 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Mutation Rate Adaptation through Group Elite Selection
Apr 11, 2022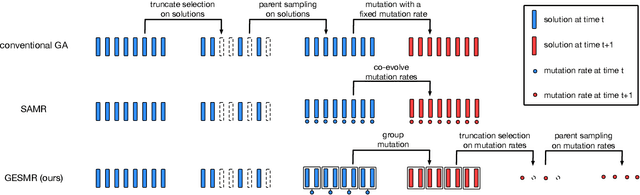
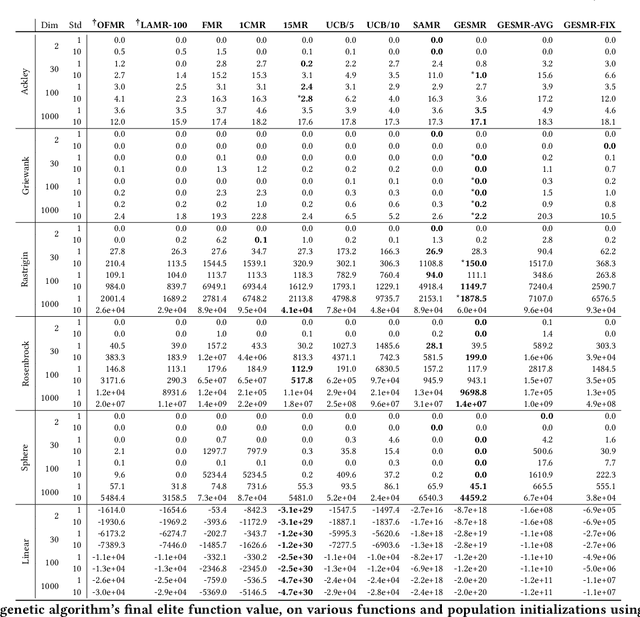
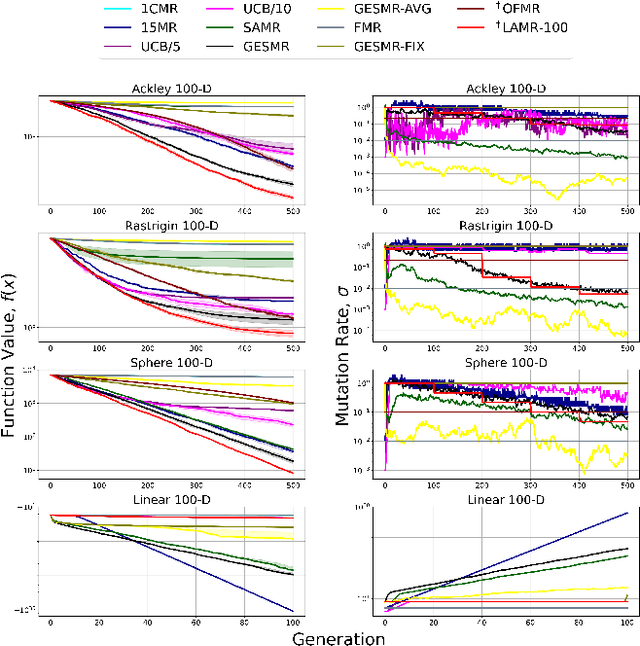
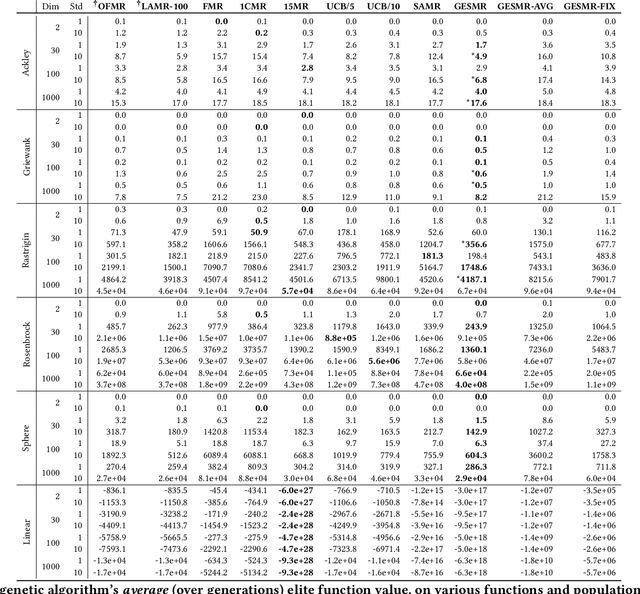
Evolutionary algorithms are sensitive to the mutation rate (MR); no single value of this parameter works well across domains. Self-adaptive MR approaches have been proposed but they tend to be brittle: Sometimes they decay the MR to zero, thus halting evolution. To make self-adaptive MR robust, this paper introduces the Group Elite Selection of Mutation Rates (GESMR) algorithm. GESMR co-evolves a population of solutions and a population of MRs, such that each MR is assigned to a group of solutions. The resulting best mutational change in the group, instead of average mutational change, is used for MR selection during evolution, thus avoiding the vanishing MR problem. With the same number of function evaluations and with almost no overhead, GESMR converges faster and to better solutions than previous approaches on a wide range of continuous test optimization problems. GESMR also scales well to high-dimensional neuroevolution for supervised image-classification tasks and for reinforcement learning control tasks. Remarkably, GESMR produces MRs that are optimal in the long-term, as demonstrated through a comprehensive look-ahead grid search. Thus, GESMR and its theoretical and empirical analysis demonstrate how self-adaptation can be harnessed to improve performance in several applications of evolutionary computation.
