 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCF: ECAPA-TDNN with Progressive Channel Fusion for Speaker Verification
Mar 01, 2023ECAPA-TDNN is currently the most popular TDNN-series model for speaker verification, which refreshed the state-of-the-art(SOTA) performance of TDNN models. However, one-dimensional convolution has a global receptive field over the feature channel. It destroys the time-frequency relevance of the spectrogram. Besides, as ECAPA-TDNN only has five layers, a much shallower structure compared to ResNet restricts the capability to generate deep representations. To further improve ECAPA-TDNN, we propose a progressive channel fusion strategy that splits the spectrogram across the feature channel and gradually expands the receptive field through the network. Secondly, we enlarge the model by extending the depth and adding branches. Our proposed model achieves EER with 0.718 and minDCF(0.01) with 0.0858 on vox1o, relatively improved 16.1\% and 19.5\% compared with ECAPA-TDNN-large.
Speech Corpora Divergence Based Unsupervised Data Selection for ASR
Feb 26, 2023Selecting application scenarios matching data is important for the automatic speech recognition (ASR) training, but it is difficult to measure the matching degree of the training corpus. This study proposes a unsupervised target-aware data selection method based on speech corpora divergence (SCD), which can measure the similarity between two speech corpora. We first use the self-supervised Hubert model to discretize the speech corpora into label sequence and calculate the N-gram probability distribution. Then we calculate the Kullback-Leibler divergence between the N-grams as the SCD. Finally, we can choose the subset which has minimum SCD to the target corpus for annotation and training. Compared to previous data selection method, the SCD data selection method can focus on more acoustic details and guarantee the diversity of the selected set. We evaluate our method on different accents from Common Voice. Experiments show that the proposed SCD data selection can realize 14.8% relative improvements to the random selection, comparable or even superior to the result of supervised selection.
Multi-dimensional frequency dynamic convolution with confident mean teacher for sound event detection
Feb 21, 2023Recently, convolutional neural networks (CNNs) have been widely used in sound event detection (SED). However, traditional convolution is deficient in learning time-frequency domain representation of different sound events. To address this issue, we propose multi-dimensional frequency dynamic convolution (MFDConv), a new design that endows convolutional kernels with frequency-adaptive dynamic properties along multiple dimensions. MFDConv utilizes a novel multi-dimensional attention mechanism with a parallel strategy to learn complementary frequency-adaptive attentions, which substantially strengthen the feature extraction ability of convolutional kernels. Moreover, in order to promote the performance of mean teacher, we propose the confident mean teacher to increase the accuracy of pseudo-labels from the teacher and train the student with high confidence labels. Experimental results show that the proposed methods achieve 0.470 and 0.692 of PSDS1 and PSDS2 on the DESED real validation dataset.
THLNet: two-stage heterogeneous lightweight network for monaural speech enhancement
Jan 19, 2023



In this paper, we propose a two-stage heterogeneous lightweight network for monaural speech enhancement. Specifically, we design a novel two-stage framework consisting of a coarse-grained full-band mask estimation stage and a fine-grained low-frequency refinement stage. Instead of using a hand-designed real-valued filter, we use a novel learnable complex-valued rectangular bandwidth (LCRB) filter bank as an extractor of compact features. Furthermore, considering the respective characteristics of the proposed two-stage task, we used a heterogeneous structure, i.e., a U-shaped subnetwork as the backbone of CoarseNet and a single-scale subnetwork as the backbone of FineNet. We conducted experiments on the VoiceBank + DEMAND and DNS datasets to evaluate the proposed approach. The experimental results show that the proposed method outperforms the current state-of-the-art methods, while maintaining relatively small model size and low computational complexity.
Deepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Oct 13, 2022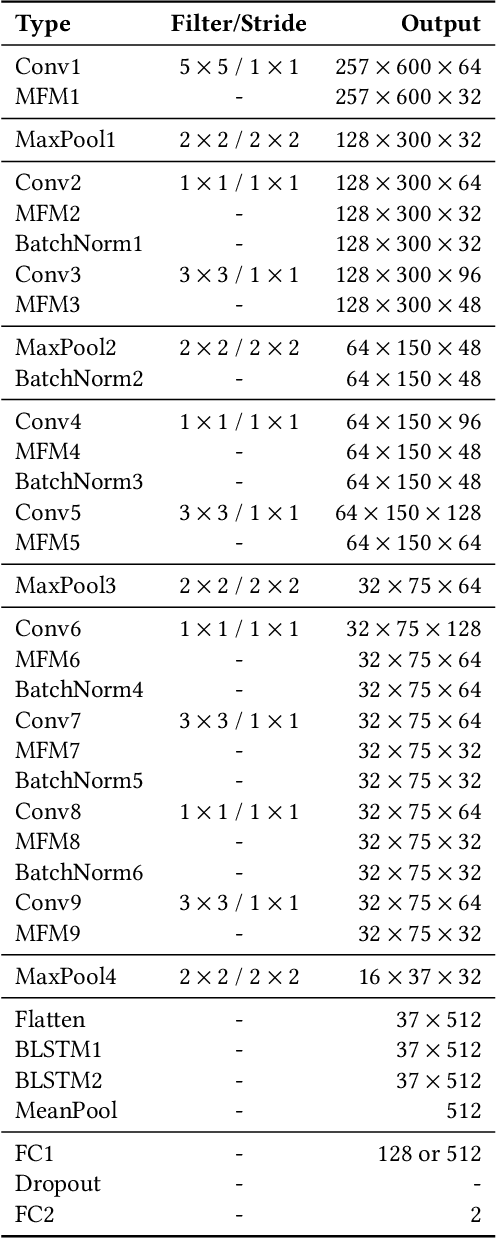
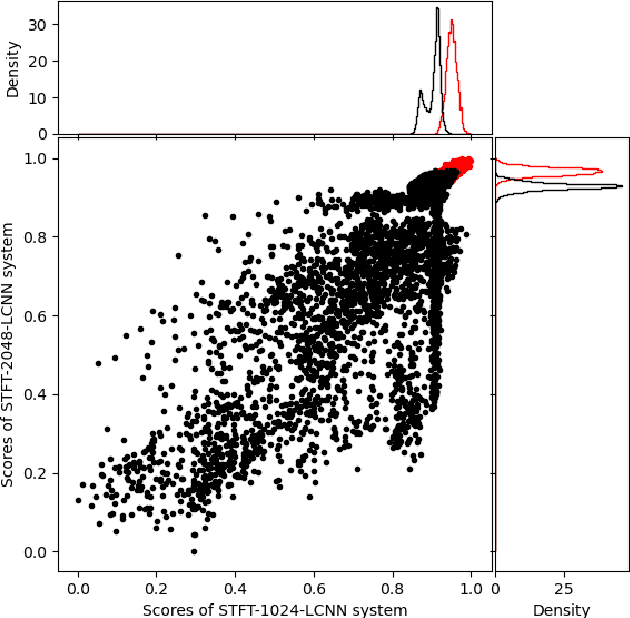
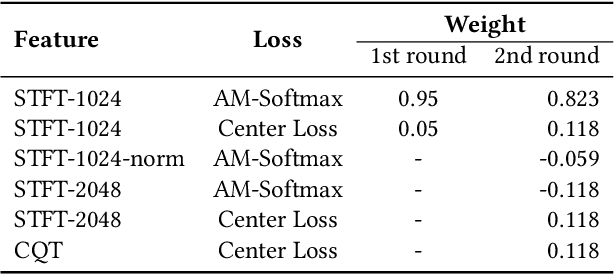
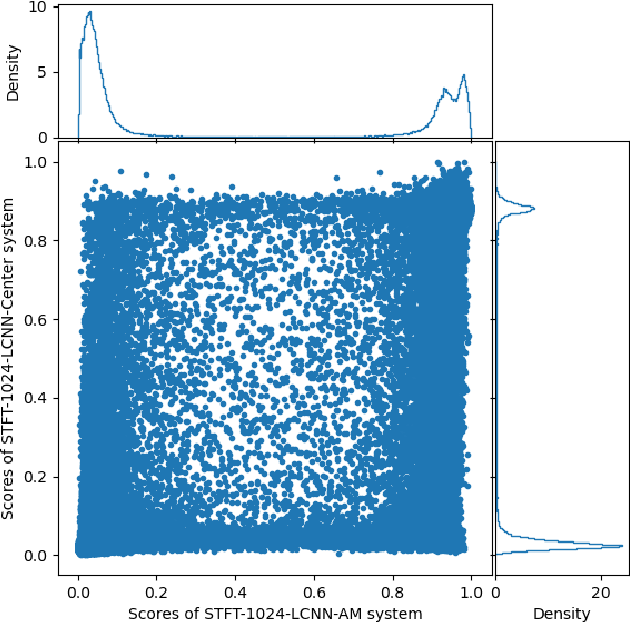
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022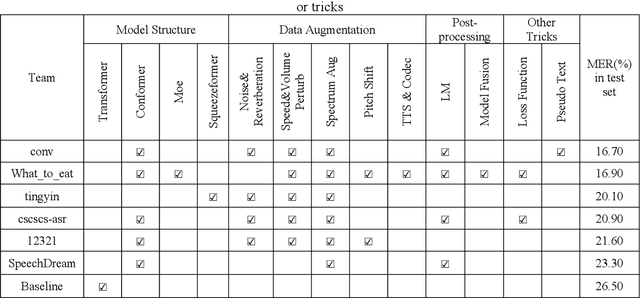
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022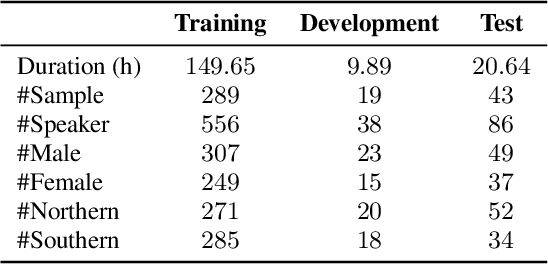

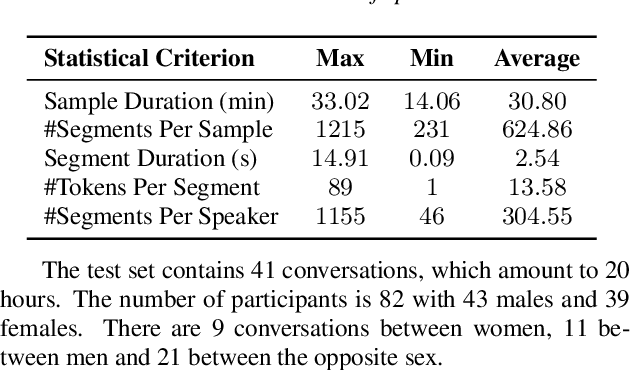
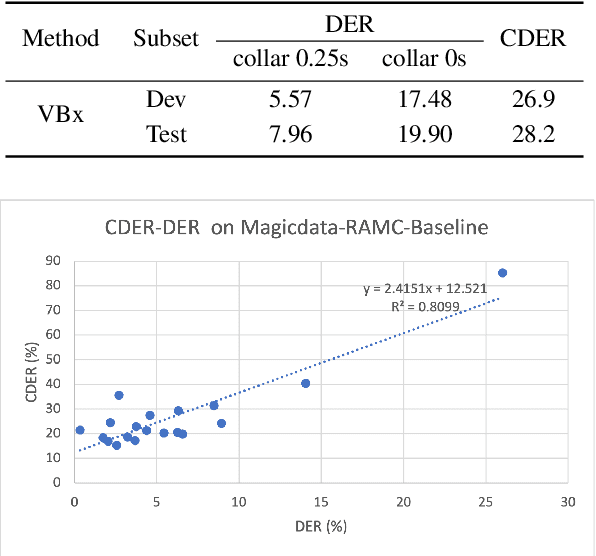
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
SASV Based on Pre-trained ASV System and Integrated Scoring Module
Jul 01, 2022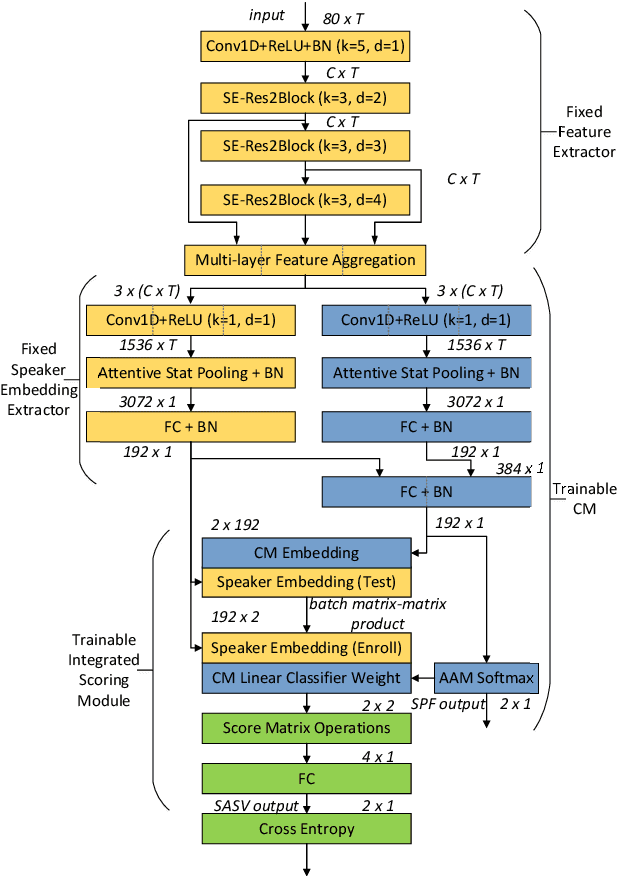
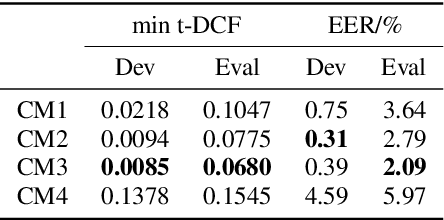
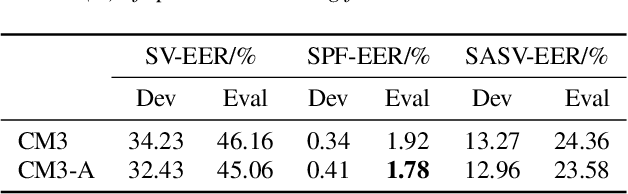

Based on the assumption that there is a correlation between anti-spoofing and speaker verification, a Total-Divide-Total integrated Spoofing-Aware Speaker Verification (SASV) system based on pre-trained automatic speaker verification (ASV) system and integrated scoring module is proposed and submitted to the SASV 2022 Challenge. The training and scoring of ASV and anti-spoofing countermeasure (CM) in current SASV systems are relatively