 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse in Multi-label Learning with Pick-all-label Loss
Nov 01, 2023



We study deep neural networks for the multi-label classification (MLab) task through the lens of neural collapse (NC). Previous works have been restricted to the multi-class classification setting and discovered a prevalent NC phenomenon comprising of the following properties for the last-layer features: (i) the variability of features within every class collapses to zero, (ii) the set of feature means form an equi-angular tight frame (ETF), and (iii) the last layer classifiers collapse to the feature mean upon some scaling. We generalize the study to multi-label learning, and prove for the first time that a generalized NC phenomenon holds with the "pick-all-label" formulation. Under the natural analog of the unconstrained feature model (UFM), we establish that the only global classifier of the pick-all-label cross entropy loss display the same ETF geometry which further collapse to multiplicity-1 feature class means. Besides, we discover a combinatorial property in generalized NC which is unique for multi-label learning that we call "tag-wise average" property, where the feature class-means of samples with multiple labels are scaled average of the feature class-means of single label tags. Theoretically, we establish global optimality result for the pick-all-label cross-entropy risk for the UFM. Additionally, We also provide empirical evidence to support our investigation into training deep neural networks on multi-label datasets, resulting in improved training efficiency.
FastInst: A Simple Query-Based Model for Real-Time Instance Segmentation
Apr 01, 2023



Recent attention in instance segmentation has focused on query-based models. Despite being non-maximum suppression (NMS)-free and end-to-end, the superiority of these models on high-accuracy real-time benchmarks has not been well demonstrated. In this paper, we show the strong potential of query-based models on efficient instance segmentation algorithm designs. We present FastInst, a simple, effective query-based framework for real-time instance segmentation. FastInst can execute at a real-time speed (i.e., 32.5 FPS) while yielding an AP of more than 40 (i.e., 40.5 AP) on COCO test-dev without bells and whistles. Specifically, FastInst follows the meta-architecture of recently introduced Mask2Former. Its key designs include instance activation-guided queries, dual-path update strategy, and ground truth mask-guided learning, which enable us to use lighter pixel decoders, fewer Transformer decoder layers, while achieving better performance. The experiments show that FastInst outperforms most state-of-the-art real-time counterparts, including strong fully convolutional baselines, in both speed and accuracy. Code can be found at https://github.com/junjiehe96/FastInst .
Learning Polysemantic Spoof Trace: A Multi-Modal Disentanglement Network for Face Anti-spoofing
Dec 07, 2022



Along with the widespread use of face recognition systems, their vulnerability has become highlighted. While existing face anti-spoofing methods can be generalized between attack types, generic solutions are still challenging due to the diversity of spoof characteristics. Recently, the spoof trace disentanglement framework has shown great potential for coping with both seen and unseen spoof scenarios, but the performance is largely restricted by the single-modal input. This paper focuses on this issue and presents a multi-modal disentanglement model which targetedly learns polysemantic spoof traces for more accurate and robust generic attack detection. In particular, based on the adversarial learning mechanism, a two-stream disentangling network is designed to estimate spoof patterns from the RGB and depth inputs, respectively. In this case, it captures complementary spoofing clues inhering in different attacks. Furthermore, a fusion module is exploited, which recalibrates both representations at multiple stages to promote the disentanglement in each individual modality. It then performs cross-modality aggregation to deliver a more comprehensive spoof trace representation for prediction. Extensive evaluations are conducted on multiple benchmarks, demonstrating that learning polysemantic spoof traces favorably contributes to anti-spoofing with more perceptible and interpretable results.
