 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing the Problem of Side Effect Regularization
Jun 24, 2022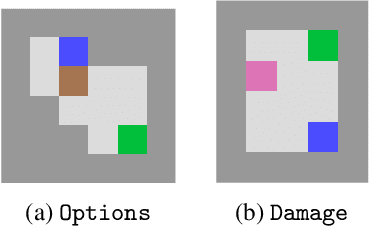
AI objectives are often hard to specify properly. Some approaches tackle this problem by regularizing the AI's side effects: Agents must weigh off "how much of a mess they make" with an imperfectly specified proxy objective. We propose a formal criterion for side effect regularization via the assistance game framework. In these games, the agent solves a partially observable Markov decision process (POMDP) representing its uncertainty about the objective function it should optimize. We consider the setting where the true objective is revealed to the agent at a later time step. We show that this POMDP is solved by trading off the proxy reward with the agent's ability to achieve a range of future tasks. We empirically demonstrate the reasonableness of our problem formalization via ground-truth evaluation in two gridworld environments.
Explainable Models via Compression of Tree Ensembles
Jun 16, 2022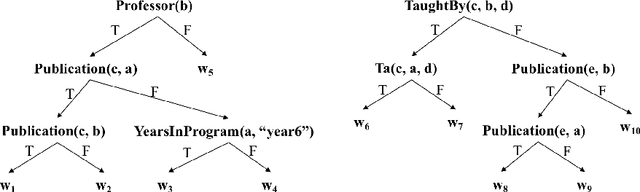
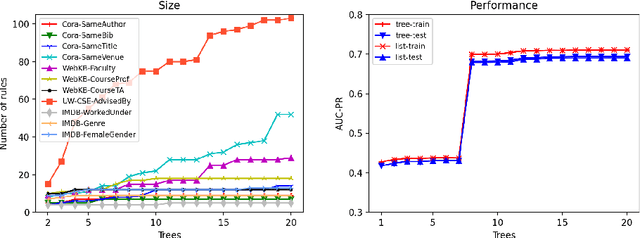
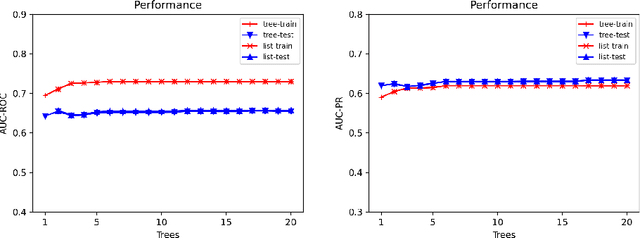
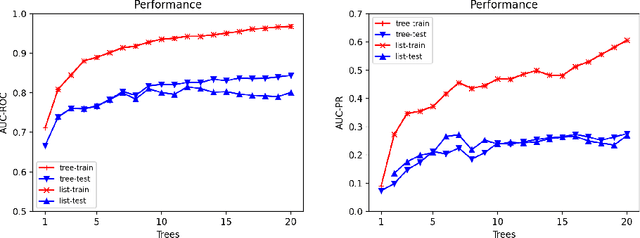
Ensemble models (bagging and gradient-boosting) of relational decision trees have proved to be one of the most effective learning methods in the area of probabilistic logic models (PLMs). While effective, they lose one of the most important aspect of PLMs -- interpretability. In this paper we consider the problem of compressing a large set of learned trees into a single explainable model. To this effect, we propose CoTE -- Compression of Tree Ensembles -- that produces a single small decision list as a compressed representation. CoTE first converts the trees to decision lists and then performs the combination and compression with the aid of the original training set. An experimental evaluation demonstrates the effectiveness of CoTE in several benchmark relational data sets.
Dynamic probabilistic logic models for effective abstractions in RL
Oct 15, 2021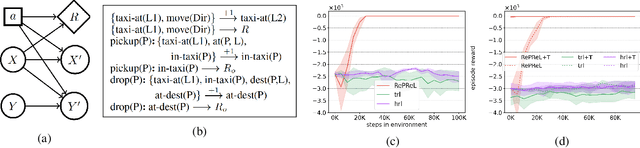
State abstraction enables sample-efficient learning and better task transfer in complex reinforcement learning environments. Recently, we proposed RePReL (Kokel et al. 2021), a hierarchical framework that leverages a relational planner to provide useful state abstractions for learning. We present a brief overview of this framework and the use of a dynamic probabilistic logic model to design these state abstractions. Our experiments show that RePReL not only achieves better performance and efficient learning on the task at hand but also demonstrates better generalization to unseen tasks.