VI-IKD: High-Speed Accurate Off-Road Navigation using Learned Visual-Inertial Inverse Kinodynamics
Mar 30, 2022
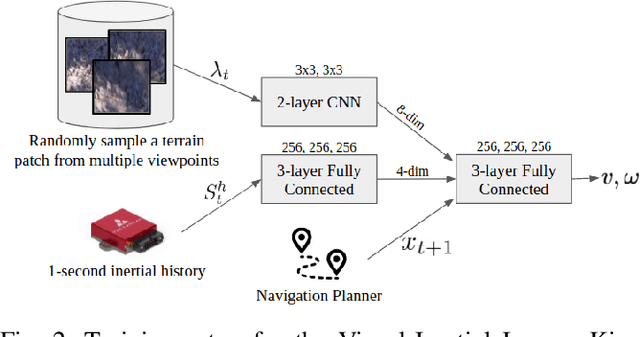


One of the key challenges in high speed off road navigation on ground vehicles is that the kinodynamics of the vehicle terrain interaction can differ dramatically depending on the terrain. Previous approaches to addressing this challenge have considered learning an inverse kinodynamics (IKD) model, conditioned on inertial information of the vehicle to sense the kinodynamic interactions. In this paper, we hypothesize that to enable accurate high-speed off-road navigation using a learned IKD model, in addition to inertial information from the past, one must also anticipate the kinodynamic interactions of the vehicle with the terrain in the future. To this end, we introduce Visual-Inertial Inverse Kinodynamics (VI-IKD), a novel learning based IKD model that is conditioned on visual information from a terrain patch ahead of the robot in addition to past inertial information, enabling it to anticipate kinodynamic interactions in the future. We validate the effectiveness of VI-IKD in accurate high-speed off-road navigation experimentally on a scale 1/5 UT-AlphaTruck off-road autonomous vehicle in both indoor and outdoor environments and show that compared to other state-of-the-art approaches, VI-IKD enables more accurate and robust off-road navigation on a variety of different terrains at speeds of up to 3.5 m/s.