LongShortNet: Exploring Temporal and Semantic Features Fusion in Streaming Perception
Oct 27, 2022
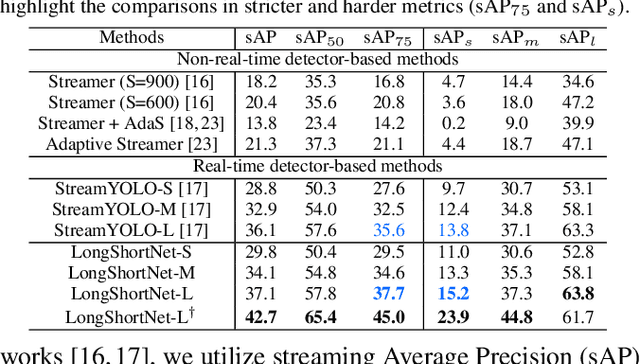
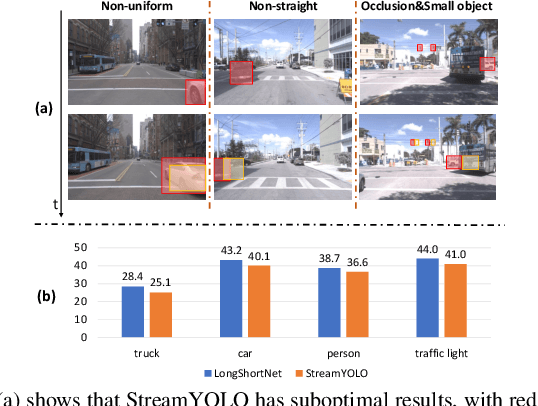

Streaming perception is a task of reporting the current state of autonomous driving, which coherently considers the latency and accuracy of autopilot systems. However, the existing streaming perception only uses the current and adjacent two frames as input for learning the movement patterns, which cannot model actual complex scenes, resulting in failed detection results. To solve this problem, we propose an end-to-end dual-path network dubbed LongShortNet, which captures long-term temporal motion and calibrates it with short-term spatial semantics for real-time perception. Moreover, we investigate a Long-Short Fusion Module (LSFM) to explore spatiotemporal feature fusion, which is the first work to extend long-term temporal in streaming perception. We evaluate the proposed LongShortNet and compare it with existing methods on the benchmark dataset Argoverse-HD. The results demonstrate that the proposed LongShortNet outperforms the other state-of-the-art methods with almost no extra computational cost.
Matrix Completion with Cross-Concentrated Sampling: Bridging Uniform Sampling and CUR Sampling
Aug 20, 2022
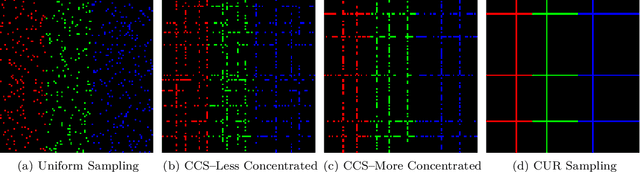

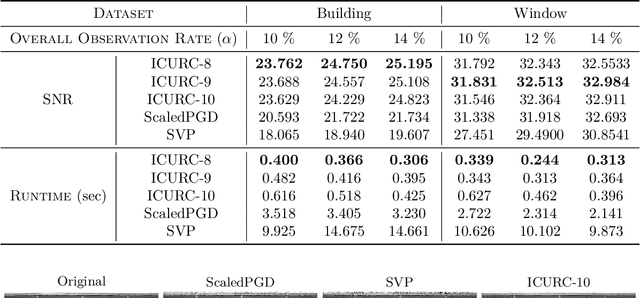
While uniform sampling has been widely studied in the matrix completion literature, CUR sampling approximates a low-rank matrix via row and column samples. Unfortunately, both sampling models lack flexibility for various circumstances in real-world applications. In this work, we propose a novel and easy-to-implement sampling strategy, coined Cross-Concentrated Sampling (CCS). By bridging uniform sampling and CUR sampling, CCS provides extra flexibility that can potentially save sampling costs in applications. In addition, we also provide a sufficient condition for CCS-based matrix completion. Moreover, we propose a highly efficient non-convex algorithm, termed Iterative CUR Completion (ICURC), for the proposed CCS model. Numerical experiments verify the empirical advantages of CCS and ICURC against uniform sampling and its baseline algorithms, on both synthetic and real-world datasets.
