 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Driving Maps by Deep Learning-based Trail Map Extraction
May 15, 2025High-definition (HD) maps offer extensive and accurate environmental information about the driving scene, making them a crucial and essential element for planning within autonomous driving systems. To avoid extensive efforts from manual labeling, methods for automating the map creation have emerged. Recent trends have moved from offline mapping to online mapping, ensuring availability and actuality of the utilized maps. While the performance has increased in recent years, online mapping still faces challenges regarding temporal consistency, sensor occlusion, runtime, and generalization. We propose a novel offline mapping approach that integrates trails - informal routes used by drivers - into the map creation process. Our method aggregates trail data from the ego vehicle and other traffic participants to construct a comprehensive global map using transformer-based deep learning models. Unlike traditional offline mapping, our approach enables continuous updates while remaining sensor-agnostic, facilitating efficient data transfer. Our method demonstrates superior performance compared to state-of-the-art online mapping approaches, achieving improved generalization to previously unseen environments and sensor configurations. We validate our approach on two benchmark datasets, highlighting its robustness and applicability in autonomous driving systems.
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Mar 31, 2025We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE ($\lambda=1$, $\gamma=1$) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency -- requiring only a tenth of the training steps, compared to DeepSeek-R1-Zero pipeline. In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
Graph-Weighted Contrastive Learning for Semi-Supervised Hyperspectral Image Classification
Mar 19, 2025Most existing graph-based semi-supervised hyperspectral image classification methods rely on superpixel partitioning techniques. However, they suffer from misclassification of certain pixels due to inaccuracies in superpixel boundaries, \ie, the initial inaccuracies in superpixel partitioning limit overall classification performance. In this paper, we propose a novel graph-weighted contrastive learning approach that avoids the use of superpixel partitioning and directly employs neural networks to learn hyperspectral image representation. Furthermore, while many approaches require all graph nodes to be available during training, our approach supports mini-batch training by processing only a subset of nodes at a time, reducing computational complexity and improving generalization to unseen nodes. Experimental results on three widely-used datasets demonstrate the effectiveness of the proposed approach compared to baselines relying on superpixel partitioning.
Reward Shaping to Mitigate Reward Hacking in RLHF
Feb 26, 2025Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to reward hacking, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. While reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests three key design principles: (1) RL reward is ideally bounded, (2) RL benefits from rapid initial growth followed by gradual convergence, and (3) RL reward is best formulated as a function of centered reward. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model itself as the signal for reinforcement learning. We evaluated PAR on two base models, Gemma2-2B and Llama3-8B, using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR's superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. Code is available at https://github.com/PorUna-byte/PAR.
InfoMatch: Entropy Neural Estimation for Semi-Supervised Image Classification
Apr 17, 2024



Semi-supervised image classification, leveraging pseudo supervision and consistency regularization, has demonstrated remarkable success. However, the ongoing challenge lies in fully exploiting the potential of unlabeled data. To address this, we employ information entropy neural estimation to harness the potential of unlabeled samples. Inspired by contrastive learning, the entropy is estimated by maximizing a lower bound on mutual information across different augmented views. Moreover, we theoretically analyze that the information entropy of the posterior of an image classifier is approximated by maximizing the likelihood function of the softmax predictions. Guided by these insights, we optimize our model from both perspectives to ensure that the predicted probability distribution closely aligns with the ground-truth distribution. Given the theoretical connection to information entropy, we name our method \textit{InfoMatch}. Through extensive experiments, we show its superior performance.
