 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Efficient Robotic Manipulation
Dec 14, 2020
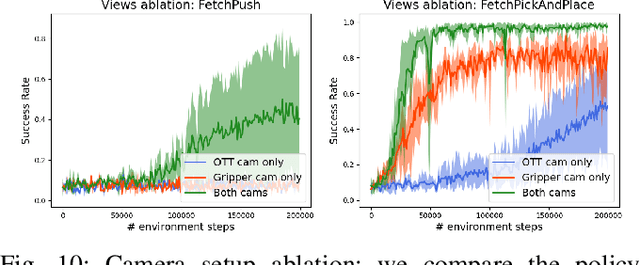
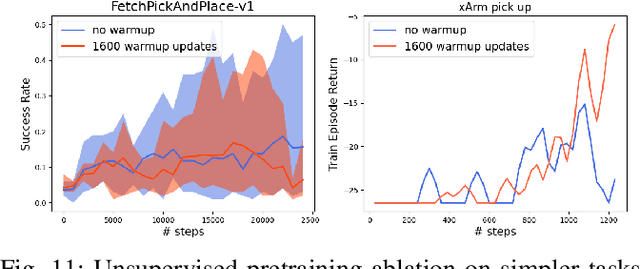
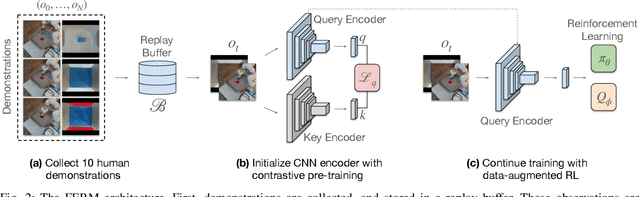
Data-efficient learning of manipulation policies from visual observations is an outstanding challenge for real-robot learning. While deep reinforcement learning (RL) algorithms have shown success learning policies from visual observations, they still require an impractical number of real-world data samples to learn effective policies. However, recent advances in unsupervised representation learning and data augmentation significantly improved the sample efficiency of training RL policies on common simulated benchmarks. Building on these advances, we present a Framework for Efficient Robotic Manipulation (FERM) that utilizes data augmentation and unsupervised learning to achieve extremely sample-efficient training of robotic manipulation policies with sparse rewards. We show that, given only 10 demonstrations, a single robotic arm can learn sparse-reward manipulation policies from pixels, such as reaching, picking, moving, pulling a large object, flipping a switch, and opening a drawer in just 15-50 minutes of real-world training time. We include videos, code, and additional information on the project website -- https://sites.google.com/view/efficient-robotic-manipulation.
Parallel Training of Deep Networks with Local Updates
Dec 07, 2020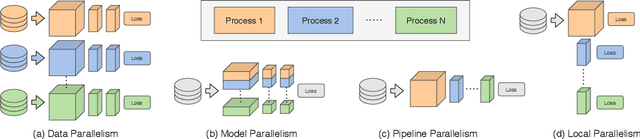
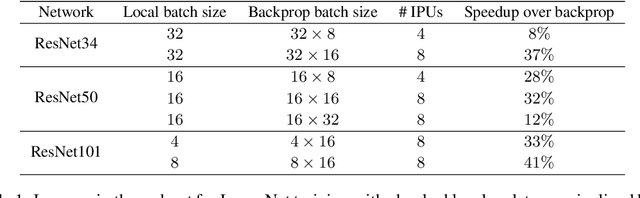
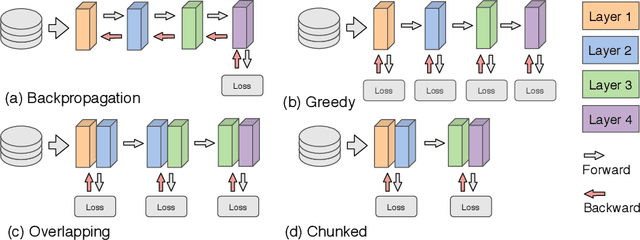
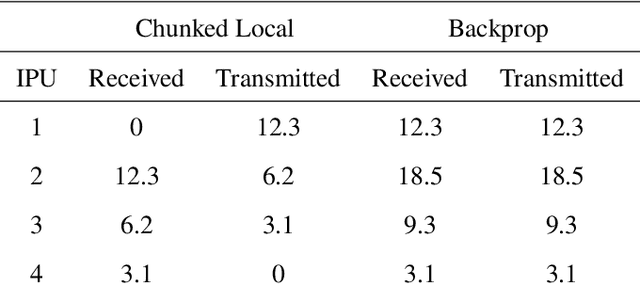
Deep learning models trained on large data sets have been widely successful in both vision and language domains. As state-of-the-art deep learning architectures have continued to grow in parameter count so have the compute budgets and times required to train them, increasing the need for compute-efficient methods that parallelize training. Two common approaches to parallelize the training of deep networks have been data and model parallelism. While useful, data and model parallelism suffer from diminishing returns in terms of compute efficiency for