Dense Learning based Semi-Supervised Object Detection
Apr 15, 2022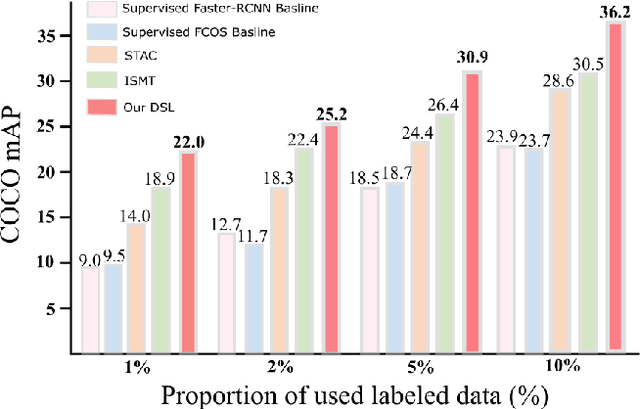
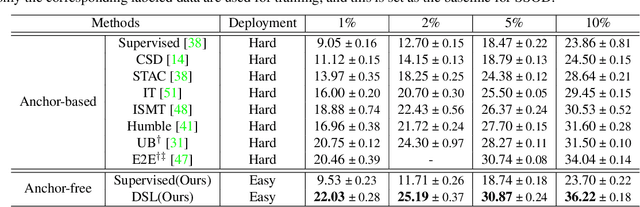
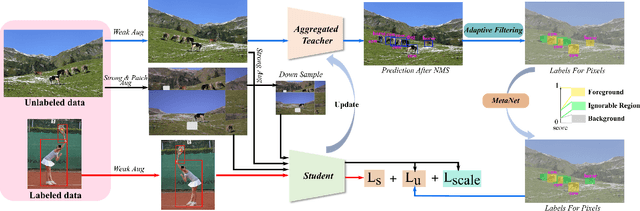
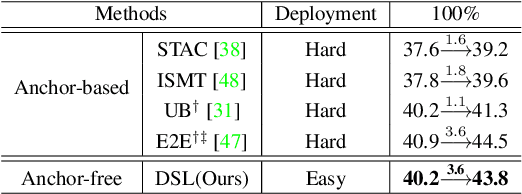
Semi-supervised object detection (SSOD) aims to facilitate the training and deployment of object detectors with the help of a large amount of unlabeled data. Though various self-training based and consistency-regularization based SSOD methods have been proposed, most of them are anchor-based detectors, ignoring the fact that in many real-world applications anchor-free detectors are more demanded. In this paper, we intend to bridge this gap and propose a DenSe Learning (DSL) based anchor-free SSOD algorithm. Specifically, we achieve this goal by introducing several novel techniques, including an Adaptive Filtering strategy for assigning multi-level and accurate dense pixel-wise pseudo-labels, an Aggregated Teacher for producing stable and precise pseudo-labels, and an uncertainty-consistency-regularization term among scales and shuffled patches for improving the generalization capability of the detector. Extensive experiments are conducted on MS-COCO and PASCAL-VOC, and the results show that our proposed DSL method records new state-of-the-art SSOD performance, surpassing existing methods by a large margin. Codes can be found at \textcolor{blue}{https://github.com/chenbinghui1/DSL}.
Guided Semi-Supervised Non-negative Matrix Factorization on Legal Documents
Jan 31, 2022



Classification and topic modeling are popular techniques in machine learning that extract information from large-scale datasets. By incorporating a priori information such as labels or important features, methods have been developed to perform classification and topic modeling tasks; however, most methods that can perform both do not allow for guidance of the topics or features. In this paper, we propose a method, namely Guided Semi-Supervised Non-negative Matrix Factorization (GSSNMF), that performs both classification and topic modeling by incorporating supervision from both pre-assigned document class labels and user-designed seed words. We test the performance of this method through its application to legal documents provided by the California Innocence Project, a nonprofit that works to free innocent convicted persons and reform the justice system. The results show that our proposed method improves both classification accuracy and topic coherence in comparison to past methods like Semi-Supervised Non-negative Matrix Factorization (SSNMF) and Guided Non-negative Matrix Factorization (Guided NMF).