From Heatmaps to Structural Explanations of Image Classifiers
Sep 13, 2021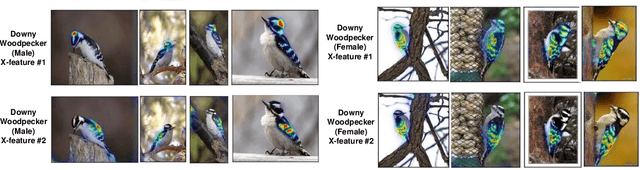
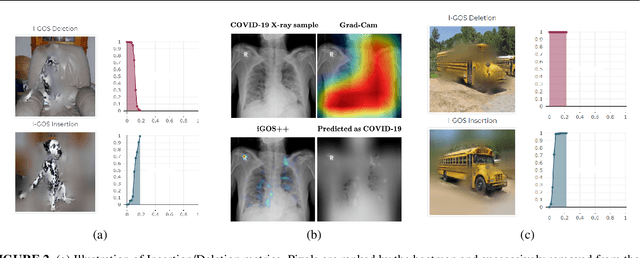

This paper summarizes our endeavors in the past few years in terms of explaining image classifiers, with the aim of including negative results and insights we have gained. The paper starts with describing the explainable neural network (XNN), which attempts to extract and visualize several high-level concepts purely from the deep network, without relying on human linguistic concepts. This helps users understand network classifications that are less intuitive and substantially improves user performance on a difficult fine-grained classification task of discriminating among different species of seagulls. Realizing that an important missing piece is a reliable heatmap visualization tool, we have developed I-GOS and iGOS++ utilizing integrated gradients to avoid local optima in heatmap generation, which improved the performance across all resolutions. During the development of those visualizations, we realized that for a significant number of images, the classifier has multiple different paths to reach a confident prediction. This has lead to our recent development of structured attention graphs (SAGs), an approach that utilizes beam search to locate multiple coarse heatmaps for a single image, and compactly visualizes a set of heatmaps by capturing how different combinations of image regions impact the confidence of a classifier. Through the research process, we have learned much about insights in building deep network explanations, the existence and frequency of multiple explanations, and various tricks of the trade that make explanations work. In this paper, we attempt to share those insights and opinions with the readers with the hope that some of them will be informative for future researchers on explainable deep learning.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021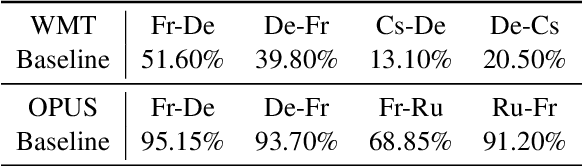
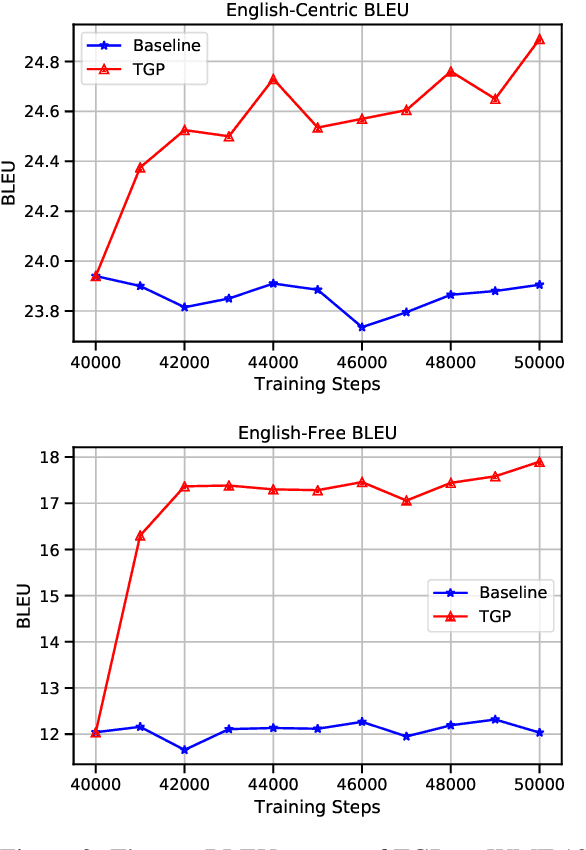
Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
Structured Attention Graphs for Understanding Deep Image Classifications
Dec 08, 2020

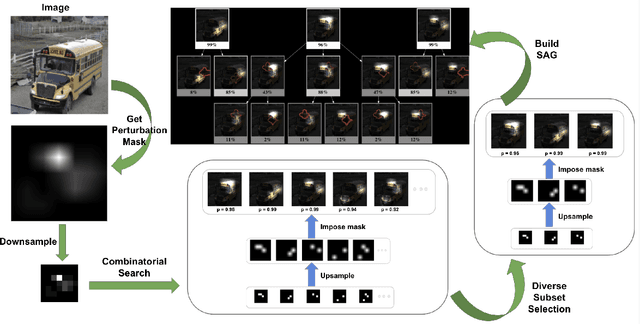

Attention maps are a popular way of explaining the decisions of convolutional networks for image classification. Typically, for each image of interest, a single attention map is produced, which assigns weights to pixels based on their importance to the classification. A single attention map, however, provides an incomplete understanding since there are often many other maps that explain a classification equally well. In this paper, we introduce structured attention graphs (SAGs), which compactly represent sets of attention maps for an image by capturing how different combinations of image regions impact a classifier's confidence. We propose an approach to compute SAGs and a visualization for SAGs so that deeper insight can be gained into a classifier's decisions. We conduct a user study comparing the use of SAGs to traditional attention maps for answering counterfactual questions about image classifications. Our results show that the users are more correct when answering comparative counterfactual questions based on SAGs compared to the baselines.
