 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Understanding Harmful Memes: A Survey
May 09, 2022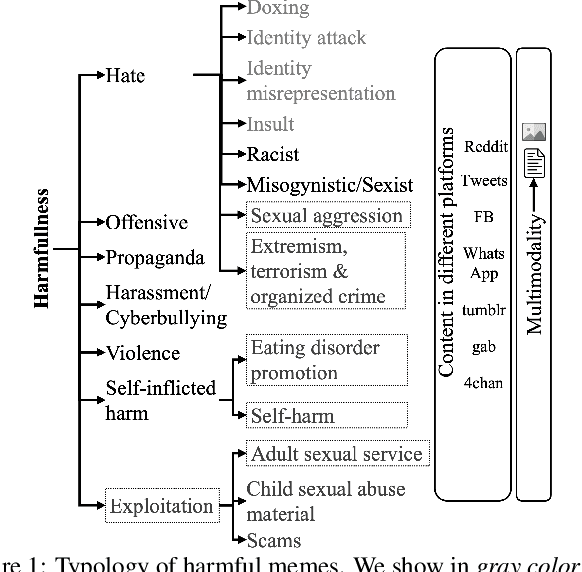
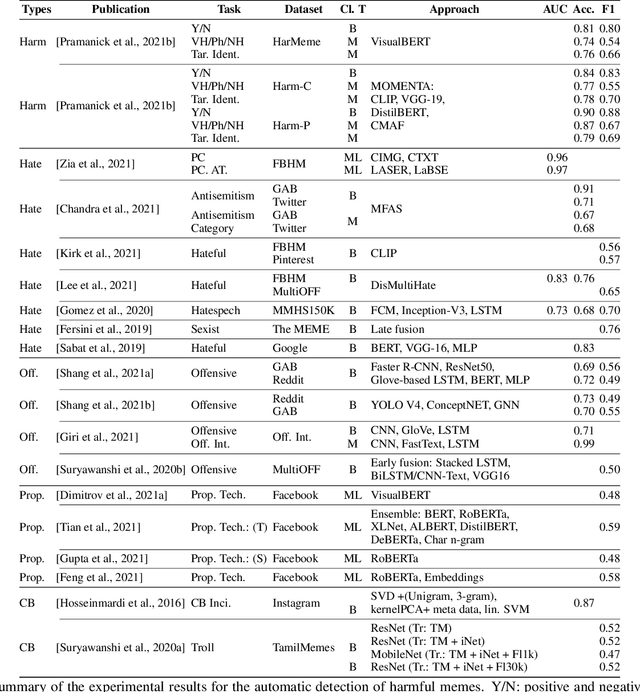

The automatic identification of harmful content online is of major concern for social media platforms, policymakers, and society. Researchers have studied textual, visual, and audio content, but typically in isolation. Yet, harmful content often combines multiple modalities, as in the case of memes, which are of particular interest due to their viral nature. With this in mind, here we offer a comprehensive survey with a focus on harmful memes. Based on a systematic analysis of recent literature, we first propose a new typology of harmful memes, and then we highlight and summarize the relevant state of the art. One interesting finding is that many types of harmful memes are not really studied, e.g., such featuring self-harm and extremism, partly due to the lack of suitable datasets. We further find that existing datasets mostly capture multi-class scenarios, which are not inclusive of the affective spectrum that memes can represent. Another observation is that memes can propagate globally through repackaging in different languages and that they can also be multilingual, blending different cultures. We conclude by highlighting several challenges related to multimodal semiotics, technological constraints and non-trivial social engagement, and we present several open-ended aspects such as delineating online harm and empirically examining related frameworks and assistive interventions, which we believe will motivate and drive future research.
