 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-aware ELMo: Learning Contextual Entity Representation for Entity Disambiguation
Aug 22, 2019

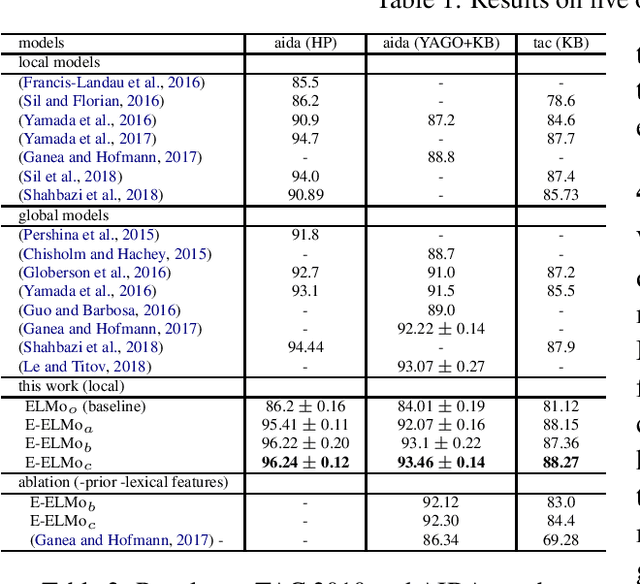
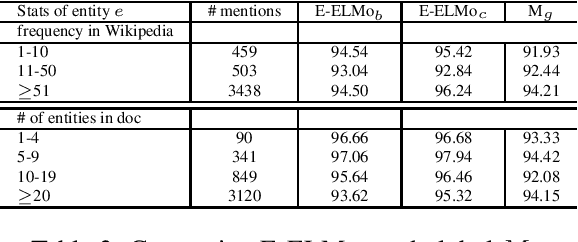
We present a new local entity disambiguation system. The key to our system is a novel approach for learning entity representations. In our approach we learn an entity aware extension of Embedding for Language Model (ELMo) which we call Entity-ELMo (E-ELMo). Given a paragraph containing one or more named entity mentions, each mention is first defined as a function of the entire paragraph (including other mentions), then they predict the referent entities. Utilizing E-ELMo for local entity disambiguation, we outperform all of the state-of-the-art local and global models on the popular benchmarks by improving about 0.5\% on micro average accuracy for AIDA test-b with Yago candidate set. The evaluation setup of the training data and candidate set are the same as our baselines for fair comparison.
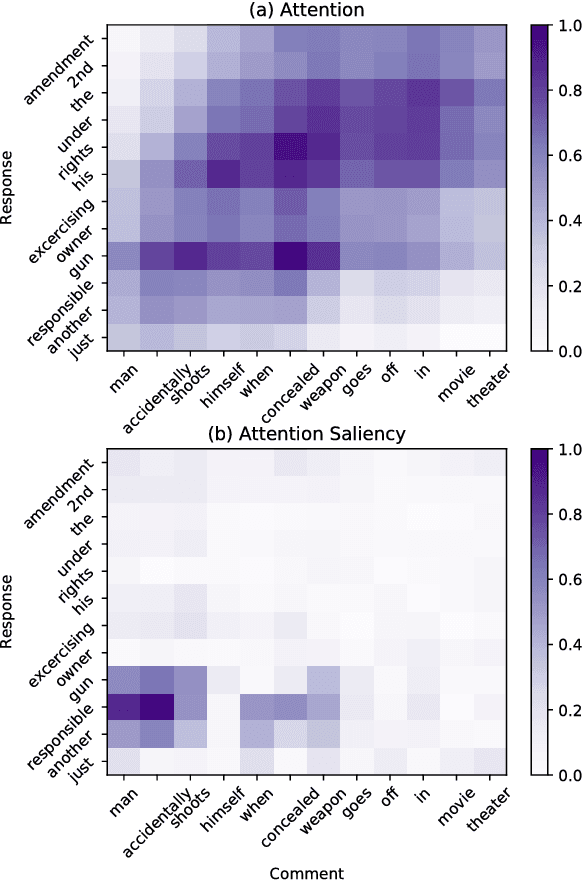
Saliency Learning: Teaching the Model Where to Pay Attention
Apr 04, 2019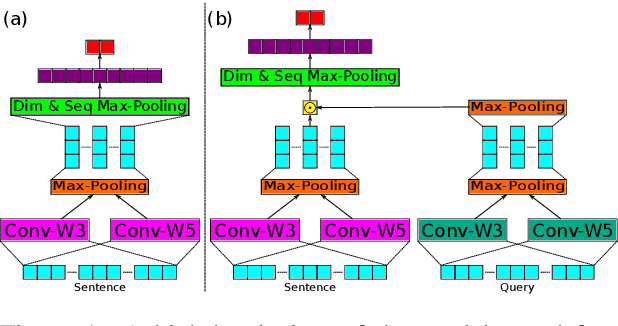
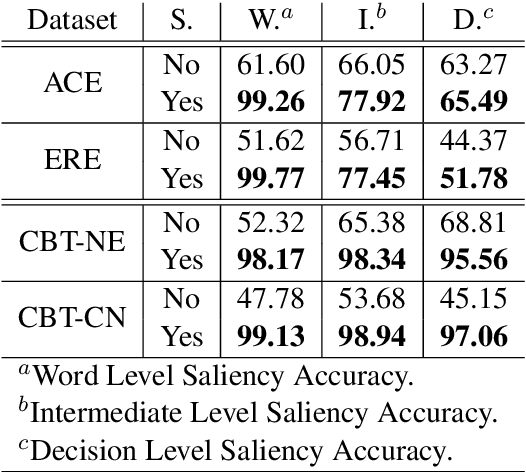
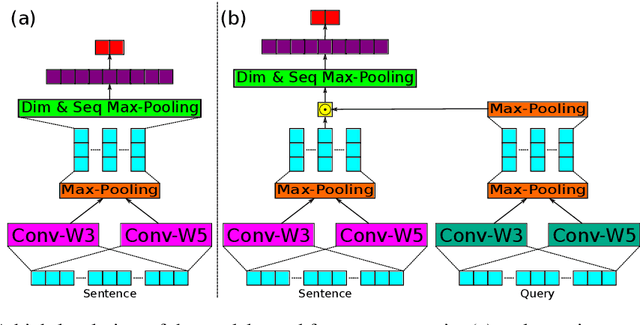
Deep learning has emerged as a compelling solution to many NLP tasks with remarkable performances. However, due to their opacity, such models are hard to interpret and trust. Recent work on explaining deep models has introduced approaches to provide insights toward the model's behaviour and predictions, which are helpful for