 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacets of Disparate Impact: Evaluating Legally Consistent Bias in Machine Learning
May 08, 2025Leveraging current legal standards, we define bias through the lens of marginal benefits and objective testing with the novel metric "Objective Fairness Index". This index combines the contextual nuances of objective testing with metric stability, providing a legally consistent and reliable measure. Utilizing the Objective Fairness Index, we provide fresh insights into sensitive machine learning applications, such as COMPAS (recidivism prediction), highlighting the metric's practical and theoretical significance. The Objective Fairness Index allows one to differentiate between discriminatory tests and systemic disparities.
Algorithmic Accountability in Small Data: Sample-Size-Induced Bias Within Classification Metrics
May 06, 2025Evaluating machine learning models is crucial not only for determining their technical accuracy but also for assessing their potential societal implications. While the potential for low-sample-size bias in algorithms is well known, we demonstrate the significance of sample-size bias induced by combinatorics in classification metrics. This revelation challenges the efficacy of these metrics in assessing bias with high resolution, especially when comparing groups of disparate sizes, which frequently arise in social applications. We provide analyses of the bias that appears in several commonly applied metrics and propose a model-agnostic assessment and correction technique. Additionally, we analyze counts of undefined cases in metric calculations, which can lead to misleading evaluations if improperly handled. This work illuminates the previously unrecognized challenge of combinatorics and probability in standard evaluation practices and thereby advances approaches for performing fair and trustworthy classification methods.
Lucid Dreaming for Experience Replay: Refreshing Past States with the Current Policy
Sep 29, 2020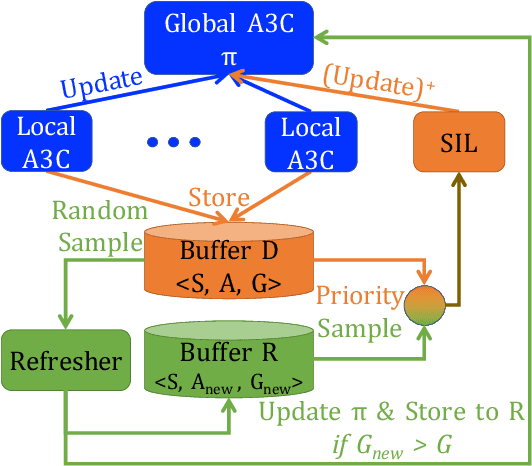

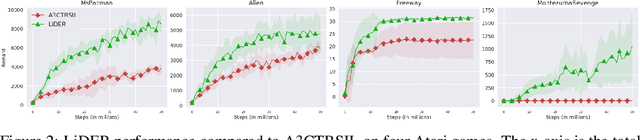
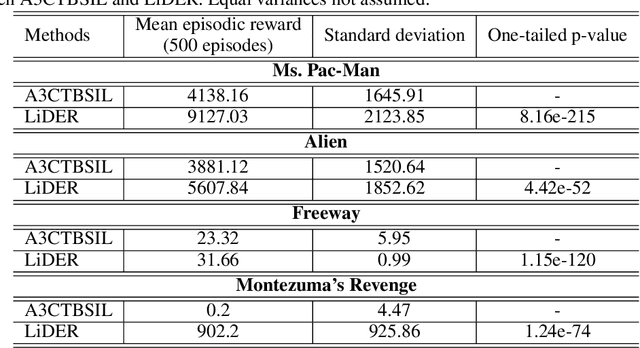
Experience replay (ER) improves the data efficiency of off-policy reinforcement learning (RL) algorithms by allowing an agent to store and reuse its past experiences in a replay buffer. While many techniques have been proposed to enhance ER by biasing how experiences are sampled from the buffer, thus far they have not considered strategies for refreshing experiences inside the buffer. In this work, we introduce Lucid Dreaming for Experience Replay (LiDER), a conceptually new framework that allows replay experiences to be refreshed by leveraging the agent's current policy. LiDER 1) moves an agent back to a past state; 2) lets the agent try following its current policy to execute different actions---as if the agent were "dreaming" about the past, but is aware of the situation and can control the dream to encounter new experiences; and 3) stores and reuses the new experience if it turned out better than what the agent previously experienced, i.e., to refresh its memories. LiDER is designed to be easily incorporated into off-policy, multi-worker RL algorithms that use ER; we present in this work a case study of applying LiDER to an actor-critic based algorithm. Results show LiDER consistently improves performance over the baseline in four Atari 2600 games. Our open-source implementation of LiDER and the data used to generate all plots in this paper are available at github.com/duyunshu/lucid-dreaming-for-exp-replay.