 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Contrastive Learning with Infinite Possibilities
Oct 10, 2020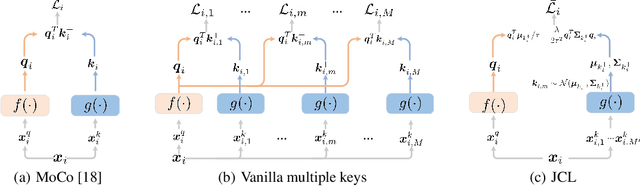
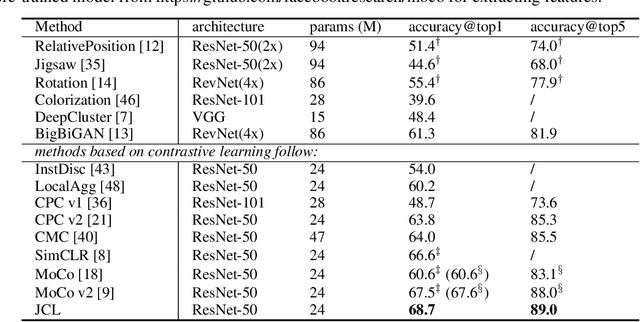
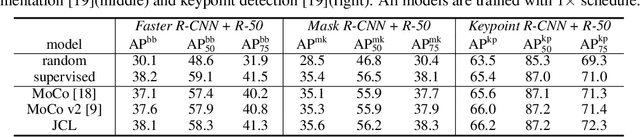
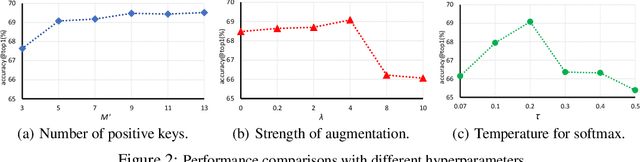
This paper explores useful modifications of the recent development in contrastive learning via novel probabilistic modeling. We derive a particular form of contrastive loss named Joint Contrastive Learning (JCL). JCL implicitly involves the simultaneous learning of an infinite number of query-key pairs, which poses tighter constraints when searching for invariant features. We derive an upper bound on this formulation that allows analytical solutions in an end-to-end training manner. While JCL is practically effective in numerous computer vision applications, we also theoretically unveil the certain mechanisms that govern the behavior of JCL. We demonstrate that the proposed formulation harbors an innate agency that strongly favors similarity within each instance-specific class, and therefore remains advantageous when searching for discriminative features among distinct instances. We evaluate these proposals on multiple benchmarks, demonstrating considerable improvements over existing algorithms. Code is publicly available at: https://github.com/caiqi/Joint-Contrastive-Learning.
A Self Contour-based Rotation and Translation-Invariant Transformation for Point Clouds Recognition
Sep 15, 2020
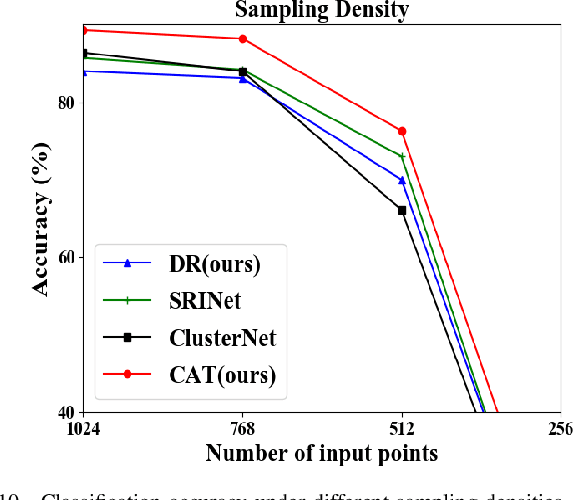
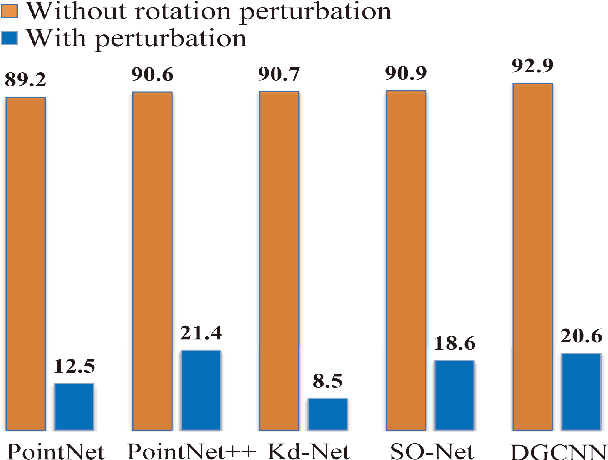
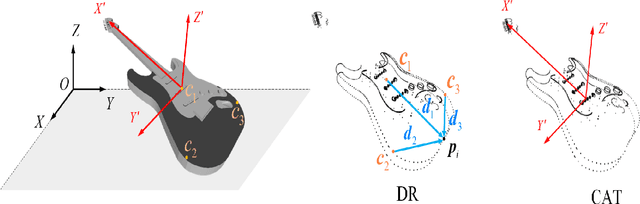
Recently, several direct processing point cloud models have achieved state-of-the-art performances for classification and segmentation tasks. However, these methods lack rotation robustness, and their performances degrade severely under random rotations, failing to extend to real-world applications with varying orientations. To address this problem, we propose a method named Self Contour-based Transformation (SCT), which can be flexibly integrated into a variety of existing point cloud recognition models against arbitrary rotations without any extra modifications. The SCT provides efficient and mathematically proved rotation and translation invariance by introducing Rotation and Translation-Invariant Transformation. It linearly transforms Cartesian coordinates of points to the self contour-based rotation-invariant representations while maintaining the global geometric structure. Moreover, to enhance discriminative feature extraction, the Frame Alignment module is further introduced, aiming to capture contours and transform self contour-based frames to the intra-class frame. Extensive experimental results and mathematical analyses show that the proposed method outperforms the state-of-the-art approaches under arbitrary rotations without any rotation augmentation on standard benchmarks, including ModelNet40, ScanObjectNN and ShapeNet.
On the Global Optimality of Model-Agnostic Meta-Learning
