 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Minimax Estimators via Online Learning
Jun 19, 2020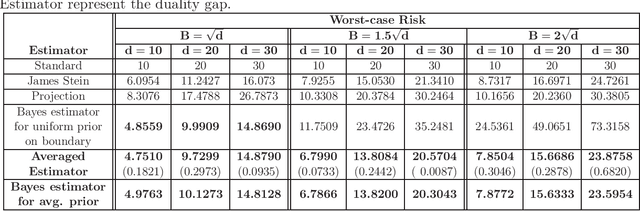
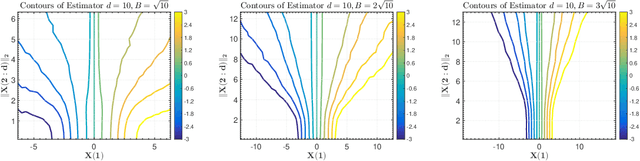

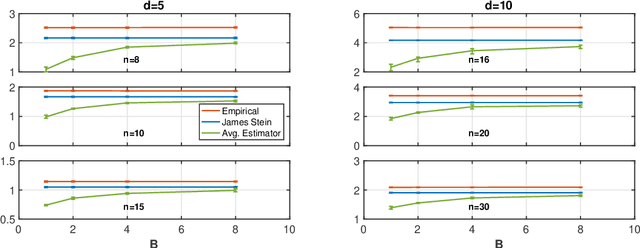
We consider the problem of designing minimax estimators for estimating the parameters of a probability distribution. Unlike classical approaches such as the MLE and minimum distance estimators, we consider an algorithmic approach for constructing such estimators. We view the problem of designing minimax estimators as finding a mixed strategy Nash equilibrium of a zero-sum game. By leveraging recent results in online learning with non-convex losses, we provide a general algorithm for finding a mixed-strategy Nash equilibrium of general non-convex non-concave zero-sum games. Our algorithm requires access to two subroutines: (a) one which outputs a Bayes estimator corresponding to a given prior probability distribution, and (b) one which computes the worst-case risk of any given estimator. Given access to these two subroutines, we show that our algorithm outputs both a minimax estimator and a least favorable prior. To demonstrate the power of this approach, we use it to construct provably minimax estimators for classical problems such as estimation in the finite Gaussian sequence model, and linear regression.
Evaluations and Methods for Explanation through Robustness Analysis
May 31, 2020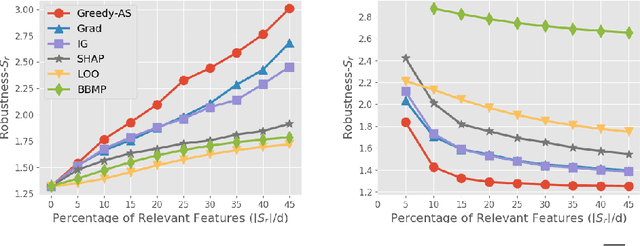


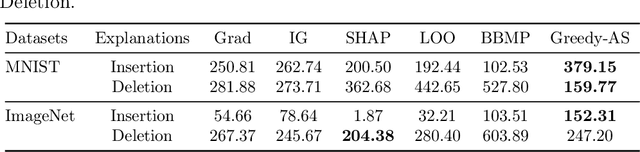
Among multiple ways of interpreting a machine learning model, measuring the importance of a set of features tied to a prediction is probably one of the most intuitive ways to explain a model. In this paper, we establish the link between a set of features to a prediction with a new evaluation criterion, robustness analysis, which measures the minimum distortion distance of adversarial perturbation. By measuring the tolerance level for an adversarial attack, we can extract a set of features that provides the most robust support for a prediction, and also can extract a set of features that contrasts the current prediction to a target class by setting a targeted adversarial attack. By applying this methodology to various prediction tasks across multiple domains, we observe the derived explanations are indeed capturing the significant feature set qualitatively and quantitatively.
