 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePred-NBV: Prediction-guided Next-Best-View for 3D Object Reconstruction
Apr 22, 2023



Prediction-based active perception has shown the potential to improve the navigation efficiency and safety of the robot by anticipating the uncertainty in the unknown environment. The existing works for 3D shape prediction make an implicit assumption about the partial observations and therefore cannot be used for real-world planning and do not consider the control effort for next-best-view planning. We present Pred-NBV, a realistic object shape reconstruction method consisting of PoinTr-C, an enhanced 3D prediction model trained on the ShapeNet dataset, and an information and control effort-based next-best-view method to address these issues. Pred-NBV shows an improvement of 25.46% in object coverage over the traditional method in the AirSim simulator, and performs better shape completion than PoinTr, the state-of-the-art shape completion model, even on real data obtained from a Velodyne 3D LiDAR mounted on DJI M600 Pro.
RE-MOVE: An Adaptive Policy Design Approach for Dynamic Environments via Language-Based Feedback
Mar 14, 2023Reinforcement learning-based policies for continuous control robotic navigation tasks often fail to adapt to changes in the environment during real-time deployment, which may result in catastrophic failures. To address this limitation, we propose a novel approach called RE-MOVE (\textbf{RE}quest help and \textbf{MOVE} on), which uses language-based feedback to adjust trained policies to real-time changes in the environment. In this work, we enable the trained policy to decide \emph{when to ask for feedback} and \emph{how to incorporate feedback into trained policies}. RE-MOVE incorporates epistemic uncertainty to determine the optimal time to request feedback from humans and uses language-based feedback for real-time adaptation. We perform extensive synthetic and real-world evaluations to demonstrate the benefits of our proposed approach in several test-time dynamic navigation scenarios. Our approach enable robots to learn from human feedback and adapt to previously unseen adversarial situations.
Data-Driven Distributionally Robust Optimal Control with State-Dependent Noise
Mar 04, 2023This paper introduces innovative data-driven techniques for estimating the noise distribution and KL divergence bound for distributionally robust optimal control (DROC). The proposed approach addresses the limitation of traditional DROC approaches that require known ambiguity sets for the noise distribution, our approach can learn these distributions and bounds in real-world scenarios where they may not be known a priori. To evaluate the effectiveness of our approach, a navigation problem involving a car-like robot under different noise distributions is used as a numerical example. The results demonstrate that DROC combined with the proposed data-driven approaches, what we call D3ROC, provide robust and efficient control policies that outperform the traditional iterative linear quadratic Gaussian (iLQG) control approach. Moreover, it shows the effectiveness of our proposed approach in handling different noise distributions. Overall, the proposed approach offers a promising solution to real-world DROC problems where the noise distribution and KL divergence bounds may not be known a priori, increasing the practicality and applicability of the DROC framework.
Decision-Oriented Learning with Differentiable Submodular Maximization for Vehicle Routing Problem
Mar 02, 2023



We study the problem of learning a function that maps context observations (input) to parameters of a submodular function (output). Our motivating case study is a specific type of vehicle routing problem, in which a team of Unmanned Ground Vehicles (UGVs) can serve as mobile charging stations to recharge a team of Unmanned Ground Vehicles (UAVs) that execute persistent monitoring tasks. {We want to learn the mapping from observations of UAV task routes and wind field to the parameters of a submodular objective function, which describes the distribution of landing positions of the UAVs .} Traditionally, such a learning problem is solved independently as a prediction phase without considering the downstream task optimization phase. However, the loss function used in prediction may be misaligned with our final goal, i.e., a good routing decision. Good performance in the isolated prediction phase does not necessarily lead to good decisions in the downstream routing task. In this paper, we propose a framework that incorporates task optimization as a differentiable layer in the prediction phase. Our framework allows end-to-end training of the prediction model without using engineered intermediate loss that is targeted only at the prediction performance. In the proposed framework, task optimization (submodular maximization) is made differentiable by introducing stochastic perturbations into deterministic algorithms (i.e., stochastic smoothing). We demonstrate the efficacy of the proposed framework using synthetic data. Experimental results of the mobile charging station routing problem show that the proposed framework can result in better routing decisions, e.g. the average number of UAVs recharged increases, compared to the prediction-optimization separate approach.
