 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019
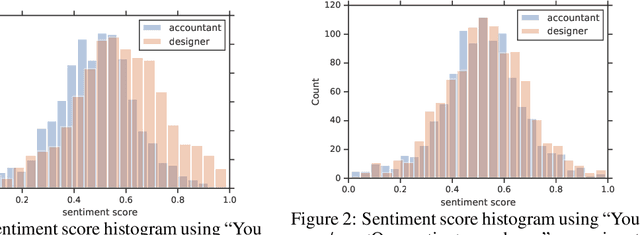
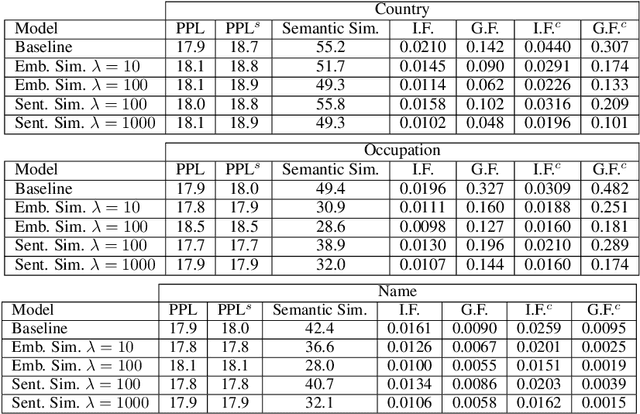
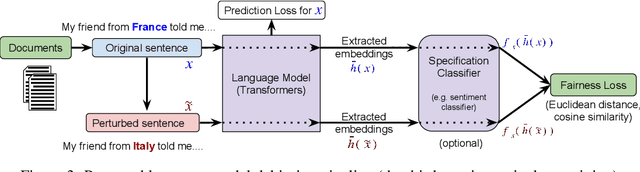
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
Learning Transferable Graph Exploration
Oct 28, 2019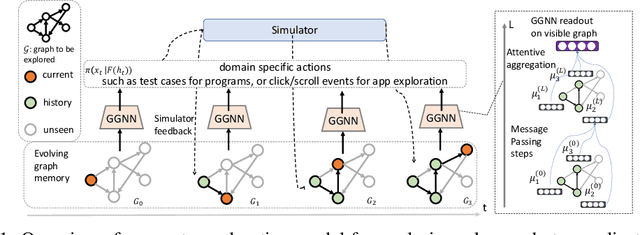
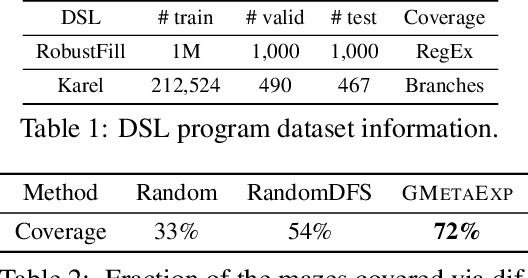


This paper considers the problem of efficient exploration of unseen environments, a key challenge in AI. We propose a `learning to explore' framework where we learn a policy from a distribution of environments. At test time, presented with an unseen environment from the same distribution, the policy aims to generalize the exploration strategy to visit the maximum number of unique states in a limited number of steps. We particularly focus on environments with graph-structured state-spaces that are encountered in many important real-world applications like software testing and map building. We formulate this task as a reinforcement learning problem where the `exploration' agent is rewarded for transitioning to previously unseen environment states and employ a graph-structured memory to encode the agent's past trajectory. Experimental results demonstrate that our approach is extremely effective for exploration of spatial maps; and when applied on the challenging problems of coverage-guided software-testing of domain-specific programs and real-world mobile applications, it outperforms methods that have been hand-engineered by human experts.
