 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
Jun 02, 2026Existing benchmarks for MLLM-generated web artifacts assess interaction through local evidence and miss the requirement-induced states and transitions that determine whether a page works. We introduce WebRISE, which compiles task requirements into Interaction Contract Graphs (ICGs) of observable states, user-intent transitions, and DOM/visual assertions for implementation-agnostic browser execution. WebRISE spans 442 tasks across five input modalities (Text, Markdown, Sketch, Image, Video), with 5,495 transitions and 5,271 requirement checks that separate user-stated functions from implicit product-level constraints. Across 14 MLLMs, even the strongest model reaches only 65.6% transition validity and 66.3% requirement coverage, and visual quality is no proxy for behavior (Qwen3.6-35B-A3B on Markdown: V=80.8 yet T=15.5). Video gives the strongest interaction signal (+10.6 pp implicit coverage over Text), while implicit constraints persist; defect injection shows ICG-based scoring detects state errors at 2-16x the rate of checkpoint-style evaluation.
Video-Zero: Self-Evolution Video Understanding
May 14, 2026Self-evolution offers a promising path for improving reasoning models without relying on intensive human annotation. However, extending this paradigm to video understanding remains underexplored and challenging: videos are long, dynamic, and redundant, while the evidence needed for reasoning is often sparse and temporally localized. Naively generating difficult question-answer pairs from full videos can therefore produce supervision that appears challenging but is weakly grounded, relying on static cues or language priors rather than temporal evidence. In this work, we argue that the key bottleneck of video self-evolution is not difficulty alone, but grounding. We propose Video-Zero, an annotation-free Questioner--Solver co-evolution framework that centers self-evolution on temporally localized evidence. The Questioner discovers informative evidence segments and generates evidence-grounded questions, while the Solver learns to answer and align its predictions with the supporting evidence. This closes an iterative loop of evidence discovery, grounded supervision, and evidence-aligned learning. Across 13 benchmarks spanning temporal grounding, long-video understanding, and video reasoning, Video-Zero consistently improves multiple video VLM backbones, demonstrating the effectiveness and transferability of evidence-centered self-evolution.
A Survey of Reasoning in Autonomous Driving Systems: Open Challenges and Emerging Paradigms
Mar 11, 2026The development of high-level autonomous driving (AD) is shifting from perception-centric limitations to a more fundamental bottleneck, namely, a deficit in robust and generalizable reasoning. Although current AD systems manage structured environments, they consistently falter in long-tail scenarios and complex social interactions that require human-like judgment. Meanwhile, the advent of large language and multimodal models (LLMs and MLLMs) presents a transformative opportunity to integrate a powerful cognitive engine into AD systems, moving beyond pattern matching toward genuine comprehension. However, a systematic framework to guide this integration is critically lacking. To bridge this gap, we provide a comprehensive review of this emerging field and argue that reasoning should be elevated from a modular component to the system's cognitive core. Specifically, we first propose a novel Cognitive Hierarchy to decompose the monolithic driving task according to its cognitive and interactive complexity. Building on this, we further derive and systematize seven core reasoning challenges, such as the responsiveness-reasoning trade-off and social-game reasoning. Furthermore, we conduct a dual-perspective review of the state-of-the-art, analyzing both system-centric approaches to architecting intelligent agents and evaluation-centric practices for their validation. Our analysis reveals a clear trend toward holistic and interpretable "glass-box" agents. In conclusion, we identify a fundamental and unresolved tension between the high-latency, deliberative nature of LLM-based reasoning and the millisecond-scale, safety-critical demands of vehicle control. For future work, a primary objective is to bridge the symbolic-to-physical gap by developing verifiable neuro-symbolic architectures, robust reasoning under uncertainty, and scalable models for implicit social negotiation.
SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
Physical Knowledge Enhanced Deep Neural Network for Sea Surface Temperature Prediction
Apr 19, 2023



Traditionally, numerical models have been deployed in oceanography studies to simulate ocean dynamics by representing physical equations. However, many factors pertaining to ocean dynamics seem to be ill-defined. We argue that transferring physical knowledge from observed data could further improve the accuracy of numerical models when predicting Sea Surface Temperature (SST). Recently, the advances in earth observation technologies have yielded a monumental growth of data. Consequently, it is imperative to explore ways in which to improve and supplement numerical models utilizing the ever-increasing amounts of historical observational data. To this end, we introduce a method for SST prediction that transfers physical knowledge from historical observations to numerical models. Specifically, we use a combination of an encoder and a generative adversarial network (GAN) to capture physical knowledge from the observed data. The numerical model data is then fed into the pre-trained model to generate physics-enhanced data, which can then be used for SST prediction. Experimental results demonstrate that the proposed method considerably enhances SST prediction performance when compared to several state-of-the-art baselines.