large batch sizes. In this paper, we investigate how to continue scaling compute efficiently beyond the point of diminishing returns for large batches through local parallelism, a framework which parallelizes training of individual layers in deep networks by replacing global backpropagation with truncated layer-wise backpropagation. Local parallelism enables fully asynchronous layer-wise parallelism with a low memory footprint, and requires little communication overhead compared with model parallelism. We show results in both vision and language domains across a diverse set of architectures, and find that local parallelism is particularly effective in the high-compute regime.
Trajectory-wise Multiple Choice Learning for Dynamics Generalization in Reinforcement Learning
Oct 26, 2020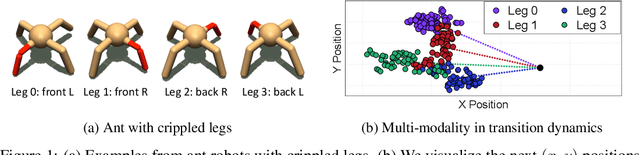
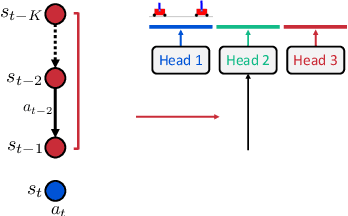
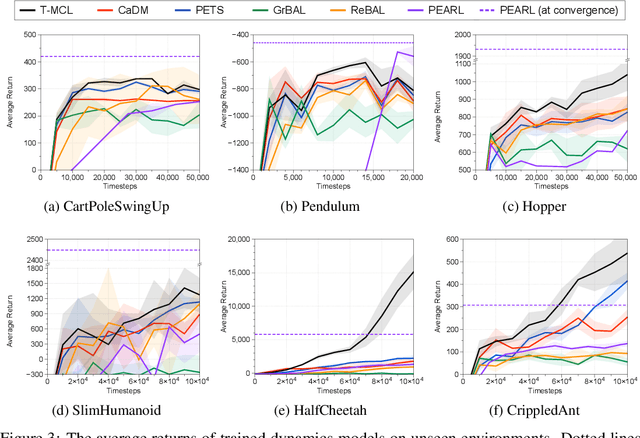

Model-based reinforcement learning (RL) has shown great potential in various control tasks in terms of both sample-efficiency and final performance. However, learning a generalizable dynamics model robust to changes in dynamics remains a challenge since the target transition dynamics follow a multi-modal distribution. In this paper, we present a new model-based RL algorithm, coined trajectory-wise multiple choice learning, that learns a multi-headed dynamics model for dynamics generalization. The main idea is updating the most accurate prediction head to specialize each head in certain environments with similar dynamics, i.e., clustering environments. Moreover, we incorporate context learning, which encodes dynamics-specific information from past experiences into the context latent vector, enabling the model to perform online adaptation to unseen environments. Finally, to utilize the specialized prediction heads more effectively, we propose an adaptive planning method, which selects the most accurate prediction head over a recent experience. Our method exhibits superior zero-shot generalization performance across a variety of control tasks, compared to state-of-the-art RL methods. Source code and videos are available at https://sites.google.com/view/trajectory-mcl.
