 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Smile is Unique: Landmark-Guided Diverse Smile Generation
Mar 28, 2018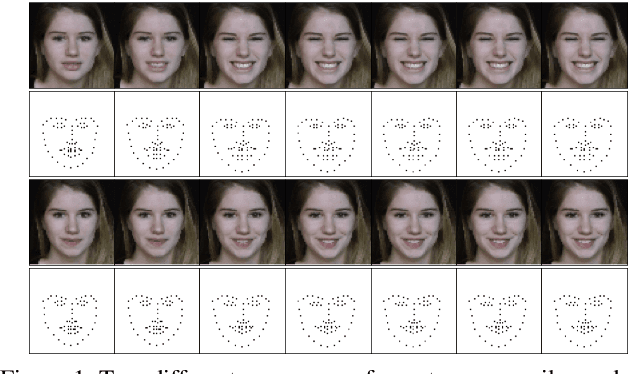
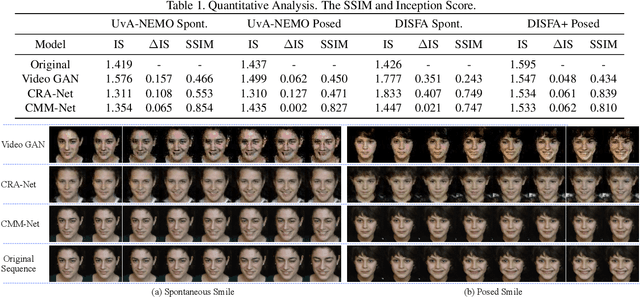
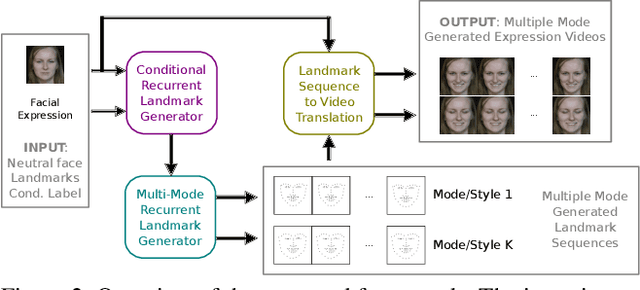
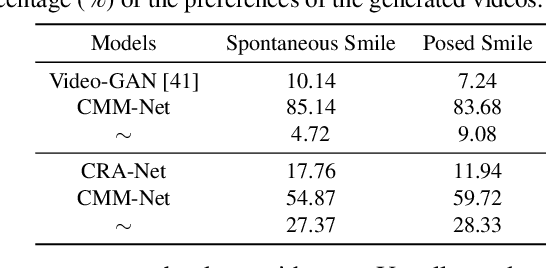
Each smile is unique: one person surely smiles in different ways (e.g., closing/opening the eyes or mouth). Given one input image of a neutral face, can we generate multiple smile videos with distinctive characteristics? To tackle this one-to-many video generation problem, we propose a novel deep learning architecture named Conditional Multi-Mode Network (CMM-Net). To better encode the dynamics of facial expressions, CMM-Net explicitly exploits facial landmarks for generating smile sequences. Specifically, a variational auto-encoder is used to learn a facial landmark embedding. This single embedding is then exploited by a conditional recurrent network which generates a landmark embedding sequence conditioned on a specific expression (e.g., spontaneous smile). Next, the generated landmark embeddings are fed into a multi-mode recurrent landmark generator, producing a set of landmark sequences still associated to the given smile class but clearly distinct from each other. Finally, these landmark sequences are translated into face videos. Our experimental results demonstrate the effectiveness of our CMM-Net in generating realistic videos of multiple smile expressions.
