 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-robot searching with limited sensing range for static and mobile intruders
Nov 05, 2025



We consider the problem of searching for an intruder in a geometric domain by utilizing multiple search robots. The domain is a simply connected orthogonal polygon with edges parallel to the cartesian coordinate axes. Each robot has a limited sensing capability. We study the problem for both static and mobile intruders. It turns out that the problem of finding an intruder is NP-hard, even for a stationary intruder. Given this intractability, we turn our attention towards developing efficient and robust algorithms, namely methods based on space-filling curves, random search, and cooperative random search. Moreover, for each proposed algorithm, we evaluate the trade-off between the number of search robots and the time required for the robots to complete the search process while considering the geometric properties of the connected orthogonal search area.
The Persistent Robot Charging Problem for Long-Duration Autonomy
Sep 01, 2024



This paper introduces a novel formulation aimed at determining the optimal schedule for recharging a fleet of $n$ heterogeneous robots, with the primary objective of minimizing resource utilization. This study provides a foundational framework applicable to Multi-Robot Mission Planning, particularly in scenarios demanding Long-Duration Autonomy (LDA) or other contexts that necessitate periodic recharging of multiple robots. A novel Integer Linear Programming (ILP) model is proposed to calculate the optimal initial conditions (partial charge) for individual robots, leading to the minimal utilization of charging stations. This formulation was further generalized to maximize the servicing time for robots given adequate charging stations. The efficacy of the proposed formulation is evaluated through a comparative analysis, measuring its performance against the thrift price scheduling algorithm documented in the existing literature. The findings not only validate the effectiveness of the proposed approach but also underscore its potential as a valuable tool in optimizing resource allocation for a range of robotic and engineering applications.
Deep Attention Driven Reinforcement Learning (DAD-RL) for Autonomous Vehicle Decision-Making in Dynamic Environment
Jul 12, 2024



Autonomous Vehicle (AV) decision making in urban environments is inherently challenging due to the dynamic interactions with surrounding vehicles. For safe planning, AV must understand the weightage of various spatiotemporal interactions in a scene. Contemporary works use colossal transformer architectures to encode interactions mainly for trajectory prediction, resulting in increased computational complexity. To address this issue without compromising spatiotemporal understanding and performance, we propose the simple Deep Attention Driven Reinforcement Learning (DADRL) framework, which dynamically assigns and incorporates the significance of surrounding vehicles into the ego's RL driven decision making process. We introduce an AV centric spatiotemporal attention encoding (STAE) mechanism for learning the dynamic interactions with different surrounding vehicles. To understand map and route context, we employ a context encoder to extract features from context maps. The spatiotemporal representations combined with contextual encoding provide a comprehensive state representation. The resulting model is trained using the Soft Actor Critic (SAC) algorithm. We evaluate the proposed framework on the SMARTS urban benchmarking scenarios without traffic signals to demonstrate that DADRL outperforms recent state of the art methods. Furthermore, an ablation study underscores the importance of the context-encoder and spatio temporal attention encoder in achieving superior performance.