DeepAveragers: Offline Reinforcement Learning by Solving Derived Non-Parametric MDPs
Oct 18, 2020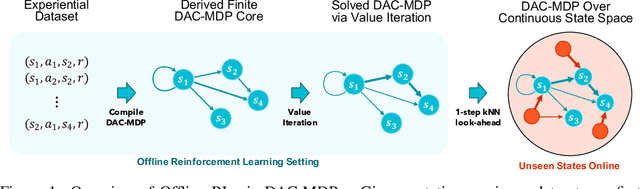

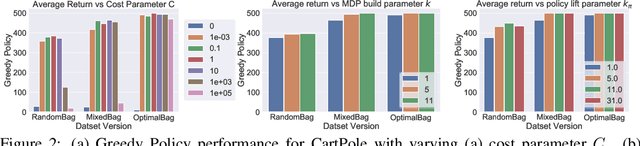
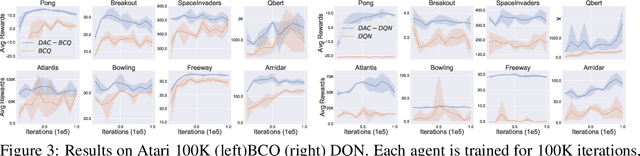
We study an approach to offline reinforcement learning (RL) based on optimally solving finitely-represented MDPs derived from a static dataset of experience. This approach can be applied on top of any learned representation and has the potential to easily support multiple solution objectives as well as zero-shot adjustment to changing environments and goals. Our main contribution is to introduce the Deep Averagers with Costs MDP (DAC-MDP) and to investigate its solutions for offline RL. DAC-MDPs are a non-parametric model that can leverage deep representations and account for limited data by introducing costs for exploiting under-represented parts of the model. In theory, we show conditions that allow for lower-bounding the performance of DAC-MDP solutions. We also investigate the empirical behavior in a number of environments, including those with image-based observations. Overall, the experiments demonstrate that the framework can work in practice and scale to large complex offline RL problems.
On the Sub-Layer Functionalities of Transformer Decoder
Oct 06, 2020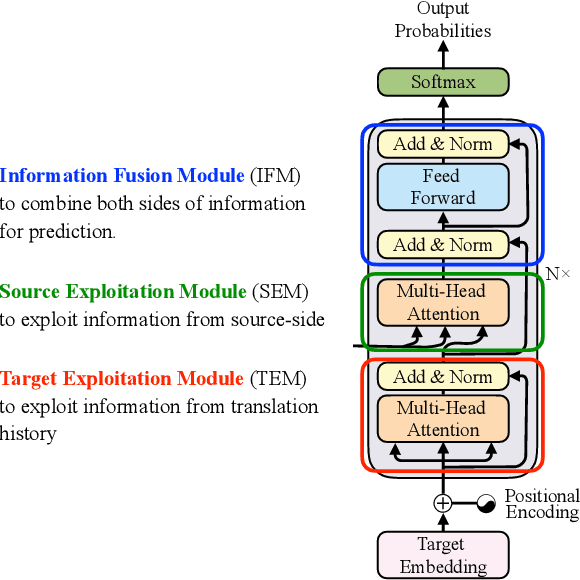
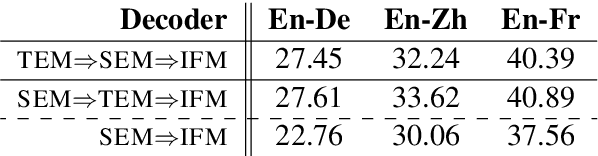
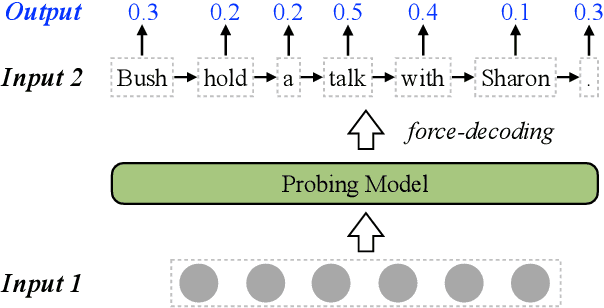
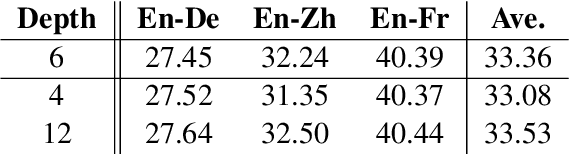
There have been significant efforts to interpret the encoder of Transformer-based encoder-decoder architectures for neural machine translation (NMT); meanwhile, the decoder remains largely unexamined despite its critical role. During translation, the decoder must predict output tokens by considering both the source-language text from the encoder and the target-language prefix produced in previous steps. In this work, we study how Transformer-based decoders leverage information from the source and target languages -- developing a universal probe task to assess how information is propagated through each module of each decoder layer. We perform extensive experiments on three major translation datasets (WMT En-De, En-Fr, and En-Zh). Our analysis provides insight on when and where decoders leverage different sources. Based on these insights, we demonstrate that the residual feed-forward module in each Transformer decoder layer can be dropped with minimal loss of performance -- a significant reduction in computation and number of parameters, and consequently a significant boost to both training and inference speed.