Eigendecomposition-free Training of Deep Networks with Zero Eigenvalue-based Losses
Mar 26, 2018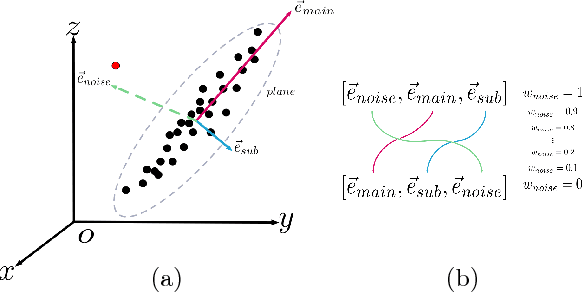
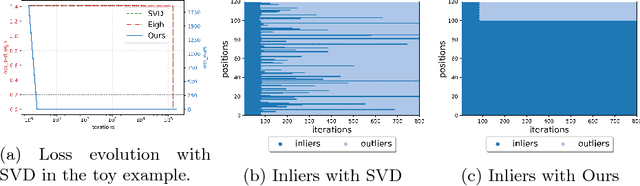
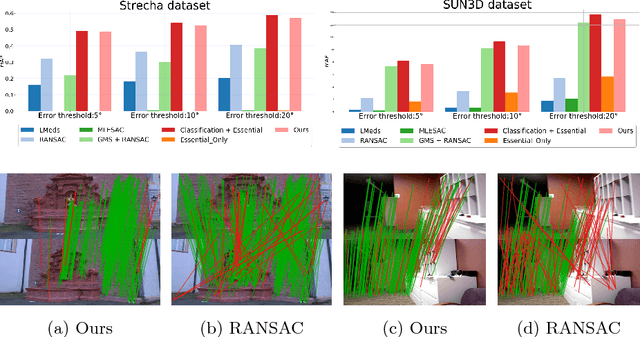
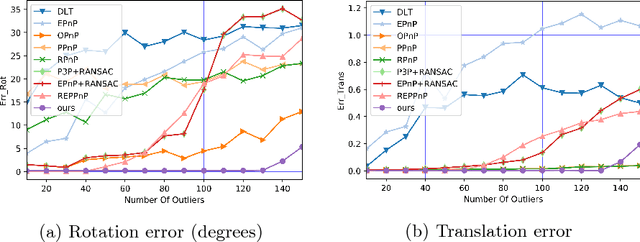
Many classical Computer Vision problems, such as essential matrix computation and pose estimation from 3D to 2D correspondences, can be solved by finding the eigenvector corresponding to the smallest, or zero, eigenvalue of a matrix representing a linear system. Incorporating this in deep learning frameworks would allow us to explicitly encode known notions of geometry, instead of having the network implicitly learn them from data. However, performing eigendecomposition within a network requires the ability to differentiate this operation. Unfortunately, while theoretically doable, this introduces numerical instability in the optimization process in practice. In this paper, we introduce an eigendecomposition-free approach to training a deep network whose loss depends on the eigenvector corresponding to a zero eigenvalue of a matrix predicted by the network. We demonstrate on several tasks, including keypoint matching and 3D pose estimation, that our approach is much more robust than explicit differentiation of the eigendecomposition, It has better convergence properties and yields state-of-the-art results on both tasks.
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018
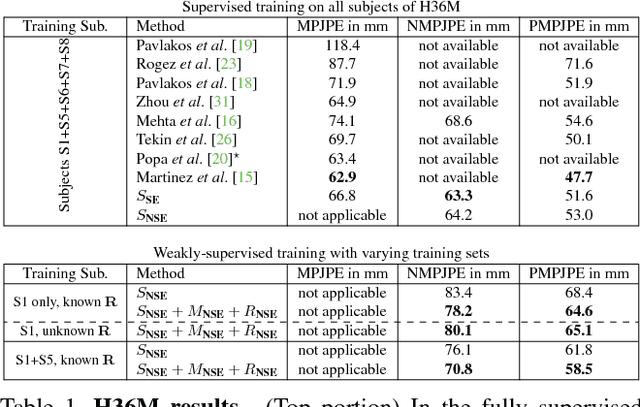

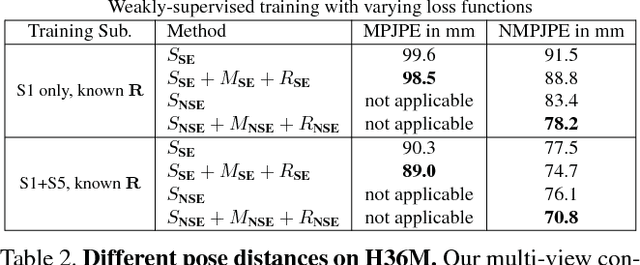
Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.