Learning Cost-maps Made Easy
Sep 26, 2022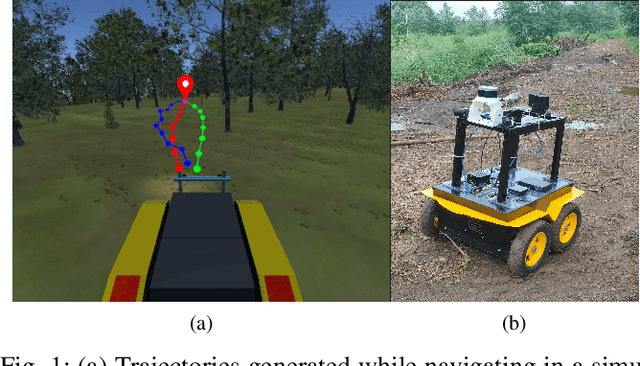
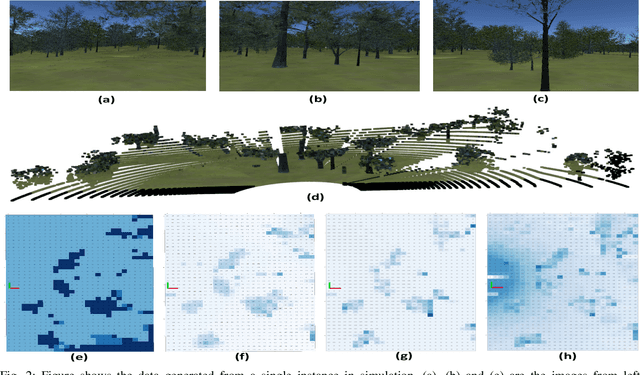
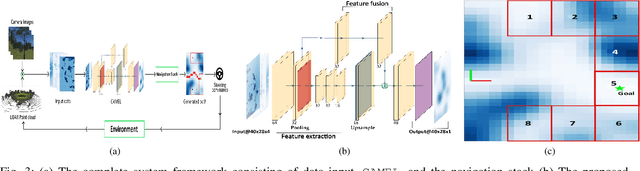
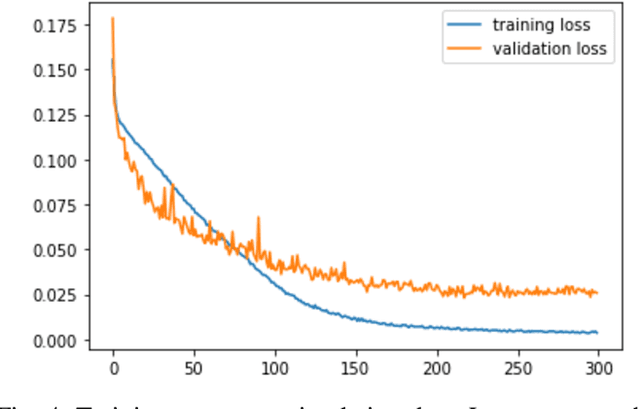
Cost-maps are used by robotic vehicles to plan collision-free paths. The cost associated with each cell in the map represents the sensed environment information which is often determined manually after several trial-and-error efforts. In off-road environments, due to the presence of several types of features, it is challenging to handcraft the cost values associated with each feature. Moreover, different handcrafted cost values can lead to different paths for the same environment which is not desirable. In this paper, we address the problem of learning the cost-map values from the sensed environment for robust vehicle path planning. We propose a novel framework called as CAMEL using deep learning approach that learns the parameters through demonstrations yielding an adaptive and robust cost-map for path planning. CAMEL has been trained on multi-modal datasets such as RELLIS-3D. The evaluation of CAMEL is carried out on an off-road scene simulator (MAVS) and on field data from IISER-B campus. We also perform realworld implementation of CAMEL on a ground rover. The results shows flexible and robust motion of the vehicle without collisions in unstructured terrains.
Multi-AAV Cooperative Path Planning using Nonlinear Model Predictive Control with Localization Constraints
Jan 23, 2022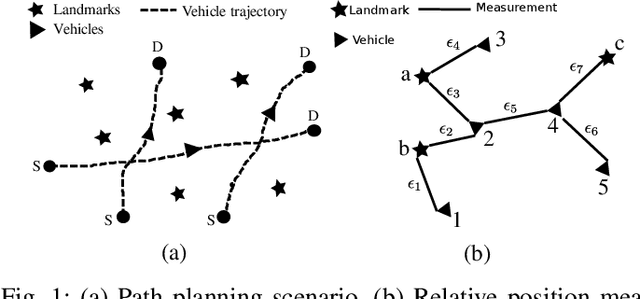
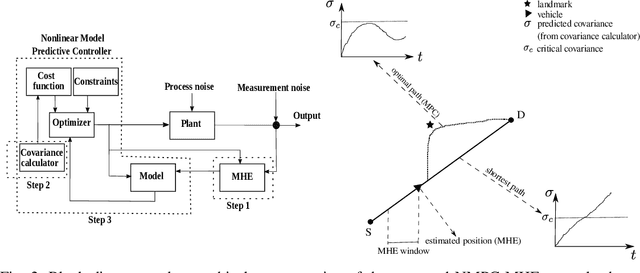
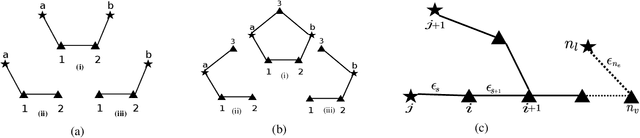
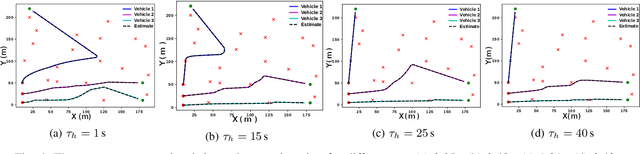
In this paper, we solve a joint cooperative localization and path planning problem for a group of Autonomous Aerial Vehicles (AAVs) in GPS-denied areas using nonlinear model predictive control (NMPC). A moving horizon estimator (MHE) is used to estimate the vehicle states with the help of relative bearing information to known landmarks and other vehicles. The goal of the NMPC is to devise optimal paths for each vehicle between a given source and destination while maintaining desired localization accuracy. Estimating localization covariance in the NMPC is computationally intensive, hence we develop an approximate analytical closed form expression based on the relationship between covariance and path lengths to landmarks. Using this expression while computing NMPC commands reduces the computational complexity significantly. We present numerical simulations to validate the proposed approach for different numbers of vehicles and landmark configurations. We also compare the results with EKF-based estimation to show the superiority of the proposed closed form approach.