Faking Fake News for Real Fake News Detection: Propaganda-loaded Training Data Generation
Mar 10, 2022
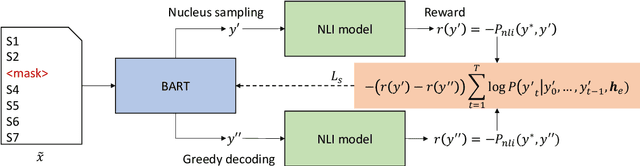
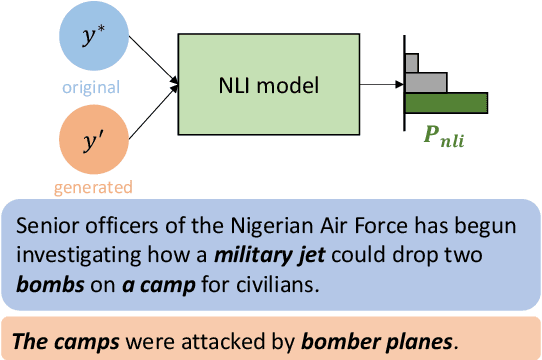

While there has been a lot of research and many recent advances in neural fake news detection, defending against human-written disinformation remains underexplored. Upon analyzing current approaches for fake news generation and human-crafted articles, we found that there is a gap between them, which can explain the poor performance on detecting human-written fake news for detectors trained on automatically generated data. To address this issue, we propose a novel framework for generating articles closer to human-written ones. Specifically, we perform self-critical sequence training with natural language inference to ensure the validity of the generated articles. We then explicitly incorporate propaganda techniques into the generated articles to mimic how humans craft fake news. Eventually, we create a fake news detection training dataset, PropaNews, which includes 2,256 examples. Our experimental results show that detectors trained on PropaNews are 7.3% to 12.0% more accurate for detecting human-written disinformation than for counterparts trained on data generated by state-of-the-art approaches.
QCRI's COVID-19 Disinformation Detector: A System to Fight the COVID-19 Infodemic in Social Media
Mar 08, 2022
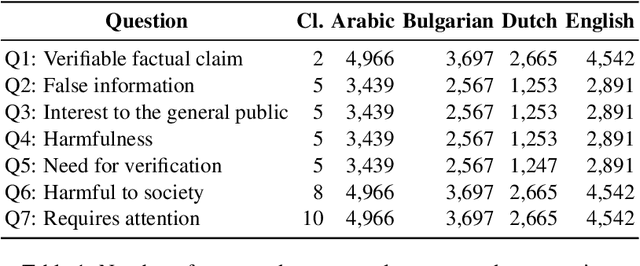
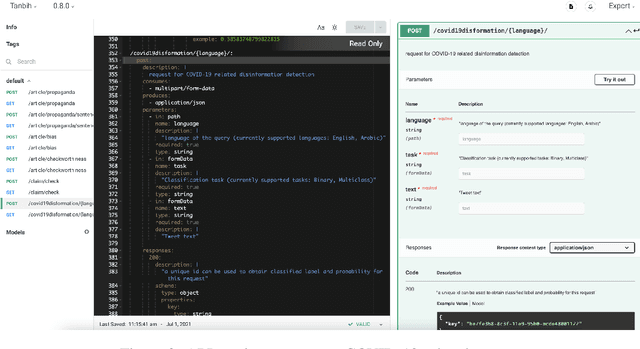
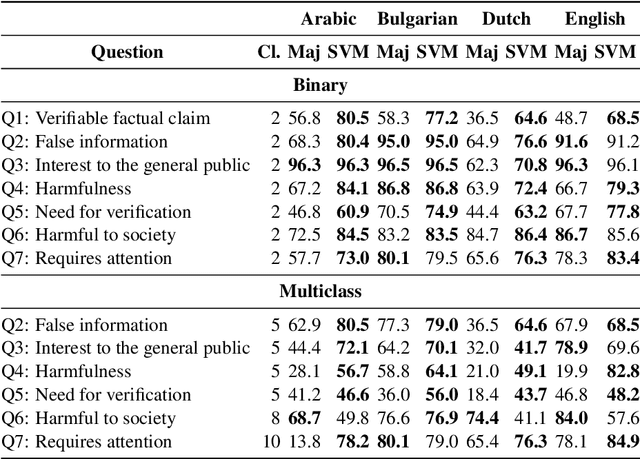
Fighting the ongoing COVID-19 infodemic has been declared as one of the most important focus areas by the World Health Organization since the onset of the COVID-19 pandemic. While the information that is consumed and disseminated consists of promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic, at the same time there is information (e.g., containing advice, promoting cure) that can help different stakeholders such as policy-makers. Social media platforms enable the infodemic and there has