Class-Weighted Classification: Trade-offs and Robust Approaches
May 26, 2020
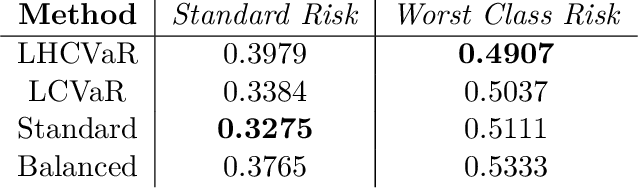
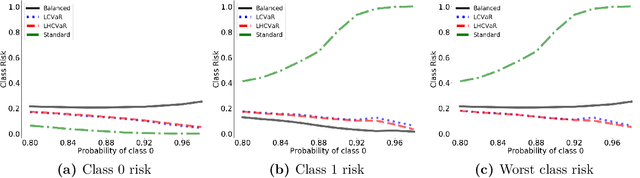
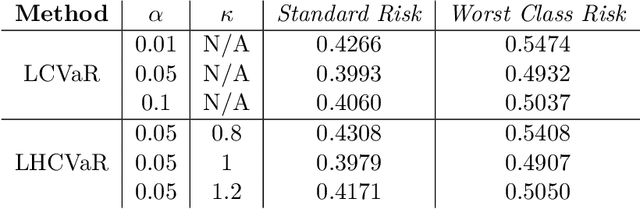
We address imbalanced classification, the problem in which a label may have low marginal probability relative to other labels, by weighting losses according to the correct class. First, we examine the convergence rates of the expected excess weighted risk of plug-in classifiers where the weighting for the plug-in classifier and the risk may be different. This leads to irreducible errors that do not converge to the weighted Bayes risk, which motivates our consideration of robust risks. We define a robust risk that minimizes risk over a set of weightings and show excess risk bounds for this problem. Finally, we show that particular choices of the weighting set leads to a special instance of conditional value at risk (CVaR) from stochastic programming, which we call label conditional value at risk (LCVaR). Additionally, we generalize this weighting to derive a new robust risk problem that we call label heterogeneous conditional value at risk (LHCVaR). Finally, we empirically demonstrate the efficacy of LCVaR and LHCVaR on improving class conditional risks.
Minimizing FLOPs to Learn Efficient Sparse Representations
Apr 12, 2020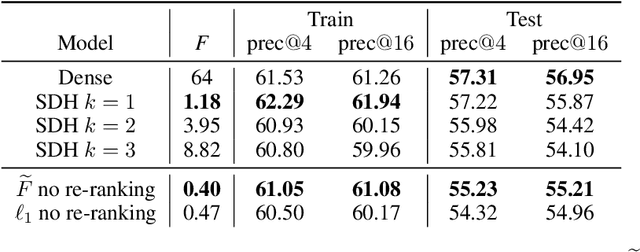

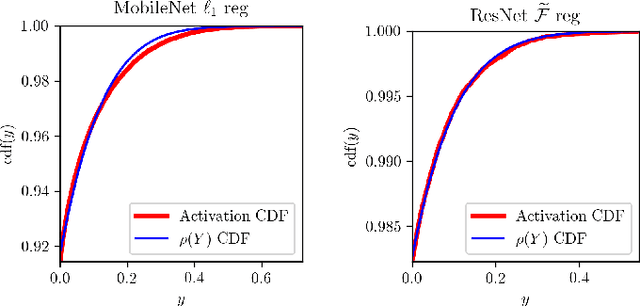
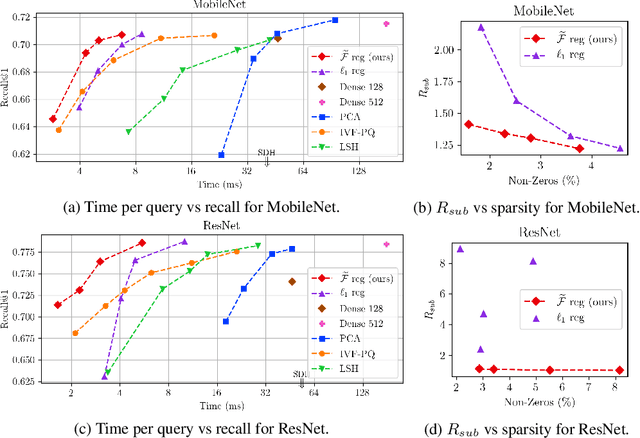
Deep representation learning has become one of the most widely adopted approaches for visual search, recommendation, and identification. Retrieval of such representations from a large database is however computationally challenging. Approximate methods based on learning compact representations, have been widely explored for this problem, such as locality sensitive hashing, product quantization, and PCA. In this work, in contrast to learning compact representations, we propose to learn high dimensional and sparse representations that have similar representational capacity as dense embeddings while being more efficient due to sparse matrix multiplication operations which can be much faster than dense multiplication. Following the key insight that the number of operations decreases quadratically with the sparsity of embeddings provided the non-zero entries are distributed uniformly across dimensions, we propose a novel approach to learn such distributed sparse embeddings via the use of a carefully constructed regularization function that directly minimizes a continuous relaxation of the number of floating-point operations (FLOPs) incurred during retrieval. Our experiments show that our approach is competitive to the other baselines and yields a similar or better speed-vs-accuracy tradeoff on practical datasets.
MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius
Feb 15, 2020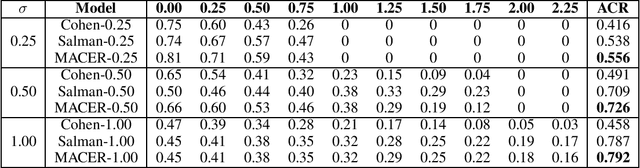
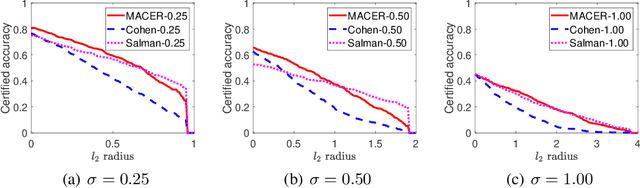
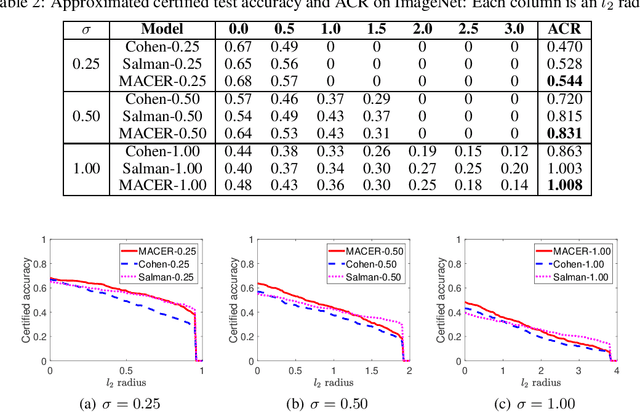
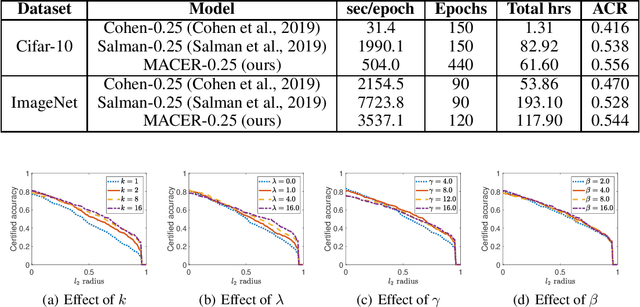
Adversarial training is one of the most popular ways to learn robust models but is usually attack-dependent and time costly. In this paper, we propose the MACER algorithm, which learns robust models without using adversarial training but performs better than all existing provable l2-defenses. Recent work shows that randomized smoothing can be used to provide a certified l2 radius to smoothed classifiers, and our algorithm trains provably robust smoothed classifiers via MAximizing the CErtified Radius (MACER). The attack-free characteristic makes MACER faster to train and easier to optimize. In our experiments, we show that our method can be applied to modern deep neural networks on a wide range of datasets, including Cifar-10, ImageNet, MNIST, and SVHN. For all tasks, MACER spends less training time than state-of-the-art adversarial training algorithms, and the learned models achieve larger average certified radius.