Avoiding Side Effects in Complex Environments
Jun 11, 2020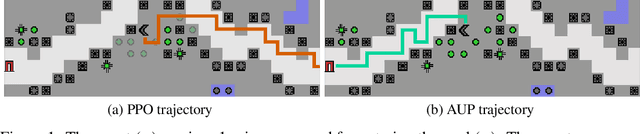


Reward function specification can be difficult, even in simple environments. Realistic environments contain millions of states. Rewarding the agent for making a widget may be easy, but penalizing the multitude of possible negative side effects is hard. In toy environments, Attainable Utility Preservation (AUP) avoids side effects by penalizing shifts in the ability to achieve randomly generated goals. We scale this approach to large, randomly generated environments based on Conway's Game of Life. By preserving optimal value for a single randomly generated reward function, AUP incurs modest overhead, completes the specified task, and avoids side effects.
The Choice Function Framework for Online Policy Improvement
Oct 07, 2019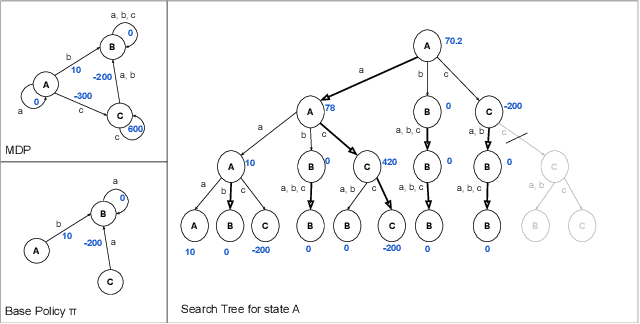
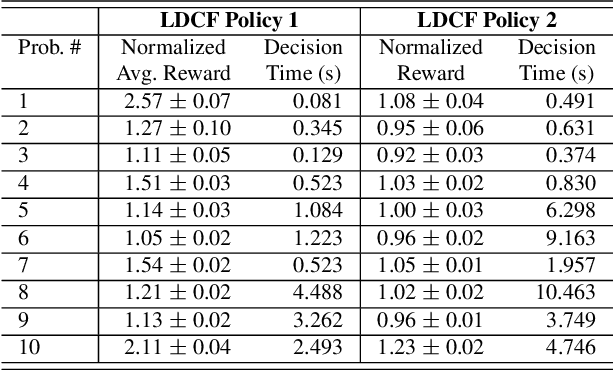
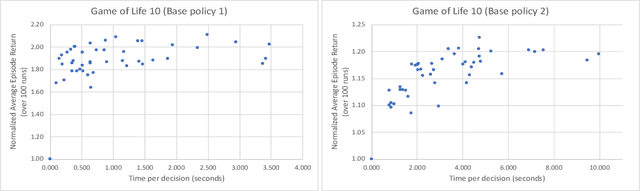
There are notable examples of online search improving over hand-coded or learned policies (e.g. AlphaZero) for sequential decision making. It is not clear, however, whether or not policy improvement is guaranteed for many of these approaches, even when given a perfect evaluation function and transition model. Indeed, simple counter examples show that seemingly reasonable online search procedures can hurt performance compared to the original policy. To address this issue, we introduce the choice function framework for analyzing online search procedures for policy improvement. A choice function specifies the actions to be considered at every node of a search tree, with all other actions being pruned. Our main contribution is to give sufficient conditions for stationary and non-stationary choice functions to guarantee that the value achieved by online search is no worse than the original policy. In addition, we describe a general parametric class of choice functions that satisfy those conditions and present an illustrative use case of the framework's empirical utility.