RevColV2: Exploring Disentangled Representations in Masked Image Modeling
Sep 02, 2023



Masked image modeling (MIM) has become a prevalent pre-training setup for vision foundation models and attains promising performance. Despite its success, existing MIM methods discard the decoder network during downstream applications, resulting in inconsistent representations between pre-training and fine-tuning and can hamper downstream task performance. In this paper, we propose a new architecture, RevColV2, which tackles this issue by keeping the entire autoencoder architecture during both pre-training and fine-tuning. The main body of RevColV2 contains bottom-up columns and top-down columns, between which information is reversibly propagated and gradually disentangled. Such design enables our architecture with the nice property: maintaining disentangled low-level and semantic information at the end of the network in MIM pre-training. Our experimental results suggest that a foundation model with decoupled features can achieve competitive performance across multiple downstream vision tasks such as image classification, semantic segmentation and object detection. For example, after intermediate fine-tuning on ImageNet-22K dataset, RevColV2-L attains 88.4% top-1 accuracy on ImageNet-1K classification and 58.6 mIoU on ADE20K semantic segmentation. With extra teacher and large scale dataset, RevColv2-L achieves 62.1 box AP on COCO detection and 60.4 mIoU on ADE20K semantic segmentation. Code and models are released at https://github.com/megvii-research/RevCol
Reversible Column Networks
Dec 22, 2022We propose a new neural network design paradigm Reversible Column Network (RevCol). The main body of RevCol is composed of multiple copies of subnetworks, named columns respectively, between which multi-level reversible connections are employed. Such architectural scheme attributes RevCol very different behavior from conventional networks: during forward propagation, features in RevCol are learned to be gradually disentangled when passing through each column, whose total information is maintained rather than compressed or discarded as other network does. Our experiments suggest that CNN-style RevCol models can achieve very competitive performances on multiple computer vision tasks such as image classification, object detection and semantic segmentation, especially with large parameter budget and large dataset. For example, after ImageNet-22K pre-training, RevCol-XL obtains 88.2% ImageNet-1K accuracy. Given more pre-training data, our largest model RevCol-H reaches 90.0% on ImageNet-1K, 63.8% APbox on COCO detection minival set, 61.0% mIoU on ADE20k segmentation. To our knowledge, it is the best COCO detection and ADE20k segmentation result among pure (static) CNN models. Moreover, as a general macro architecture fashion, RevCol can also be introduced into transformers or other neural networks, which is demonstrated to improve the performances in both computer vision and NLP tasks. We release code and models at https://github.com/megvii-research/RevCol
RF-Next: Efficient Receptive Field Search for Convolutional Neural Networks
Jun 15, 2022



Temporal/spatial receptive fields of models play an important role in sequential/spatial tasks. Large receptive fields facilitate long-term relations, while small receptive fields help to capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combinations further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation-guided iterative local search scheme to refine combinations effectively. Our RF-Next models, plugging receptive field search to various models, boost the performance on many tasks, e.g., temporal action segmentation, object detection, instance segmentation, and speech synthesis. The source code is publicly available on http://mmcheng.net/rfnext.
ChemiRise: a data-driven retrosynthesis engine
Aug 09, 2021
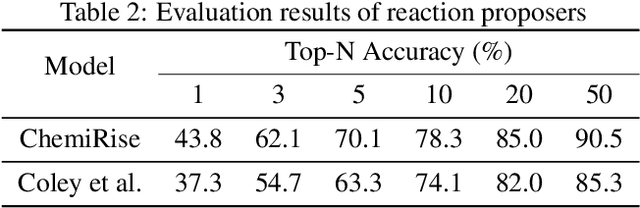

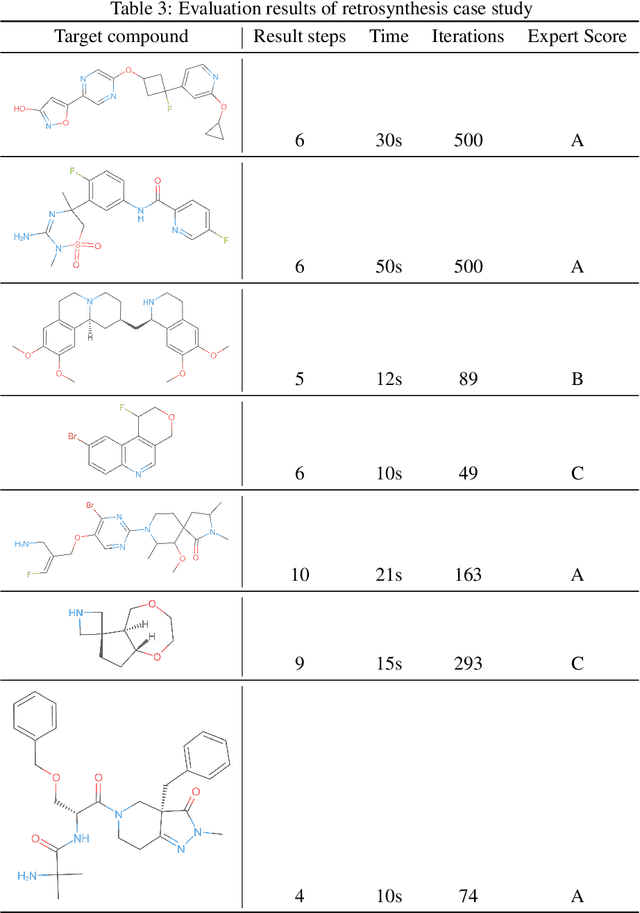
We have developed an end-to-end, retrosynthesis system, named ChemiRise, that can propose complete retrosynthesis routes for organic compounds rapidly and reliably. The system was trained on a processed patent database of over 3 million organic reactions. Experimental reactions were atom-mapped, clustered, and extracted into reaction templates. We then trained a graph convolutional neural network-based one-step reaction proposer using template embeddings and developed a guiding algorithm on the directed acyclic graph (DAG) of chemical compounds to find the best candidate to explore. The atom-mapping algorithm and the one-step reaction proposer were benchmarked against previous studies and showed better results. The final product was demonstrated by retrosynthesis routes reviewed and rated by human experts, showing satisfying functionality and a potential productivity boost in real-life use cases.
Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
Jun 08, 2021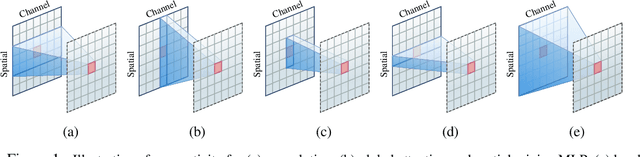
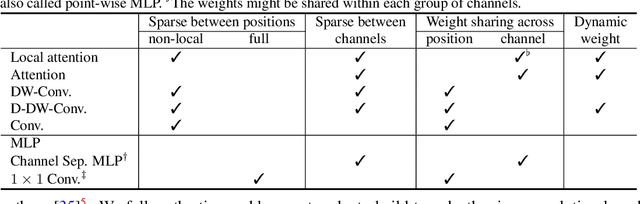
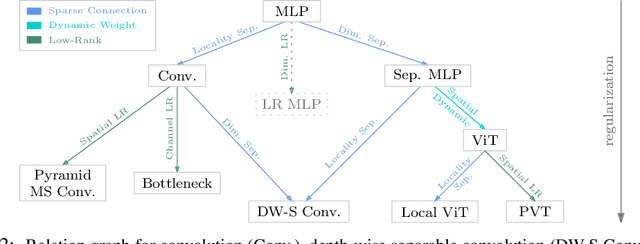
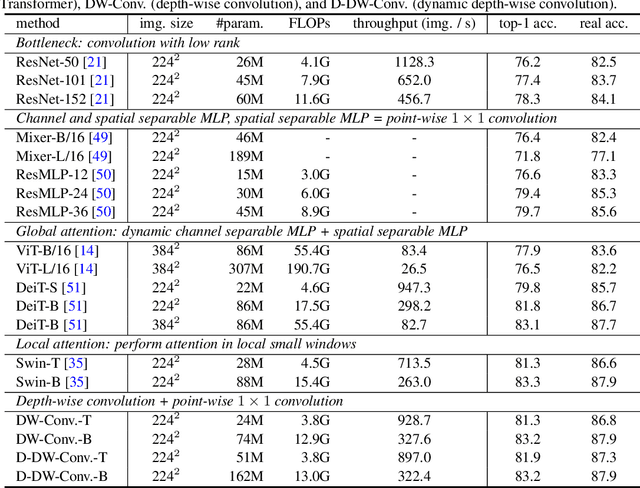
Vision Transformer (ViT) attains state-of-the-art performance in visual recognition, and the variant, Local Vision Transformer, makes further improvements. The major component in Local Vision Transformer, local attention, performs the attention separately over small local windows. We rephrase local attention as a channel-wise locally-connected layer and analyze it from two network regularization manners, sparse connectivity and weight sharing, as well as weight computation. Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window. Weight sharing: the connection weights for one position are shared across channels or within each group of channels. Dynamic weight: the connection weights are dynamically predicted according to each image instance. We point out that local attention resembles depth-wise convolution and its dynamic version in sparse connectivity. The main difference lies in weight sharing - depth-wise convolution shares connection weights (kernel weights) across spatial positions. We empirically observe that the models based on depth-wise convolution and the dynamic variant with lower computation complexity perform on-par with or sometimes slightly better than Swin Transformer, an instance of Local Vision Transformer, for ImageNet classification, COCO object detection and ADE semantic segmentation. These observations suggest that Local Vision Transformer takes advantage of two regularization forms and dynamic weight to increase the network capacity.