 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Residual-based Latent Denoising in Semantic Communication
Feb 11, 2025A latent denoising semantic communication (SemCom) framework is proposed for robust image transmission over noisy channels. By incorporating a learnable latent denoiser into the receiver, the received signals are preprocessed to effectively remove the channel noise and recover the semantic information, thereby enhancing the quality of the decoded images. Specifically, a latent denoising mapping is established by an iterative residual learning approach to improve the denoising efficiency while ensuring stable performance. Moreover, channel signal-to-noise ratio (SNR) is utilized to estimate and predict the latent similarity score (SS) for conditional denoising, where the number of denoising steps is adapted based on the predicted SS sequence, further reducing the communication latency. Finally, simulations demonstrate that the proposed framework can effectively and efficiently remove the channel noise at various levels and reconstruct visual-appealing images.
WatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025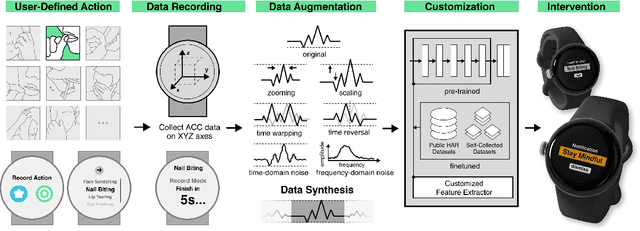
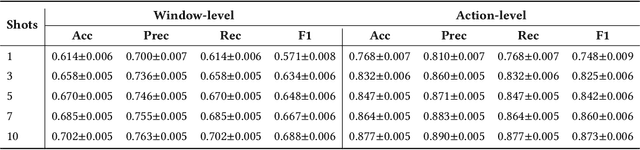
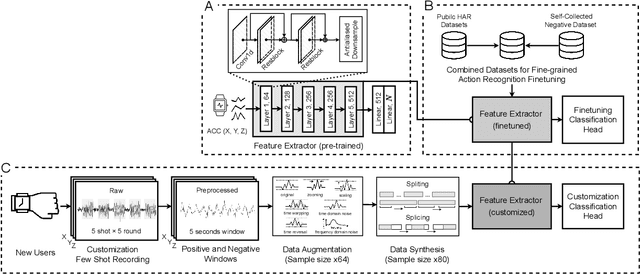
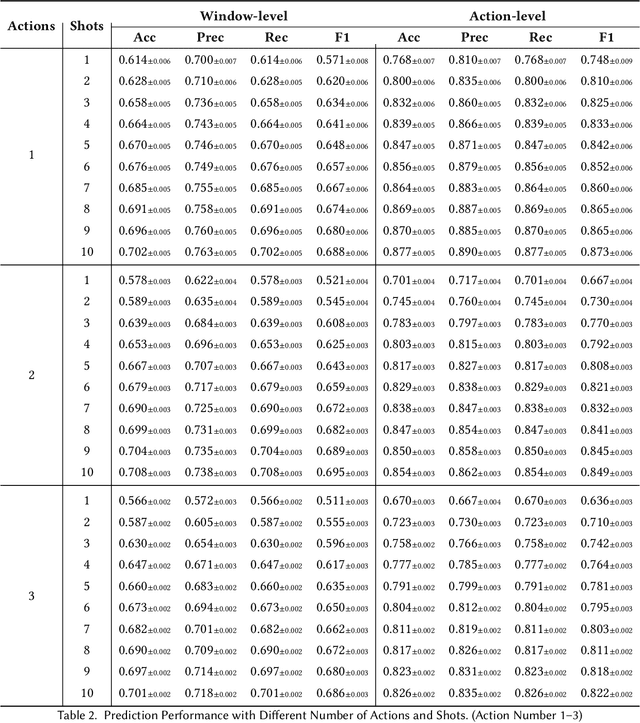
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
WirelessGPT: A Generative Pre-trained Multi-task Learning Framework for Wireless Communication
Feb 08, 2025



