 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect simultaneous speech to speech translation
Oct 15, 2021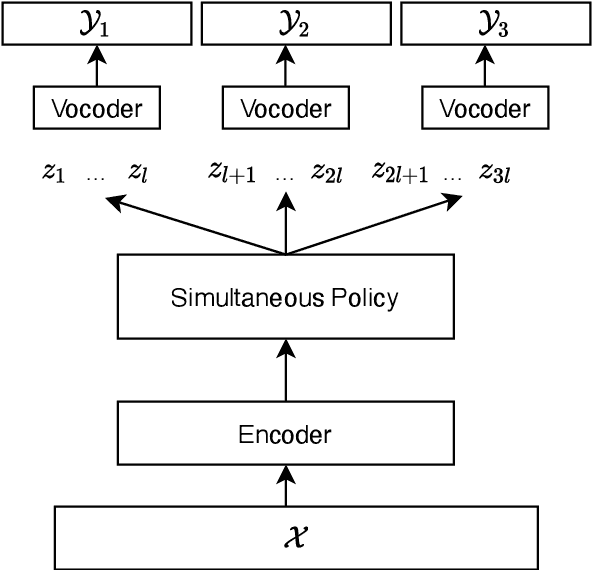
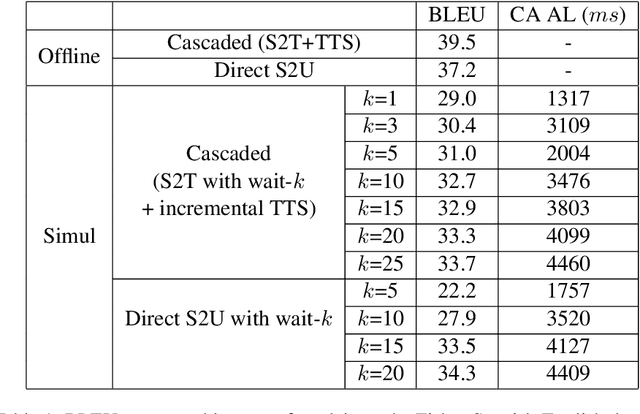
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021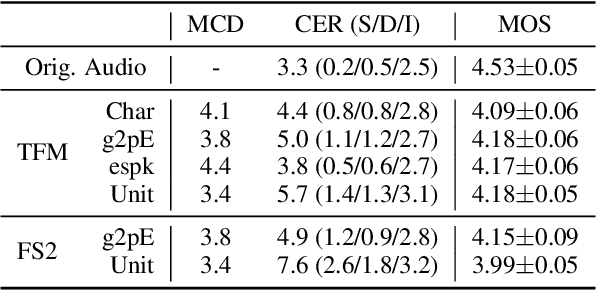
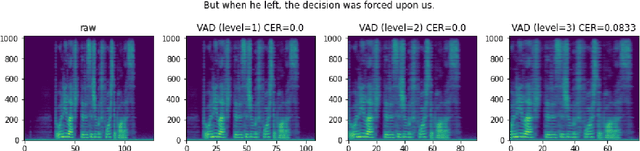

This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.
Direct speech-to-speech translation with discrete units
Jul 12, 2021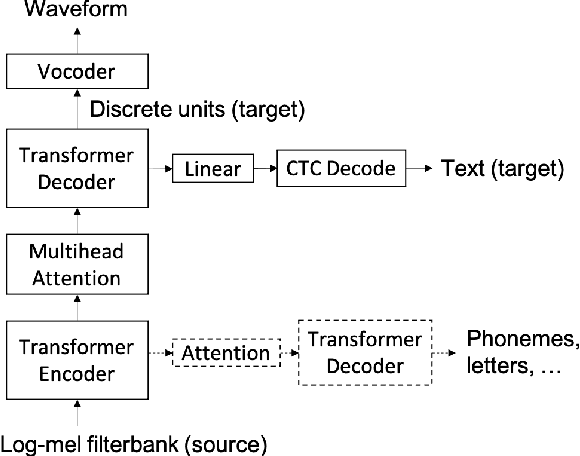
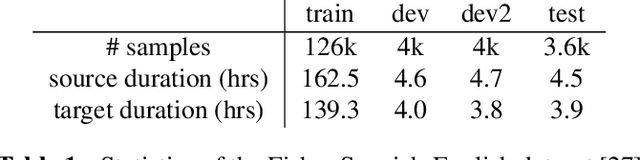
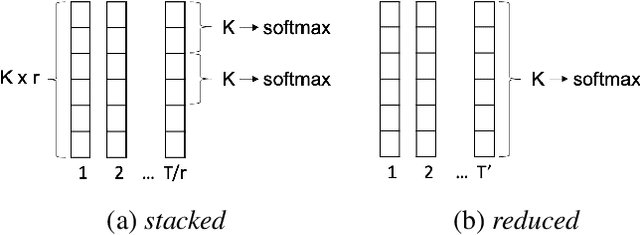
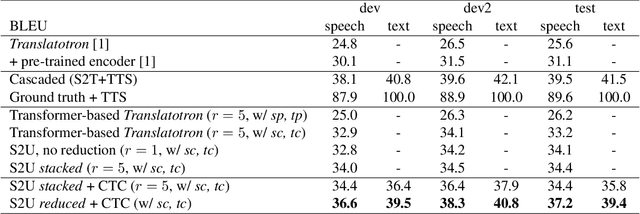
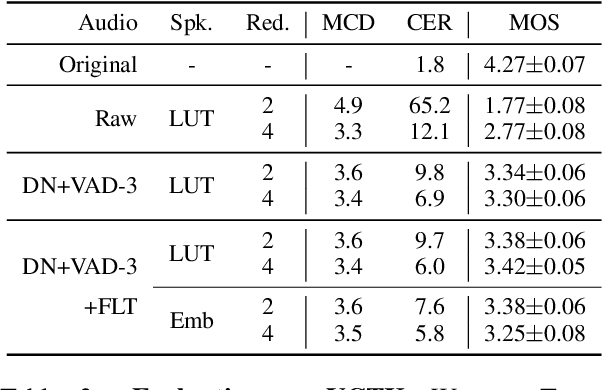
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation
Jun 06, 2021
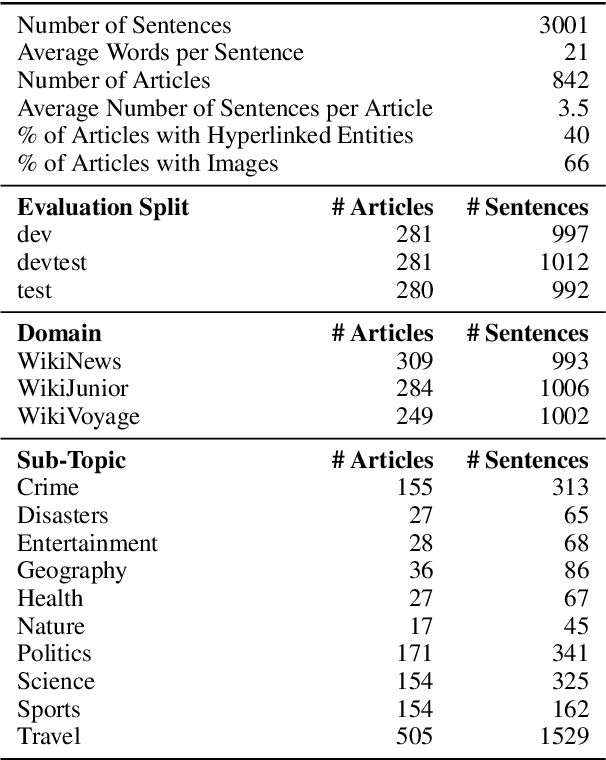
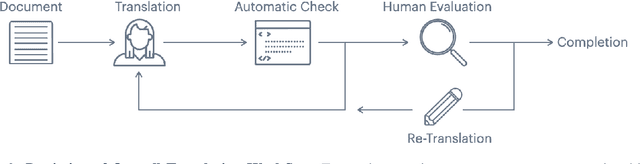

One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi-automatic procedures. In this work, we introduce the FLORES-101 evaluation benchmark, consisting of 3001 sentences extracted from English Wikipedia and covering a variety of different topics and domains. These sentences have been translated in 101 languages by professional translators through a carefully controlled process. The resulting dataset enables better assessment of model quality on the long tail of low-resource languages, including the evaluation of many-to-many multilingual translation systems, as all translations are multilingually aligned. By publicly releasing such a high-quality and high-coverage dataset, we hope to foster progress in the machine translation community and beyond.
Facebook AI's WMT20 News Translation Task Submission
Nov 16, 2020

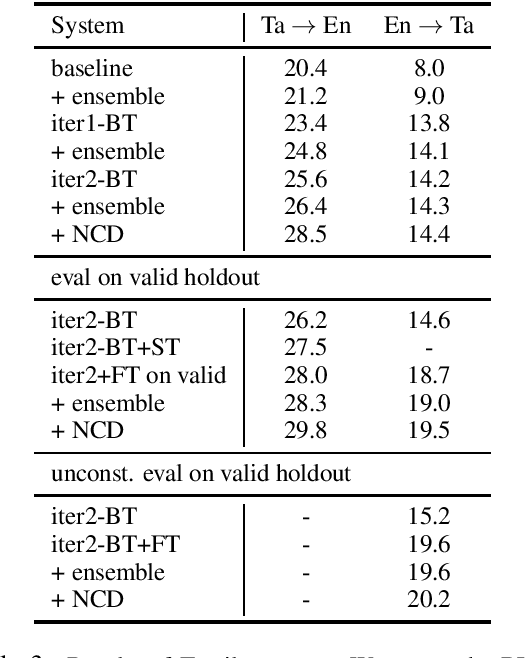
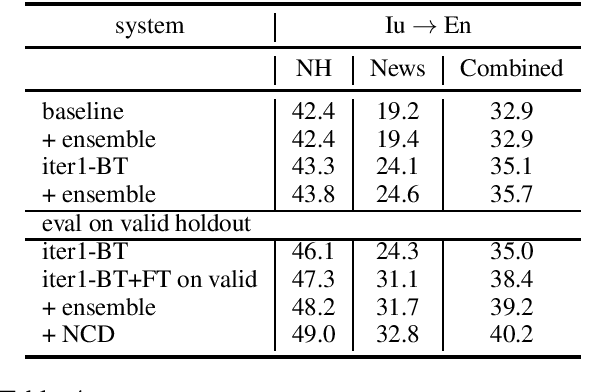
This paper describes Facebook AI's submission to WMT20 shared news translation task. We focus on the low resource setting and participate in two language pairs, Tamil <-> English and Inuktitut <-> English, where there are limited out-of-domain bitext and monolingual data. We approach the low resource problem using two main strategies, leveraging all available data and adapting the system to the target news domain. We explore techniques that leverage bitext and monolingual data from all languages, such as self-supervised model pretraining, multilingual models, data augmentation, and reranking. To better adapt the translation system to the test domain, we explore dataset tagging and fine-tuning on in-domain data. We observe that different techniques provide varied improvements based on the available data of the language pair. Based on the finding, we integrate these techniques into one training pipeline. For En->Ta, we explore an unconstrained setup with additional Tamil bitext and monolingual data and show that further improvement can be obtained. On the test set, our best submitted systems achieve 21.5 and 13.7 BLEU for Ta->En and En->Ta respectively, and 27.9 and 13.0 for Iu->En and En->Iu respectively.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020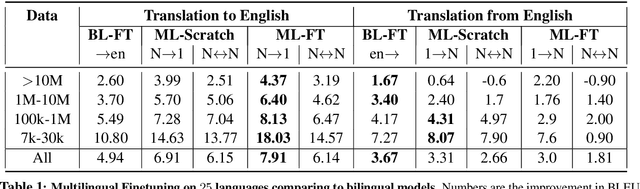
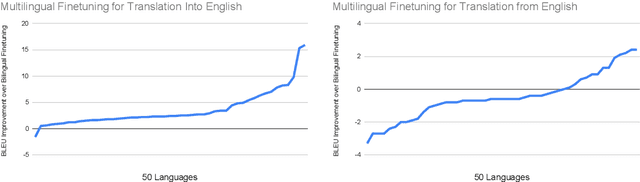
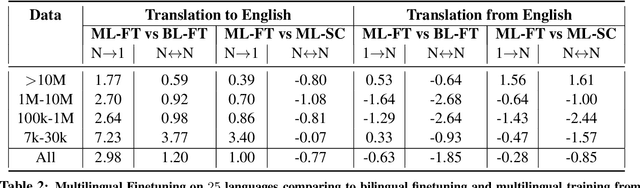
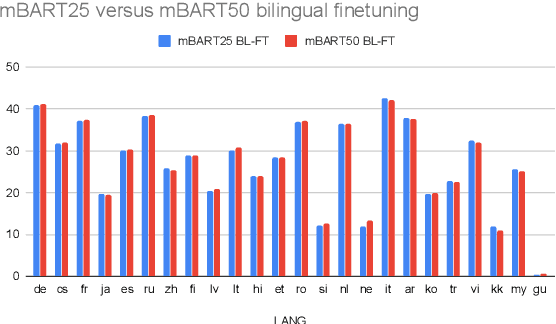
Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.
Facebook AI's WAT19 Myanmar-English Translation Task Submission
Oct 15, 2019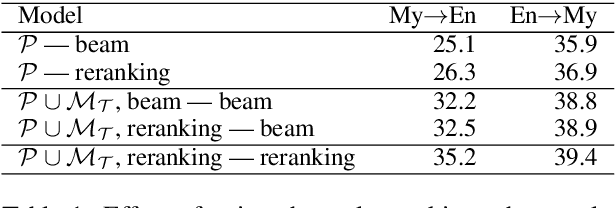
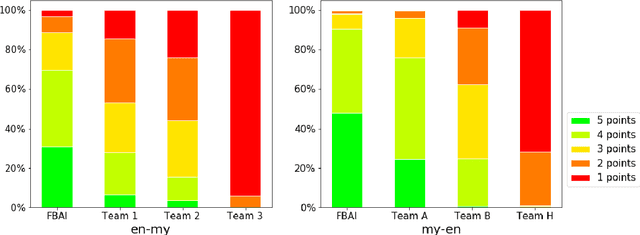
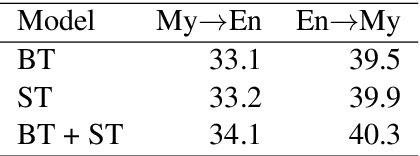
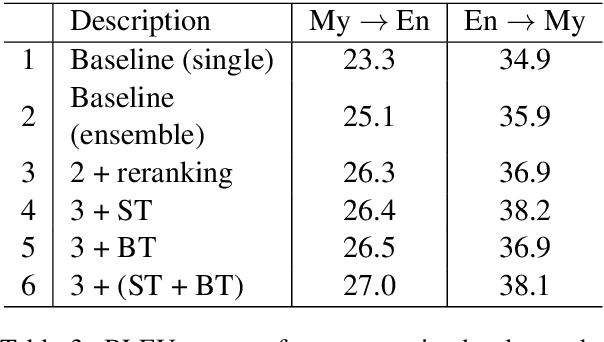
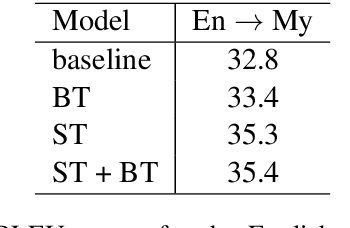
This paper describes Facebook AI's submission to the WAT 2019 Myanmar-English translation task. Our baseline systems are BPE-based transformer models. We explore methods to leverage monolingual data to improve generalization, including self-training, back-translation and their combination. We further improve results by using noisy channel re-ranking and ensembling. We demonstrate that these techniques can significantly improve not only a system trained with additional monolingual data, but even the baseline system trained exclusively on the provided small parallel dataset. Our system ranks first in both directions according to human evaluation and BLEU, with a gain of over 8 BLEU points above the second best system.
The Source-Target Domain Mismatch Problem in Machine Translation
Sep 28, 2019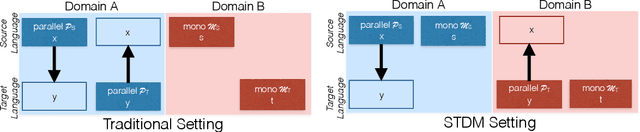
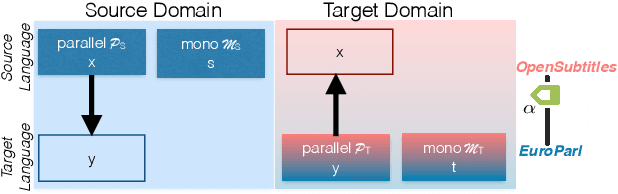
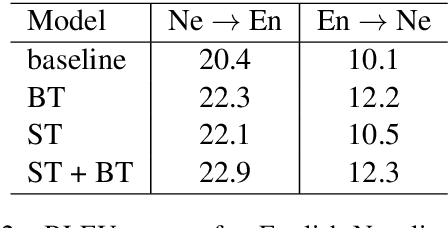
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that particularly in low resource settings this causes the domains of the source and target language to greatly mismatch, as the two languages are often spoken in further apart regions of the world with more distinctive cultural traits and unrelated local events. In this work we first propose a controlled setting to carefully analyze the source-target domain mismatch, and its dependence on the amount of parallel and monolingual data. Second, we test both a model trained with back-translation and one trained with self-training. The latter leverages in-domain source monolingual data but uses potentially incorrect target references. We found that these two approaches are often complementary to each other. For instance, on a low-resource Nepali-English dataset the combined approach improves upon the baseline using just parallel data by 2.5 BLEU points, and by 0.6 BLEU point when compared to back-translation.