Certified Robustness to Label-Flipping Attacks via Randomized Smoothing
Feb 07, 2020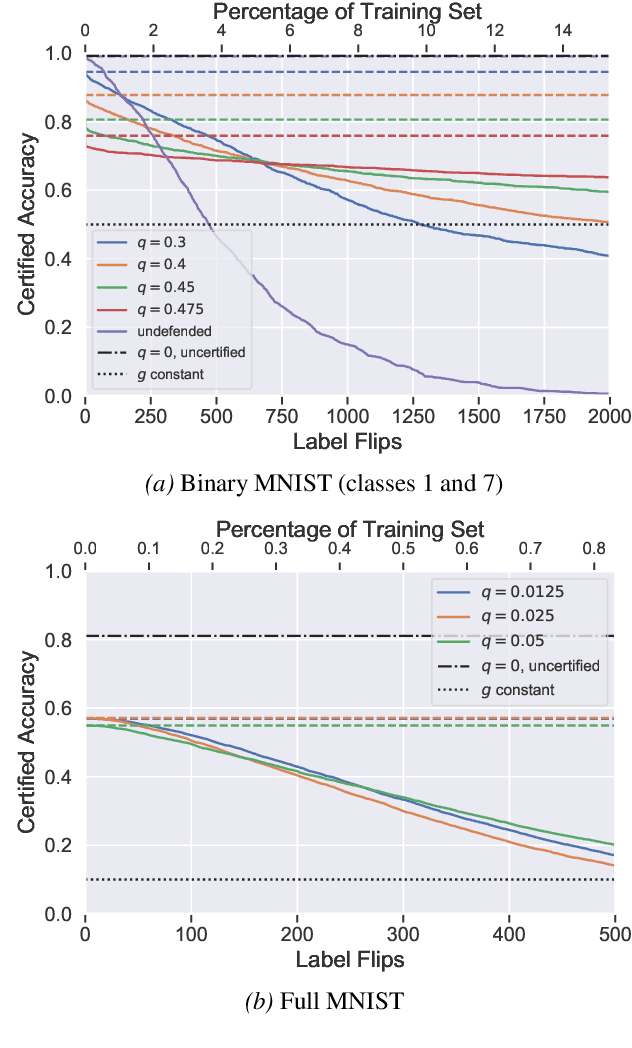
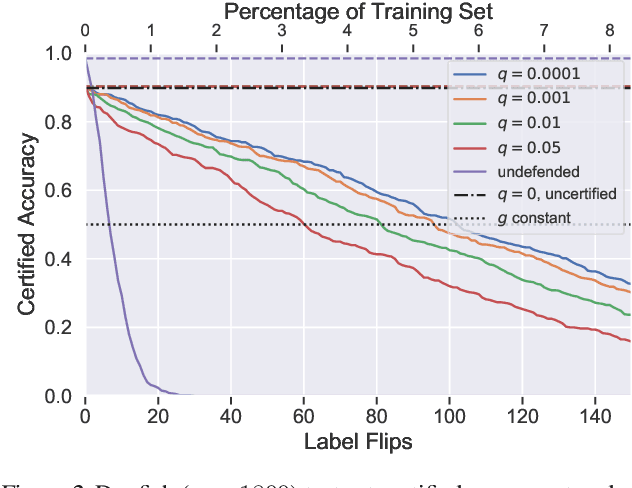
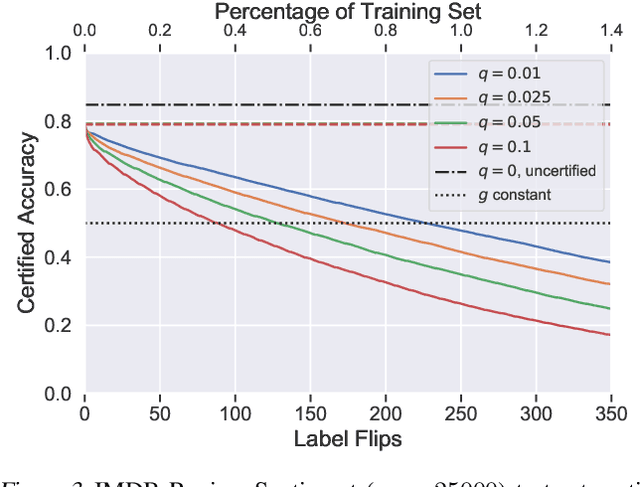
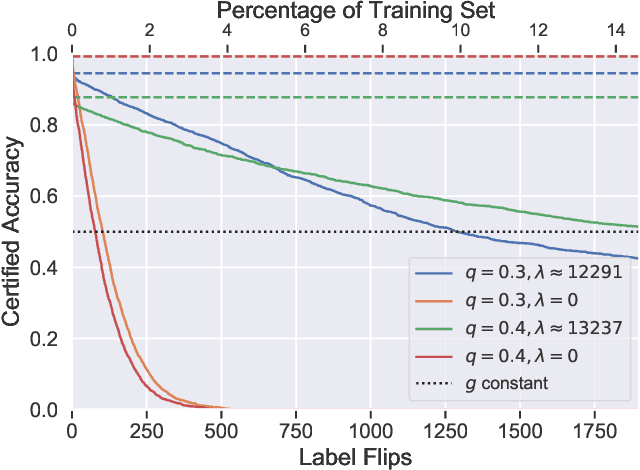
Machine learning algorithms are known to be susceptible to data poisoning attacks, where an adversary manipulates the training data to degrade performance of the resulting classifier. While many heuristic defenses have been proposed, few defenses exist which are certified against worst-case corruption of the training data. In this work, we propose a strategy to build linear classifiers that are certifiably robust against a strong variant of label-flipping, where each test example is targeted independently. In other words, for each test point, our classifier makes a prediction and includes a certification that its prediction would be the same had some number of training labels been changed adversarially. Our approach leverages randomized smoothing, a technique that has previously been used to guarantee---with high probability---test-time robustness to adversarial manipulation of the input to a classifier. We derive a variant which provides a deterministic, analytical bound, sidestepping the probabilistic certificates that traditionally result from the sampling subprocedure. Further, we obtain these certified bounds with no additional runtime cost over standard classification. We generalize our results to the multi-class case, providing what we believe to be the first multi-class classification algorithm that is certifiably robust to label-flipping attacks.