LaND: Learning to Navigate from Disengagements
Oct 09, 2020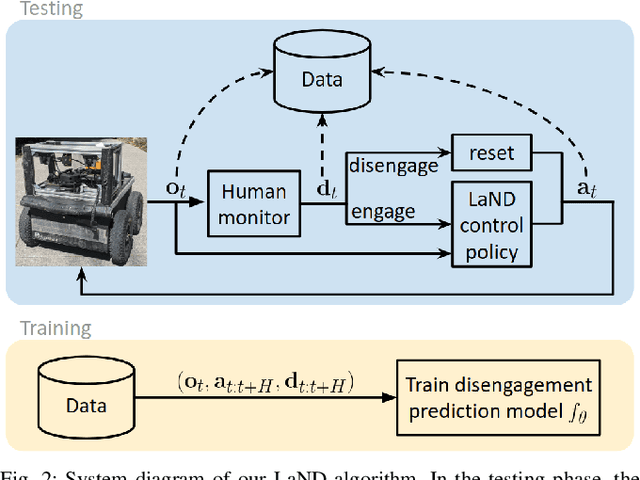

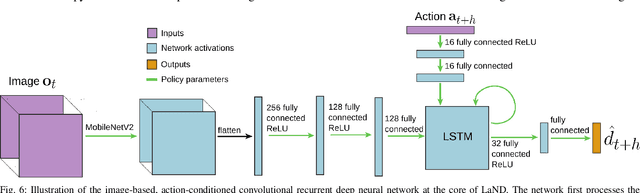
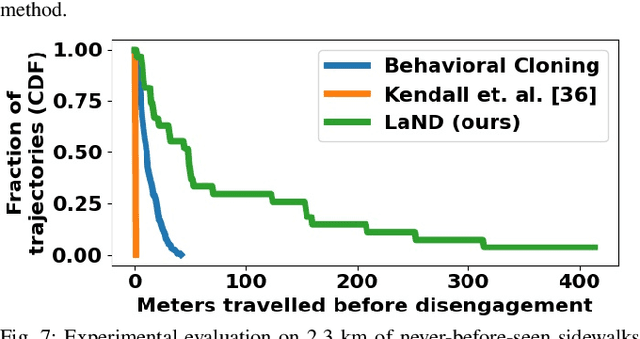
Consistently testing autonomous mobile robots in real world scenarios is a necessary aspect of developing autonomous navigation systems. Each time the human safety monitor disengages the robot's autonomy system due to the robot performing an undesirable maneuver, the autonomy developers gain insight into how to improve the autonomy system. However, we believe that these disengagements not only show where the system fails, which is useful for troubleshooting, but also provide a direct learning signal by which the robot can learn to navigate. We present a reinforcement learning approach for learning to navigate from disengagements, or LaND. LaND learns a neural network model that predicts which actions lead to disengagements given the current sensory observation, and then at test time plans and executes actions that avoid disengagements. Our results demonstrate LaND can successfully learn to navigate in diverse, real world sidewalk environments, outperforming both imitation learning and reinforcement learning approaches. Videos, code, and other material are available on our website https://sites.google.com/view/sidewalk-learning
Decoupling Representation Learning from Reinforcement Learning
Sep 30, 2020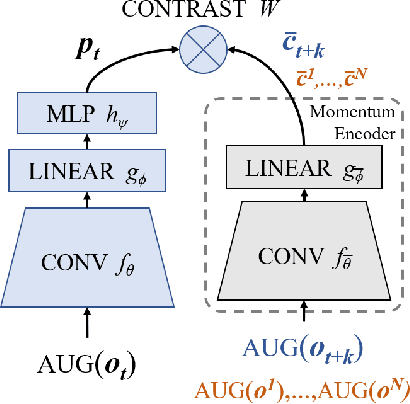

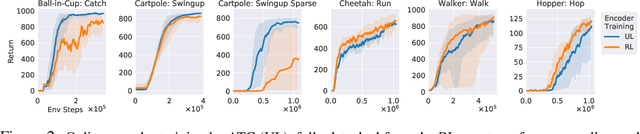
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/tree/master/rlpyt/ul.