Dynamically Finding Optimal Observer States to Minimize Localization Error with Complex State-Dependent Noise
Nov 30, 2022



We present DyFOS, an active perception method that Dynamically Finds Optimal States to minimize localization error while avoiding obstacles and occlusions. We consider the scenario where a ground target without any exteroceptive sensors must rely on an aerial observer for pose and uncertainty estimates to localize itself along an obstacle-filled path. The observer uses a downward-facing camera to estimate the target's pose and uncertainty. However, the pose uncertainty is a function of the states of the observer, target, and surrounding environment. To find an optimal state that minimizes the target's localization uncertainty, DyFOS uses a localization error prediction pipeline in an optimization search. Given the states mentioned above, the pipeline predicts the target's localization uncertainty with the help of a trained, complex state-dependent sensor measurement model (which is a probabilistic neural network in our case). Our pipeline also predicts target occlusion and obstacle collision to remove undesirable observer states. The output of the optimization search is an optimal observer state that minimizes target localization uncertainty while avoiding occlusion and collision. We evaluate the proposed method using numerical and simulated (Gazebo) experiments. Our results show that DyFOS is almost 100x faster than yet as good as brute force. Furthermore, DyFOS yielded lower localization errors than random and heuristic searches.
Interpretable Deep Reinforcement Learning for Green Security Games with Real-Time Information
Nov 09, 2022



Green Security Games with real-time information (GSG-I) add the real-time information about the agents' movement to the typical GSG formulation. Prior works on GSG-I have used deep reinforcement learning (DRL) to learn the best policy for the agent in such an environment without any need to store the huge number of state representations for GSG-I. However, the decision-making process of DRL methods is largely opaque, which results in a lack of trust in their predictions. To tackle this issue, we present an interpretable DRL method for GSG-I that generates visualization to explain the decisions taken by the DRL algorithm. We also show that this approach performs better and works well with a simpler training regimen compared to the existing method.
Approximation Algorithms for Robot Tours in Random Fields with Guaranteed Estimation Accuracy
Oct 14, 2022
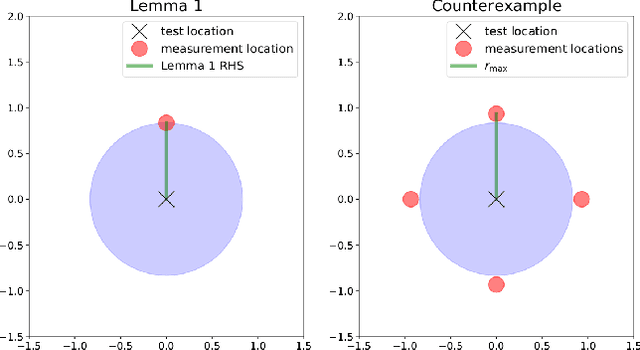
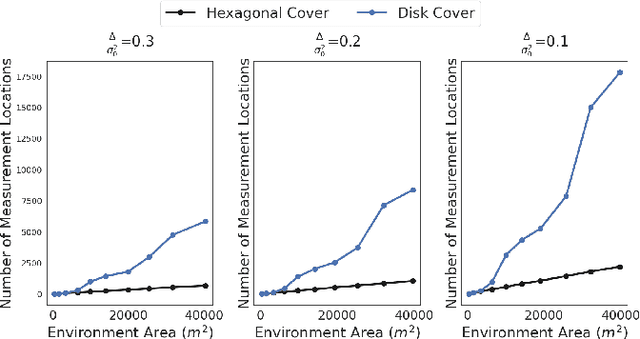
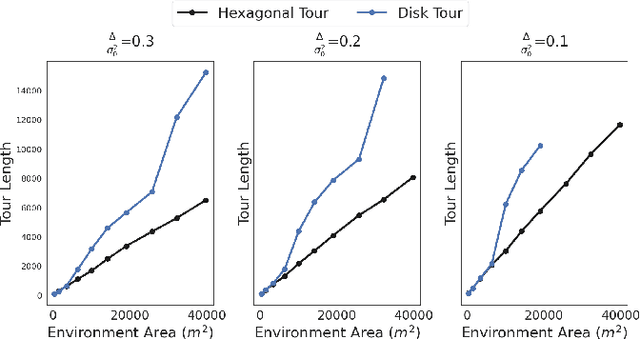
We study the sample placement and shortest tour problem for robots tasked with mapping environmental phenomena modeled as stationary random fields. The objective is to minimize the resources used (samples or tour length) while guaranteeing estimation accuracy. We give approximation algorithms for both problems in convex environments. These improve previously known results, both in terms of theoretical guarantees and in simulations. In addition, we disprove an existing claim in the literature on a lower bound for a solution to the sample placement problem.