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022


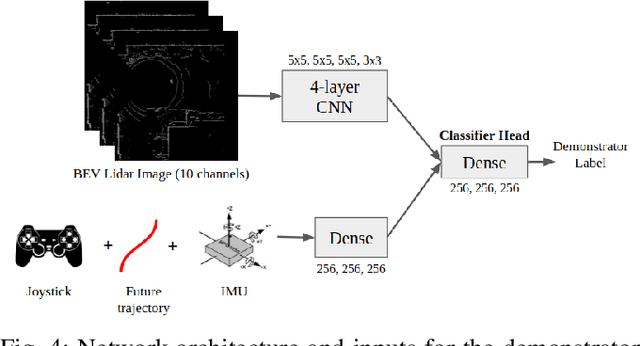
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
Continual Learning and Private Unlearning
Mar 24, 2022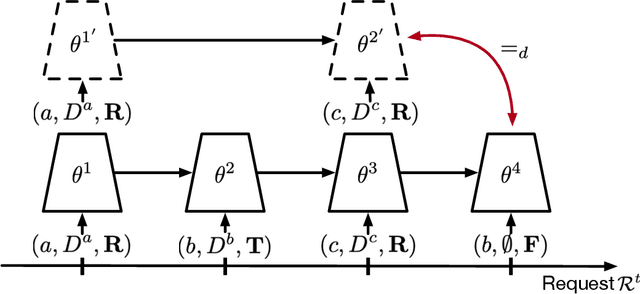
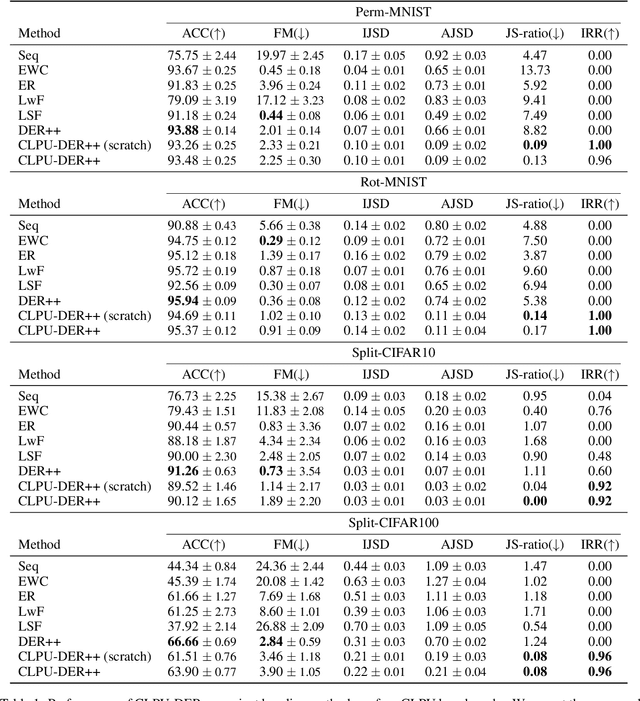
As intelligent agents become autonomous over longer periods of time, they may eventually become lifelong counterparts to specific people. If so, it may be common for a user to want the agent to master a task temporarily but later on to forget the task due to privacy concerns. However enabling an agent to \emph{forget privately} what the user specified without degrading the rest of the learned knowledge is a challenging problem. With the aim of addressing this challenge, this paper formalizes this continual learning and private unlearning (CLPU) problem. The paper further introduces a straightforward but exactly private solution, CLPU-DER++, as the first step towards solving the CLPU problem, along with a set of carefully designed benchmark problems to evaluate the effectiveness of the proposed solution.
