 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Neural Compilation
May 26, 2016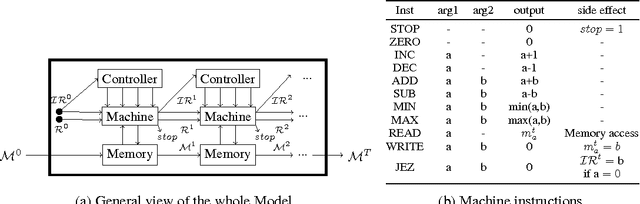
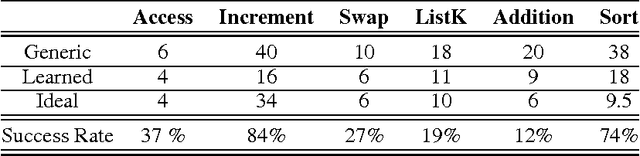

This paper proposes an adaptive neural-compilation framework to address the problem of efficient program learning. Traditional code optimisation strategies used in compilers are based on applying pre-specified set of transformations that make the code faster to execute without changing its semantics. In contrast, our work involves adapting programs to make them more efficient while considering correctness only on a target input distribution. Our approach is inspired by the recent works on differentiable representations of programs. We show that it is possible to compile programs written in a low-level language to a differentiable representation. We also show how programs in this representation can be optimised to make them efficient on a target distribution of inputs. Experimental results demonstrate that our approach enables learning specifically-tuned algorithms for given data distributions with a high success rate.
Time-Sensitive Bayesian Information Aggregation for Crowdsourcing Systems
Apr 18, 2016
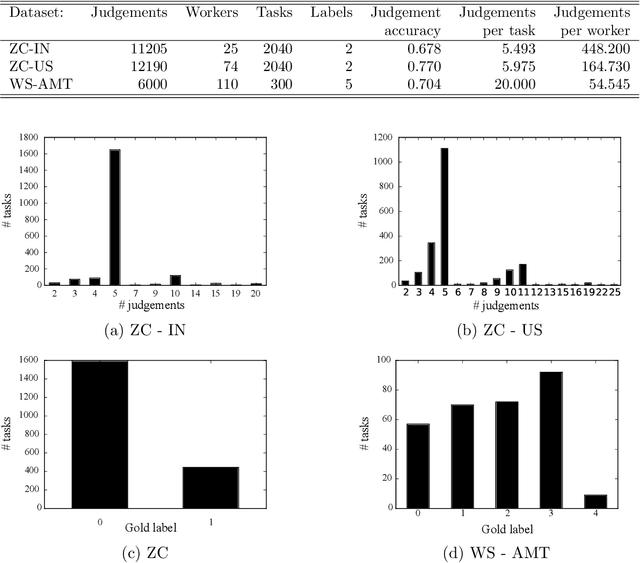
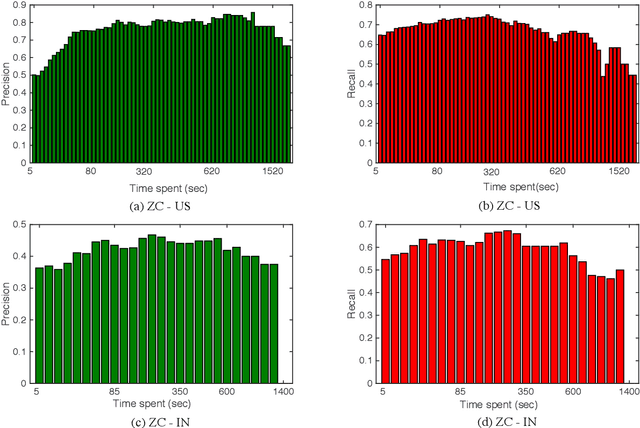
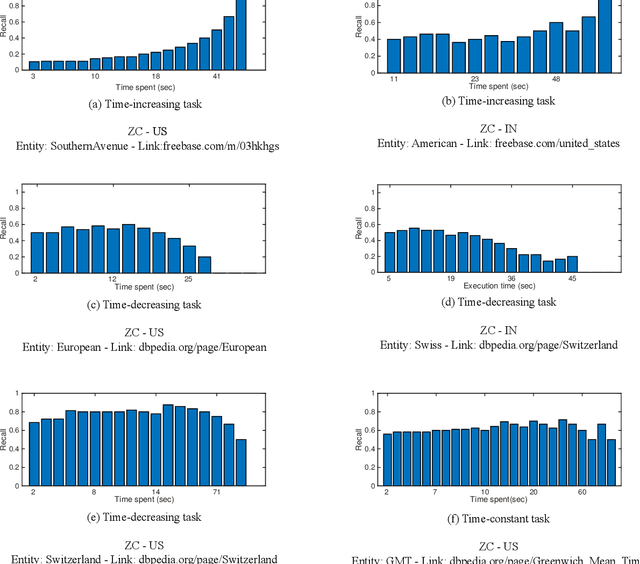
Crowdsourcing systems commonly face the problem of aggregating multiple judgments provided by potentially unreliable workers. In addition, several aspects of the design of efficient crowdsourcing processes, such as defining worker's bonuses, fair prices and time limits of the tasks, involve knowledge of the likely duration of the task at hand. Bringing this together, in this work we introduce a new time--sensitive Bayesian aggregation method that simultaneously estimates a task's duration and obtains reliable aggregations of crowdsourced judgments. Our method, called BCCTime, builds on the key insight that the time taken by a worker to perform a task is an important indicator of the likely quality of the produced judgment. To capture this, BCCTime uses latent variables to represent the uncertainty about the workers' completion time, the tasks' duration and the workers' accuracy. To relate the quality of a judgment to the time a worker spends on a task, our model assumes that each task is completed within a latent time window within