 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Code-Switched Language Identification is Harder Than You Think
Feb 02, 2024



Code switching (CS) is a very common phenomenon in written and spoken communication but one that is handled poorly by many natural language processing applications. Looking to the application of building CS corpora, we explore CS language identification (LID) for corpus building. We make the task more realistic by scaling it to more languages and considering models with simpler architectures for faster inference. We also reformulate the task as a sentence-level multi-label tagging problem to make it more tractable. Having defined the task, we investigate three reasonable models for this task and define metrics which better reflect desired performance. We present empirical evidence that no current approach is adequate and finally provide recommendations for future work in this area.
Monolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca
Sep 16, 2023



Foundational large language models (LLMs) can be instruction-tuned to develop open-ended question-answering capability, facilitating applications such as the creation of AI assistants. While such efforts are often carried out in a single language, building on prior research, we empirically analyze cost-efficient approaches of monolingual and multilingual tuning, shedding light on the efficacy of LLMs in responding to queries across monolingual and multilingual contexts. Our study employs the Alpaca dataset and machine translations of it to form multilingual training data, which is then used to tune LLMs through low-rank adaptation and full-parameter training. Comparisons reveal that multilingual tuning is not crucial for an LLM's English performance, but is key to its robustness in a multilingual environment. With a fixed budget, a multilingual instruction-tuned model, merely trained on downsampled data, can be as powerful as training monolingual models for each language. Our findings serve as a guide for expanding language support through instruction tuning with constrained computational resources.
Iterative Translation Refinement with Large Language Models
Jun 06, 2023Large language models have shown surprising performances in understanding instructions and performing natural language tasks. In this paper, we propose iterative translation refinement to leverage the power of large language models for more natural translation and post-editing. We show that by simply involving a large language model in an iterative process, the output quality improves beyond mere translation. Extensive test scenarios with GPT-3.5 reveal that although iterations reduce string-based metric scores, neural metrics indicate comparable if not improved translation quality. Further, human evaluations demonstrate that our method effectively reduces translationese compared to initial GPT translations and even human references, especially for into-English directions. Ablation studies underscore the importance of anchoring the refinement process to the source input and a reasonable initial translation.
An Open Dataset and Model for Language Identification
May 23, 2023