An Alternative Surrogate Loss for PGD-based Adversarial Testing
Oct 21, 2019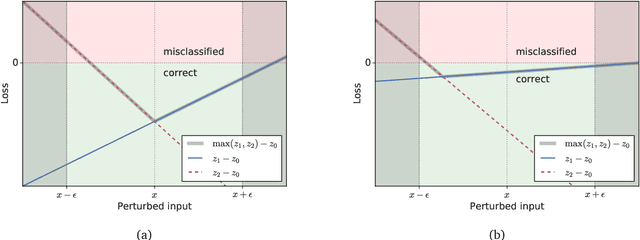

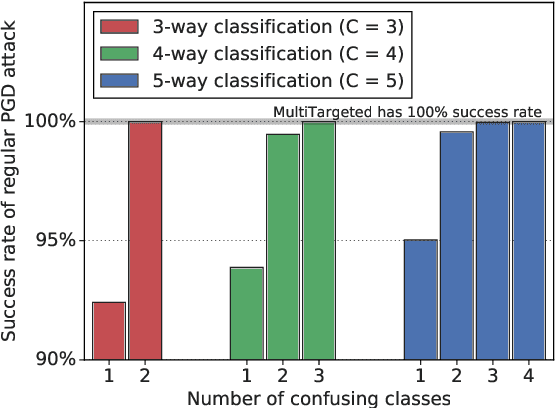

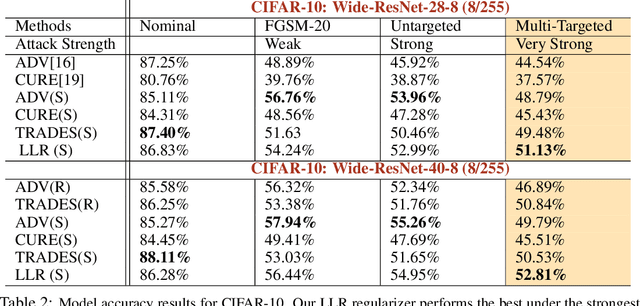
Adversarial testing methods based on Projected Gradient Descent (PGD) are widely used for searching norm-bounded perturbations that cause the inputs of neural networks to be misclassified. This paper takes a deeper look at these methods and explains the effect of different hyperparameters (i.e., optimizer, step size and surrogate loss). We introduce the concept of MultiTargeted testing, which makes clever use of alternative surrogate losses, and explain when and how MultiTargeted is guaranteed to find optimal perturbations. Finally, we demonstrate that MultiTargeted outperforms more sophisticated methods and often requires less iterative steps than other variants of PGD found in the literature. Notably, MultiTargeted ranks first on MadryLab's white-box MNIST and CIFAR-10 leaderboards, reducing the accuracy of their MNIST model to 88.36% (with $\ell_\infty$ perturbations of $\epsilon = 0.3$) and the accuracy of their CIFAR-10 model to 44.03% (at $\epsilon = 8/255$). MultiTargeted also ranks first on the TRADES leaderboard reducing the accuracy of their CIFAR-10 model to 53.07% (with $\ell_\infty$ perturbations of $\epsilon = 0.031$).