which all workers with a propensity to genuinely attempt the labelling task (i.e., no spammers) are expected to submit their judgments. In contrast, workers with a lower propensity to valid labeling, such as spammers, bots or lazy labelers, are assumed to perform tasks considerably faster or slower than the time required by normal workers. Specifically, we use efficient message-passing Bayesian inference to learn approximate posterior probabilities of (i) the confusion matrix of each worker, (ii) the propensity to valid labeling of each worker, (iii) the unbiased duration of each task and (iv) the true label of each task. Using two real-world public datasets for entity linking tasks, we show that BCCTime produces up to 11% more accurate classifications and up to 100% more informative estimates of a task's duration compared to state-of-the-art methods.
Visual Storytelling
Apr 13, 2016

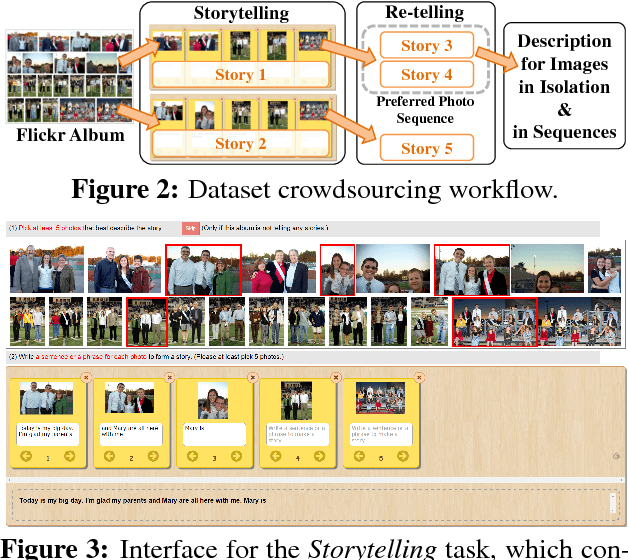
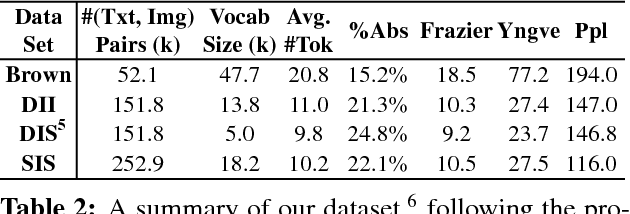
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories
Apr 06, 2016
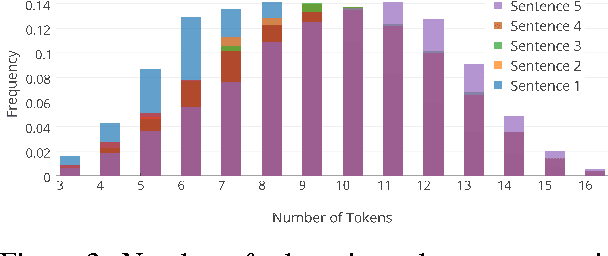

Representation and learning of commonsense knowledge is one of the foundational problems in the quest to enable deep language understanding. This issue is particularly challenging for understanding casual and correlational relationships between events. While this topic has received a lot of interest in the NLP community, research has been hindered by the lack of a proper evaluation framework. This paper attempts to address this problem with a new framework for evaluating story understanding and script learning: the 'Story Cloze Test'. This test requires a system to choose the correct ending to a four-sentence story. We created a new corpus of ~50k five-sentence commonsense stories, ROCStories, to enable this evaluation. This corpus is unique in two ways: (1) it captures a rich set of causal and temporal commonsense relations between daily events, and (2) it is a high quality collection of everyday life stories that can also be used for story generation. Experimental evaluation shows that a host of baselines and state-of-the-art models based on shallow language understanding struggle to achieve a high score on the Story Cloze Test. We discuss these implications for script and story learning, and offer suggestions for deeper language understanding.