Geometric and Physical Constraints for Head Plane Crowd Density Estimation in Videos
Mar 23, 2018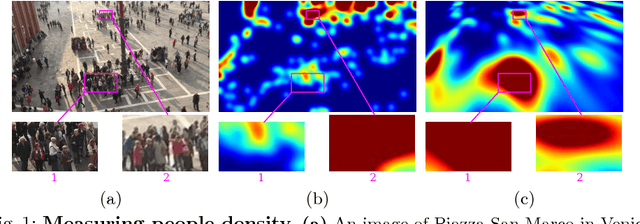
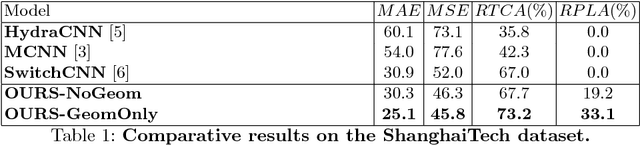
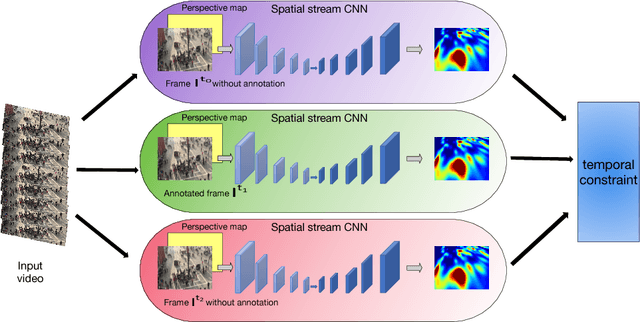
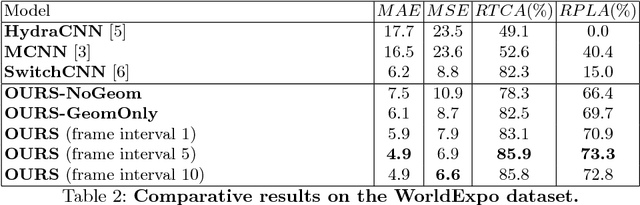
State-of-the-art methods of people counting in crowded scenes rely on deep networks to estimate people density in the image plane. Perspective distortion effects are handled implicitly by either learning scale-invariant features or estimating density in patches of different sizes, neither of which accounts for the fact that scale changes must be consistent over the whole scene. In this paper, we show that feeding an explicit model of the scale changes to the network considerably increases performance. An added benefit is that it lets us reason in terms of number of people per square meter on the ground, allowing us to enforce physically-inspired temporal consistency constraints that do not have to be learned. This yields an algorithm that outperforms state-of-the-art methods on crowded scenes, especially when perspective effects are strong.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018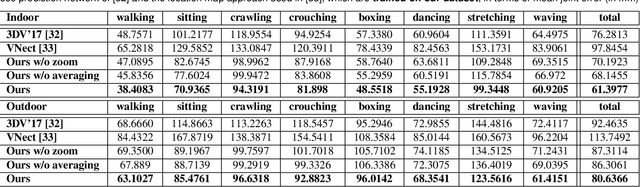


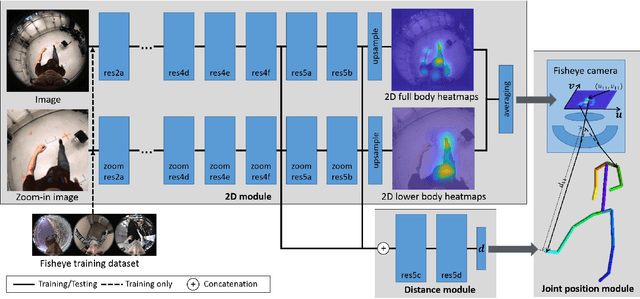
We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.
