 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AVSR Meets Video Conferencing: Dataset, Degradation, and the Hidden Mechanism Behind Performance Collapse
Mar 24, 2026Audio-Visual Speech Recognition (AVSR) has achieved remarkable progress in offline conditions, yet its robustness in real-world video conferencing (VC) remains largely unexplored. This paper presents the first systematic evaluation of state-of-the-art AVSR models across mainstream VC platforms, revealing severe performance degradation caused by transmission distortions and spontaneous human hyper-expression. To address this gap, we construct \textbf{MLD-VC}, the first multimodal dataset tailored for VC, comprising 31 speakers, 22.79 hours of audio-visual data, and explicit use of the Lombard effect to enhance human hyper-expression. Through comprehensive analysis, we find that speech enhancement algorithms are the primary source of distribution shift, which alters the first and second formants of audio. Interestingly, we find that the distribution shift induced by the Lombard effect closely resembles that introduced by speech enhancement, which explains why models trained on Lombard data exhibit greater robustness in VC. Fine-tuning AVSR models on MLD-VC mitigates this issue, achieving an average 17.5% reduction in CER across several VC platforms. Our findings and dataset provide a foundation for developing more robust and generalizable AVSR systems in real-world video conferencing. MLD-VC is available at https://huggingface.co/datasets/nccm2p2/MLD-VC.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
SE4Lip: Speech-Lip Encoder for Talking Head Synthesis to Solve Phoneme-Viseme Alignment Ambiguity
Apr 08, 2025Speech-driven talking head synthesis tasks commonly use general acoustic features (such as HuBERT and DeepSpeech) as guided speech features. However, we discovered that these features suffer from phoneme-viseme alignment ambiguity, which refers to the uncertainty and imprecision in matching phonemes (speech) with visemes (lip). To address this issue, we propose the Speech Encoder for Lip (SE4Lip) to encode lip features from speech directly, aligning speech and lip features in the joint embedding space by a cross-modal alignment framework. The STFT spectrogram with the GRU-based model is designed in SE4Lip to preserve the fine-grained speech features. Experimental results show that SE4Lip achieves state-of-the-art performance in both NeRF and 3DGS rendering models. Its lip sync accuracy improves by 13.7% and 14.2% compared to the best baseline and produces results close to the ground truth videos.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
COVID-19 Literature Topic-Based Search via Hierarchical NMF
Sep 07, 2020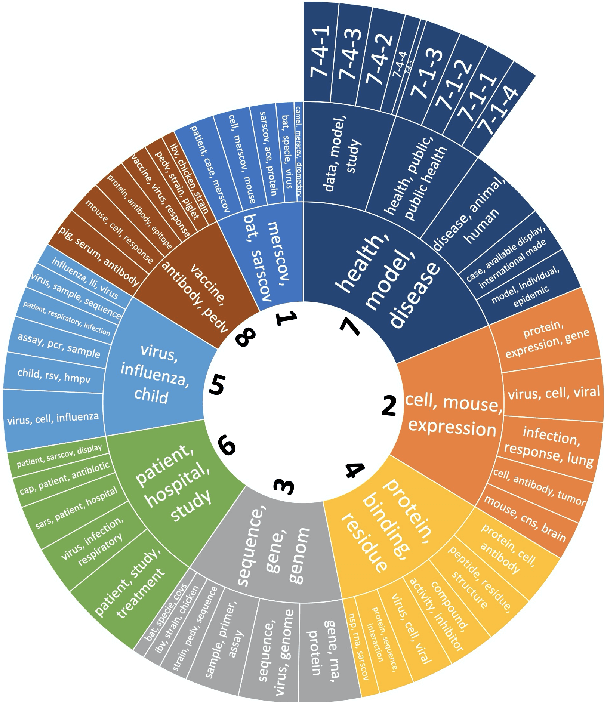
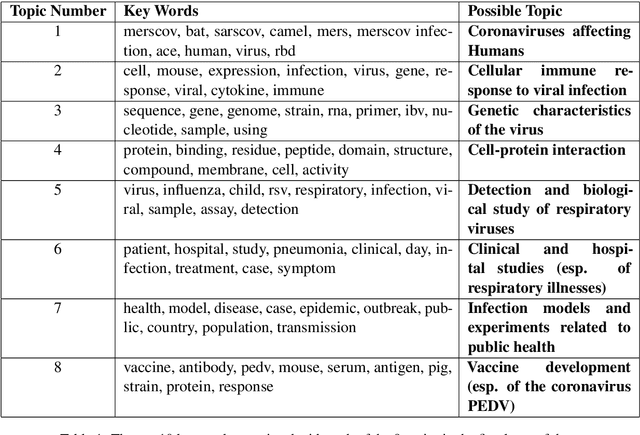

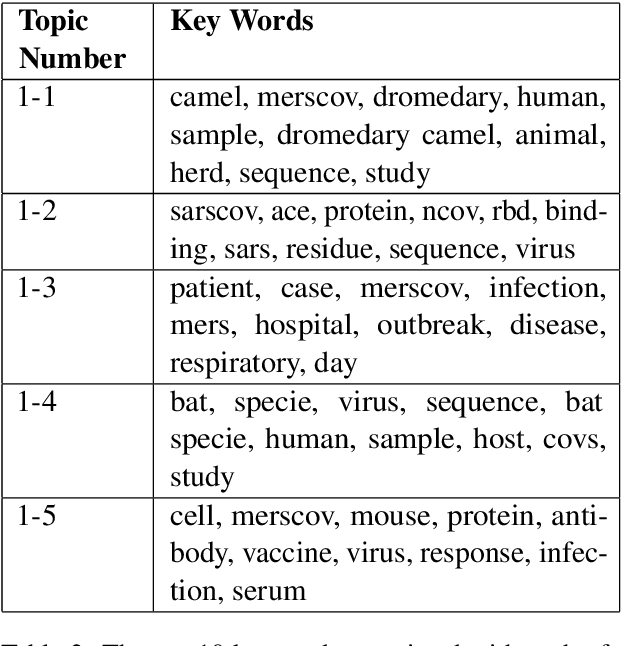
A dataset of COVID-19-related scientific literature is compiled, combining the articles from several online libraries and selecting those with open access and full text available. Then, hierarchical nonnegative matrix factorization is used to organize literature related to the novel coronavirus into a tree structure that allows researchers to search for relevant literature based on detected topics. We discover eight major latent topics and 52 granular subtopics in the body of literature, related to vaccines, genetic structure and modeling of the disease and patient studies, as well as related diseases and virology. In order that our tool may help current researchers, an interactive website is created that organizes available literature using this hierarchical structure.