Learning to Navigate the Energy Landscape
Mar 18, 2016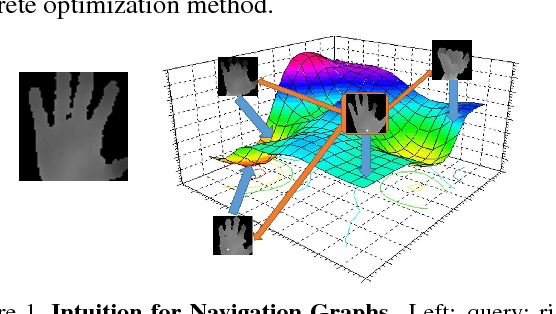
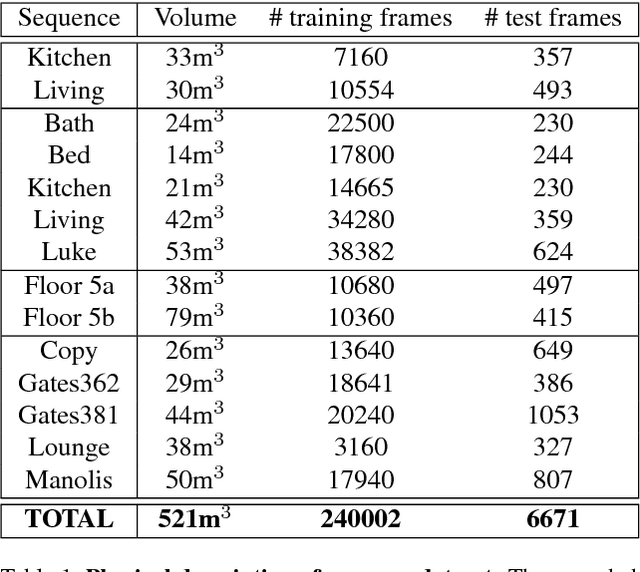
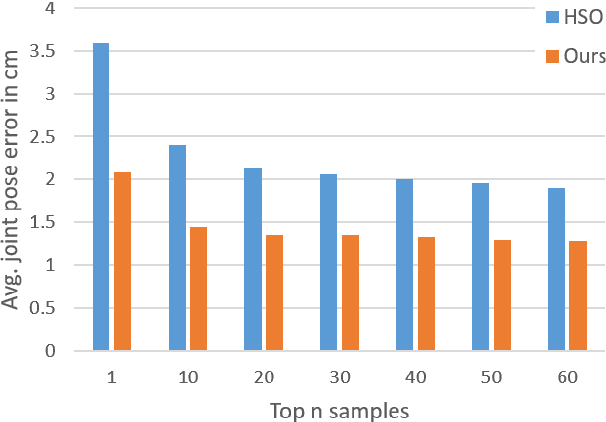
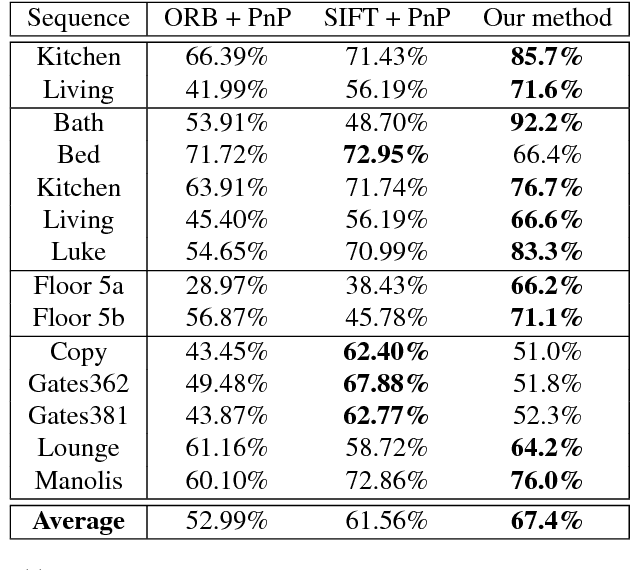
In this paper, we present a novel and efficient architecture for addressing computer vision problems that use `Analysis by Synthesis'. Analysis by synthesis involves the minimization of the reconstruction error which is typically a non-convex function of the latent target variables. State-of-the-art methods adopt a hybrid scheme where discriminatively trained predictors like Random Forests or Convolutional Neural Networks are used to initialize local search algorithms. While these methods have been shown to produce promising results, they often get stuck in local optima. Our method goes beyond the conventional hybrid architecture by not only proposing multiple accurate initial solutions but by also defining a navigational structure over the solution space that can be used for extremely efficient gradient-free local search. We demonstrate the efficacy of our approach on the challenging problem of RGB Camera Relocalization. To make the RGB camera relocalization problem particularly challenging, we introduce a new dataset of 3D environments which are significantly larger than those found in other publicly-available datasets. Our experiments reveal that the proposed method is able to achieve state-of-the-art camera relocalization results. We also demonstrate the generalizability of our approach on Hand Pose Estimation and Image Retrieval tasks.