Visually Grounded Task and Motion Planning for Mobile Manipulation
Feb 24, 2022
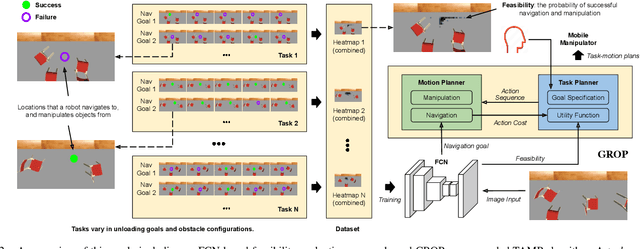
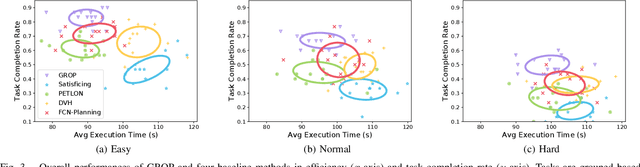
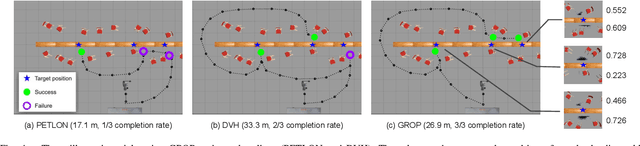
Task and motion planning (TAMP) algorithms aim to help robots achieve task-level goals, while maintaining motion-level feasibility. This paper focuses on TAMP domains that involve robot behaviors that take extended periods of time (e.g., long-distance navigation). In this paper, we develop a visual grounding approach to help robots probabilistically evaluate action feasibility, and introduce a TAMP algorithm, called GROP, that optimizes both feasibility and efficiency. We have collected a dataset that includes 96,000 simulated trials of a robot conducting mobile manipulation tasks, and then used the dataset to learn to ground symbolic spatial relationships for action feasibility evaluation. Compared with competitive TAMP baselines, GROP exhibited a higher task-completion rate while maintaining lower or comparable action costs. In addition to these extensive experiments in simulation, GROP is fully implemented and tested on a real robot system.
Learning a Shield from Catastrophic Action Effects: Never Repeat the Same Mistake
Feb 19, 2022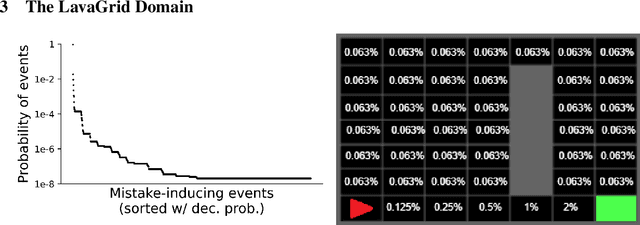
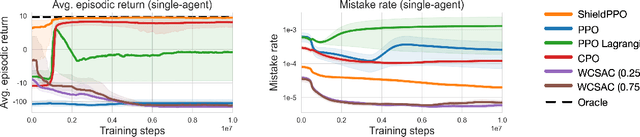
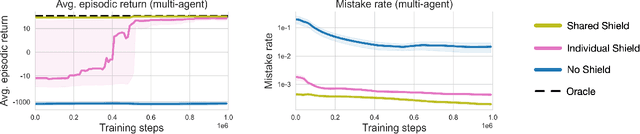
Agents that operate in an unknown environment are bound to make mistakes while learning, including, at least occasionally, some that lead to catastrophic consequences. When humans make catastrophic mistakes, they are expected to learn never to repeat them, such as a toddler who touches a hot stove and immediately learns never to do so again. In this work we consider a novel class of POMDPs, called POMDP with Catastrophic Actions (POMDP-CA) in which pairs of states and actions are labeled as catastrophic. Agents that act in a POMDP-CA do not have a priori knowledge about which (state, action) pairs are catastrophic, thus they are sure to make mistakes when trying to learn any meaningful policy. Rather, their aim is to maximize reward while never repeating mistakes. As a first step of avoiding mistake repetition, we leverage the concept of a shield which prevents agents from executing specific actions from specific states. In particular, we store catastrophic mistakes (unsafe pairs of states and actions) that agents make in a database. Agents are then forbidden to pick actions that appear in the database. This approach is especially useful in a continual learning setting, where groups of agents perform a variety of tasks over time in the same underlying environment. In this setting, a task-agnostic shield can be constructed in a way that stores mistakes made by any agent, such that once one agent in a group makes a mistake the entire group learns to never repeat that mistake. This paper introduces a variant of the PPO algorithm that utilizes this shield, called ShieldPPO, and empirically evaluates it in a controlled environment. Results indicate that ShieldPPO outperforms PPO, as well as baseline methods from the safe reinforcement learning literature, in a range of settings.