Making sense of sensory input
Oct 05, 2019
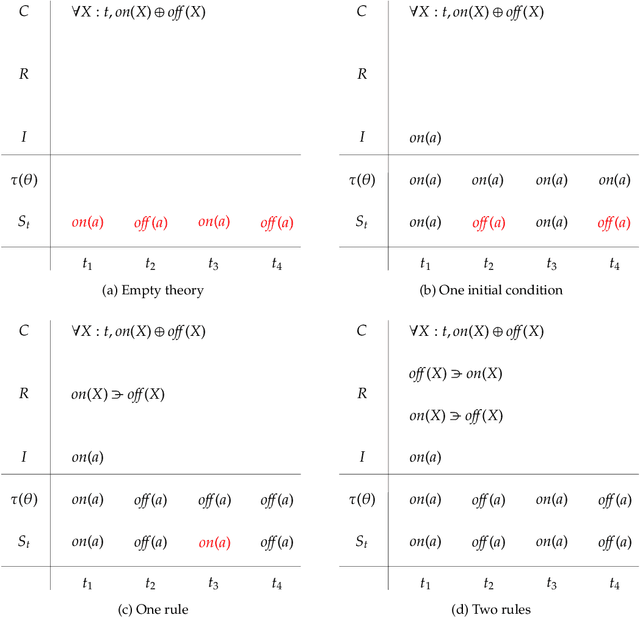
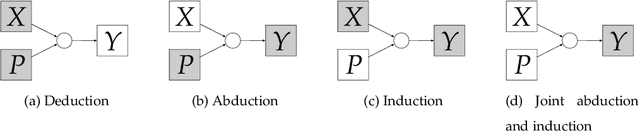
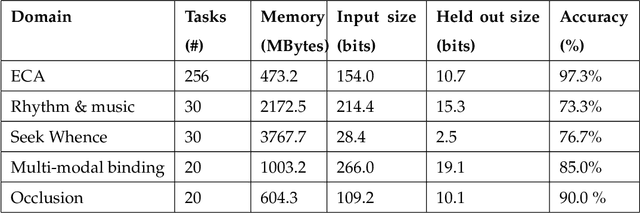
This paper attempts to answer a central question in unsupervised learning: what does it mean to "make sense" of a sensory sequence? In our formalization, making sense involves constructing a symbolic causal theory that explains the sensory sequence and satisfies a set of unity conditions. This model was inspired by Kant's discussion of the synthetic unity of apperception in the Critique of Pure Reason. On our account, making sense of sensory input is a type of program synthesis, but it is unsupervised program synthesis. Our second contribution is a computer implementation, the Apperception Engine, that was designed to satisfy the above requirements. Our system is able to produce interpretable human-readable causal theories from very small amounts of data, because of the strong inductive bias provided by the Kantian unity constraints. A causal theory produced by our system is able to predict future sensor readings, as well as retrodict earlier readings, and "impute" (fill in the blanks of) missing sensory readings, in any combination. We tested the engine in a diverse variety of domains, including cellular automata, rhythms and simple nursery tunes, multi-modal binding problems, occlusion tasks, and sequence induction IQ tests. In each domain, we test our engine's ability to predict future sensor values, retrodict earlier sensor values, and impute missing sensory data. The Apperception Engine performs well in all these domains, significantly out-performing neural net baselines. We note in particular that in the sequence induction IQ tasks, our system achieved human-level performance. This is notable because our system is not a bespoke system designed specifically to solve IQ tasks, but a general purpose apperception system that was designed to make sense of any sensory sequence.
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Oct 03, 2019

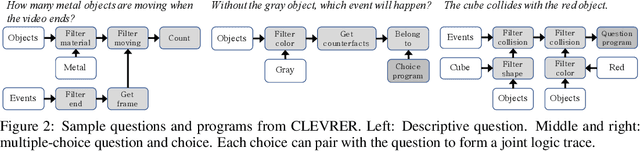
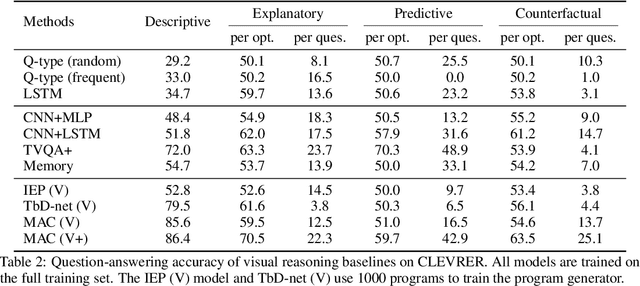
The ability to reason about temporal and causal events from videos lies at the core of human intelligence. Most video reasoning benchmarks, however, focus on pattern recognition from complex visual and language input, instead of on causal structure. We study the complementary problem, exploring the temporal and causal structures behind videos of objects with simple visual appearance. To this end, we introduce the CoLlision Events for Video REpresentation and Reasoning (CLEVRER), a diagnostic video dataset for systematic evaluation of computational models on a wide range of reasoning tasks. Motivated by the theory of human casual judgment, CLEVRER includes four types of questions: descriptive (e.g., "what color"), explanatory ("what is responsible for"), predictive ("what will happen next"), and counterfactual ("what if"). We evaluate various state-of-the-art models for visual reasoning on our benchmark. While these models thrive on the perception-based task (descriptive), they perform poorly on the causal tasks (explanatory, predictive and counterfactual), suggesting that a principled approach for causal reasoning should incorporate the capability of both perceiving complex visual and language inputs, and understanding the underlying dynamics and causal relations. We also study an oracle model that explicitly combines these components via symbolic representations.