assessing the reliability of the model's predictions. However, such methods do not improve the model's reliability. In this paper, we aim to teach the model to make the right prediction for the right reason by providing explanation training and ensuring the alignment of the model's explanation with the ground truth explanation. Our experimental results on multiple tasks and datasets demonstrate the effectiveness of the proposed method, which produces more reliable predictions while delivering better results compared to traditionally trained models.
Attentional Multi-Reading Sarcasm Detection
Sep 09, 2018
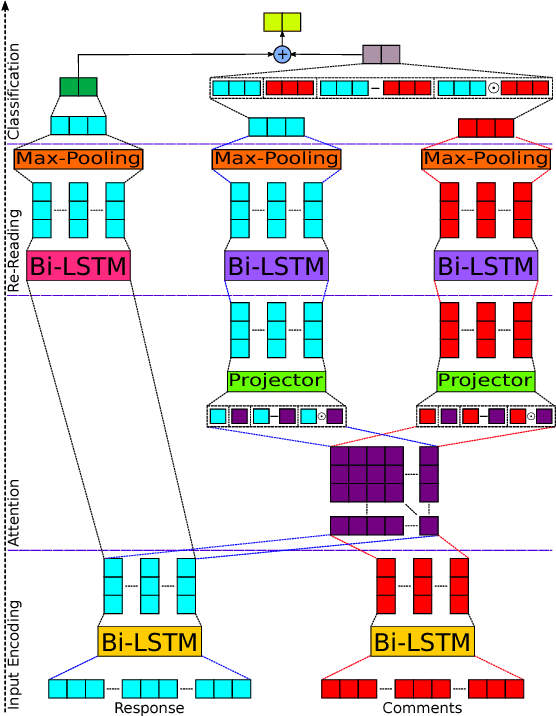
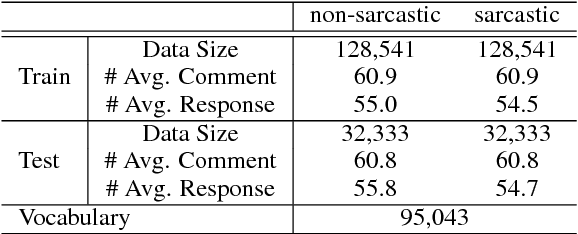
Recognizing sarcasm often requires a deep understanding of multiple sources of information, including the utterance, the conversational context, and real world facts. Most of the current sarcasm detection systems consider only the utterance in isolation. There are some limited attempts toward taking into account the conversational context. In this paper, we propose an interpretable end-to-end model that combines information from both the utterance and the conversational context to detect sarcasm, and demonstrate its effectiveness through empirical evaluations. We also study the behavior of the proposed model to provide explanations for the model's decisions. Importantly, our model is capable of determining the impact of utterance and conversational context on the model's decisions. Finally, we provide an ablation study to illustrate the impact of different components of the proposed model.