Language identification (LID) is a fundamental step in many natural language processing pipelines. However, current LID systems are far from perfect, particularly on lower-resource languages. We present a LID model which achieves a macro-average F1 score of 0.93 and a false positive rate of 0.033 across 201 languages, outperforming previous work. We achieve this by training on a curated dataset of monolingual data, the reliability of which we ensure by auditing a sample from each source and each language manually. We make both the model and the dataset available to the research community. Finally, we carry out detailed analysis into our model's performance, both in comparison to existing open models and by language class.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
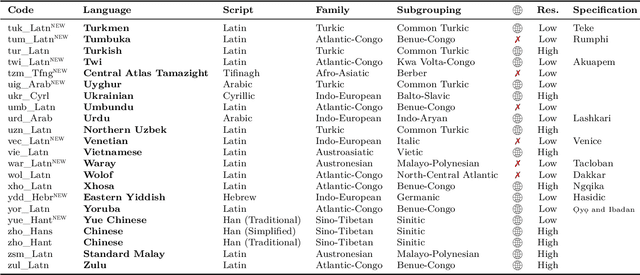
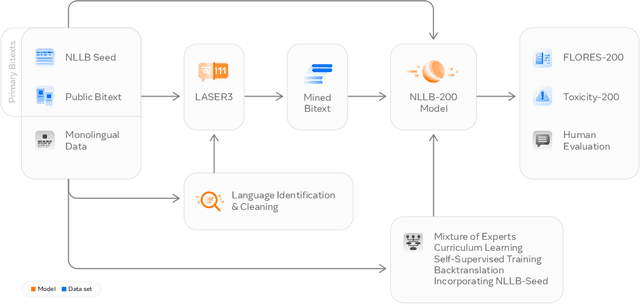
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Exploring Diversity in Back Translation for Low-Resource Machine Translation
Jun 01, 2022
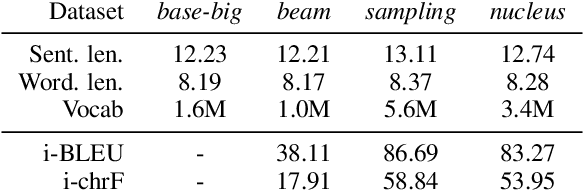
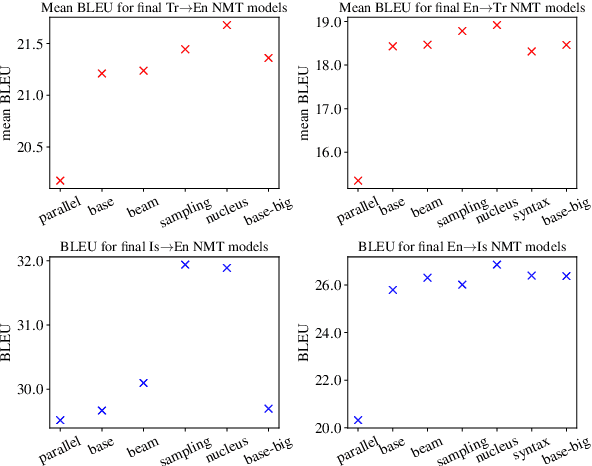
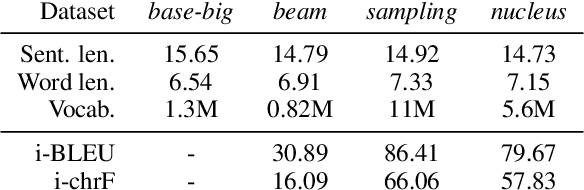
Back translation is one of the most widely used methods for improving the performance of neural machine translation systems. Recent research has sought to enhance the effectiveness of this method by increasing the 'diversity' of the generated translations. We argue that the definitions and metrics used to quantify 'diversity' in previous work have been insufficient. This work puts forward a more nuanced framework for understanding diversity in training data, splitting it into lexical diversity and syntactic diversity. We present novel metrics for measuring these different aspects of diversity and carry out empirical analysis into the effect of these types of diversity on final neural machine translation model performance for low-resource English$\leftrightarrow$Turkish and mid-resource English$\leftrightarrow$Icelandic. Our findings show that generating back translation using nucleus sampling results in higher final model performance, and that this method of generation has high levels of both lexical and syntactic diversity. We also find evidence that lexical diversity is more important than syntactic for back translation performance.
Direct simultaneous speech to speech translation
Oct 15, 2021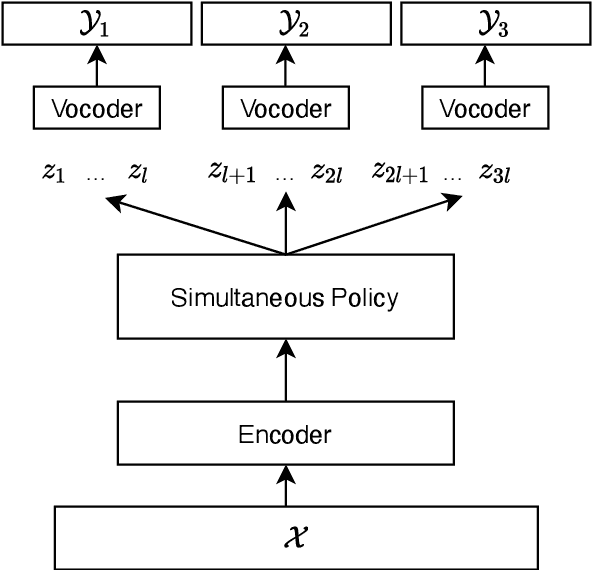
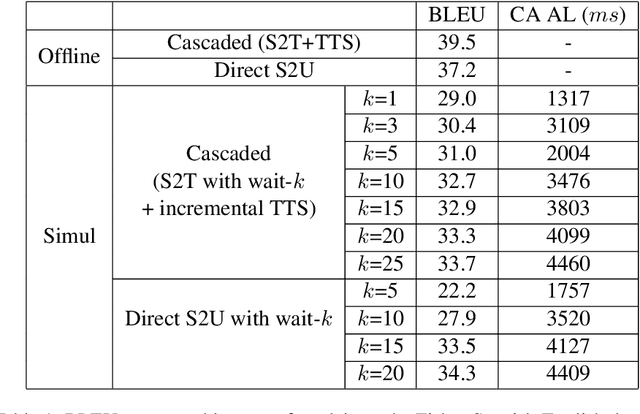
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
TranslateLocally: Blazing-fast translation running on the local CPU
Sep 21, 2021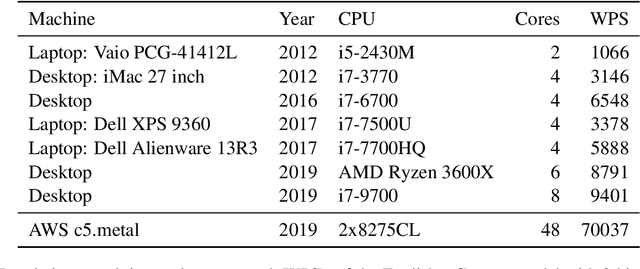
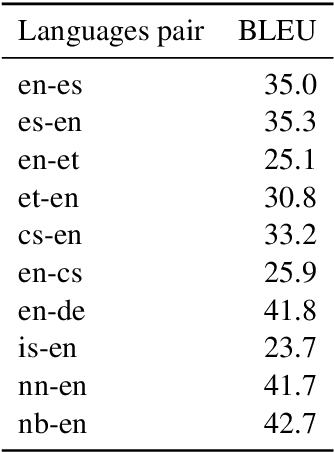
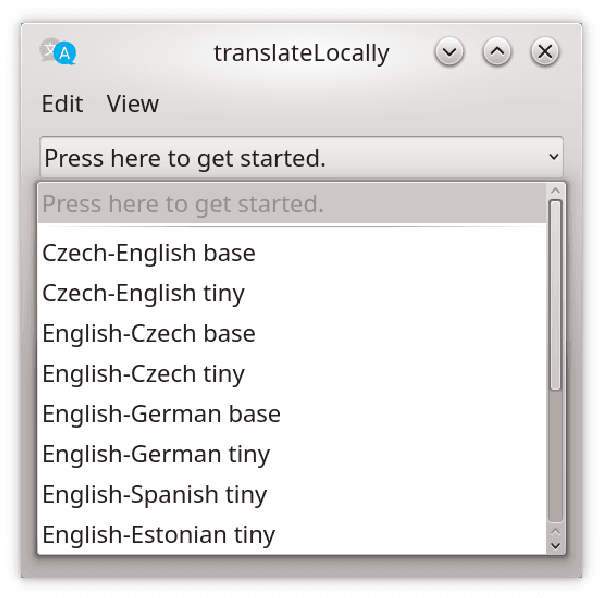
Every day, millions of people sacrifice their privacy and browsing habits in exchange for online machine translation. Companies and governments with confidentiality requirements often ban online translation or pay a premium to disable logging. To bring control back to the end user and demonstrate speed, we developed translateLocally. Running locally on a desktop or laptop CPU, translateLocally delivers cloud-like translation speed and quality even on 10 year old hardware. The open-source software is based on Marian and runs on Linux, Windows, and macOS.