independent, ignoring the correlation. In this paper, by leveraging the correlation between the two tasks, an integrated SASV system can be obtained by simply training a few more layers on the basis of the baseline pre-trained ASV subsystem. The features in pre-trained ASV system are utilized for logical access spoofing speech detection. Further, speaker embeddings extracted by the pre-trained ASV system are used to improve the performance of the CM. The integrated scoring module takes the embeddings of the ASV and anti-spoofing branches as input and preserves the correlation between the two tasks through matrix operations to produce integrated SASV scores. Submitted primary system achieved equal error rate (EER) of 3.07\% on the development dataset of the SASV 2022 Challenge and 4.30\% on the evaluation part, which is a 25\% improvement over the baseline systems.
Interrelate Training and Searching: A Unified Online Clustering Framework for Speaker Diarization
Jun 28, 2022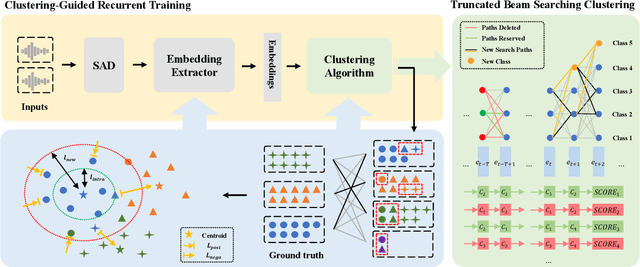
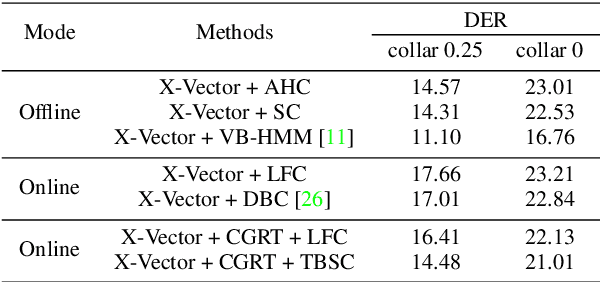
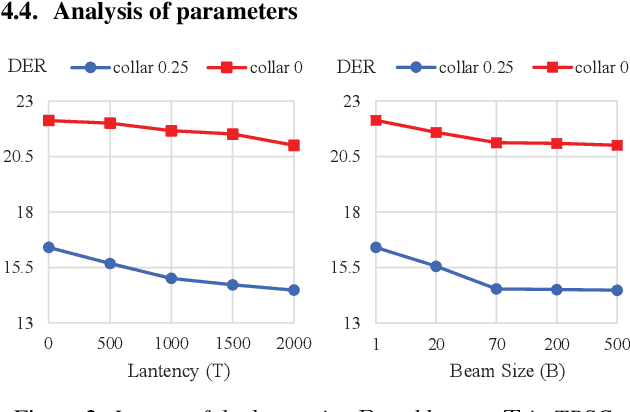
For online speaker diarization, samples arrive incrementally, and the overall distribution of the samples is invisible. Moreover, in most existing clustering-based methods, the training objective of the embedding extractor is not designed specially for clustering. To improve online speaker diarization performance, we propose a unified online clustering framework, which provides an interactive manner between embedding extractors and clustering algorithms. Specifically, the framework consists of two highly coupled parts: clustering-guided recurrent training (CGRT) and truncated beam searching clustering (TBSC). The CGRT introduces the clustering algorithm into the training process of embedding extractors, which could provide not only cluster-aware information for the embedding extractor, but also crucial parameters for the clustering process afterward. And with these parameters, which contain preliminary information of the metric space, the TBSC penalizes the probability score of each cluster, in order to output more accurate clustering results in online fashion with low latency. With the above innovations, our proposed online clustering system achieves 14.48\% DER with collar 0.25 at 2.5s latency on the AISHELL-4, while the DER of the offline agglomerative hierarchical clustering is 14.57\%.