Visual Imitation Made Easy
Aug 11, 2020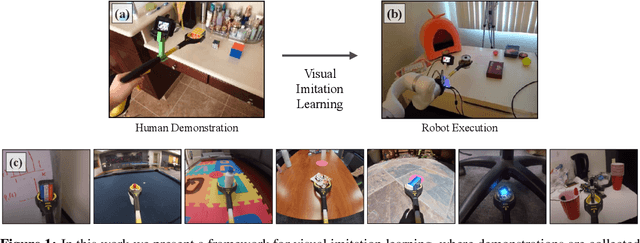



Visual imitation learning provides a framework for learning complex manipulation behaviors by leveraging human demonstrations. However, current interfaces for imitation such as kinesthetic teaching or teleoperation prohibitively restrict our ability to efficiently collect large-scale data in the wild. Obtaining such diverse demonstration data is paramount for the generalization of learned skills to novel scenarios. In this work, we present an alternate interface for imitation that simplifies the data collection process while allowing for easy transfer to robots. We use commercially available reacher-grabber assistive tools both as a data collection device and as the robot's end-effector. To extract action information from these visual demonstrations, we use off-the-shelf Structure from Motion (SfM) techniques in addition to training a finger detection network. We experimentally evaluate on two challenging tasks: non-prehensile pushing and prehensile stacking, with 1000 diverse demonstrations for each task. For both tasks, we use standard behavior cloning to learn executable policies from the previously collected offline demonstrations. To improve learning performance, we employ a variety of data augmentations and provide an extensive analysis of its effects. Finally, we demonstrate the utility of our interface by evaluating on real robotic scenarios with previously unseen objects and achieve a 87% success rate on pushing and a 62% success rate on stacking. Robot videos are available at https://dhiraj100892.github.io/Visual-Imitation-Made-Easy.
Hybrid Discriminative-Generative Training via Contrastive Learning
Aug 10, 2020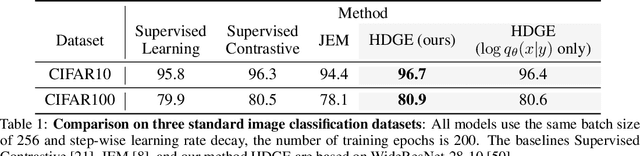
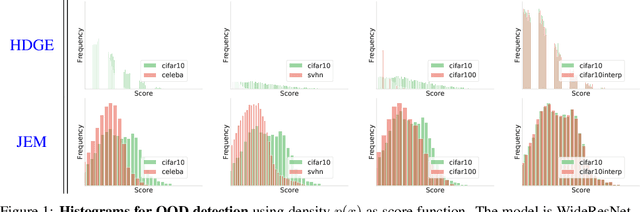
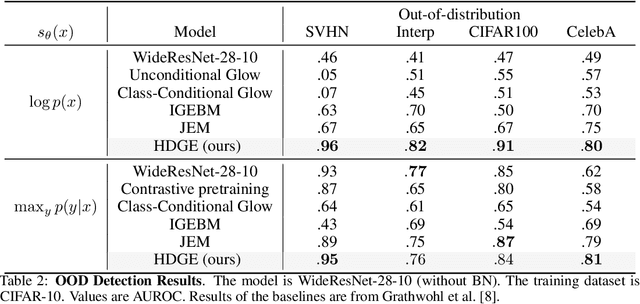
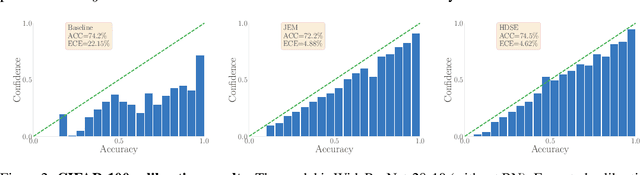
Contrastive learning and supervised learning have both seen significant progress and success. However, thus far they have largely been treated as two separate objectives, brought together only by having a shared neural network. In this paper we show that through the perspective of hybrid discriminative-generative training of energy-based models we can make a direct connection between contrastive learning and supervised learning. Beyond presenting this unified view, we show our specific choice of approximation of the energy-based loss outperforms the existing practice in terms of classification accuracy of WideResNet on CIFAR-10 and CIFAR-100. It also leads to improved performance on robustness, out-of-distribution detection, and calibration.