Efficient non-greedy optimization of decision trees
Nov 12, 2015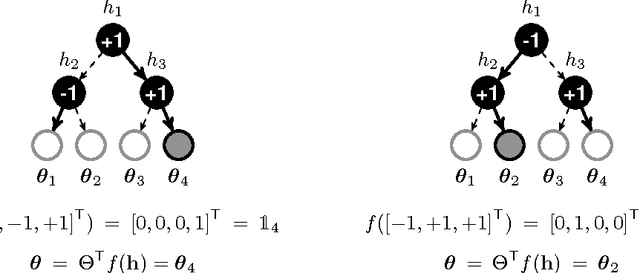
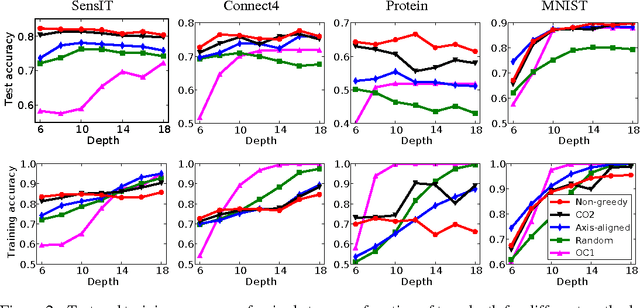
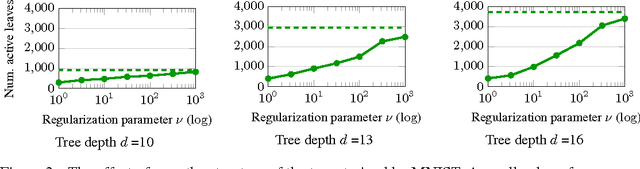
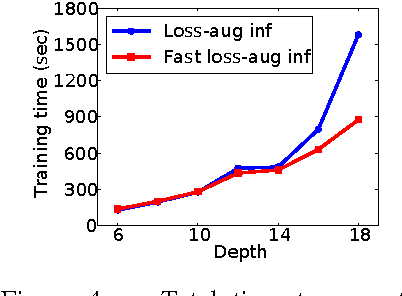
Decision trees and randomized forests are widely used in computer vision and machine learning. Standard algorithms for decision tree induction optimize the split functions one node at a time according to some splitting criteria. This greedy procedure often leads to suboptimal trees. In this paper, we present an algorithm for optimizing the split functions at all levels of the tree jointly with the leaf parameters, based on a global objective. We show that the problem of finding optimal linear-combination (oblique) splits for decision trees is related to structured prediction with latent variables, and we formulate a convex-concave upper bound on the tree's empirical loss. The run-time of computing the gradient of the proposed surrogate objective with respect to each training exemplar is quadratic in the the tree depth, and thus training deep trees is feasible. The use of stochastic gradient descent for optimization enables effective training with large datasets. Experiments on several classification benchmarks demonstrate that the resulting non-greedy decision trees outperform greedy decision tree baselines.