Variational Attention: Propagating Domain-Specific Knowledge for Multi-Domain Learning in Crowd Counting
Aug 18, 2021
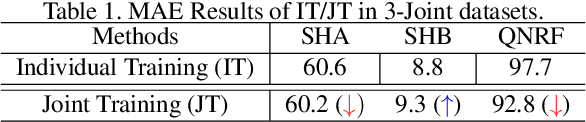
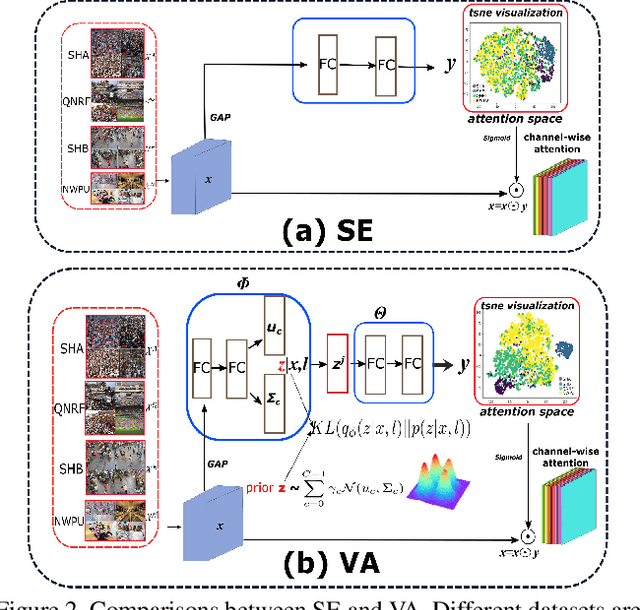
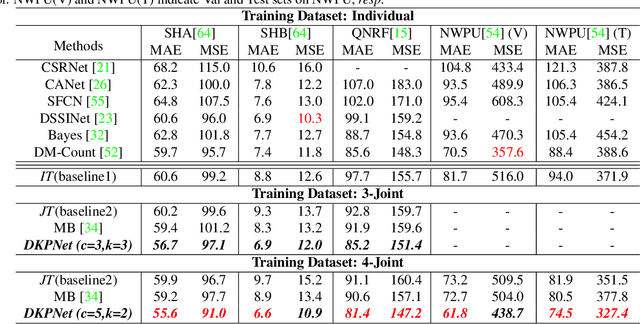
In crowd counting, due to the problem of laborious labelling, it is perceived intractability of collecting a new large-scale dataset which has plentiful images with large diversity in density, scene, etc. Thus, for learning a general model, training with data from multiple different datasets might be a remedy and be of great value. In this paper, we resort to the multi-domain joint learning and propose a simple but effective Domain-specific Knowledge Propagating Network (DKPNet)1 for unbiasedly learning the knowledge from multiple diverse data domains at the same time. It is mainly achieved by proposing the novel Variational Attention(VA) technique for explicitly modeling the attention distributions for different domains. And as an extension to VA, Intrinsic Variational Attention(InVA) is proposed to handle the problems of over-lapped domains and sub-domains. Extensive experiments have been conducted to validate the superiority of our DKPNet over several popular datasets, including ShanghaiTech A/B, UCF-QNRF and NWPU.