Geometry in Active Learning for Binary and Multi-class Image Segmentation
Jan 16, 2018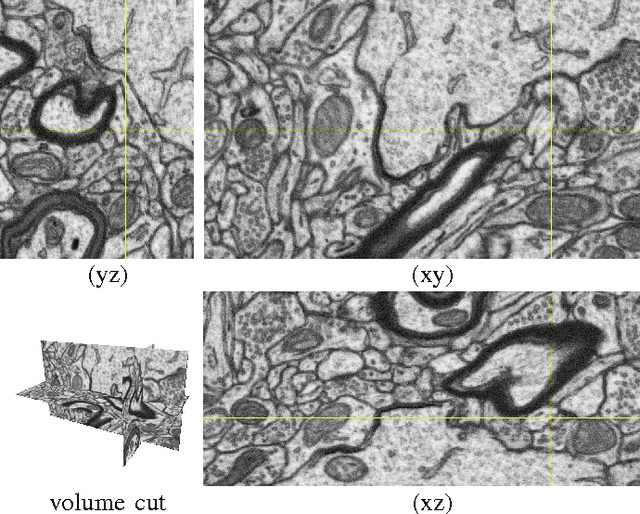

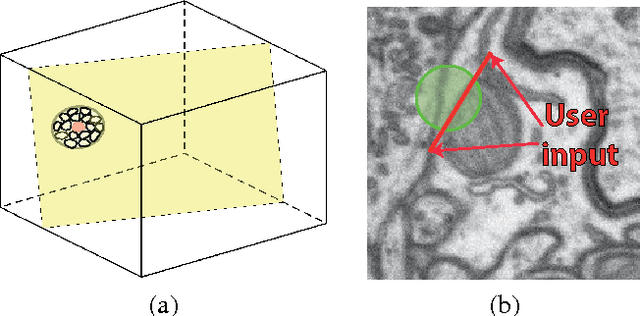
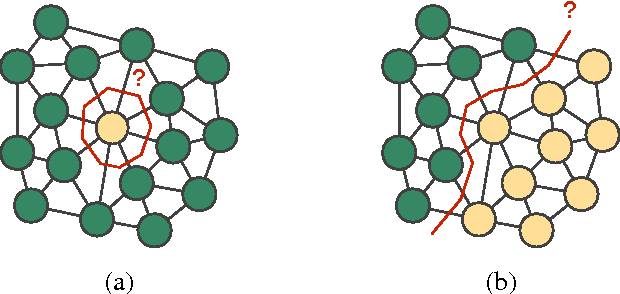
We propose an Active Learning approach to image segmentation that exploits geometric priors to streamline the annotation process. We demonstrate this for both background-foreground and multi-class segmentation tasks in 2D images and 3D image volumes. Our approach combines geometric smoothness priors in the image space with more traditional uncertainty measures to estimate which pixels or voxels are most in need of annotation. For multi-class settings, we additionally introduce two novel criteria for uncertainty. In the 3D case, we use the resulting uncertainty measure to show the annotator voxels lying on the same planar patch, which makes batch annotation much easier than if they were randomly distributed in the volume. The planar patch is found using a branch-and-bound algorithm that finds a patch with the most informative instances. We evaluate our approach on Electron Microscopy and Magnetic Resonance image volumes, as well as on regular images of horses and faces. We demonstrate a substantial performance increase over state-of-the-art approaches.