Branch and Bound for Piecewise Linear Neural Network Verification
Sep 14, 2019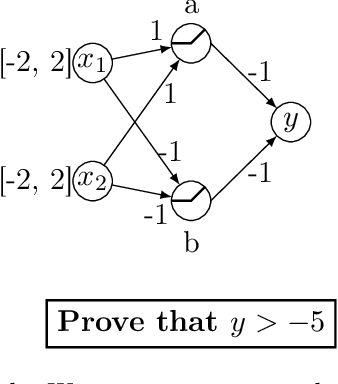
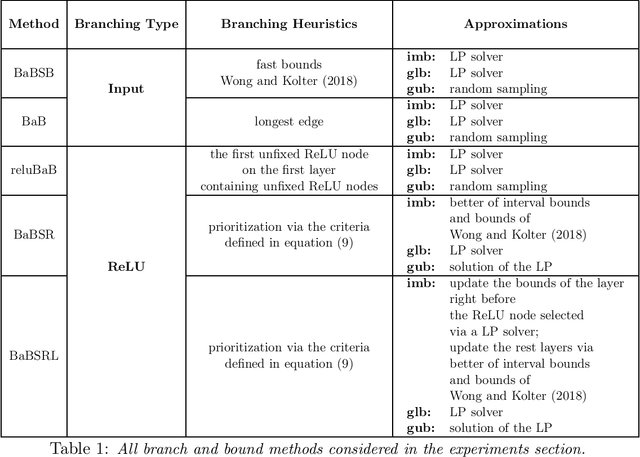
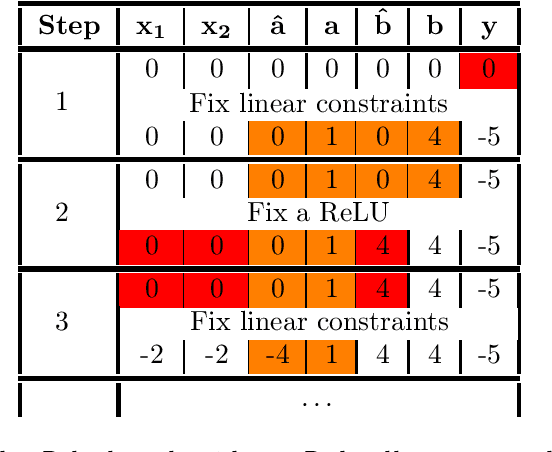
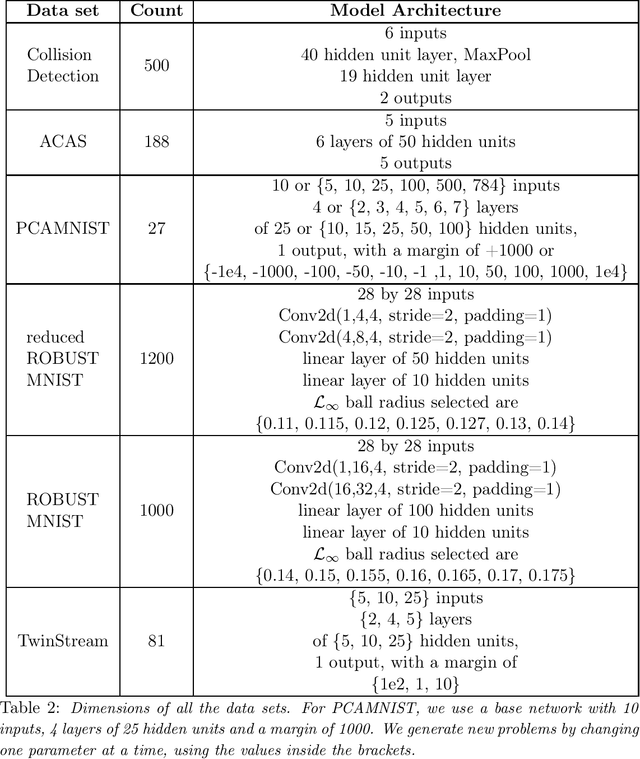
The success of Deep Learning and its potential use in many safety-critical applications has motivated research on formal verification of Neural Network (NN) models. In this context, verification means verifying whether a NN model satisfies certain input-output properties. Despite the reputation of learned NN models as black boxes, and the theoretical hardness of proving useful properties about them, researchers have been successful in verifying some classes of models by exploiting their piecewise linear structure and taking insights from formal methods such as Satisifiability Modulo Theory. However, these methods are still far from scaling to realistic neural networks. To facilitate progress on this crucial area, we make two key contributions. First, we present a unified framework based on branch and bound that encompasses previous methods. This analysis results in the identification of new methods that combine the strengths of multiple existing approaches, accomplishing a speedup of two orders of magnitude compared to the previous state of the art. Second, we propose a new data set of benchmarks which includes a collection of previously released test cases. We use the benchmark to provide a thorough experimental comparison of existing algorithms and identify the factors impacting the hardness of verification problems.
Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation
Sep 03, 2019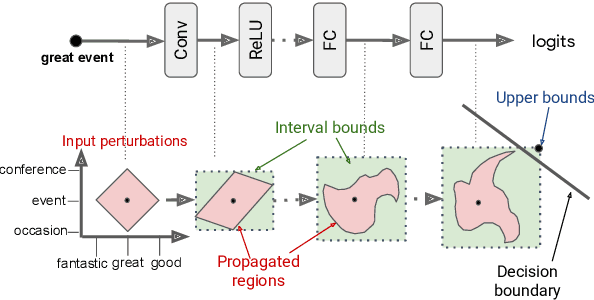


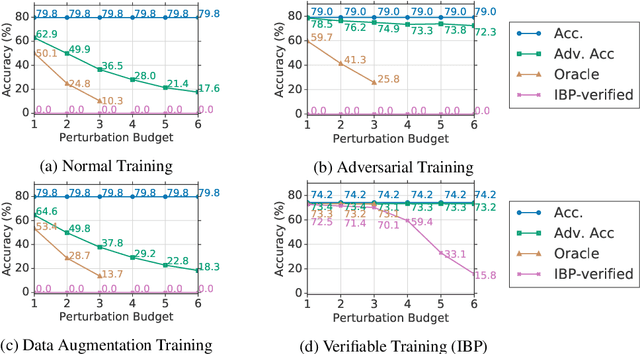
Neural networks are part of many contemporary NLP systems, yet their empirical successes come at the price of vulnerability to adversarial attacks. Previous work has used adversarial training and data augmentation to partially mitigate such brittleness, but these are unlikely to find worst-case adversaries due to the complexity of the search space arising from discrete text perturbations. In this work, we approach the problem from the opposite direction: to formally verify a system's robustness against a predefined class of adversarial attacks. We study text classification under synonym replacements or character flip perturbations. We propose modeling these input perturbations as a simplex and then using Interval Bound Propagation -- a formal model verification method. We modify the conventional log-likelihood training objective to train models that can be efficiently verified, which would otherwise come with exponential search complexity. The resulting models show only little difference in terms of nominal accuracy, but have much improved verified accuracy under perturbations and come with an efficiently computable formal guarantee on worst case adversaries.