been an effort to curate the content on such platforms, analyze and debunk them. While a majority of the research efforts consider one or two aspects (e.g., detecting factuality) of such information, in this study we focus on a multifaceted approach, including an API,\url{https://app.swaggerhub.com/apis/yifan2019/Tanbih/0.8.0/} and a demo system,\url{https://covid19.tanbih.org}, which we made freely and publicly available. We believe that this will facilitate researchers and different stakeholders. A screencast of the API services and demo is available.\url{https://youtu.be/zhbcSvxEKMk}
Leaf: Multiple-Choice Question Generation
Jan 22, 2022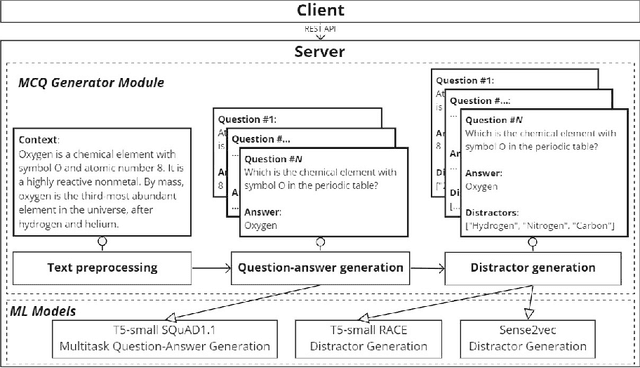
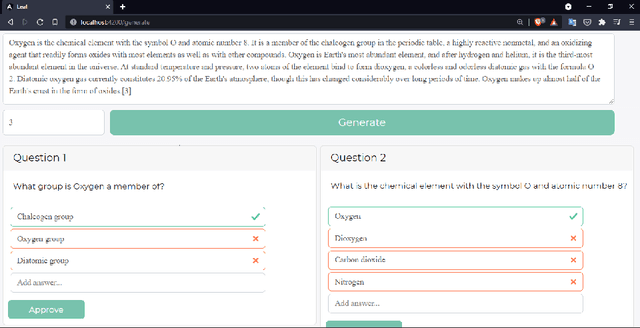
Testing with quiz questions has proven to be an effective way to assess and improve the educational process. However, manually creating quizzes is tedious and time-consuming. To address this challenge, we present Leaf, a system for generating multiple-choice questions from factual text. In addition to being very well suited for the classroom, Leaf could also be used in an industrial setting, e.g., to facilitate onboarding and knowledge sharing, or as a component of chatbots, question answering systems, or Massive Open Online Courses (MOOCs). The code and the demo are available on https://github.com/KristiyanVachev/Leaf-Question-Generation.
Batch-Softmax Contrastive Loss for Pairwise Sentence Scoring Tasks
Oct 10, 2021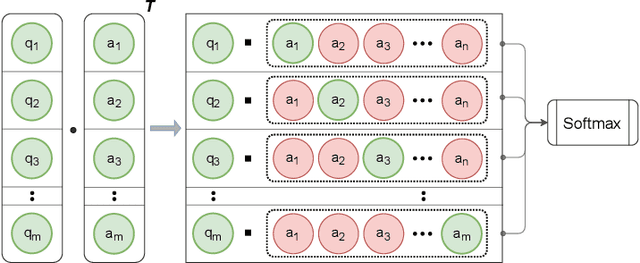
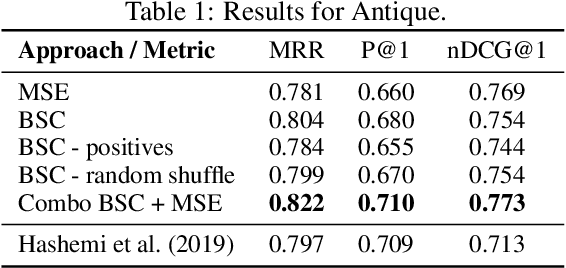
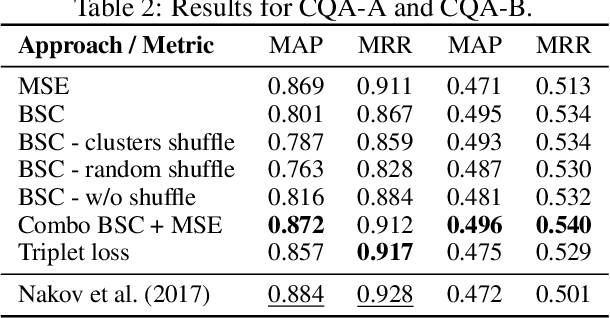
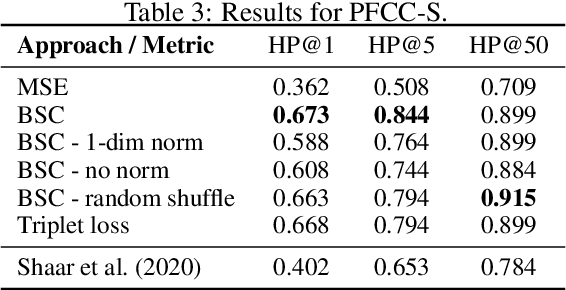
The use of contrastive loss for representation learning has become prominent in computer vision, and it is now getting attention in Natural Language Processing (NLP). Here, we explore the idea of using a batch-softmax contrastive loss when fine-tuning large-scale pre-trained transformer models to learn better task-specific sentence embeddings for pairwise sentence scoring tasks. We introduce and study a number