Jun 23, 2020Model-agnostic meta-learning (MAML) formulates meta-learning as a bilevel optimization problem, where the inner level solves each subtask based on a shared prior, while the outer level searches for the optimal shared prior by optimizing its aggregated performance over all the subtasks. Despite its empirical success, MAML remains less understood in theory, especially in terms of its global optimality, due to the nonconvexity of the meta-objective (the outer-level objective). To bridge such a gap between theory and practice, we characterize the optimality gap of the stationary points attained by MAML for both reinforcement learning and supervised learning, where the inner-level and outer-level problems are solved via first-order optimization methods. In particular, our characterization connects the optimality gap of such stationary points with (i) the functional geometry of inner-level objectives and (ii) the representation power of function approximators, including linear models and neural networks. To the best of our knowledge, our analysis establishes the global optimality of MAML with nonconvex meta-objectives for the first time.
Learning a Unified Sample Weighting Network for Object Detection
Jun 14, 2020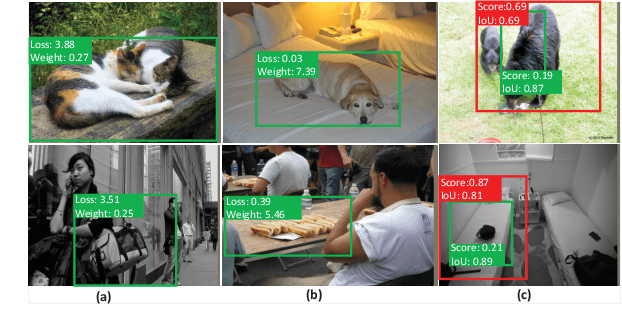

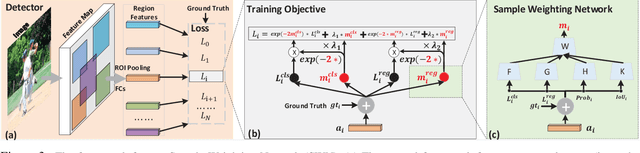
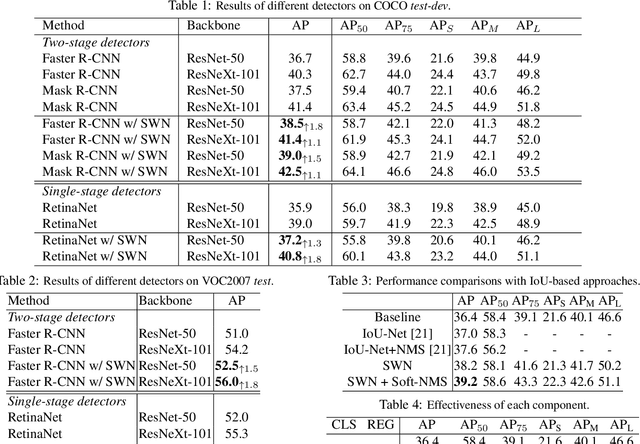
Region sampling or weighting is significantly important to the success of modern region-based object detectors. Unlike some previous works, which only focus on "hard" samples when optimizing the objective function, we argue that sample weighting should be data-dependent and task-dependent. The importance of a sample for the objective function optimization is determined by its uncertainties to both object classification and bounding box regression tasks. To this end, we devise a general loss function to cover most region-based object detectors with various sampling strategies, and then based on it we propose a unified sample weighting network to predict a sample's task weights. Our framework is simple yet effective. It leverages the samples' uncertainty distributions on classification loss, regression loss, IoU, and probability score, to predict sample weights. Our approach has several advantages: (i). It jointly learns sample weights for both classification and regression tasks, which differentiates it from most previous work. (ii). It is a data-driven process, so it avoids some manual parameter tuning. (iii). It can be effortlessly plugged into most object detectors and achieves noticeable performance improvements without affecting their inference time. Our approach has been thoroughly evaluated with recent object detection frameworks and it can consistently boost the detection accuracy. Code has been made available at \url{https://github.com/caiqi/sample-weighting-network}.
Can Temporal-Difference and Q-Learning Learn Representation? A Mean-Field Theory
Jun 08, 2020