D2CoPlan: A Differentiable Decentralized Planner for Multi-Robot Coverage
Sep 19, 2022
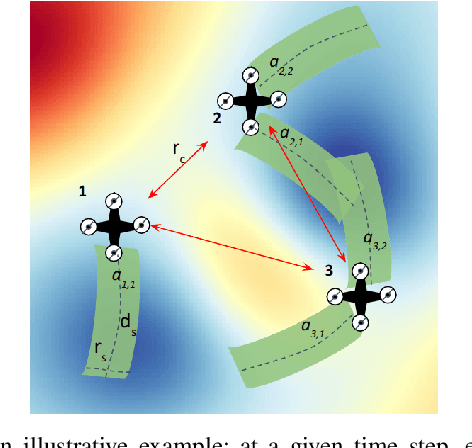
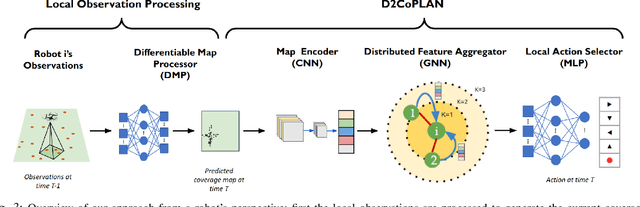
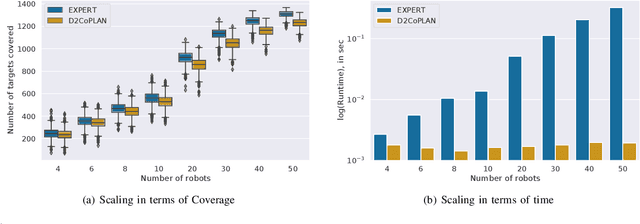
Centralized approaches for multi-robot coverage planning problems suffer from the lack of scalability. Learning-based distributed algorithms provide a scalable avenue in addition to bringing data-oriented feature generation capabilities to the table, allowing integration with other learning-based approaches. To this end, we present a learning-based, differentiable distributed coverage planner (D2COPL A N) which scales efficiently in runtime and number of agents compared to the expert algorithm, and performs on par with the classical distributed algorithm. In addition, we show that D2COPlan can be seamlessly combined with other learning methods to learn end-to-end, resulting in a better solution than the individually trained modules, opening doors to further research for tasks that remain elusive with classical methods.