Two New Evaluation Datasets for Low-Resource Machine Translation: Nepali-English and Sinhala-English
Feb 04, 2019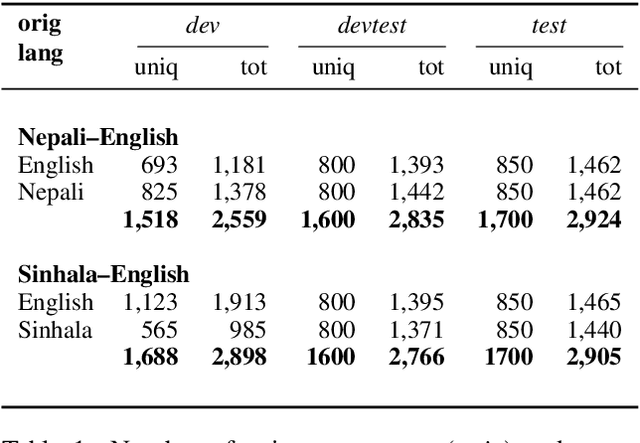
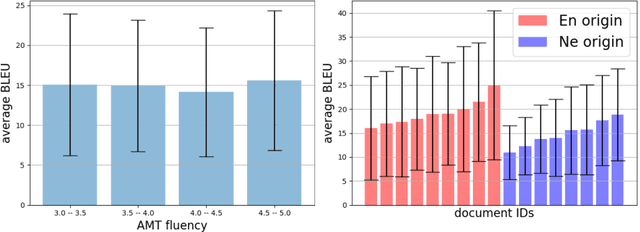
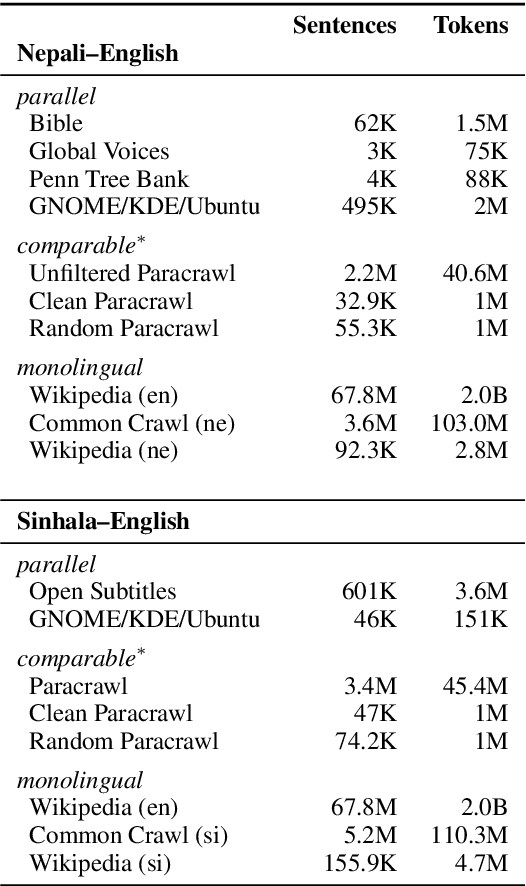
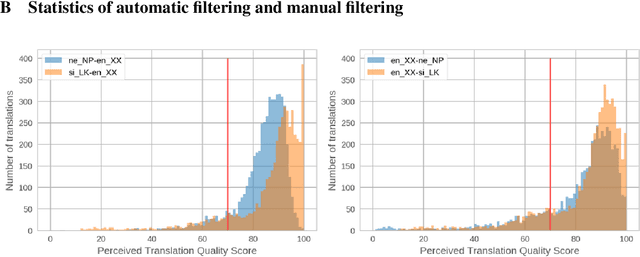
The vast majority of language pairs in the world are low-resource because they have little, if any, parallel data available. Unfortunately, machine translation (MT) systems do not currently work well in this setting. Besides the technical challenges of learning with limited supervision, there is also another challenge: it is very difficult to evaluate methods trained on low resource language pairs because there are very few freely and publicly available benchmarks. In this work, we take sentences from Wikipedia pages and introduce new evaluation datasets in two very low resource language pairs, Nepali-English and Sinhala-English. These are languages with very different morphology and syntax, for which little out-of-domain parallel data is available and for which relatively large amounts of monolingual data are freely available. We describe our process to collect and cross-check the quality of translations, and we report baseline performance using several learning settings: fully supervised, weakly supervised, semi-supervised, and fully unsupervised. Our experiments demonstrate that current state-of-the-art methods perform rather poorly on this benchmark, posing a challenge to the research community working on low resource MT. Data and code to reproduce our experiments are available at https://github.com/facebookresearch/flores.