Learning Estimates At The Edge Using Intermittent And Aged Measurement Updates
Jan 20, 2022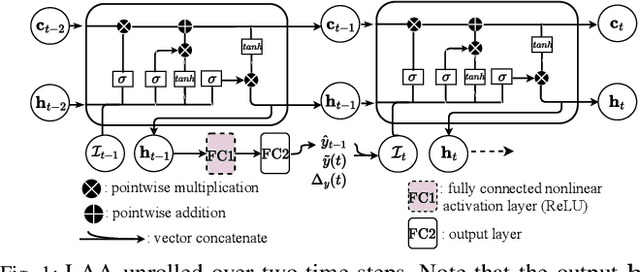
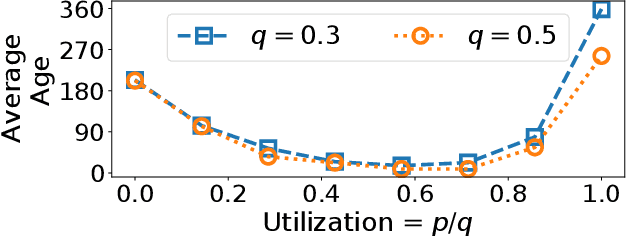
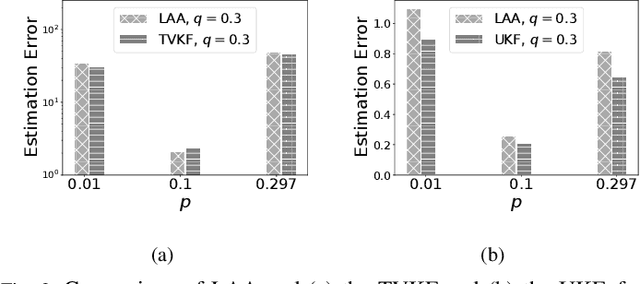
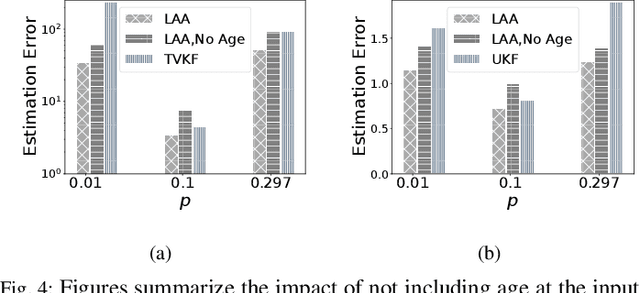
Cyber Physical Systems (CPS) applications have agents that actuate in their local vicinity, while requiring measurements that capture the state of their larger environment to make actuation choices. These measurements are made by sensors and communicated over a network as update packets. Network resource constraints dictate that updates arrive at an agent intermittently and be aged on their arrival. This can be alleviated by providing an agent with a fast enough rate of estimates of the measurements. Often works on estimation assume knowledge of the dynamic model of the system being measured. However, as CPS applications become pervasive, such information may not be available in practice. In this work, we propose a novel deep neural network architecture that leverages Long Short Term Memory (LSTM) networks to learn estimates in a model-free setting using only updates received over the network. We detail an online algorithm that enables training of our architecture. The architecture is shown to provide good estimates of measurements of both a linear and a non-linear dynamic system. It learns good estimates even when the learning proceeds over a generic network setting in which the distributions that govern the rate and age of received measurements may change significantly over time. We demonstrate the efficacy of the architecture by comparing it with the baselines of the Time-varying Kalman Filter and the Unscented Kalman Filter. The architecture enables empirical insights with regards to maintaining the ages of updates at the estimator, which are used by it and also the baselines.