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
COVID-19 Literature Topic-Based Search via Hierarchical NMF
Sep 07, 2020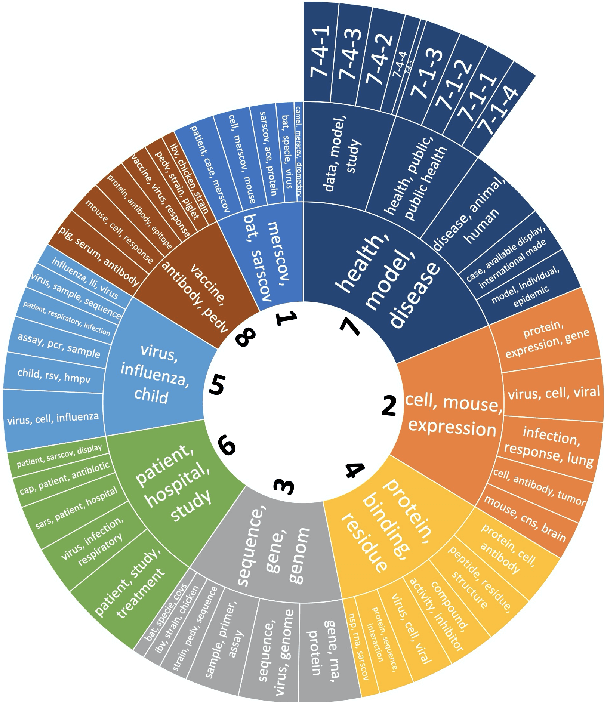
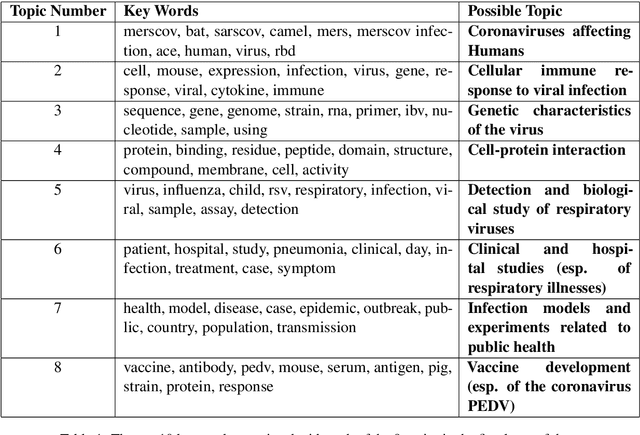

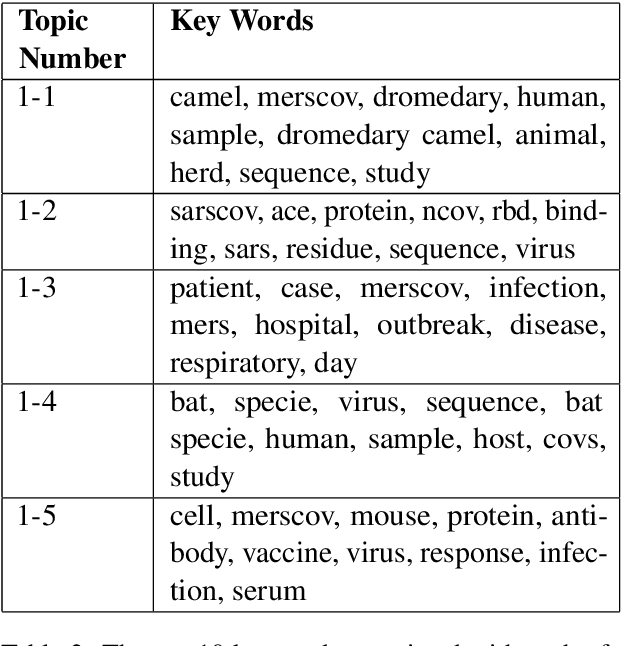
A dataset of COVID-19-related scientific literature is compiled, combining the articles from several online libraries and selecting those with open access and full text available. Then, hierarchical nonnegative matrix factorization is used to organize literature related to the novel coronavirus into a tree structure that allows researchers to search for relevant literature based on detected topics. We discover eight major latent topics and 52 granular subtopics in the body of literature, related to vaccines, genetic structure and modeling of the disease and patient studies, as well as related diseases and virology. In order that our tool may help current researchers, an interactive website is created that organizes available literature using this hierarchical structure.