 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search of Hybrid Models for NPU-CIM Heterogeneous AR/VR Devices
Oct 10, 2024



Low-Latency and Low-Power Edge AI is essential for Virtual Reality and Augmented Reality applications. Recent advances show that hybrid models, combining convolution layers (CNN) and transformers (ViT), often achieve superior accuracy/performance tradeoff on various computer vision and machine learning (ML) tasks. However, hybrid ML models can pose system challenges for latency and energy-efficiency due to their diverse nature in dataflow and memory access patterns. In this work, we leverage the architecture heterogeneity from Neural Processing Units (NPU) and Compute-In-Memory (CIM) and perform diverse execution schemas to efficiently execute these hybrid models. We also introduce H4H-NAS, a Neural Architecture Search framework to design efficient hybrid CNN/ViT models for heterogeneous edge systems with both NPU and CIM. Our H4H-NAS approach is powered by a performance estimator built with NPU performance results measured on real silicon, and CIM performance based on industry IPs. H4H-NAS searches hybrid CNN/ViT models with fine granularity and achieves significant (up to 1.34%) top-1 accuracy improvement on ImageNet dataset. Moreover, results from our Algo/HW co-design reveal up to 56.08% overall latency and 41.72% energy improvements by introducing such heterogeneous computing over baseline solutions. The framework guides the design of hybrid network architectures and system architectures of NPU+CIM heterogeneous systems.
Practical offloading for fine-tuning LLM on commodity GPU via learned subspace projectors
Jun 14, 2024



Fine-tuning large language models (LLMs) requires significant memory, often exceeding the capacity of a single GPU. A common solution to this memory challenge is offloading compute and data from the GPU to the CPU. However, this approach is hampered by the limited bandwidth of commodity hardware, which constrains communication between the CPU and GPU. In this paper, we present an offloading framework, LSP_Offload, that enables near-native speed LLM fine-tuning on commodity hardware through learned subspace projectors. Our data-driven approach involves learning an efficient sparse compressor that minimizes communication with minimal precision loss. Additionally, we introduce a novel layer-wise communication schedule to maximize parallelism between communication and computation. As a result, our framework can fine-tune a 1.3 billion parameter model on a 4GB laptop GPU and a 7 billion parameter model on an NVIDIA RTX 4090 GPU with 24GB memory, achieving only a 31% slowdown compared to fine-tuning with unlimited memory. Compared to state-of-the-art offloading frameworks, our approach increases fine-tuning throughput by up to 3.33 times and reduces end-to-end fine-tuning time by 33.1%~62.5% when converging to the same accuracy.
RobotPerf: An Open-Source, Vendor-Agnostic, Benchmarking Suite for Evaluating Robotics Computing System Performance
Sep 17, 2023



We introduce RobotPerf, a vendor-agnostic benchmarking suite designed to evaluate robotics computing performance across a diverse range of hardware platforms using ROS 2 as its common baseline. The suite encompasses ROS 2 packages covering the full robotics pipeline and integrates two distinct benchmarking approaches: black-box testing, which measures performance by eliminating upper layers and replacing them with a test application, and grey-box testing, an application-specific measure that observes internal system states with minimal interference. Our benchmarking framework provides ready-to-use tools and is easily adaptable for the assessment of custom ROS 2 computational graphs. Drawing from the knowledge of leading robot architects and system architecture experts, RobotPerf establishes a standardized approach to robotics benchmarking. As an open-source initiative, RobotPerf remains committed to evolving with community input to advance the future of hardware-accelerated robotics.
ACRoBat: Optimizing Auto-batching of Dynamic Deep Learning at Compile Time
May 17, 2023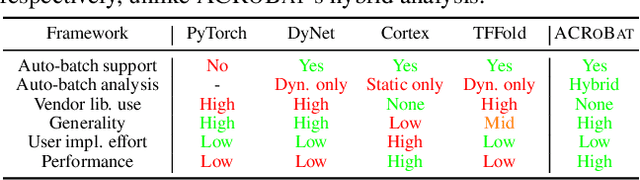
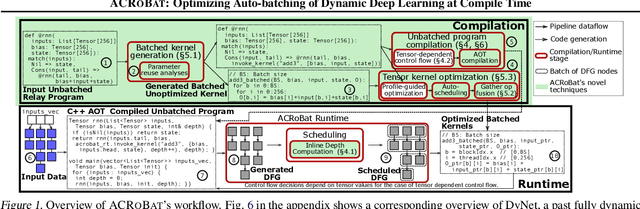

Dynamic control flow is an important technique often used to design expressive and efficient deep learning computations for applications such as text parsing, machine translation, exiting early out of deep models and so on. However, the resulting control flow divergence makes batching, an important performance optimization, difficult to perform manually. In this paper, we present ACRoBat, a framework that enables efficient automatic batching for dynamic deep learning computations by performing hybrid static+dynamic compiler optimizations and end-to-end tensor code generation. ACRoBat performs up to 8.5X better than DyNet, a state-of-the-art framework for automatic batching, on an Nvidia GeForce RTX 3070 GPU.
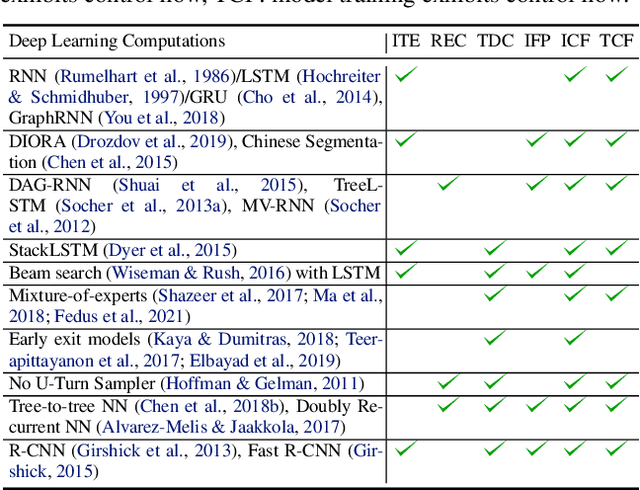
ED-Batch: Efficient Automatic Batching of Dynamic Neural Networks via Learned Finite State Machines
Feb 08, 2023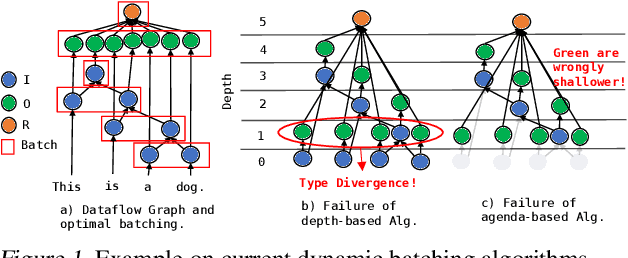
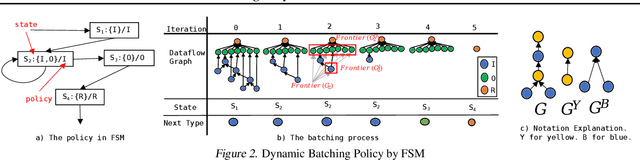
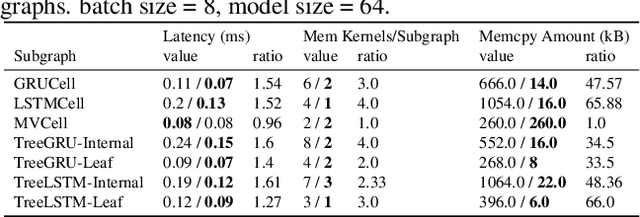
Batching has a fundamental influence on the efficiency of deep neural network (DNN) execution. However, for dynamic DNNs, efficient batching is particularly challenging as the dataflow graph varies per input instance. As a result, state-of-the-art frameworks use heuristics that result in suboptimal batching decisions. Further, batching puts strict restrictions on memory adjacency and can lead to high data movement costs. In this paper, we provide an approach for batching dynamic DNNs based on finite state machines, which enables the automatic discovery of batching policies specialized for each DNN via reinforcement learning. Moreover, we find that memory planning that is aware of the batching policy can save significant data movement overheads, which is automated by a PQ tree-based algorithm we introduce. Experimental results show that our framework speeds up state-of-the-art frameworks by on average 1.15x, 1.39x, and 2.45x for chain-based, tree-based, and lattice-based DNNs across CPU and GPU.
Federated Learning under Distributed Concept Drift
Jun 01, 2022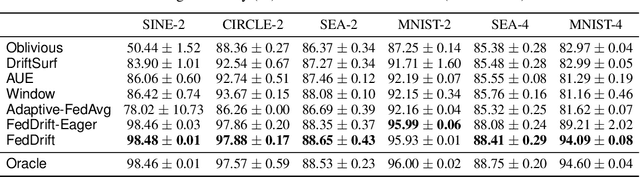


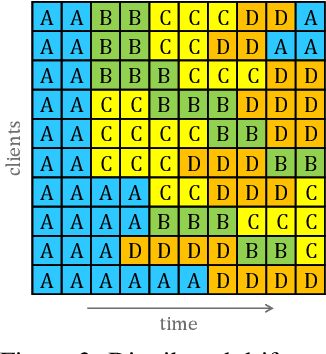
Federated Learning (FL) under distributed concept drift is a largely unexplored area. Although concept drift is itself a well-studied phenomenon, it poses particular challenges for FL, because drifts arise staggered in time and space (across clients). Our work is the first to explicitly study data heterogeneity in both dimensions. We first demonstrate that prior solutions to drift adaptation, with their single global model, are ill-suited to staggered drifts, necessitating multi-model solutions. We identify the problem of drift adaptation as a time-varying clustering problem, and we propose two new clustering algorithms for reacting to drifts based on local drift detection and hierarchical clustering. Empirical evaluation shows that our solutions achieve significantly higher accuracy than existing baselines, and are comparable to an idealized algorithm with oracle knowledge of the ground-truth clustering of clients to concepts at each time step.
The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding
Oct 29, 2021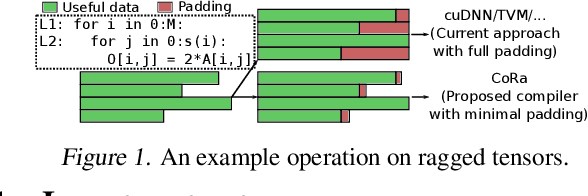
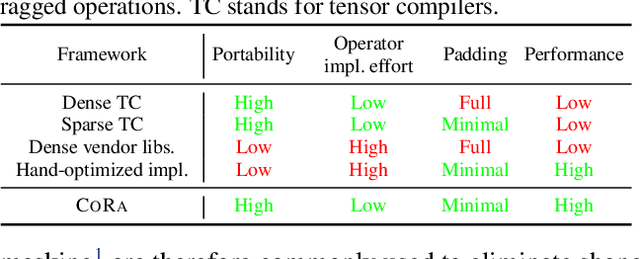
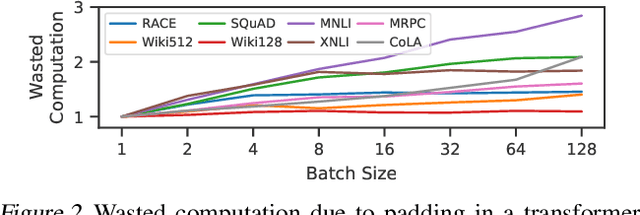
There is often variation in the shape and size of input data used for deep learning. In many cases, such data can be represented using tensors with non-uniform shapes, or ragged tensors. Due to limited and non-portable support for efficient execution on ragged tensors, current deep learning frameworks generally use techniques such as padding and masking to make the data shapes uniform and then offload the computations to optimized kernels for dense tensor algebra. Such techniques can, however, lead to a lot of wasted computation and therefore, a loss in performance. This paper presents CoRa, a tensor compiler that allows users to easily generate efficient code for ragged tensor operators targeting a wide range of CPUs and GPUs. Evaluating CoRa on a variety of operators on ragged tensors as well as on an encoder layer of the transformer model, we find that CoRa (i)performs competitively with hand-optimized implementations of the operators and the transformer encoder and (ii) achieves, over PyTorch, a 1.6X geomean speedup for the encoder on an Nvidia GPU and a 1.86X geomean speedup for the multi-head attention module used in transformers on an ARM CPU.
DriftSurf: A Risk-competitive Learning Algorithm under Concept Drift
Mar 13, 2020
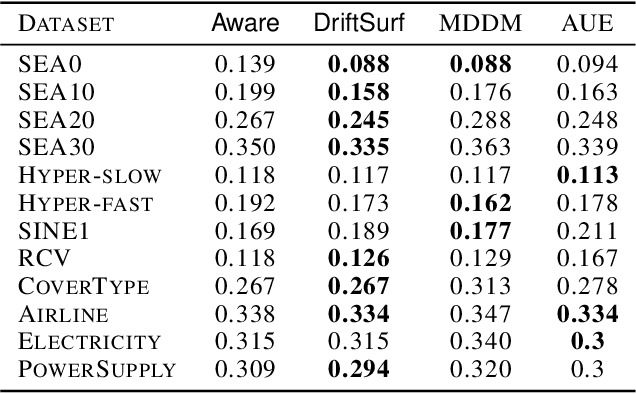

When learning from streaming data, a change in the data distribution, also known as concept drift, can render a previously-learned model inaccurate and require training a new model. We present an adaptive learning algorithm that extends previous drift-detection-based methods by incorporating drift detection into a broader stable-state/reactive-state process. The advantage of our approach is that we can use aggressive drift detection in the stable state to achieve a high detection rate, but mitigate the false positive rate of standalone drift detection via a reactive state that reacts quickly to true drifts while eliminating most false positives. The algorithm is generic in its base learner and can be applied across a variety of supervised learning problems. Our theoretical analysis shows that the risk of the algorithm is competitive to an algorithm with oracle knowledge of when (abrupt) drifts occur. Experiments on synthetic and real datasets with concept drifts confirm our theoretical analysis.
Advances and Open Problems in Federated Learning
Dec 10, 2019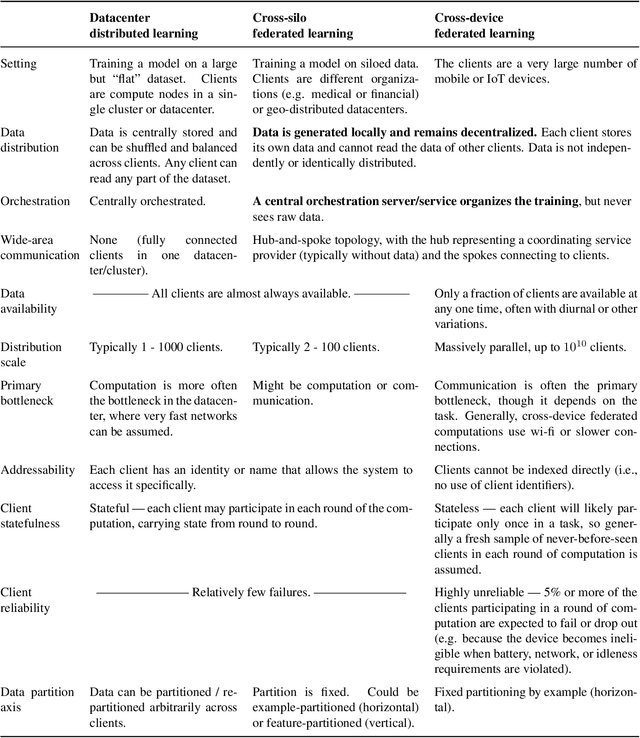
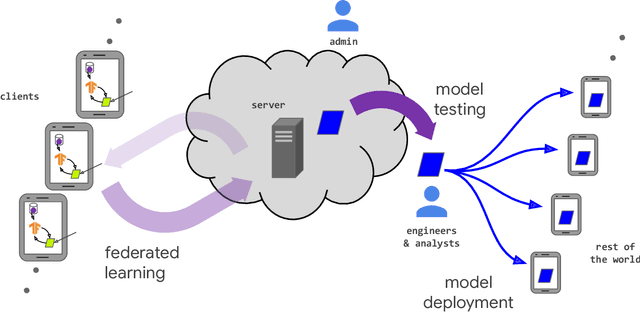
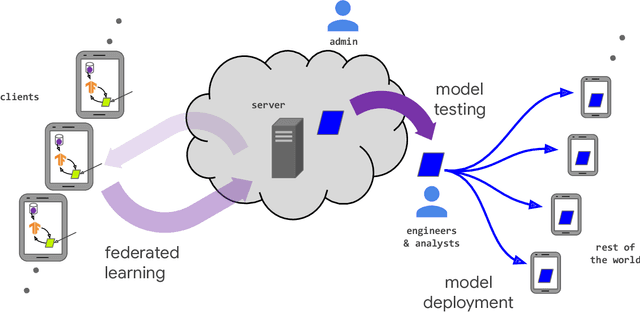

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
The Non-IID Data Quagmire of Decentralized Machine Learning
Oct 01, 2019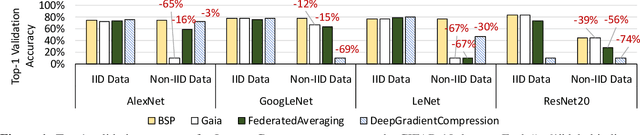
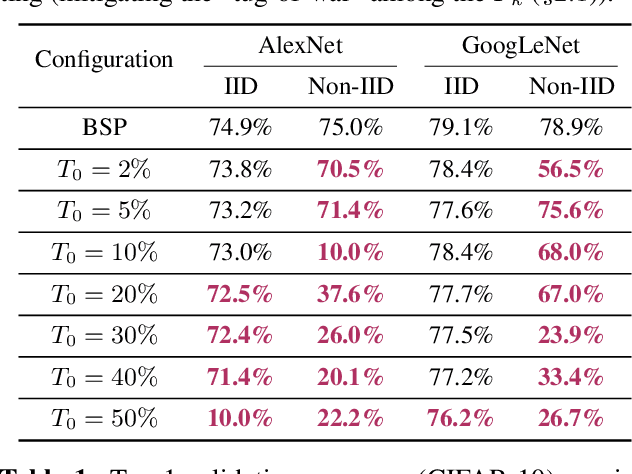
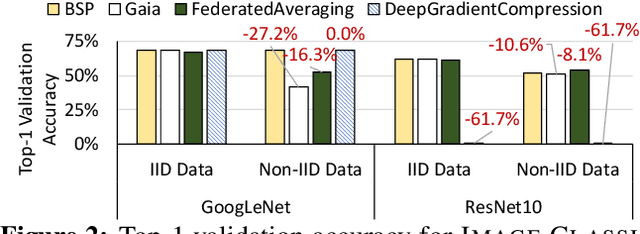

Many large-scale machine learning (ML) applications need to train ML models over decentralized datasets that are generated at different devices and locations. These decentralized datasets pose a fundamental challenge to ML because they are typically generated in very different contexts, which leads to significant differences in data distribution across devices/locations (i.e., they are not independent and identically distributed (IID)). In this work, we take a step toward better understanding this challenge, by presenting the first detailed experimental study of the impact of such non-IID data on the decentralized training of deep neural networks (DNNs). Our study shows that: (i) the problem of non-IID data partitions is fundamental and pervasive, as it exists in all ML applications, DNN models, training datasets, and decentralized learning algorithms in our study; (ii) this problem is particularly difficult for DNN models with batch normalization layers; and (iii) the degree of deviation from IID (the skewness) is a key determinant of the difficulty level of the problem. With these findings in mind, we present SkewScout, a system-level approach that adapts the communication frequency of decentralized learning algorithms to the (skew-induced) accuracy loss between data partitions. We also show that group normalization can recover much of the skew-induced accuracy loss of batch normalization.