Game Design for Eliciting Distinguishable Behavior
Dec 12, 2019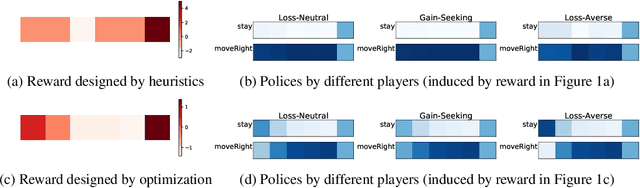
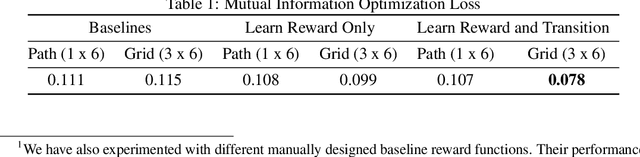
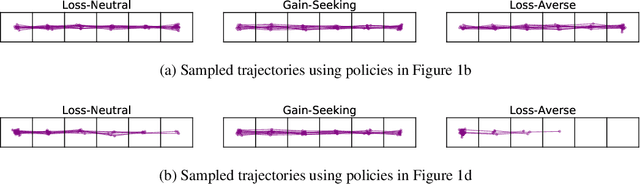

The ability to inferring latent psychological traits from human behavior is key to developing personalized human-interacting machine learning systems. Approaches to infer such traits range from surveys to manually-constructed experiments and games. However, these traditional games are limited because they are typically designed based on heuristics. In this paper, we formulate the task of designing \emph{behavior diagnostic games} that elicit distinguishable behavior as a mutual information maximization problem, which can be solved by optimizing a variational lower bound. Our framework is instantiated by using prospect theory to model varying player traits, and Markov Decision Processes to parameterize the games. We validate our approach empirically, showing that our designed games can successfully distinguish among players with different traits, outperforming manually-designed ones by a large margin.
Diagnostic Curves for Black Box Models
Dec 02, 2019
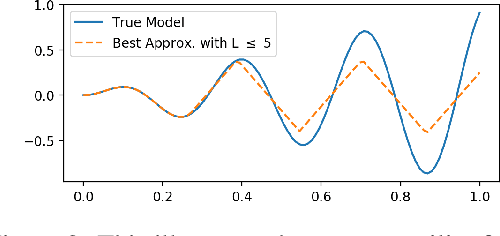
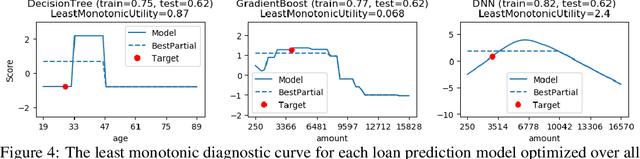
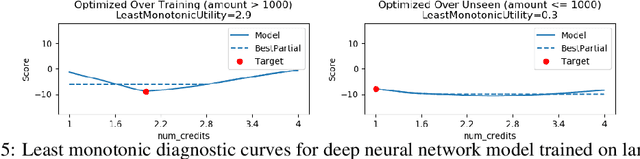
In safety-critical applications of machine learning, it is often necessary to look beyond standard metrics such as test accuracy in order to validate various qualitative properties such as monotonicity with respect to a feature or combination of features, checking for undesirable changes or oscillations in the response, and differences in outcomes (e.g. discrimination) for a protected class. To help answer this need, we propose a framework for approximately validating (or invalidating) various properties of a black box model by finding a univariate diagnostic curve in the input space whose output maximally violates a given property. These diagnostic curves show the exact value of the model along the curve and can be displayed with a simple and intuitive line graph. We demonstrate the usefulness of these diagnostic curves across multiple use-cases and datasets including selecting between two models and understanding out-of-sample behavior.