Interpreting Recurrent and Attention-Based Neural Models: a Case Study on Natural Language Inference
Aug 12, 2018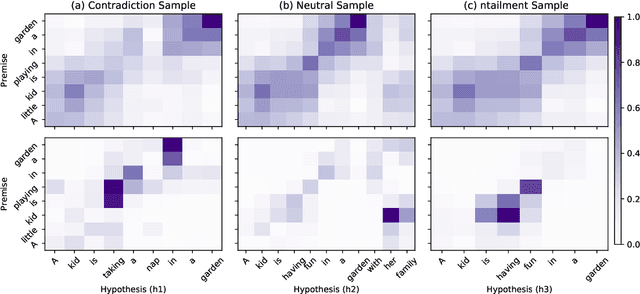
Deep learning models have achieved remarkable success in natural language inference (NLI) tasks. While these models are widely explored, they are hard to interpret and it is often unclear how and why they actually work. In this paper, we take a step toward explaining such deep learning based models through a case study on a popular neural model for NLI. In particular, we propose to interpret the intermediate layers of NLI models by visualizing the saliency of attention and LSTM gating signals. We present several examples for which our methods are able to reveal interesting insights and identify the critical information contributing to the model decisions.
Joint Neural Entity Disambiguation with Output Space Search
Jun 19, 2018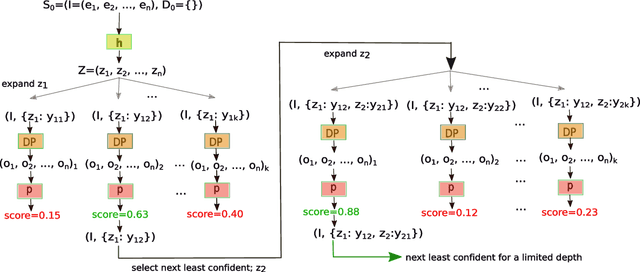

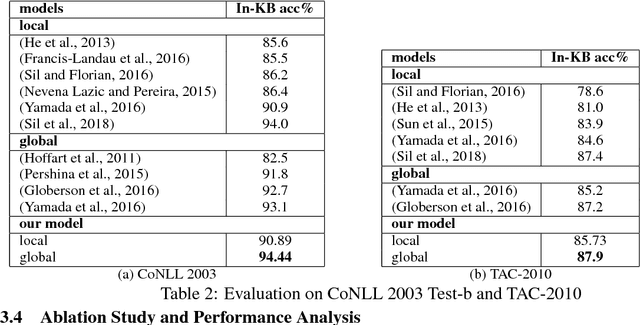
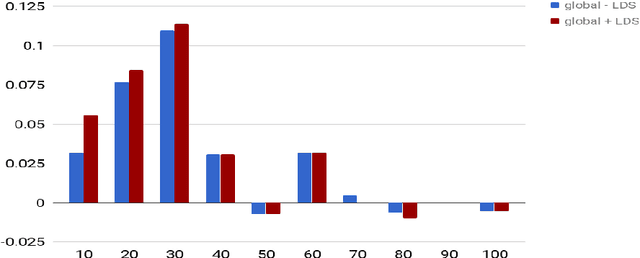
In this paper, we present a novel model for entity disambiguation that combines both local contextual information and global evidences through Limited Discrepancy Search (LDS). Given an input document, we start from a complete solution constructed by a local model and conduct a search in the space of possible corrections to improve the local solution from a global view point. Our search utilizes a heuristic function to focus more on the least confident local decisions and a pruning function to score the global solutions based on their local fitness and the global coherences among the predicted entities. Experimental results on CoNLL 2003 and TAC 2010 benchmarks verify the effectiveness of our model.