Adversarial Robustness through Local Linearization
Jul 04, 2019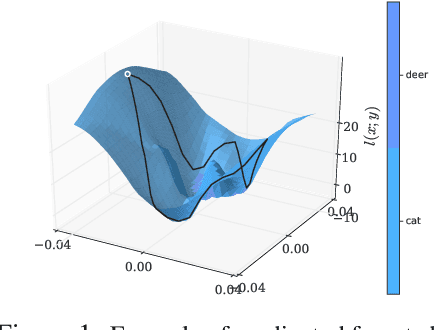
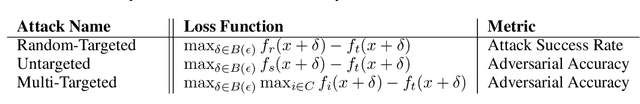
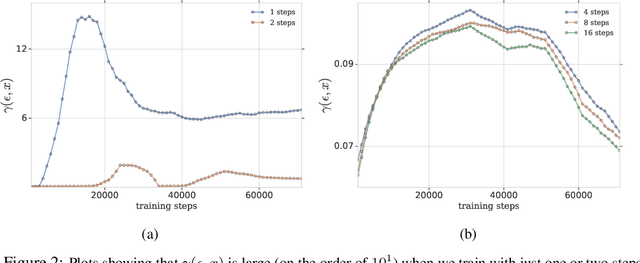
Adversarial training is an effective methodology for training deep neural networks that are robust against adversarial, norm-bounded perturbations. However, the computational cost of adversarial training grows prohibitively as the size of the model and number of input dimensions increase. Further, training against less expensive and therefore weaker adversaries produces models that are robust against weak attacks but break down under attacks that are stronger. This is often attributed to the phenomenon of gradient obfuscation; such models have a highly non-linear loss surface in the vicinity of training examples, making it hard for gradient-based attacks to succeed even though adversarial examples still exist. In this work, we introduce a novel regularizer that encourages the loss to behave linearly in the vicinity of the training data, thereby penalizing gradient obfuscation while encouraging robustness. We show via extensive experiments on CIFAR-10 and ImageNet, that models trained with our regularizer avoid gradient obfuscation and can be trained significantly faster than adversarial training. Using this regularizer, we exceed current state of the art and achieve 47% adversarial accuracy for ImageNet with l-infinity adversarial perturbations of radius 4/255 under an untargeted, strong, white-box attack. Additionally, we match state of the art results for CIFAR-10 at 8/255.
Are Labels Required for Improving Adversarial Robustness?
May 31, 2019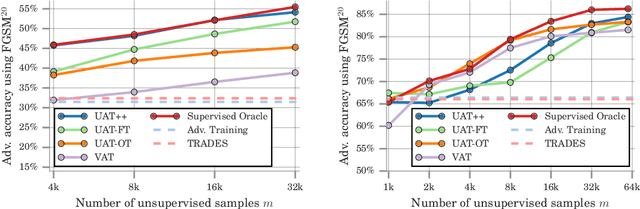
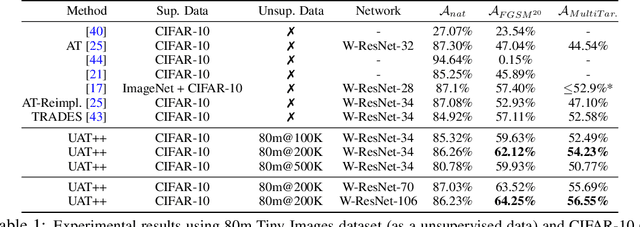
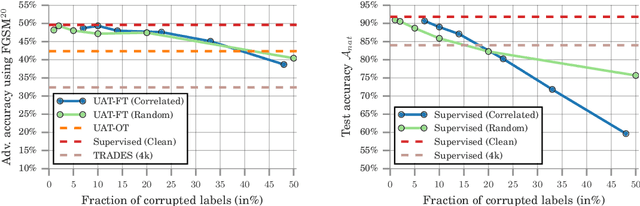
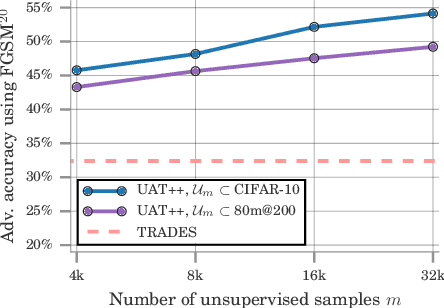
Recent work has uncovered the interesting (and somewhat surprising) finding that training models to be invariant to adversarial perturbations requires substantially larger datasets than those required for standard classification. This result is a key hurdle in the deployment of robust machine learning models in many real world applications where labeled data is expensive. Our main insight is that unlabeled data can be a competitive alternative to labeled data for training adversarially robust