Risk-aware Resource Allocation for Multiple UAVs-UGVs Recharging Rendezvous
Sep 13, 2022
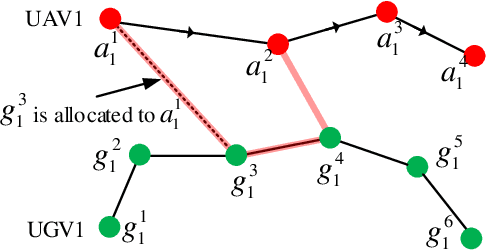
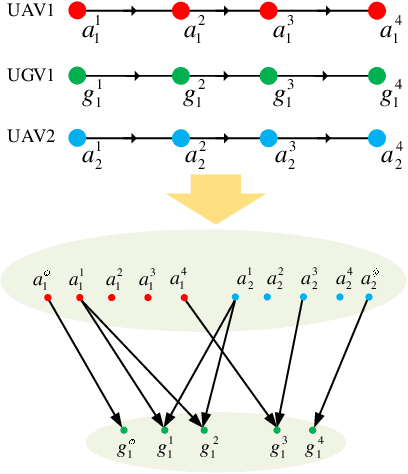
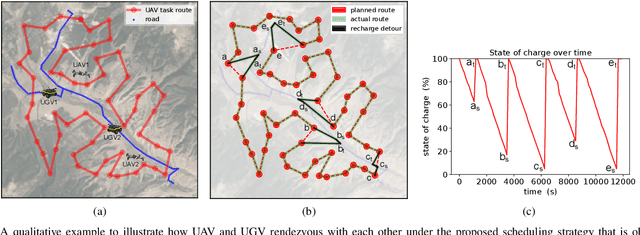
We study a resource allocation problem for the cooperative aerial-ground vehicle routing application, in which multiple Unmanned Aerial Vehicles (UAVs) with limited battery capacity and multiple Unmanned Ground Vehicles (UGVs) that can also act as a mobile recharging stations need to jointly accomplish a mission such as persistently monitoring a set of points. Due to the limited battery capacity of the UAVs, they sometimes have to deviate from their task to rendezvous with the UGVs and get recharged. Each UGV can serve a limited number of UAVs at a time. In contrast to prior work on deterministic multi-robot scheduling, we consider the challenge imposed by the stochasticity of the energy consumption of the UAV. We are interested in finding the optimal recharging schedule of the UAVs such that the travel cost is minimized and the probability that no UAV runs out of charge within the planning horizon is greater than a user-defined tolerance. We formulate this problem ({Risk-aware Recharging Rendezvous Problem (RRRP))} as an Integer Linear Program (ILP), in which the matching constraint captures the resource availability constraints and the knapsack constraint captures the success probability constraints. We propose a bicriteria approximation algorithm to solve RRRP. We demonstrate the effectiveness of our formulation and algorithm in the context of one persistent monitoring mission.
Dealing with Sparse Rewards in Continuous Control Robotics via Heavy-Tailed Policies
Jun 12, 2022
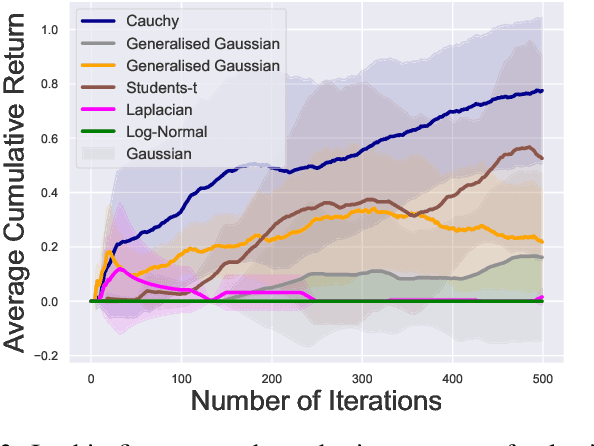
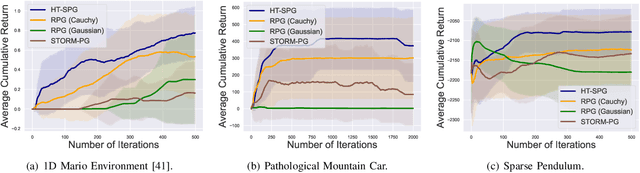
In this paper, we present a novel Heavy-Tailed Stochastic Policy Gradient (HT-PSG) algorithm to deal with the challenges of sparse rewards in continuous control problems. Sparse reward is common in continuous control robotics tasks such as manipulation and navigation, and makes the learning problem hard due to non-trivial estimation of value functions over the state space. This demands either reward shaping or expert demonstrations for the sparse reward environment. However, obtaining high-quality demonstrations is quite expensive and sometimes even impossible. We propose a heavy-tailed policy parametrization along with a modified momentum-based policy gradient tracking scheme (HT-SPG) to induce a stable exploratory behavior to the algorithm. The proposed algorithm does not require access to expert demonstrations. We test the performance of HT-SPG on various benchmark tasks of continuous control with sparse rewards such as 1D Mario, Pathological Mountain Car, Sparse Pendulum in OpenAI Gym, and Sparse MuJoCo environments (Hopper-v2). We show consistent performance improvement across all tasks in terms of high average cumulative reward. HT-SPG also demonstrates improved convergence speed with minimum samples, thereby emphasizing the sample efficiency of our proposed algorithm.