Dependent Gated Reading for Cloze-Style Question Answering
Jun 01, 2018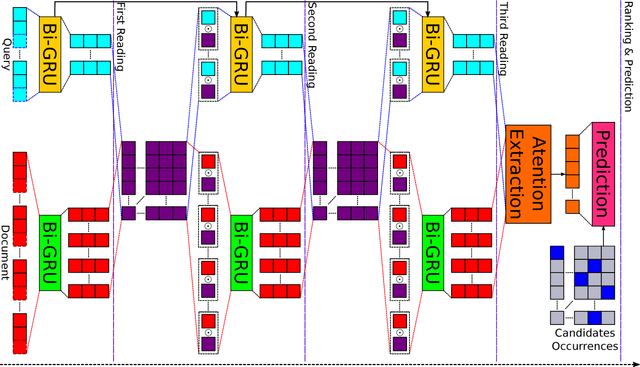
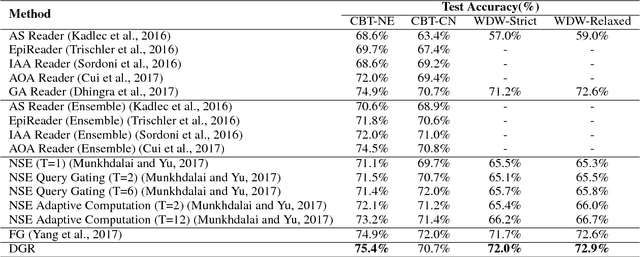
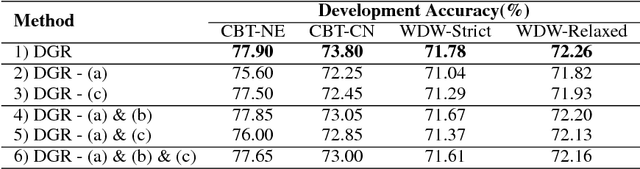
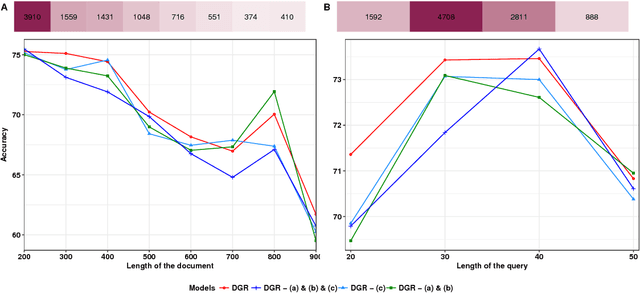
We present a novel deep learning architecture to address the cloze-style question answering task. Existing approaches employ reading mechanisms that do not fully exploit the interdependency between the document and the query. In this paper, we propose a novel \emph{dependent gated reading} bidirectional GRU network (DGR) to efficiently model the relationship between the document and the query during encoding and decision making. Our evaluation shows that DGR obtains highly competitive performance on well-known machine comprehension benchmarks such as the Children's Book Test (CBT-NE and CBT-CN) and Who DiD What (WDW, Strict and Relaxed). Finally, we extensively analyze and validate our model by ablation and attention studies.