A Survey of Ad Hoc Teamwork: Definitions, Methods, and Open Problems
Feb 16, 2022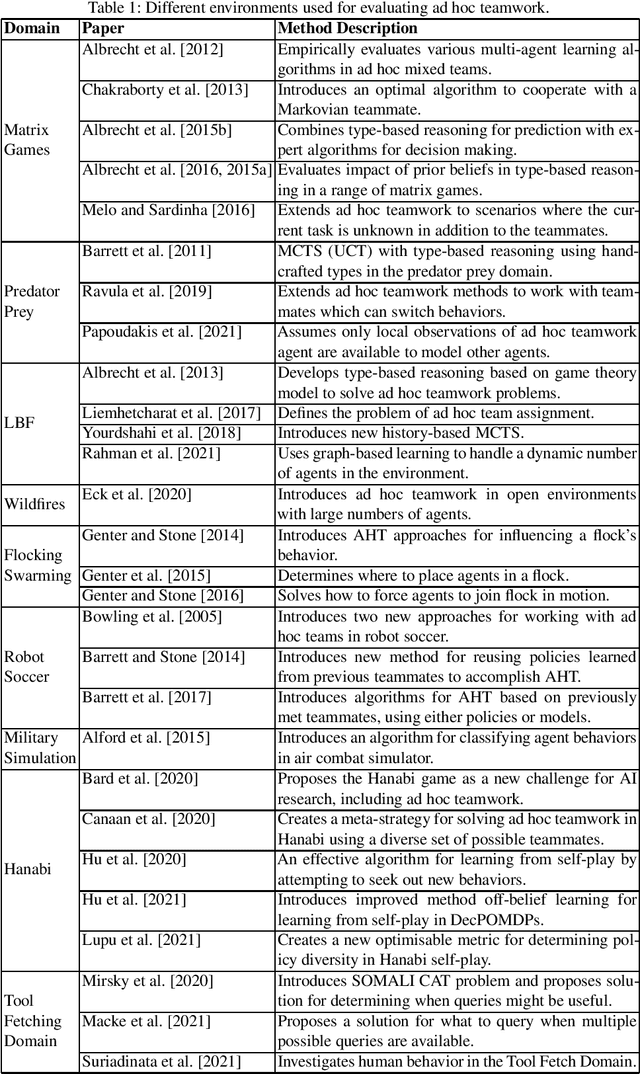
Ad hoc teamwork is the well-established research problem of designing agents that can collaborate with new teammates without prior coordination. This survey makes a two-fold contribution. First, it provides a structured description of the different facets of the ad hoc teamwork problem. Second, it discusses the progress that has been made in the field so far, and identifies the immediate and long-term open problems that need to be addressed in the field of ad hoc teamwork.
Adversarial Imitation Learning from Video using a State Observer
Feb 01, 2022
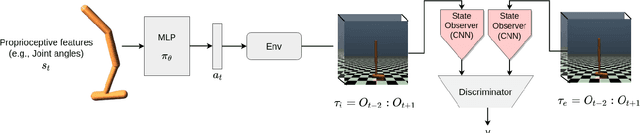
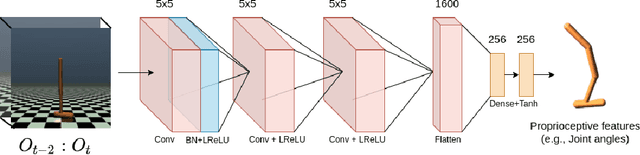
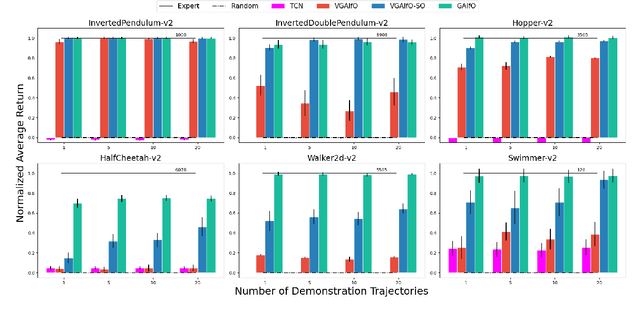
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.