Temporal-difference and Q-learning play a key role in deep reinforcement learning, where they are empowered by expressive nonlinear function approximators such as neural networks. At the core of their empirical successes is the learned feature representation, which embeds rich observations, e.g., images and texts, into the latent space that encodes semantic structures. Meanwhile, the evolution of such a feature representation is crucial to the convergence of temporal-difference and Q-learning. In particular, temporal-difference learning converges when the function approximator is linear in a feature representation, which is fixed throughout learning, and possibly diverges otherwise. We aim to answer the following questions: When the function approximator is a neural network, how does the associated feature representation evolve? If it converges, does it converge to the optimal one? We prove that, utilizing an overparameterized two-layer neural network, temporal-difference and Q-learning globally minimize the mean-squared projected Bellman error at a sublinear rate. Moreover, the associated feature representation converges to the optimal one, generalizing the previous analysis of Cai et al. (2019) in the neural tangent kernel regime, where the associated feature representation stabilizes at the initial one. The key to our analysis is a mean-field perspective, which connects the evolution of a finite-dimensional parameter to its limiting counterpart over an infinite-dimensional Wasserstein space. Our analysis generalizes to soft Q-learning, which is further connected to policy gradient.
Generative Adversarial Imitation Learning with Neural Networks: Global Optimality and Convergence Rate
Mar 08, 2020Generative adversarial imitation learning (GAIL) demonstrates tremendous success in practice, especially when combined with neural networks. Different from reinforcement learning, GAIL learns both policy and reward function from expert (human) demonstration. Despite its empirical success, it remains unclear whether GAIL with neural networks converges to the globally optimal solution. The major difficulty comes from the nonconvex-nonconcave minimax optimization structure. To bridge the gap between practice and theory, we analyze a gradient-based algorithm with alternating updates and establish its sublinear convergence to the globally optimal solution. To the best of our knowledge, our analysis establishes the global optimality and convergence rate of GAIL with neural networks for the first time.
Provably Efficient Exploration in Policy Optimization
Dec 12, 2019While policy-based reinforcement learning (RL) achieves tremendous successes in practice, it is significantly less understood in theory, especially compared with value-based RL. In particular, it remains elusive how to design a provably efficient policy optimization algorithm that incorporates exploration. To bridge such a gap, this paper proposes an Optimistic variant of the Proximal Policy Optimization algorithm (OPPO), which follows an "optimistic version" of the policy gradient direction. This paper proves that, in the problem of episodic Markov decision process with linear function approximation, unknown transition, and adversarial reward with full-information feedback, OPPO achieves $\tilde{O}(\sqrt{d^3 H^3 T})$ regret. Here $d$ is the feature dimension, $H$ is the episode horizon, and $T$ is the total number of steps. To the best of our knowledge, OPPO is the first provably efficient policy optimization algorithm that explores.