A Model-free Deep Reinforcement Learning Approach To Maneuver A Quadrotor Despite Single Rotor Failure
Sep 22, 2021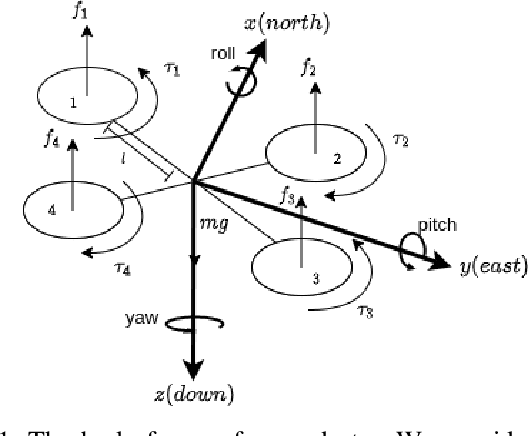
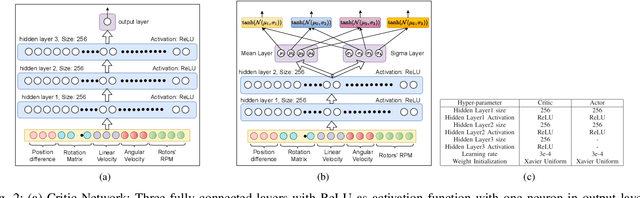
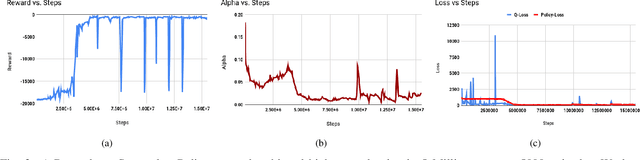
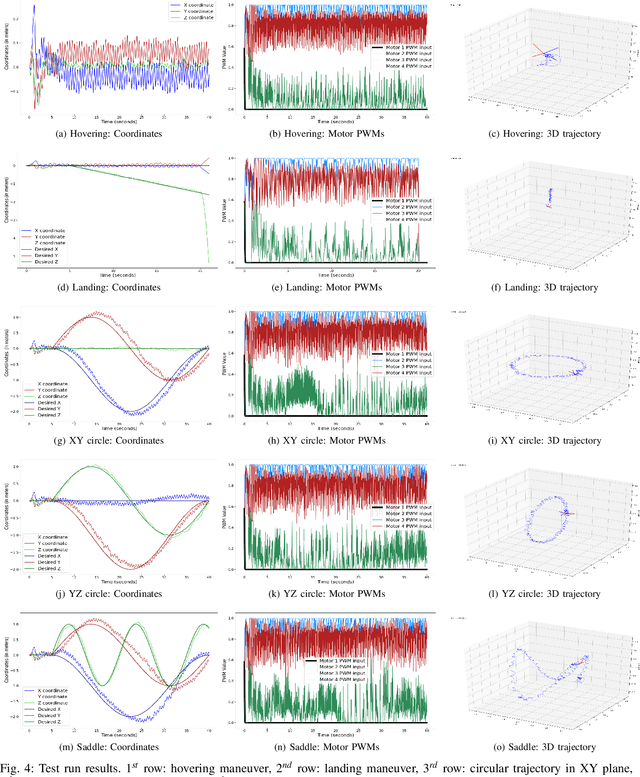
Ability to recover from faults and continue mission is desirable for many quadrotor applications. The quadrotor's rotor may fail while performing a mission and it is essential to develop recovery strategies so that the vehicle is not damaged. In this paper, we develop a model-free deep reinforcement learning approach for a quadrotor to recover from a single rotor failure. The approach is based on Soft-actor-critic that enables the vehicle to hover, land, and perform complex maneuvers. Simulation results are presented to validate the proposed approach using a custom simulator. The results show that the proposed approach achieves hover, landing, and path following in 2D and 3D. We also show that the proposed approach is robust to wind disturbances.