Physics-Guided Generative Adversarial Networks for Sea Subsurface Temperature Prediction
Nov 04, 2021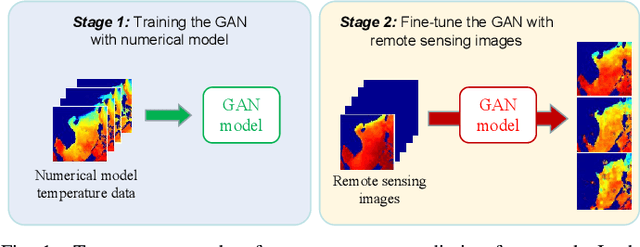
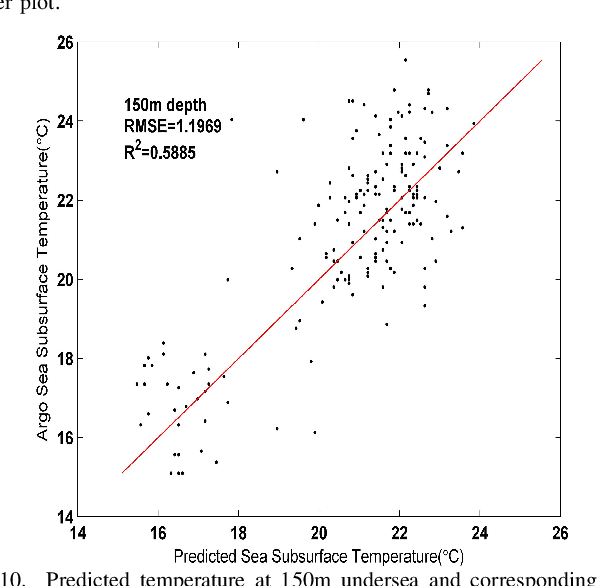
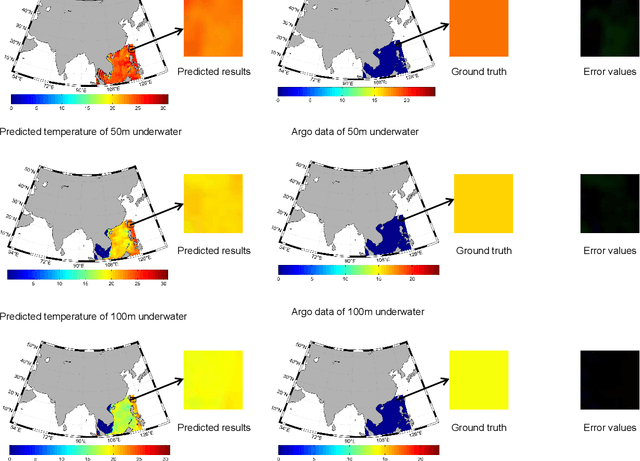
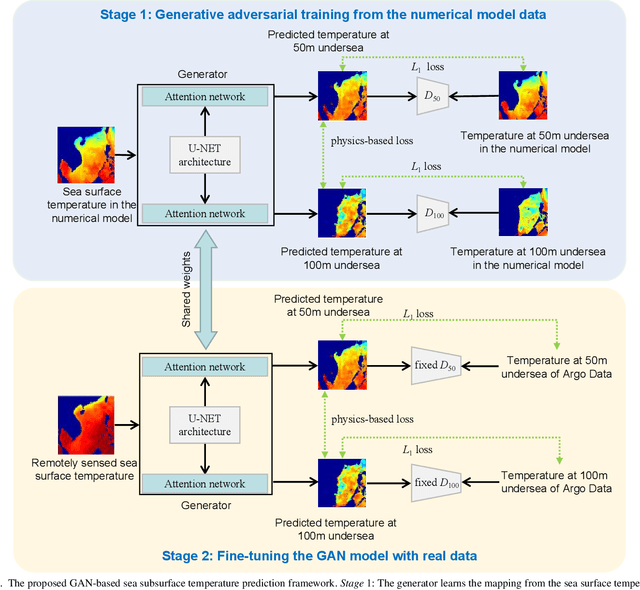
Sea subsurface temperature, an essential component of aquatic wildlife, underwater dynamics and heat transfer with the sea surface, is affected by global warming in climate change. Existing research is commonly based on either physics-based numerical models or data based models. Physical modeling and machine learning are traditionally considered as two unrelated fields for the sea subsurface temperature prediction task, with very different scientific paradigms (physics-driven and data-driven). However, we believe both methods are complementary to each other. Physical modeling methods can offer the potential for extrapolation beyond observational conditions, while data-driven methods are flexible in adapting to data and are capable of detecting unexpected patterns. The combination of both approaches is very attractive and offers potential performance improvement. In this paper, we propose a novel framework based on generative adversarial network (GAN) combined with numerical model to predict sea subsurface temperature. First, a GAN-based model is used to learn the simplified physics between the surface temperature and the target subsurface temperature in numerical model. Then, observation data are used to calibrate the GAN-based model parameters to obtain better prediction. We evaluate the proposed framework by predicting daily sea subsurface temperature in the South China sea. Extensive experiments demonstrate the effectiveness of the proposed framework compared to existing state-of-the-art methods.