DR-BiLSTM: Dependent Reading Bidirectional LSTM for Natural Language Inference
Apr 11, 2018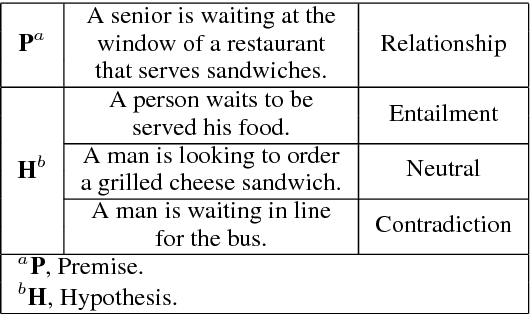
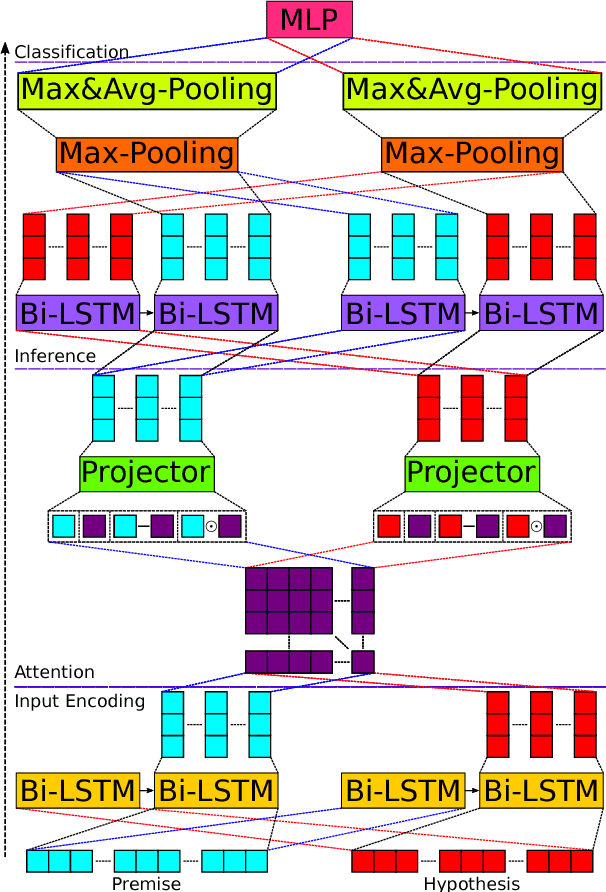
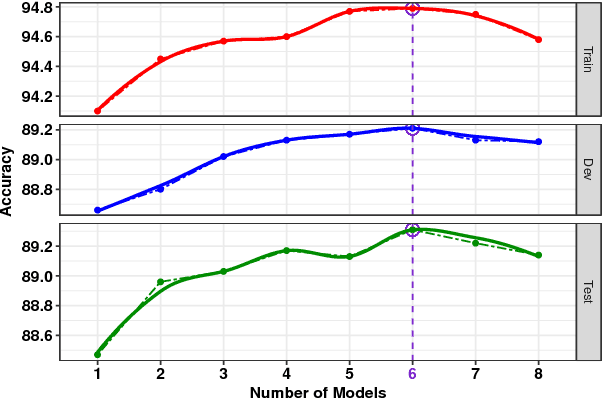
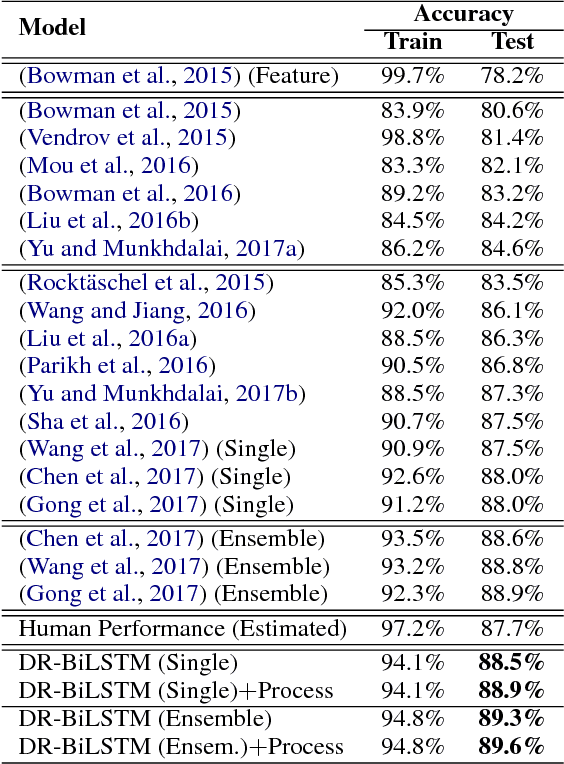
We present a novel deep learning architecture to address the natural language inference (NLI) task. Existing approaches mostly rely on simple reading mechanisms for independent encoding of the premise and hypothesis. Instead, we propose a novel dependent reading bidirectional LSTM network (DR-BiLSTM) to efficiently model the relationship between a premise and a hypothesis during encoding and inference. We also introduce a sophisticated ensemble strategy to combine our proposed models, which noticeably improves final predictions. Finally, we demonstrate how the results can be improved further with an additional preprocessing step. Our evaluation shows that DR-BiLSTM obtains the best single model and ensemble model results achieving the new state-of-the-art scores on the Stanford NLI dataset.