Learning a Robust Multiagent Driving Policy for Traffic Congestion Reduction
Dec 03, 2021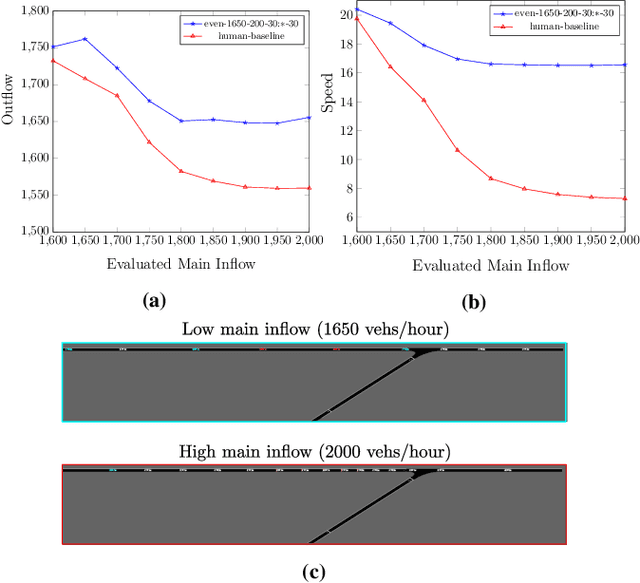
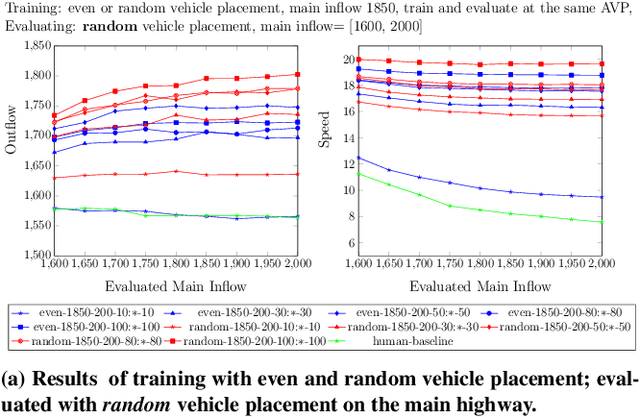

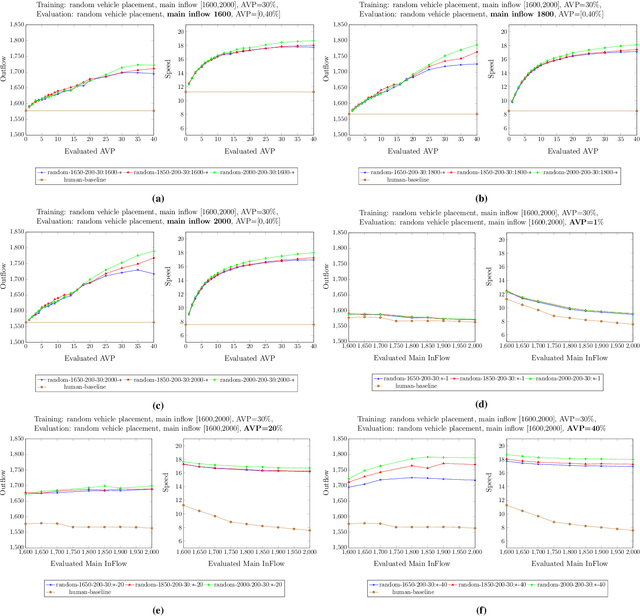
The advent of automated and autonomous vehicles (AVs) creates opportunities to achieve system-level goals using multiple AVs, such as traffic congestion reduction. Past research has shown that multiagent congestion-reducing driving policies can be learned in a variety of simulated scenarios. While initial proofs of concept were in small, closed traffic networks with a centralized controller, recently successful results have been demonstrated in more realistic settings with distributed control policies operating in open road networks where vehicles enter and leave. However, these driving policies were mostly tested under the same conditions they were trained on, and have not been thoroughly tested for robustness to different traffic conditions, which is a critical requirement in real-world scenarios. This paper presents a learned multiagent driving policy that is robust to a variety of open-network traffic conditions, including vehicle flows, the fraction of AVs in traffic, AV placement, and different merging road geometries. A thorough empirical analysis investigates the sensitivity of such a policy to the amount of AVs in both a simple merge network and a more complex road with two merging ramps. It shows that the learned policy achieves significant improvement over simulated human-driven policies even with AV penetration as low as 2%. The same policy is also shown to be capable of reducing traffic congestion in more complex roads with two merging ramps.