of variations in the calculation of the loss as well as in the overall training procedure; in particular, we find that data shuffling can be quite important. Our experimental results show sizable improvements on a number of datasets and pairwise sentence scoring tasks including classification, ranking, and regression. Finally, we offer detailed analysis and discussion, which should be useful for researchers aiming to explore the utility of contrastive loss in NLP.
The Spread of Propaganda by Coordinated Communities on Social Media
Sep 27, 2021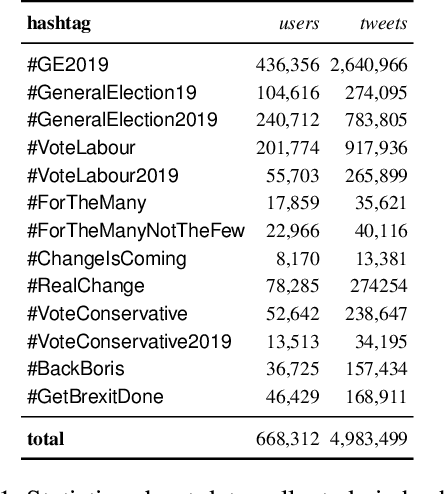
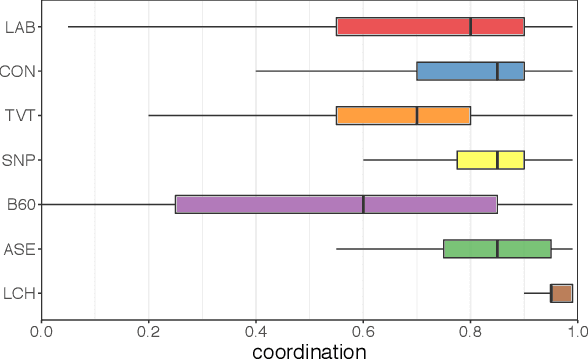
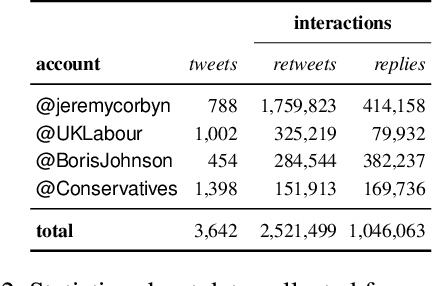
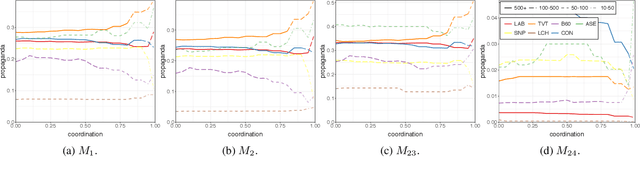
Large-scale manipulations on social media have two important characteristics: (i) use of \textit{propaganda} to influence others, and (ii) adoption of coordinated behavior to spread it and to amplify its impact. Despite the connection between them, these two characteristics have so far been considered in isolation. Here we aim to bridge this gap. In particular, we analyze the spread of propaganda and its interplay with coordinated behavior on a large Twitter dataset about the 2019 UK general election. We first propose and evaluate several metrics for measuring the use of propaganda on Twitter. Then, we investigate the use of propaganda by different coordinated communities that participated in the online debate. The combination of the use of propaganda and coordinated behavior allows us to uncover the authenticity and harmfulness of the different communities. Finally, we compare our measures of propaganda and coordination with automation (i.e., bot) scores and Twitter suspensions, revealing interesting trends. From a theoretical viewpoint, we introduce a methodology for analyzing several important dimensions of online behavior that are seldom conjointly considered. From a practical viewpoint, we provide new insights into authentic and inauthentic online activities during the 2019 UK general election.