Multi-Source Domain Adaptation and Semi-Supervised Domain Adaptation with Focus on Visual Domain Adaptation Challenge 2019
Oct 14, 2019
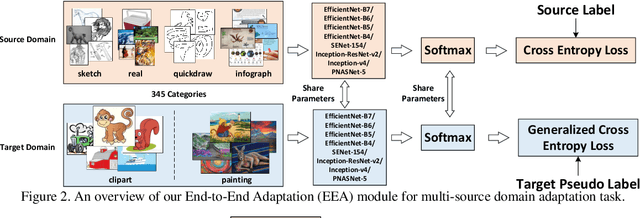
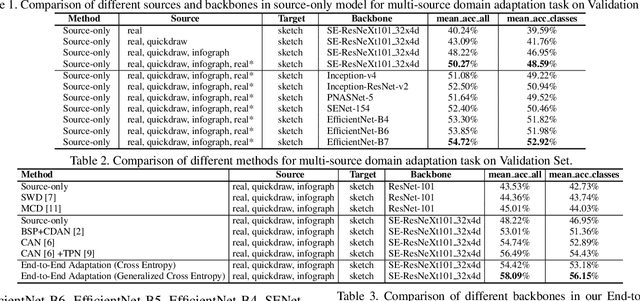
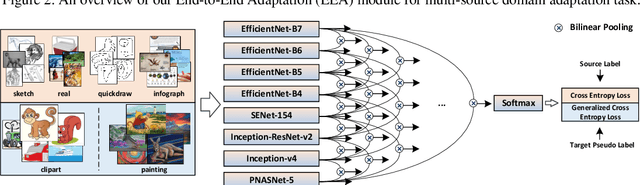
This notebook paper presents an overview and comparative analysis of our systems designed for the following two tasks in Visual Domain Adaptation Challenge (VisDA-2019): multi-source domain adaptation and semi-supervised domain adaptation. Multi-Source Domain Adaptation: We investigate both pixel-level and feature-level adaptation for multi-source domain adaptation task, i.e., directly hallucinating labeled target sample via CycleGAN and learning domain-invariant feature representations through self-learning. Moreover, the mechanism of fusing features from different backbones is further studied to facilitate the learning of domain-invariant classifiers. Source code and pre-trained models are available at \url{https://github.com/Panda-Peter/visda2019-multisource}. Semi-Supervised Domain Adaptation: For this task, we adopt a standard self-learning framework to construct a classifier based on the labeled source and target data, and generate the pseudo labels for unlabeled target data. These target data with pseudo labels are then exploited to re-training the classifier in a following iteration. Furthermore, a prototype-based classification module is additionally utilized to strengthen the predictions. Source code and pre-trained models are available at \url{https://github.com/Panda-Peter/visda2019-semisupervised}.
Neural Policy Gradient Methods: Global Optimality and Rates of Convergence
Oct 07, 2019Policy gradient methods with actor-critic schemes demonstrate tremendous empirical successes, especially when the actors and critics are parameterized by neural networks. However, it remains less clear whether such "neural" policy gradient methods converge to globally optimal policies and whether they even converge at all. We answer both the questions affirmatively in the overparameterized regime. In detail, we prove that neural natural policy gradient converges to a globally optimal policy at a sublinear rate. Also, we show that neural vanilla policy gradient converges sublinearly to a stationary point. Meanwhile, by relating the suboptimality of the stationary points to the representation power of neural actor and critic classes, we prove the global optimality of all stationary points under mild regularity conditions. Particularly, we show that a key to the global optimality and convergence is the "compatibility" between the actor and critic, which is ensured by sharing neural architectures and random initializations across the actor and critic. To the best of our knowledge, our analysis establishes the first global optimality and convergence guarantees for neural policy gradient methods.
Neural Proximal/Trust Region Policy Optimization Attains Globally Optimal Policy
Jun 25, 2019Proximal policy optimization and trust region policy optimization (PPO and TRPO) with actor and critic parametrized by neural networks achieve significant empirical success in deep reinforcement learning. However, due to nonconvexity, the global convergence of PPO and TRPO remains less understood, which separates theory from practice. In this paper, we prove that a variant of PPO and TRPO equipped with overparametrized neural networks converges to the globally optimal policy at a sublinear rate. The key to our analysis is the global convergence of infinite-dimensional mirror descent under a notion of one-point monotonicity, where the gradient and iterate are instantiated by neural networks. In particular, the desirable representation power and optimization geometry induced by the overparametrization of such neural networks allow them to accurately approximate the infinite-dimensional gradient and iterate.