This paper introduces WirelessGPT, a pioneering foundation model specifically designed for multi-task learning in wireless communication and sensing. Specifically, WirelessGPT leverages large-scale wireless channel datasets for unsupervised pretraining and extracting universal channel representations, which captures complex spatiotemporal dependencies. In fact,this task-agnostic design adapts WirelessGPT seamlessly to a wide range of downstream tasks, using a unified representation with minimal fine-tuning. By unifying communication and sensing functionalities, WirelessGPT addresses the limitations of task-specific models, offering a scalable and efficient solution for integrated sensing and communication (ISAC). With an initial parameter size of around 80 million, WirelessGPT demonstrates significant improvements over conventional methods and smaller AI models, reducing reliance on large-scale labeled data. As the first foundation model capable of supporting diverse tasks across different domains, WirelessGPT establishes a new benchmark, paving the way for future advancements in multi-task wireless systems.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Secure Semantic Communication With Homomorphic Encryption
Jan 17, 2025



In recent years, Semantic Communication (SemCom), which aims to achieve efficient and reliable transmission of meaning between agents, has garnered significant attention from both academia and industry. To ensure the security of communication systems, encryption techniques are employed to safeguard confidentiality and integrity. However, traditional cryptography-based encryption algorithms encounter obstacles when applied to SemCom. Motivated by this, this paper explores the feasibility of applying homomorphic encryption to SemCom. Initially, we review the encryption algorithms utilized in mobile communication systems and analyze the challenges associated with their application to SemCom. Subsequently, we employ scale-invariant feature transform to demonstrate that semantic features can be preserved in homomorphic encrypted ciphertext. Based on this finding, we propose a task-oriented SemCom scheme secured through homomorphic encryption. We design the privacy preserved deep joint source-channel coding (JSCC) encoder and decoder, and the frequency of key updates can be adjusted according to service requirements without compromising transmission performance. Simulation results validate that, when compared to plaintext images, the proposed scheme can achieve almost the same classification accuracy performance when dealing with homomorphic ciphertext images. Furthermore, we provide potential future research directions for homomorphic encrypted SemCom.
A Survey of Secure Semantic Communications
Jan 01, 2025



Semantic communication (SemCom) is regarded as a promising and revolutionary technology in 6G, aiming to transcend the constraints of ``Shannon's trap" by filtering out redundant information and extracting the core of effective data. Compared to traditional communication paradigms, SemCom offers several notable advantages, such as reducing the burden on data transmission, enhancing network management efficiency, and optimizing resource allocation. Numerous researchers have extensively explored SemCom from various perspectives, including network architecture, theoretical analysis, potential technologies, and future applications. However, as SemCom continues to evolve, a multitude of security and privacy concerns have arisen, posing threats to the confidentiality, integrity, and availability of SemCom systems. This paper presents a comprehensive survey of the technologies that can be utilized to secure SemCom. Firstly, we elaborate on the entire life cycle of SemCom, which includes the model training, model transfer, and semantic information transmission phases. Then, we identify the security and privacy issues that emerge during these three stages. Furthermore, we summarize the techniques available to mitigate these security and privacy threats, including data cleaning, robust learning, defensive strategies against backdoor attacks, adversarial training, differential privacy, cryptography, blockchain technology, model compression, and physical-layer security. Lastly, this paper outlines future research directions to guide researchers in related fields.
SepsisCalc: Integrating Clinical Calculators into Early Sepsis Prediction via Dynamic Temporal Graph Construction
Dec 31, 2024