Learning to Hire Teams
Aug 12, 2015
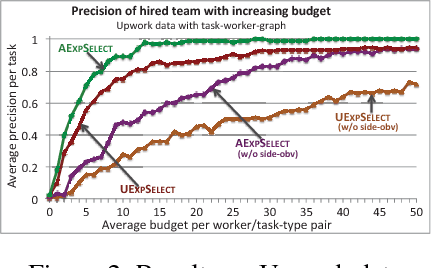
Crowdsourcing and human computation has been employed in increasingly sophisticated projects that require the solution of a heterogeneous set of tasks. We explore the challenge of building or hiring an effective team, for performing tasks required for such projects on an ongoing basis, from an available pool of applicants or workers who have bid for the tasks. The recruiter needs to learn workers' skills and expertise by performing online tests and interviews, and would like to minimize the amount of budget or time spent in this process before committing to hiring the team. How can one optimally spend budget to learn the expertise of workers as part of recruiting a team? How can one exploit the similarities among tasks as well as underlying social ties or commonalities among the workers for faster learning? We tackle these decision-theoretic challenges by casting them as an instance of online learning for best action selection. We present algorithms with PAC bounds on the required budget to hire a near-optimal team with high confidence. Furthermore, we consider an embedding of the tasks and workers in an underlying graph that may arise from task similarities or social ties, and that can provide additional side-observations for faster learning. We then quantify the improvement in the bounds that we can achieve depending on the characteristic properties of this graph structure. We evaluate our methodology on simulated problem instances as well as on real-world crowdsourcing data collected from the oDesk platform. Our methodology and results present an interesting direction of research to tackle the challenges faced by a recruiter for contract-based crowdsourcing.
CO2 Forest: Improved Random Forest by Continuous Optimization of Oblique Splits
Jun 24, 2015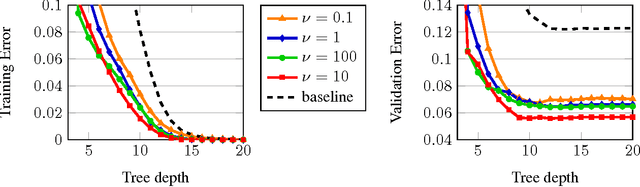
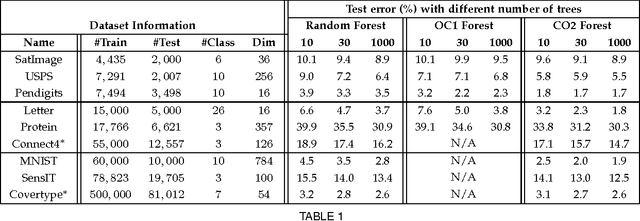
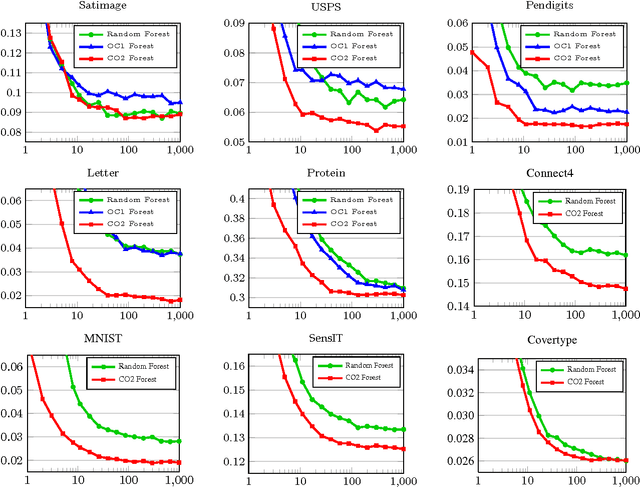

We propose a novel algorithm for optimizing multivariate linear threshold functions as split functions of decision trees to create improved Random Forest classifiers. Standard tree induction methods resort to sampling and exhaustive search to find good univariate split functions. In contrast, our method computes a linear combination of the features at each node, and optimizes the parameters of the linear combination (oblique) split functions by adopting a variant of latent variable SVM formulation. We develop a convex-concave upper bound on the classification loss for a one-level decision tree, and optimize the bound by stochastic gradient descent at each internal node of the tree. Forests of up to 1000 Continuously Optimized Oblique (CO2) decision trees are created, which significantly outperform Random Forest with univariate splits and previous techniques for constructing oblique trees. Experimental results are reported on multi-class classification benchmarks and on Labeled Faces in the Wild (LFW) dataset.
Deep Convolutional Inverse Graphics Network
Jun 22, 2015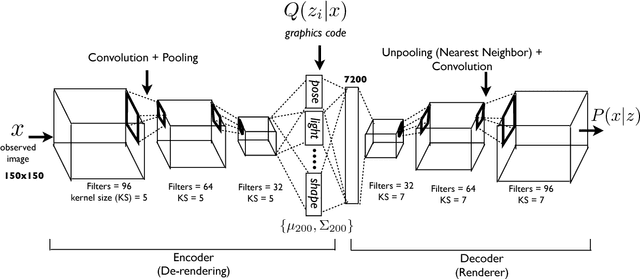

This paper presents the Deep Convolution Inverse Graphics Network (DC-IGN), a model that learns an interpretable representation of images. This representation is disentangled with respect to transformations such as out-of-plane rotations and lighting variations. The DC-IGN model is composed of multiple layers of convolution and de-convolution operators and is trained using the Stochastic Gradient Variational Bayes (SGVB) algorithm. We propose a training procedure to encourage neurons in the graphics code layer to represent a specific transformation (e.g. pose or light). Given a single input image, our model can generate new images of the same object with variations in pose and lighting. We present qualitative and quantitative results of the model's efficacy at learning a 3D rendering engine.
Information Gathering in Networks via Active Exploration
May 06, 2015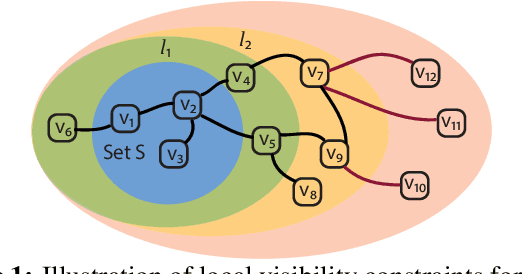
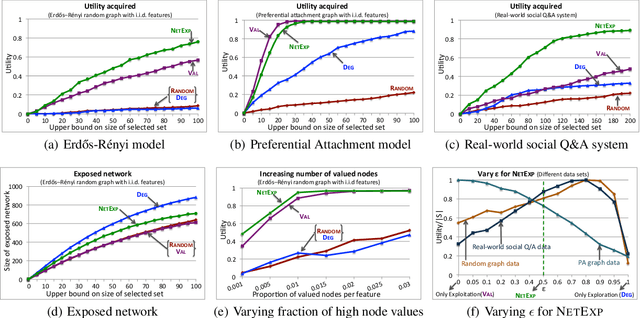
How should we gather information in a network, where each node's visibility is limited to its local neighborhood? This problem arises in numerous real-world applications, such as surveying and task routing in social networks, team formation in collaborative networks and experimental design with dependency constraints. Often the informativeness of a set of nodes can be quantified via a submodular utility function. Existing approaches for submodular optimization, however, require that the set of all nodes that can be selected is known ahead of time, which is often unrealistic. In contrast, we propose a novel model where we start our exploration from an initial node, and new nodes become visible and available for selection only once one of their neighbors has been chosen. We then present a general algorithm NetExp for this problem, and provide theoretical bounds on its performance dependent on structural properties of the underlying network. We evaluate our methodology on various simulated problem instances as well as on data collected from social question answering system deployed within a large enterprise.