Optimal Analysis of Subset-Selection Based L_p Low Rank Approximation
Oct 30, 2019We study the low rank approximation problem of any given matrix $A$ over $\mathbb{R}^{n\times m}$ and $\mathbb{C}^{n\times m}$ in entry-wise $\ell_p$ loss, that is, finding a rank-$k$ matrix $X$ such that $\|A-X\|_p$ is minimized. Unlike the traditional $\ell_2$ setting, this particular variant is NP-Hard. We show that the algorithm of column subset selection, which was an algorithmic foundation of many existing algorithms, enjoys approximation ratio $(k+1)^{1/p}$ for $1\le p\le 2$ and $(k+1)^{1-1/p}$ for $p\ge 2$. This improves upon the previous $O(k+1)$ bound for $p\ge 1$ \cite{chierichetti2017algorithms}. We complement our analysis with lower bounds; these bounds match our upper bounds up to constant $1$ when $p\geq 2$. At the core of our techniques is an application of \emph{Riesz-Thorin interpolation theorem} from harmonic analysis, which might be of independent interest to other algorithmic designs and analysis more broadly. As a consequence of our analysis, we provide better approximation guarantees for several other algorithms with various time complexity. For example, to make the algorithm of column subset selection computationally efficient, we analyze a polynomial time bi-criteria algorithm which selects $O(k\log m)$ columns. We show that this algorithm has an approximation ratio of $O((k+1)^{1/p})$ for $1\le p\le 2$ and $O((k+1)^{1-1/p})$ for $p\ge 2$. This improves over the best-known bound with an $O(k+1)$ approximation ratio. Our bi-criteria algorithm also implies an exact-rank method in polynomial time with a slightly larger approximation ratio.
On Concept-Based Explanations in Deep Neural Networks
Oct 17, 2019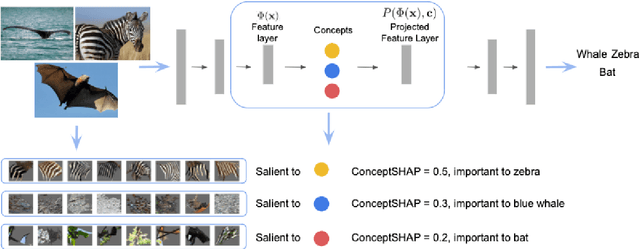
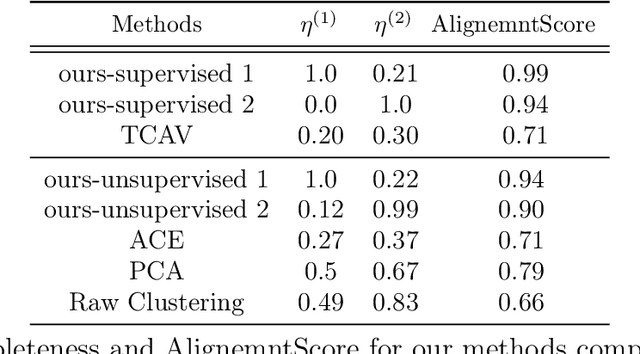
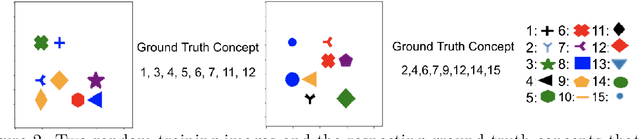

Deep neural networks (DNNs) build high-level intelligence on low-level raw features. Understanding of this high-level intelligence can be enabled by deciphering the concepts they base their decisions on, as human-level thinking. In this paper, we study concept-based explainability for DNNs in a systematic framework. First, we define the notion of completeness, which quantifies how sufficient a particular set of concepts is in explaining a model's prediction behavior. Based on performance and variability motivations, we propose two definitions to quantify completeness. We show that under degenerate conditions, our method is equivalent to Principal Component Analysis. Next, we propose a concept discovery method that considers two additional constraints to encourage the interpretability of the discovered concepts. We use game-theoretic notions to aggregate over sets to define an importance score for each discovered concept, which we call ConceptSHAP. On specifically-designed synthetic datasets and real-world text and image datasets, we validate the effectiveness of our framework in finding concepts that are complete in explaining the decision, and interpretable.