Sepsis is an organ dysfunction caused by a deregulated immune response to an infection. Early sepsis prediction and identification allow for timely intervention, leading to improved clinical outcomes. Clinical calculators (e.g., the six-organ dysfunction assessment of SOFA) play a vital role in sepsis identification within clinicians' workflow, providing evidence-based risk assessments essential for sepsis diagnosis. However, artificial intelligence (AI) sepsis prediction models typically generate a single sepsis risk score without incorporating clinical calculators for assessing organ dysfunctions, making the models less convincing and transparent to clinicians. To bridge the gap, we propose to mimic clinicians' workflow with a novel framework SepsisCalc to integrate clinical calculators into the predictive model, yielding a clinically transparent and precise model for utilization in clinical settings. Practically, clinical calculators usually combine information from multiple component variables in Electronic Health Records (EHR), and might not be applicable when the variables are (partially) missing. We mitigate this issue by representing EHRs as temporal graphs and integrating a learning module to dynamically add the accurately estimated calculator to the graphs. Experimental results on real-world datasets show that the proposed model outperforms state-of-the-art methods on sepsis prediction tasks. Moreover, we developed a system to identify organ dysfunctions and potential sepsis risks, providing a human-AI interaction tool for deployment, which can help clinicians understand the prediction outputs and prepare timely interventions for the corresponding dysfunctions, paving the way for actionable clinical decision-making support for early intervention.
A Deep Subgrouping Framework for Precision Drug Repurposing via Emulating Clinical Trials on Real-world Patient Data
Dec 29, 2024Drug repurposing identifies new therapeutic uses for existing drugs, reducing the time and costs compared to traditional de novo drug discovery. Most existing drug repurposing studies using real-world patient data often treat the entire population as homogeneous, ignoring the heterogeneity of treatment responses across patient subgroups. This approach may overlook promising drugs that benefit specific subgroups but lack notable treatment effects across the entire population, potentially limiting the number of repurposable candidates identified. To address this, we introduce STEDR, a novel drug repurposing framework that integrates subgroup analysis with treatment effect estimation. Our approach first identifies repurposing candidates by emulating multiple clinical trials on real-world patient data and then characterizes patient subgroups by learning subgroup-specific treatment effects. We deploy \model to Alzheimer's Disease (AD), a condition with few approved drugs and known heterogeneity in treatment responses. We emulate trials for over one thousand medications on a large-scale real-world database covering over 8 million patients, identifying 14 drug candidates with beneficial effects to AD in characterized subgroups. Experiments demonstrate STEDR's superior capability in identifying repurposing candidates compared to existing approaches. Additionally, our method can characterize clinically relevant patient subgroups associated with important AD-related risk factors, paving the way for precision drug repurposing.
Amplifier-Enhanced Memristive Massive MIMO Linear Detector Circuit: An Ultra-Energy-Efficient and Robust-to-Conductance-Error Design
Dec 22, 2024



The emerging analog matrix computing technology based on memristive crossbar array (MCA) constitutes a revolutionary new computational paradigm applicable to a wide range of domains. Despite the proven applicability of MCA for massive multiple-input multiple-output (MIMO) detection, existing schemes do not take into account the unique characteristics of massive MIMO channel matrix. This oversight makes their computational accuracy highly sensitive to conductance errors of memristive devices, which is unacceptable for massive MIMO receivers. In this paper, we propose an MCA-based circuit design for massive MIMO zero forcing and minimum mean-square error detectors. Unlike the existing MCA-based detectors, we decompose the channel matrix into the product of small-scale and large-scale fading coefficient matrices, thus employing an MCA-based matrix computing module and amplifier circuits to process the two matrices separately. We present two conductance mapping schemes which are crucial but have been overlooked in all prior studies on MCA-based detector circuits. The proposed detector circuit exhibits significantly superior performance to the conventional MCA-based detector circuit, while only incurring negligible additional power consumption. Our proposed detector circuit maintains its advantage in energy efficiency over traditional digital approach by tens to hundreds of times.
In-Memory Massive MIMO Linear Detector Circuit with Extremely High Energy Efficiency and Strong Memristive Conductance Deviation Robustness
Dec 22, 2024



The memristive crossbar array (MCA) has been successfully applied to accelerate matrix computations of signal detection in massive multiple-input multiple-output (MIMO) systems. However, the unique property of massive MIMO channel matrix makes the detection performance of existing MCA-based detectors sensitive to conductance deviations of memristive devices, and the conductance deviations are difficult to be avoided. In this paper, we propose an MCA-based detector circuit, which is robust to conductance deviations, to compute massive MIMO zero forcing and minimum mean-square error algorithms. The proposed detector circuit comprises an MCA-based matrix computing module, utilized for processing the small-scale fading coefficient matrix, and amplifier circuits based on operational amplifiers (OAs), utilized for processing the large-scale fading coefficient matrix. We investigate the impacts of the open-loop gain of OAs, conductance mapping scheme, and conductance deviation level on detection performance and demonstrate the performance superiority of the proposed detector circuit over the conventional MCA-based detector circuit. The energy efficiency of the proposed detector circuit surpasses that of a traditional digital processor by several tens to several hundreds of times.