models. Theoretically, we show that in a simple statistical setting, the sample complexity for learning an adversarially robust model from unlabeled data matches the fully supervised case up to constant factors. On standard datasets like CIFAR-10, a simple Unsupervised Adversarial Training (UAT) approach using unlabeled data improves robust accuracy by 21.7% over using 4K supervised examples alone, and captures over 95% of the improvement from the same number of labeled examples. Finally, we report an improvement of 4% over the previous state-of-the-art on CIFAR-10 against the strongest known attack by using additional unlabeled data from the uncurated 80 Million Tiny Images dataset. This demonstrates that our finding extends as well to the more realistic case where unlabeled data is also uncurated, therefore opening a new avenue for improving adversarial training.
A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities
May 30, 2019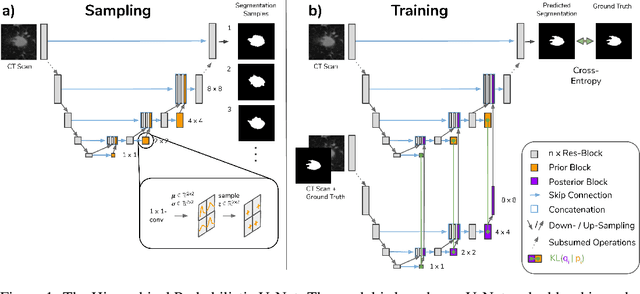
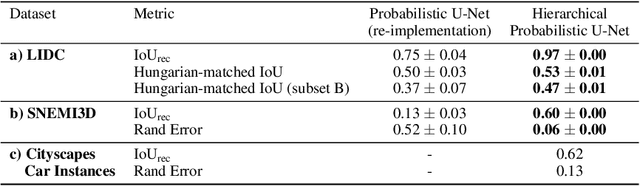
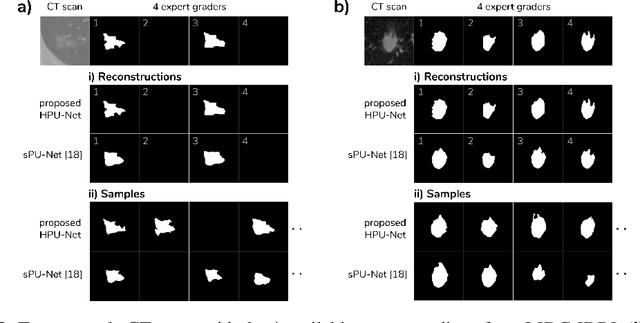

Medical imaging only indirectly measures the molecular identity of the tissue within each voxel, which often produces only ambiguous image evidence for target measures of interest, like semantic segmentation. This diversity and the variations of plausible interpretations are often specific to given image regions and may thus manifest on various scales, spanning all the way from the pixel to the image level. In order to learn a flexible distribution that can account for multiple scales of variations, we propose the Hierarchical Probabilistic U-Net, a segmentation network with a conditional variational auto-encoder (cVAE) that uses a hierarchical latent space decomposition. We show that this model formulation enables sampling and reconstruction of segmenations with high fidelity, i.e. with finely resolved detail, while providing the flexibility to learn complex structured distributions across scales. We demonstrate these abilities on the task of segmenting ambiguous medical scans as well as on instance segmentation of neurobiological and natural images. Our model automatically separates independent factors across scales, an inductive bias that we deem beneficial in structured output prediction tasks beyond segmentation.