Robust Reinforcement Learning using Adversarial Populations
Aug 04, 2020
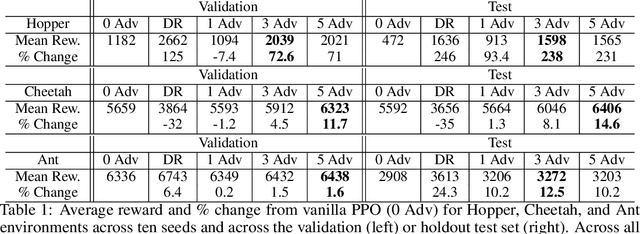
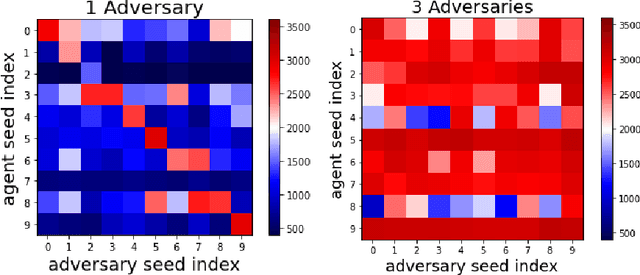
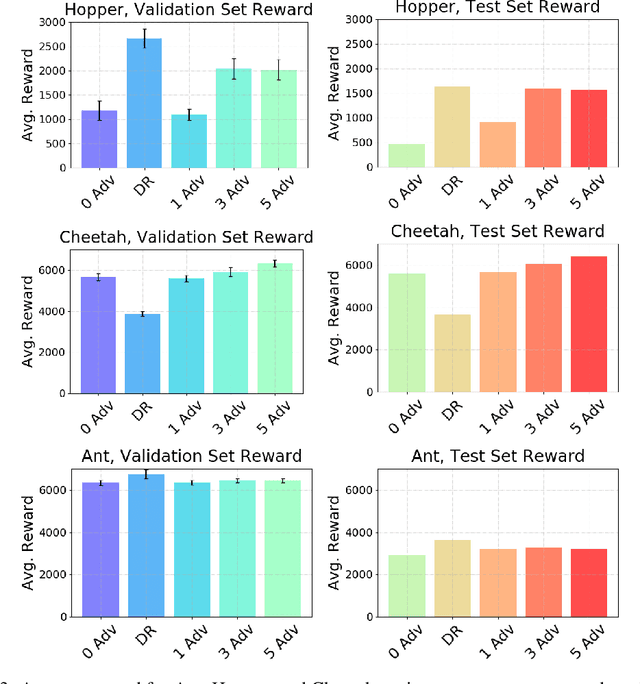
Reinforcement Learning (RL) is an effective tool for controller design but can struggle with issues of robustness, failing catastrophically when the underlying system dynamics are perturbed. The Robust RL formulation tackles this by adding worst-case adversarial noise to the dynamics and constructing the noise distribution as the solution to a zero-sum minimax game. However, existing work on learning solutions to the Robust RL formulation has primarily focused on training a single RL agent against a single adversary. In this work, we demonstrate that using a single adversary does not consistently yield robustness to dynamics variations under standard parametrizations of the adversary; the resulting policy is highly exploitable by new adversaries. We propose a population-based augmentation to the Robust RL formulation in which we randomly initialize a population of adversaries and sample from the population uniformly during training. We empirically validate across robotics benchmarks that the use of an adversarial population results in a more robust policy that also improves out-of-distribution generalization. Finally, we demonstrate that this approach provides comparable robustness and generalization as domain randomization on these benchmarks while avoiding a ubiquitous domain randomization failure mode.