Analyzing the Use of Character-Level Translation with Sparse and Noisy Datasets
Sep 27, 2021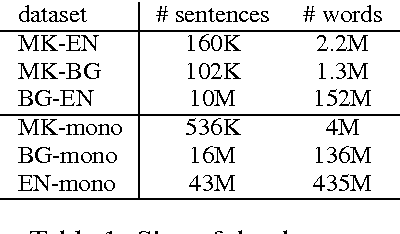
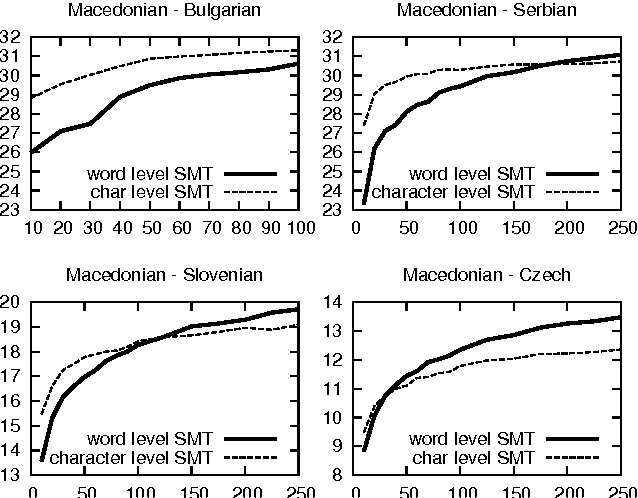
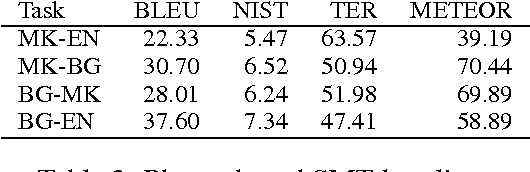
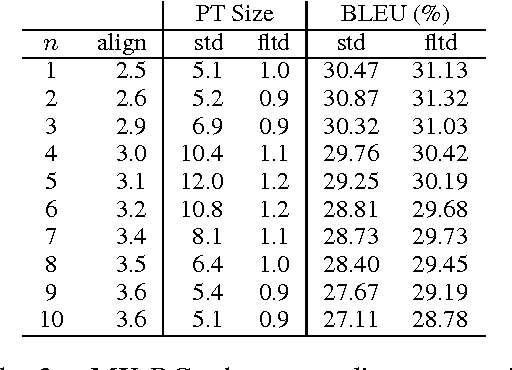
This paper provides an analysis of character-level machine translation models used in pivot-based translation when applied to sparse and noisy datasets, such as crowdsourced movie subtitles. In our experiments, we find that such character-level models cut the number of untranslated words by over 40% and are especially competitive (improvements of 2-3 BLEU points) in the case of limited training data. We explore the impact of character alignment, phrase table filtering, bitext size and the choice of pivot language on translation quality. We further compare cascaded translation models to the use of synthetic training data via multiple pivots, and we find that the latter works significantly better. Finally, we demonstrate that neither word-nor character-BLEU correlate perfectly with human judgments, due to BLEU's sensitivity to length.