A Performance Evaluation of Local Features for Image Based 3D Reconstruction
Dec 14, 2017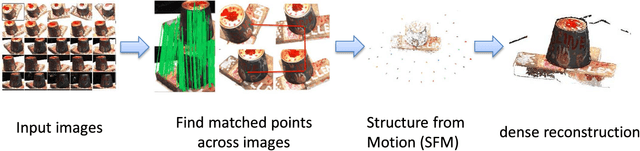

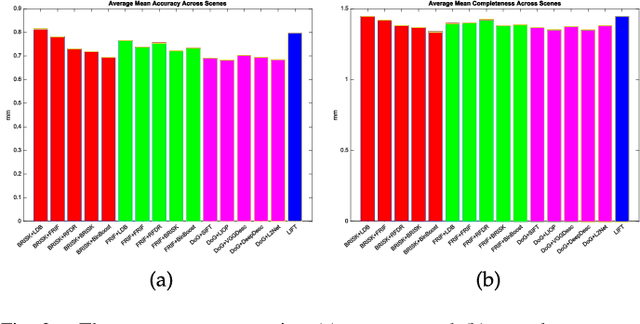
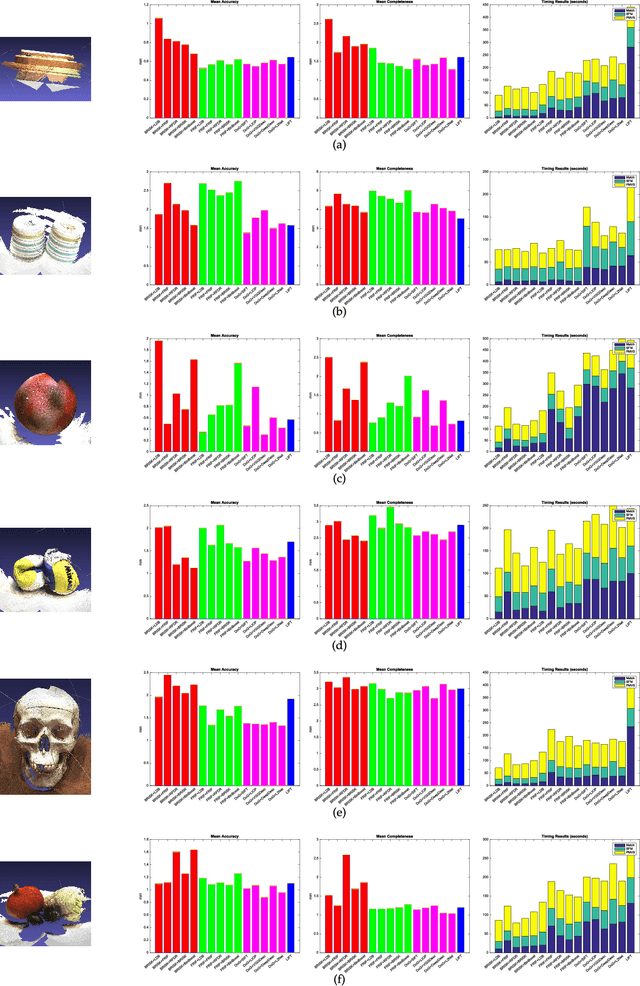
This paper performs a comprehensive and comparative evaluation of the state of the art local features for the task of image based 3D reconstruction. The evaluated local features cover the recently developed ones by using powerful machine learning techniques and the elaborately designed handcrafted features. To obtain a comprehensive evaluation, we choose to include both float type features and binary ones. Meanwhile, two kinds of datasets have been used in this evaluation. One is a dataset of many different scene types with groundtruth 3D points, containing images of different scenes captured at fixed positions, for quantitative performance evaluation of different local features in the controlled image capturing situations. The other dataset contains Internet scale image sets of several landmarks with a lot of unrelated images, which is used for qualitative performance evaluation of different local features in the free image collection situations. Our experimental results show that binary features are competent to reconstruct scenes from controlled image sequences with only a fraction of processing time compared to use float type features. However, for the case of large scale image set with many distracting images, float type features show a clear advantage over binary ones.