GALOPP: Multi-Agent Deep Reinforcement Learning For Persistent Monitoring With Localization Constraints
Sep 22, 2021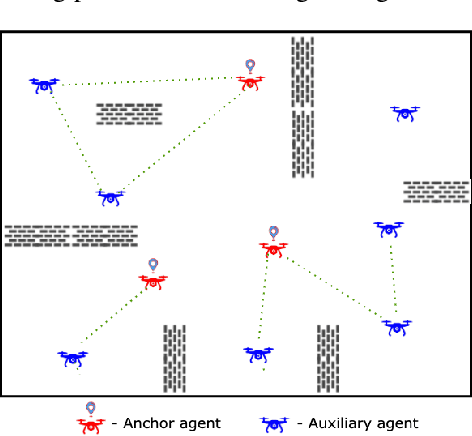
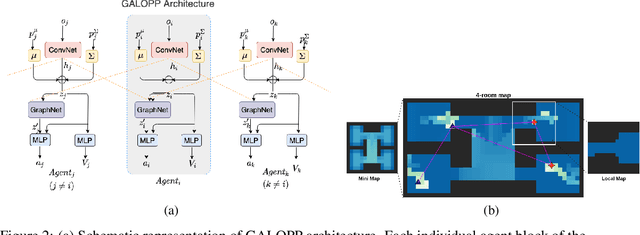
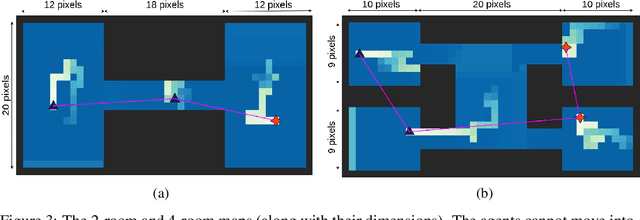
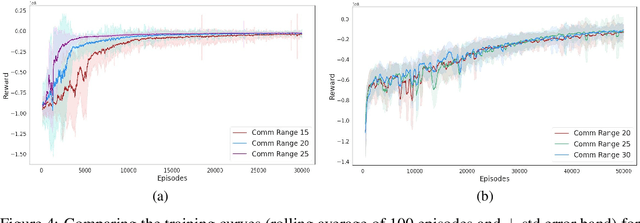
Persistently monitoring a region under localization and communication constraints is a challenging problem. In this paper, we consider a heterogenous robotic system consisting of two types of agents -- anchor agents that have accurate localization capability, and auxiliary agents that have low localization accuracy. The auxiliary agents must be within the communication range of an {anchor}, directly or indirectly to localize itself. The objective of the robotic team is to minimize the uncertainty in the environment through persistent monitoring. We propose a multi-agent deep reinforcement learning (MADRL) based architecture with graph attention called Graph Localized Proximal Policy Optimization (GALLOP), which incorporates the localization and communication constraints of the agents along with persistent monitoring objective to determine motion policies for each agent. We evaluate the performance of GALLOP on three different custom-built environments. The results show the agents are able to learn a stable policy and outperform greedy and random search baseline approaches.
OffRoadTranSeg: Semi-Supervised Segmentation using Transformers on OffRoad environments
Jun 26, 2021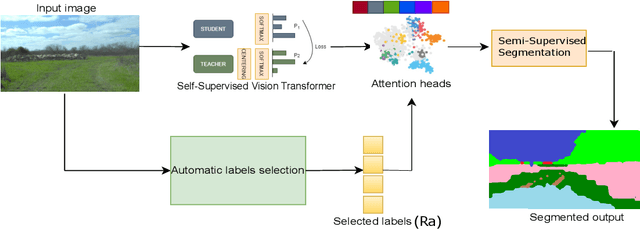
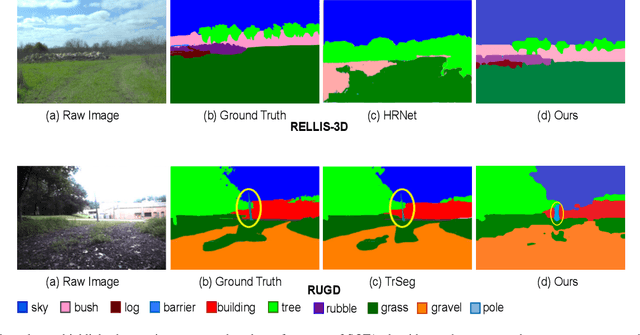
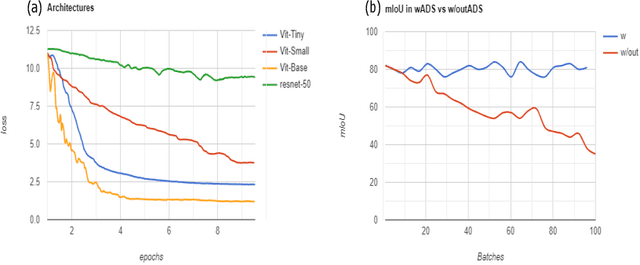
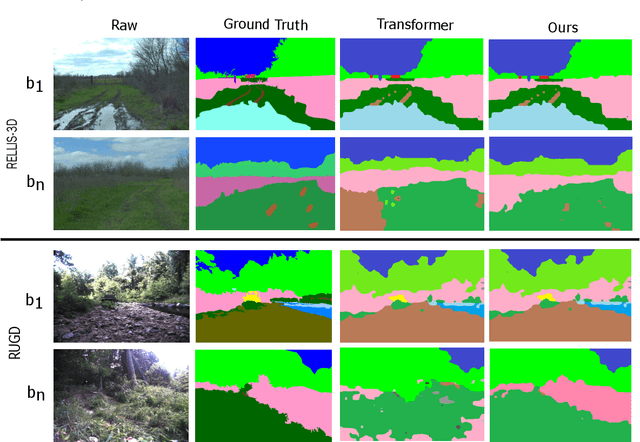
We present OffRoadTranSeg, the first end-to-end framework for semi-supervised segmentation in unstructured outdoor environment using transformers and automatic data selection for labelling. The offroad segmentation is a scene understanding approach that is widely used in autonomous driving. The popular offroad segmentation method is to use fully connected convolution layers and large labelled data, however, due to class imbalance, there will be several mismatches and also some classes may not be detected. Our approach is to do the task of offroad segmentation in a semi-supervised manner. The aim is to provide a model where self supervised vision transformer is used to fine-tune offroad datasets with self-supervised data collection for labelling using depth estimation. The proposed method is validated on RELLIS-3D and RUGD offroad datasets. The experiments show that OffRoadTranSeg outperformed other state of the art models, and also solves the RELLIS-3D class imbalance problem.
Target-Following Double Deep Q-Networks for UAVs
May 12, 2021
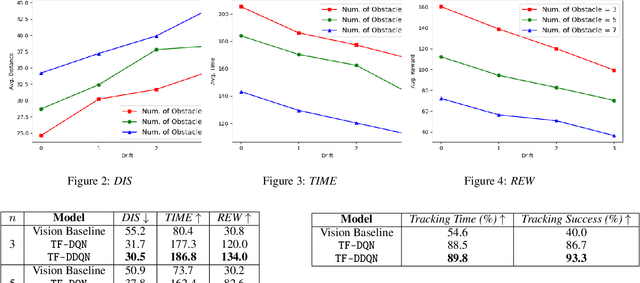


Target tracking in unknown real-world environments in the presence of obstacles and target motion uncertainty demand agents to develop an intrinsic understanding of the environment in order to predict the suitable actions to be taken at each time step. This task requires the agents to maximize the visibility of the mobile target maneuvering randomly in a network of roads by learning a policy that takes into consideration the various aspects of a real-world environment. In this paper, we propose a DDQN-based extension to the state-of-the-art in target tracking using a UAV TF-DQN, that we call TF-DDQN, that isolates the value estimation and evaluation steps. Additionally, in order to carefully benchmark the performance of any given target tracking algorithm, we introduce a novel target tracking evaluation scheme that quantifies its efficacy in terms of a wide set of diverse parameters. To replicate the real-world setting, we test our approach against standard baselines for the task of target tracking in complex environments with varying drift conditions and changes in environmental configuration.