* machine translation, character-level, pivoting, cascade models, character alignment, phrase table filtering
Translating from Morphologically Complex Languages: A Paraphrase-Based Approach
Sep 27, 2021We propose a novel approach to translating from a morphologically complex language. Unlike previous research, which has targeted word inflections and concatenations, we focus on the pairwise relationship between morphologically related words, which we treat as potential paraphrases and handle using paraphrasing techniques at the word, phrase, and sentence level. An important advantage of this framework is that it can cope with derivational morphology, which has so far remained largely beyond the capabilities of statistical machine translation systems. Our experiments translating from Malay, whose morphology is mostly derivational, into English show significant improvements over rivaling approaches based on five automatic evaluation measures (for 320,000 sentence pairs; 9.5 million English word tokens).
* machine translation, morphologically complex languages, paraphrases (word, phrase, and sentence level), infelctional morphology, derivational morphology, Malay, Indonesian
Sentiment Analysis in Twitter for Macedonian
Sep 27, 2021


We present work on sentiment analysis in Twitter for Macedonian. As this is pioneering work for this combination of language and genre, we created suitable resources for training and evaluating a system for sentiment analysis of Macedonian tweets. In particular, we developed a corpus of tweets annotated with tweet-level sentiment polarity (positive, negative, and neutral), as well as with phrase-level sentiment, which we made freely available for research purposes. We further bootstrapped several large-scale sentiment lexicons for Macedonian, motivated by previous work for English. The impact of several different pre-processing steps as well as of various features is shown in experiments that represent the first attempt to build a system for sentiment analysis in Twitter for the morphologically rich Macedonian language. Overall, our experimental results show an F1-score of 92.16, which is very strong and is on par with the best results for English, which were achieved in recent SemEval competitions.
* sentiment analysis, Twitter, Macedonian
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021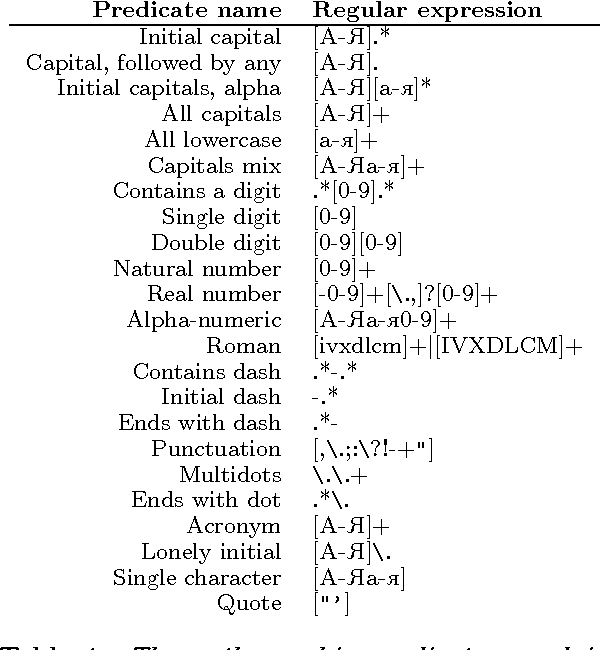

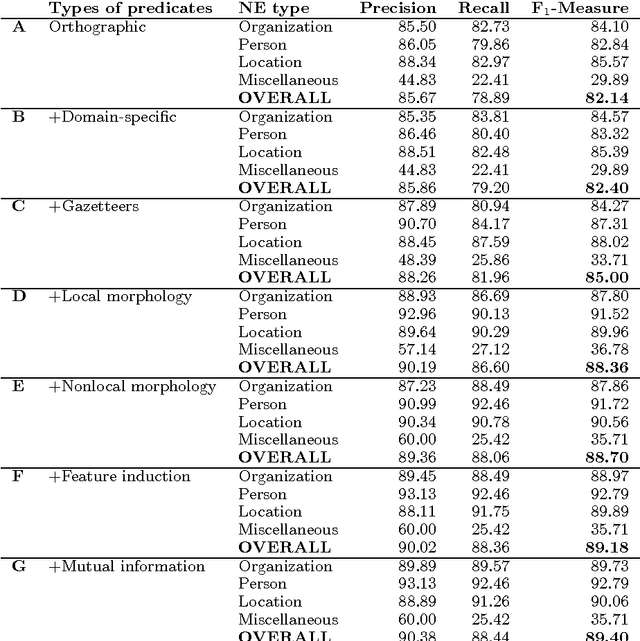
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank