 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Safe Evaluation For Offline Learning: Are We Ready To Deploy?
Dec 16, 2022The world currently offers an abundance of data in multiple domains, from which we can learn reinforcement learning (RL) policies without further interaction with the environment. RL agents learning offline from such data is possible but deploying them while learning might be dangerous in domains where safety is critical. Therefore, it is essential to find a way to estimate how a newly-learned agent will perform if deployed in the target environment before actually deploying it and without the risk of overestimating its true performance. To achieve this, we introduce a framework for safe evaluation of offline learning using approximate high-confidence off-policy evaluation (HCOPE) to estimate the performance of offline policies during learning. In our setting, we assume a source of data, which we split into a train-set, to learn an offline policy, and a test-set, to estimate a lower-bound on the offline policy using off-policy evaluation with bootstrapping. A lower-bound estimate tells us how good a newly-learned target policy would perform before it is deployed in the real environment, and therefore allows us to decide when to deploy our learned policy.
Learning to Correct Mistakes: Backjumping in Long-Horizon Task and Motion Planning
Nov 15, 2022



As robots become increasingly capable of manipulation and long-term autonomy, long-horizon task and motion planning problems are becoming increasingly important. A key challenge in such problems is that early actions in the plan may make future actions infeasible. When reaching a dead-end in the search, most existing planners use backtracking, which exhaustively reevaluates motion-level actions, often resulting in inefficient planning, especially when the search depth is large. In this paper, we propose to learn backjumping heuristics which identify the culprit action directly using supervised learning models to guide the task-level search. Based on evaluations on two different tasks, we find that our method significantly improves planning efficiency compared to backtracking and also generalizes to problems with novel numbers of objects.
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
Nov 08, 2022Given a dataset of expert agent interactions with an environment of interest, a viable method to extract an effective agent policy is to estimate the maximum likelihood policy indicated by this data. This approach is commonly referred to as behavioral cloning (BC). In this work, we describe a key disadvantage of BC that arises due to the maximum likelihood objective function; namely that BC is mean-seeking with respect to the state-conditional expert action distribution when the learner's policy is represented with a Gaussian. To address this issue, we introduce a modified version of BC, Adversarial Behavioral Cloning (ABC), that exhibits mode-seeking behavior by incorporating elements of GAN (generative adversarial network) training. We evaluate ABC on toy domains and a domain based on Hopper from the DeepMind Control suite, and show that it outperforms standard BC by being mode-seeking in nature.
Event Tables for Efficient Experience Replay
Nov 01, 2022Experience replay (ER) is a crucial component of many deep reinforcement learning (RL) systems. However, uniform sampling from an ER buffer can lead to slow convergence and unstable asymptotic behaviors. This paper introduces Stratified Sampling from Event Tables (SSET), which partitions an ER buffer into Event Tables, each capturing important subsequences of optimal behavior. We prove a theoretical advantage over the traditional monolithic buffer approach and combine SSET with an existing prioritized sampling strategy to further improve learning speed and stability. Empirical results in challenging MiniGrid domains, benchmark RL environments, and a high-fidelity car racing simulator demonstrate the advantages and versatility of SSET over existing ER buffer sampling approaches.
Artificial Intelligence and Life in 2030: The One Hundred Year Study on Artificial Intelligence
Oct 31, 2022In September 2016, Stanford's "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the first report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Peter Stone of the University of Texas at Austin. The report, entitled "Artificial Intelligence and Life in 2030," examines eight domains of typical urban settings on which AI is likely to have impact over the coming years: transportation, home and service robots, healthcare, education, public safety and security, low-resource communities, employment and workplace, and entertainment. It aims to provide the general public with a scientifically and technologically accurate portrayal of the current state of AI and its potential and to help guide decisions in industry and governments, as well as to inform research and development in the field. The charge for this report was given to the panel by the AI100 Standing Committee, chaired by Barbara Grosz of Harvard University.
D-Shape: Demonstration-Shaped Reinforcement Learning via Goal Conditioning
Oct 26, 2022



While combining imitation learning (IL) and reinforcement learning (RL) is a promising way to address poor sample efficiency in autonomous behavior acquisition, methods that do so typically assume that the requisite behavior demonstrations are provided by an expert that behaves optimally with respect to a task reward. If, however, suboptimal demonstrations are provided, a fundamental challenge appears in that the demonstration-matching objective of IL conflicts with the return-maximization objective of RL. This paper introduces D-Shape, a new method for combining IL and RL that uses ideas from reward shaping and goal-conditioned RL to resolve the above conflict. D-Shape allows learning from suboptimal demonstrations while retaining the ability to find the optimal policy with respect to the task reward. We experimentally validate D-Shape in sparse-reward gridworld domains, showing that it both improves over RL in terms of sample efficiency and converges consistently to the optimal policy in the presence of suboptimal demonstrations.
VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors
Oct 20, 2022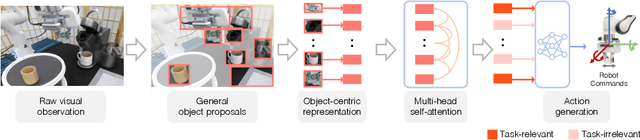
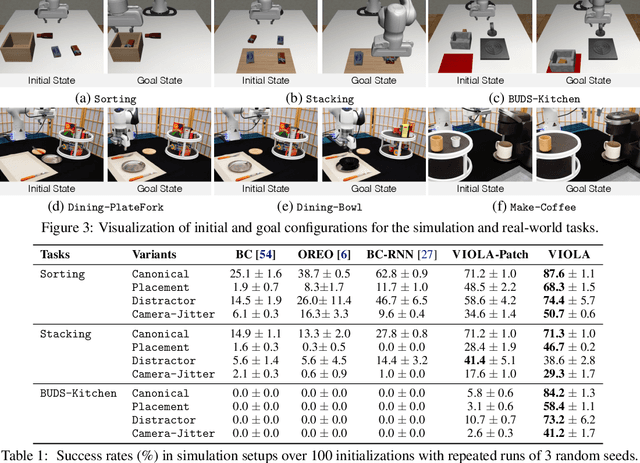
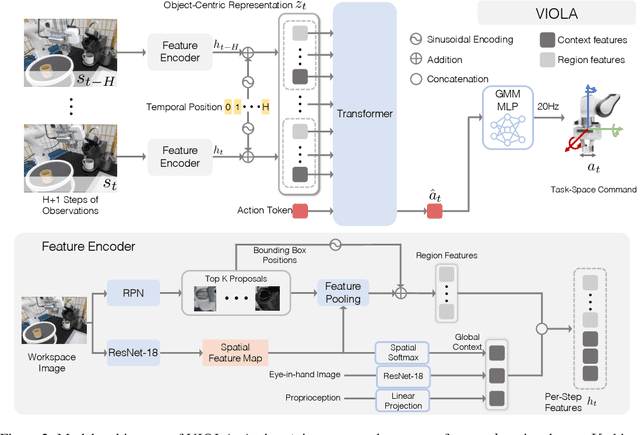
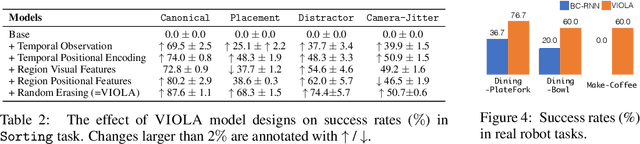
We introduce VIOLA, an object-centric imitation learning approach to learning closed-loop visuomotor policies for robot manipulation. Our approach constructs object-centric representations based on general object proposals from a pre-trained vision model. VIOLA uses a transformer-based policy to reason over these representations and attend to the task-relevant visual factors for action prediction. Such object-based structural priors improve deep imitation learning algorithm's robustness against object variations and environmental perturbations. We quantitatively evaluate VIOLA in simulation and on real robots. VIOLA outperforms the state-of-the-art imitation learning methods by $45.8\%$ in success rate. It has also been deployed successfully on a physical robot to solve challenging long-horizon tasks, such as dining table arrangement and coffee making. More videos and model details can be found in supplementary material and the project website: https://ut-austin-rpl.github.io/VIOLA .
Learning Real-world Autonomous Navigation by Self-Supervised Environment Synthesis
Oct 10, 2022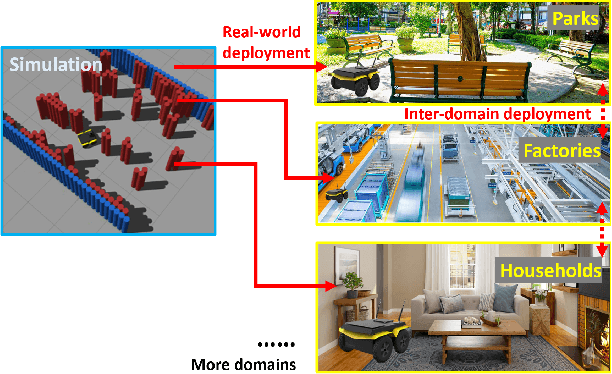
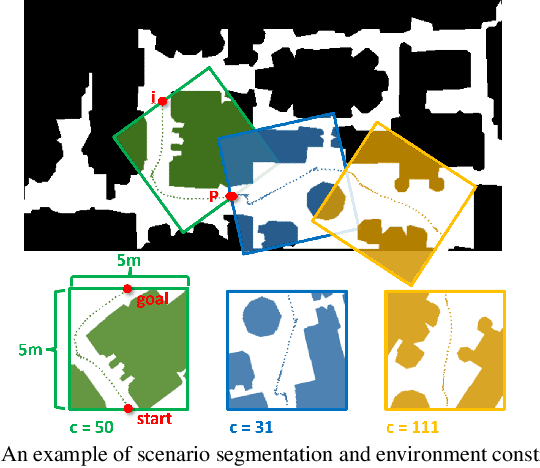
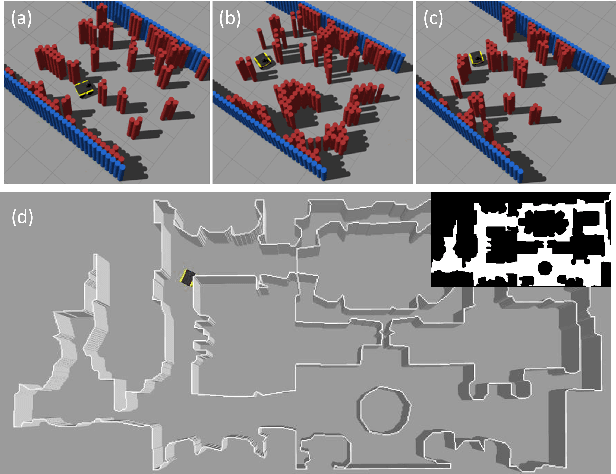

Machine learning approaches have recently enabled autonomous navigation for mobile robots in a data-driven manner. Since most existing learning-based navigation systems are trained with data generated in artificially created training environments, during real-world deployment at scale, it is inevitable that robots will encounter unseen scenarios, which are out of the training distribution and therefore lead to poor real-world performance. On the other hand, directly training in the real world is generally unsafe and inefficient. To address this issue, we introduce Self-supervised Environment Synthesis (SES), in which, after real-world deployment with safety and efficiency requirements, autonomous mobile robots can utilize experience from the real-world deployment, reconstruct navigation scenarios, and synthesize representative training environments in simulation. Training in these synthesized environments leads to improved future performance in the real world. The effectiveness of SES at synthesizing representative simulation environments and improving real-world navigation performance is evaluated via a large-scale deployment in a high-fidelity, realistic simulator and a small-scale deployment on a physical robot.
Benchmarking Reinforcement Learning Techniques for Autonomous Navigation
Oct 10, 2022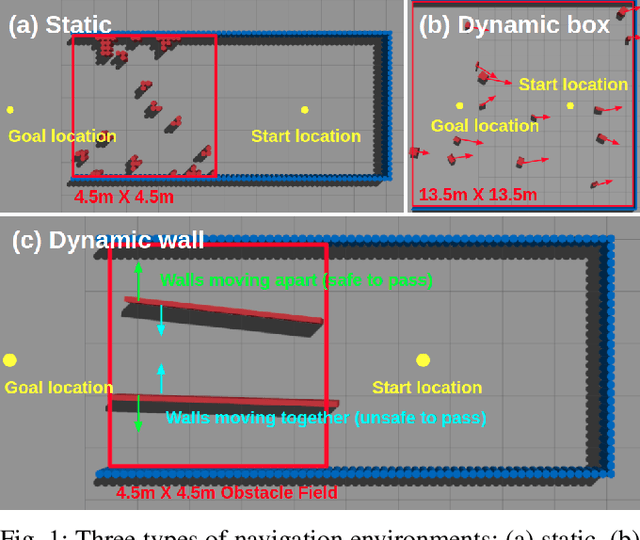
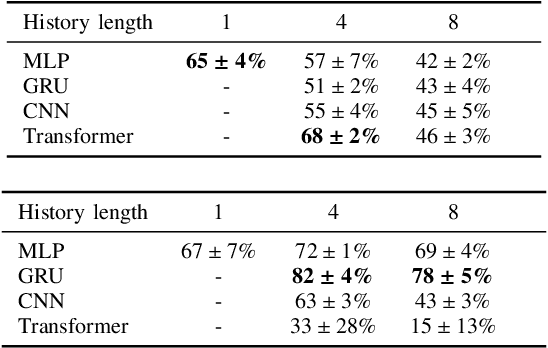

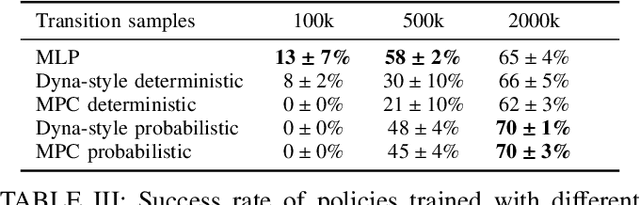
Deep reinforcement learning (RL) has brought many successes for autonomous robot navigation. However, there still exists important limitations that prevent real-world use of RL-based navigation systems. For example, most learning approaches lack safety guarantees; and learned navigation systems may not generalize well to unseen environments. Despite a variety of recent learning techniques to tackle these challenges in general, a lack of an open-source benchmark and reproducible learning methods specifically for autonomous navigation makes it difficult for roboticists to choose what learning methods to use for their mobile robots and for learning researchers to identify current shortcomings of general learning methods for autonomous navigation. In this paper, we identify four major desiderata of applying deep RL approaches for autonomous navigation: (D1) reasoning under uncertainty, (D2) safety, (D3) learning from limited trial-and-error data, and (D4) generalization to diverse and novel environments. Then, we explore four major classes of learning techniques with the purpose of achieving one or more of the four desiderata: memory-based neural network architectures (D1), safe RL (D2), model-based RL (D2, D3), and domain randomization (D4). By deploying these learning techniques in a new open-source large-scale navigation benchmark and real-world environments, we perform a comprehensive study aimed at establishing to what extent can these techniques achieve these desiderata for RL-based navigation systems.