Boosting Cross-Domain Speech Recognition with Self-Supervision
Jun 20, 2022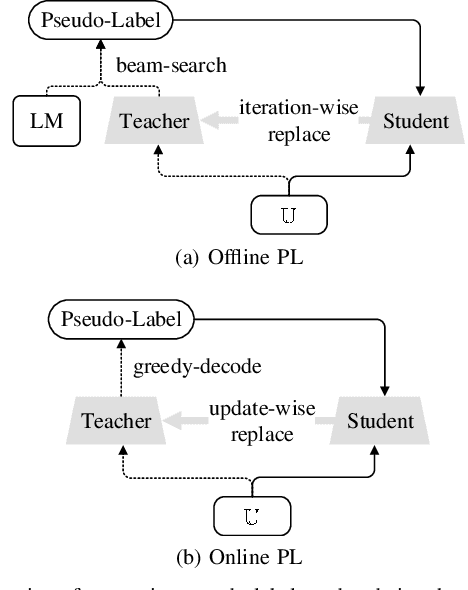
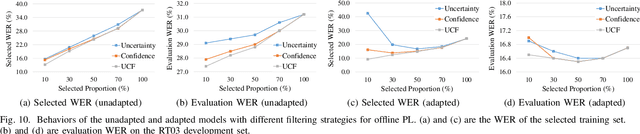
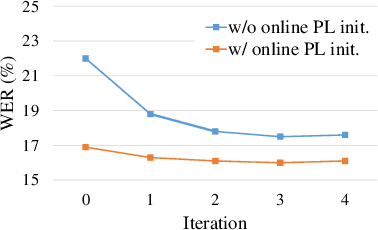
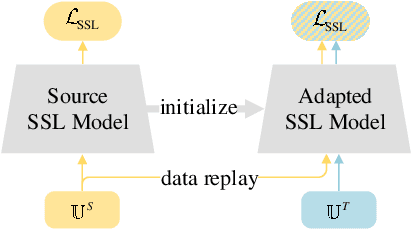
The cross-domain performance of automatic speech recognition (ASR) could be severely hampered due to the mismatch between training and testing distributions. Since the target domain usually lacks labeled data, and domain shifts exist at acoustic and linguistic levels, it is challenging to perform unsupervised domain adaptation (UDA) for ASR. Previous work has shown that self-supervised learning (SSL) or pseudo-labeling (PL) is effective in UDA by exploiting the self-supervisions of unlabeled data. However, these self-supervisions also face performance degradation in mismatched domain distributions, which previous work fails to address. This work presents a systematic UDA framework to fully utilize the unlabeled data with self-supervision in the pre-training and fine-tuning paradigm. On the one hand, we apply continued pre-training and data replay techniques to mitigate the domain mismatch of the SSL pre-trained model. On the other hand, we propose a domain-adaptive fine-tuning approach based on the PL technique with three unique modifications: Firstly, we design a dual-branch PL method to decrease the sensitivity to the erroneous pseudo-labels; Secondly, we devise an uncertainty-aware confidence filtering strategy to improve pseudo-label correctness; Thirdly, we introduce a two-step PL approach to incorporate target domain linguistic knowledge, thus generating more accurate target domain pseudo-labels. Experimental results on various cross-domain scenarios demonstrate that the proposed approach could effectively boost the cross-domain performance and significantly outperform previous approaches.