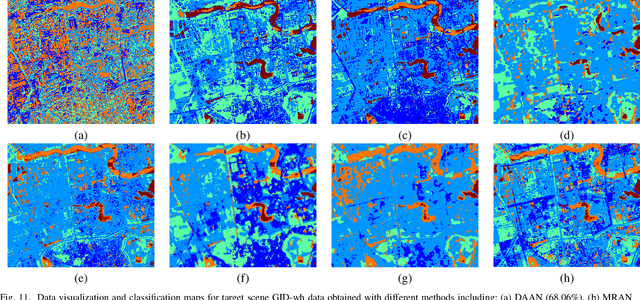
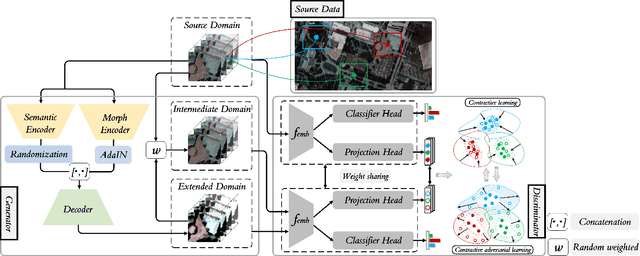
Currently, cross-scene hyperspectral image (HSI) classification has drawn increasing attention. It is necessary to train a model only on source domain (SD) and directly transferring the model to target domain (TD), when TD needs to be processed in real time and cannot be reused for training. Based on the idea of domain generalization, a Single-source Domain Expansion Network (SDEnet) is developed to ensure the reliability and effectiveness of domain extension. The method uses generative adversarial learning to train in SD and test in TD. A generator including semantic encoder and morph encoder is designed to generate the extended domain (ED) based on encoder-randomization-decoder architecture, where spatial and spectral randomization are specifically used to generate variable spatial and spectral information, and the morphological knowledge is implicitly applied as domain invariant information during domain expansion. Furthermore, the supervised contrastive learning is employed in the discriminator to learn class-wise domain invariant representation, which drives intra-class samples of SD and ED. Meanwhile, adversarial training is designed to optimize the generator to drive intra-class samples of SD and ED to be separated. Extensive experiments on two public HSI datasets and one additional multispectral image (MSI) dataset demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.