Dynamics Generalization via Information Bottleneck in Deep Reinforcement Learning
Aug 03, 2020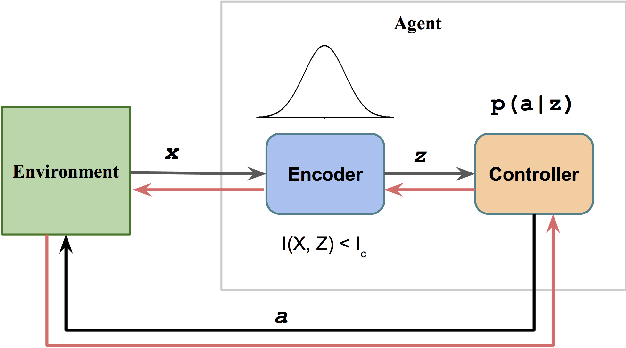
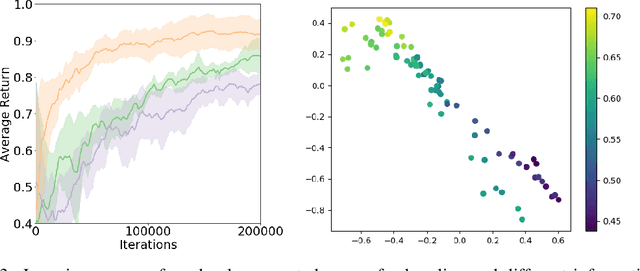
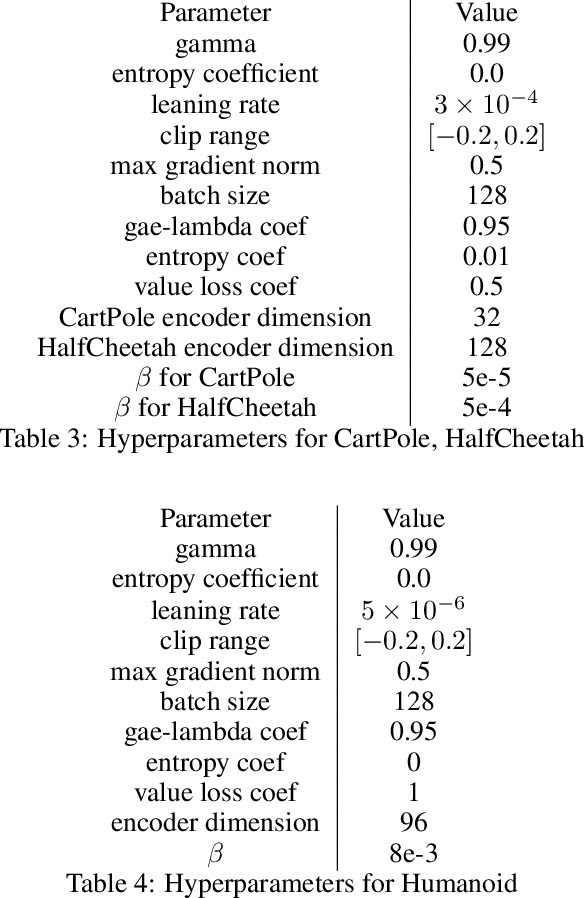
Despite the significant progress of deep reinforcement learning (RL) in solving sequential decision making problems, RL agents often overfit to training environments and struggle to adapt to new, unseen environments. This prevents robust applications of RL in real world situations, where system dynamics may deviate wildly from the training settings. In this work, our primary contribution is to propose an information theoretic regularization objective and an annealing-based optimization method to achieve better generalization ability in RL agents. We demonstrate the extreme generalization benefits of our approach in different domains ranging from maze navigation to robotic tasks; for the first time, we show that agents can generalize to test parameters more than 10 standard deviations away from the training parameter distribution. This work provides a principled way to improve generalization in RL by gradually removing information that is redundant for task-solving; it opens doors for the systematic study of generalization from training to extremely different testing settings, focusing on the established connections between information theory and machine learning.