Beyond the Pixel-Wise Loss for Topology-Aware Delineation
Dec 06, 2017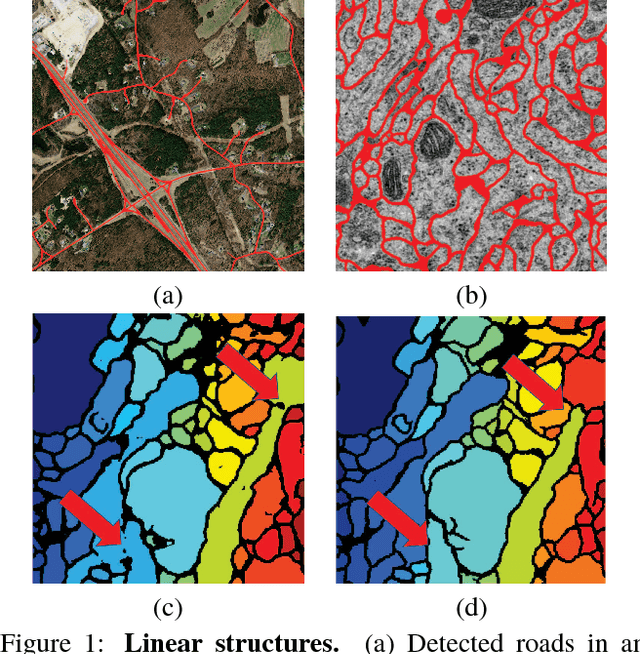

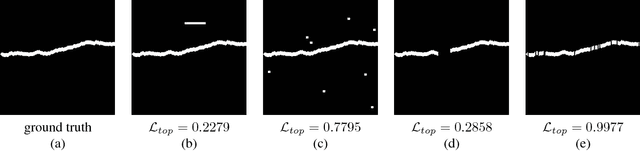

Delineation of curvilinear structures is an important problem in Computer Vision with multiple practical applications. With the advent of Deep Learning, many current approaches on automatic delineation have focused on finding more powerful deep architectures, but have continued using the habitual pixel-wise losses such as binary cross-entropy. In this paper we claim that pixel-wise losses alone are unsuitable for this problem because of their inability to reflect the topological impact of mistakes in the final prediction. We propose a new loss term that is aware of the higher-order topological features of linear structures. We also introduce a refinement pipeline that iteratively applies the same model over the previous delineation to refine the predictions at each step while keeping the number of parameters and the complexity of the model constant. When combined with the standard pixel-wise loss, both our new loss term and our iterative refinement boost the quality of the predicted delineations, in some cases almost doubling the accuracy as compared to the same classifier trained with the binary cross-entropy alone. We show that our approach outperforms state-of-the-art methods on a wide range of data, from microscopy to aerial images.