Event Nugget Detection with Forward-Backward Recurrent Neural Networks
Feb 15, 2018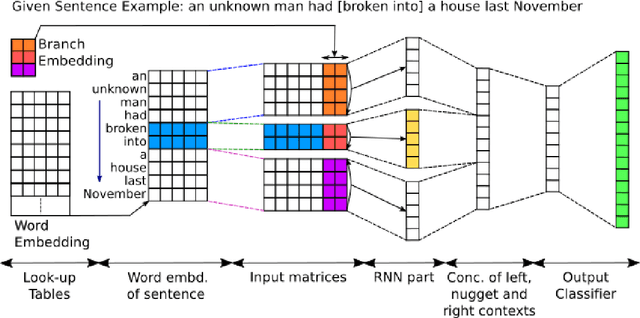
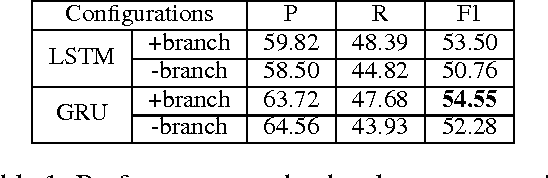
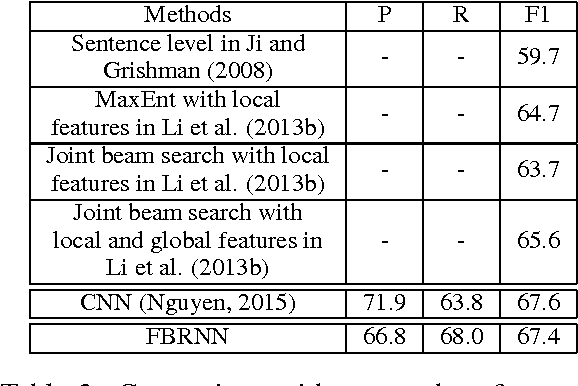
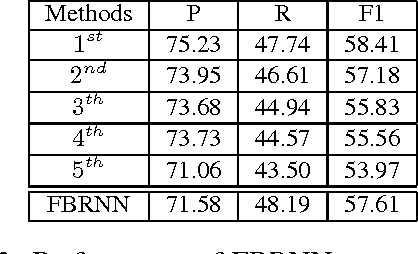
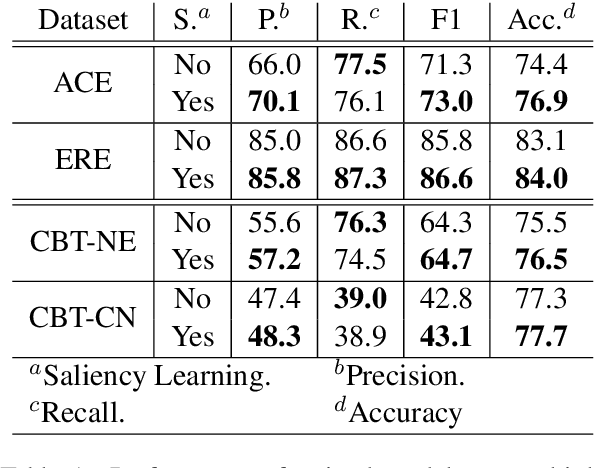
Traditional event detection methods heavily rely on manually engineered rich features. Recent deep learning approaches alleviate this problem by automatic feature engineering. But such efforts, like tradition methods, have so far only focused on single-token event mentions, whereas in practice events can also be a phrase. We instead use forward-backward recurrent neural networks (FBRNNs) to detect events that can be either words or phrases. To the best our knowledge, this is one of the first efforts to handle multi-word events and also the first attempt to use RNNs for event detection. Experimental results demonstrate that FBRNN is competitive with the state-of-the-art methods on the ACE 2005 and the Rich ERE 2015 event detection tasks.
* Published as a short paper at ACL 2016. The main purpose of this submission is to add this paper to arxiv