Efficient Online Estimation of Empowerment for Reinforcement Learning
Jul 14, 2020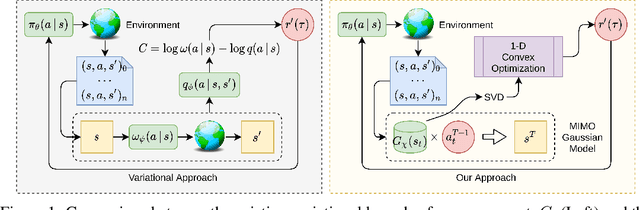
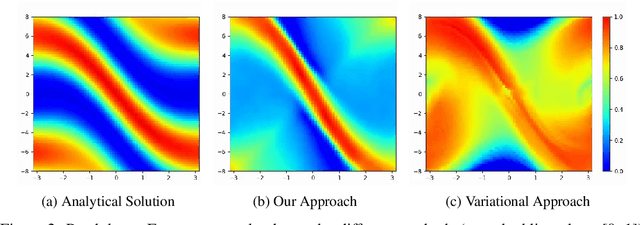
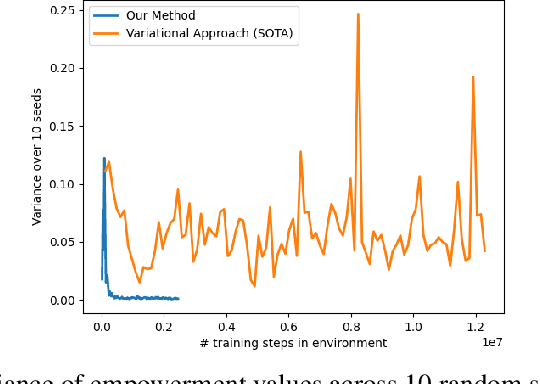
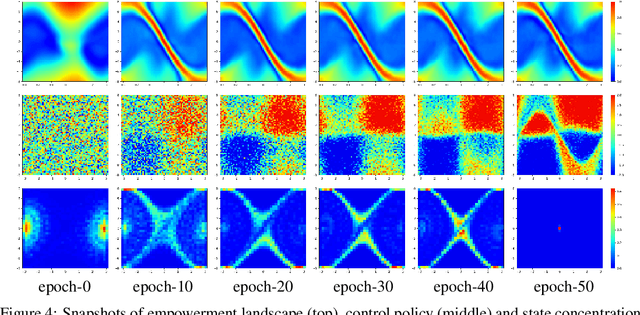
Training artificial agents to acquire desired skills through model-free reinforcement learning (RL) depends heavily on domain-specific knowledge, and the ability to reset the system to desirable configurations for better reward signals. The former hinders generalization to new domains; the latter precludes training in real-life conditions because physical resets are not scalable. Recently, intrinsic motivation was proposed as an alternative objective to alleviate the first issue, but there has been no reasonable remedy for the second. In this work, we present an efficient online algorithm for a type of intrinsic motivation, known as empowerment, and address both limitations. Our method is distinguished by its significantly lower sample and computation complexity, along with improved training stability compared to the relevant state of the art. We achieve this superior efficiency by transforming the challenging empowerment computation into a convex optimization problem through neural networks. In simulations, our method manages to train policies with neither domain-specific knowledge nor manual intervention. To address the issue of resetting in RL, we further show that our approach boosts learning when there's no early termination. Our proposed method opens doors for studying intrinsic motivation for policy training and scaling up model-free RL training in real-life conditions.