Conflict-Averse Gradient Descent for Multi-task Learning
Oct 26, 2021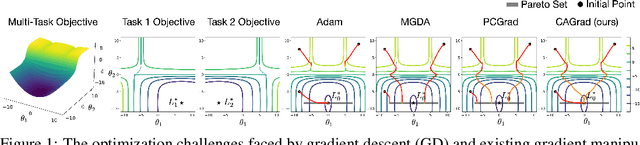
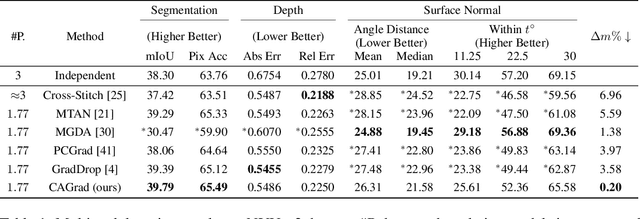
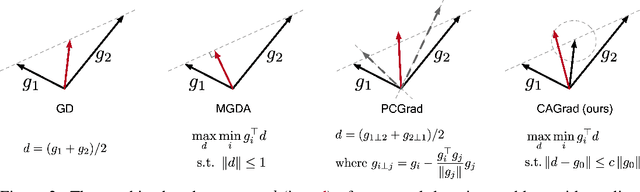
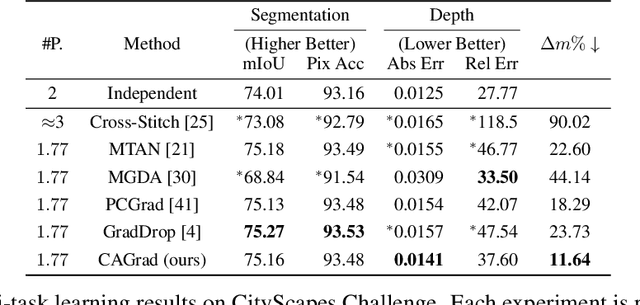
The goal of multi-task learning is to enable more efficient learning than single task learning by sharing model structures for a diverse set of tasks. A standard multi-task learning objective is to minimize the average loss across all tasks. While straightforward, using this objective often results in much worse final performance for each task than learning them independently. A major challenge in optimizing a multi-task model is the conflicting gradients, where gradients of different task objectives are not well aligned so that following the average gradient direction can be detrimental to specific tasks' performance. Previous work has proposed several heuristics to manipulate the task gradients for mitigating this problem. But most of them lack convergence guarantee and/or could converge to any Pareto-stationary point. In this paper, we introduce Conflict-Averse Gradient descent (CAGrad) which minimizes the average loss function, while leveraging the worst local improvement of individual tasks to regularize the algorithm trajectory. CAGrad balances the objectives automatically and still provably converges to a minimum over the average loss. It includes the regular gradient descent (GD) and the multiple gradient descent algorithm (MGDA) in the multi-objective optimization (MOO) literature as special cases. On a series of challenging multi-task supervised learning and reinforcement learning tasks, CAGrad achieves improved performance over prior state-of-the-art multi-objective gradient manipulation methods.