Flight Dynamics-based Recovery of a UAV Trajectory using Ground Cameras
Nov 21, 2017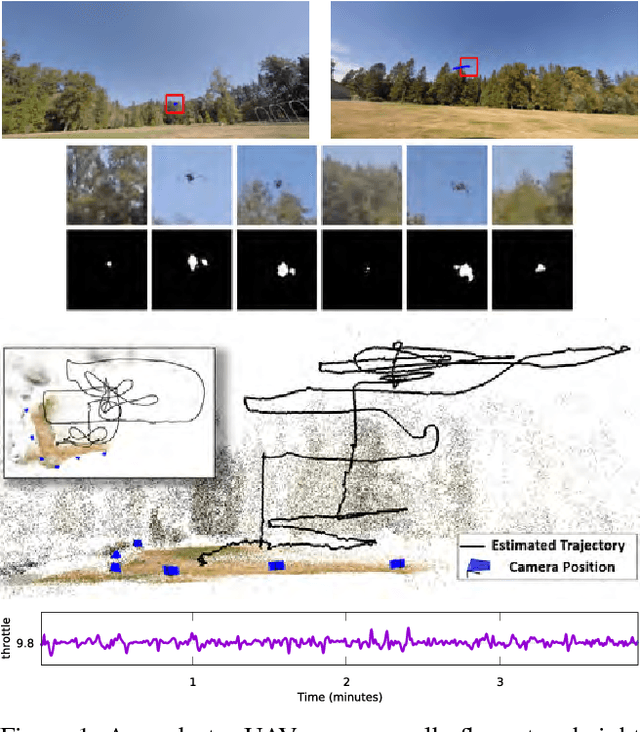

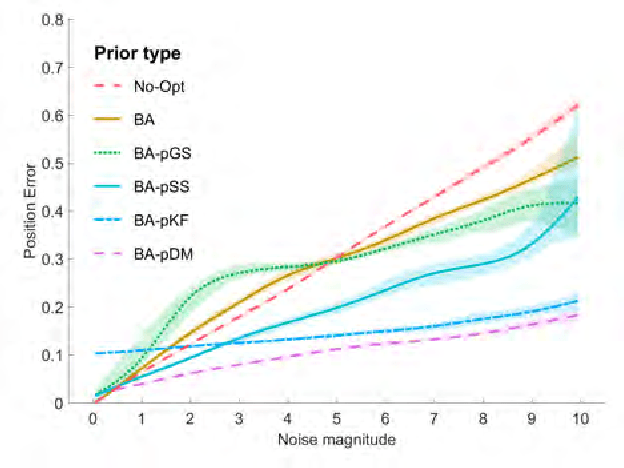
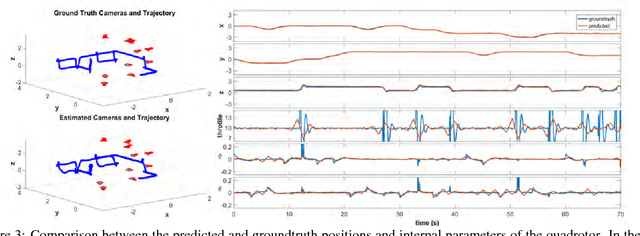
We propose a new method to estimate the 6-dof trajectory of a flying object such as a quadrotor UAV within a 3D airspace monitored using multiple fixed ground cameras. It is based on a new structure from motion formulation for the 3D reconstruction of a single moving point with known motion dynamics. Our main contribution is a new bundle adjustment procedure which in addition to optimizing the camera poses, regularizes the point trajectory using a prior based on motion dynamics (or specifically flight dynamics). Furthermore, we can infer the underlying control input sent to the UAV's autopilot that determined its flight trajectory. Our method requires neither perfect single-view tracking nor appearance matching across views. For robustness, we allow the tracker to generate multiple detections per frame in each video. The true detections and the data association across videos is estimated using robust multi-view triangulation and subsequently refined during our bundle adjustment procedure. Quantitative evaluation on simulated data and experiments on real videos from indoor and outdoor scenes demonstrates the effectiveness of our method.
Residual Parameter Transfer for Deep Domain Adaptation
Nov 21, 2017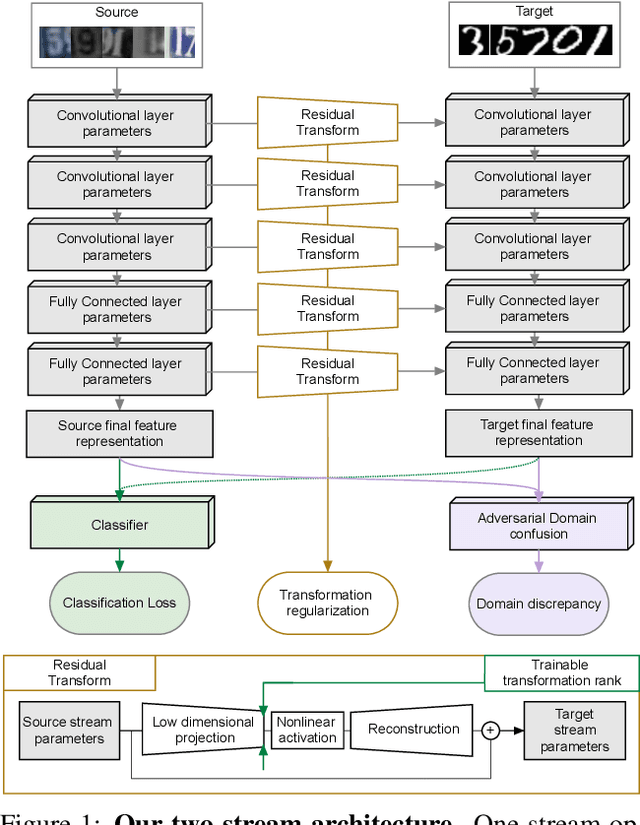

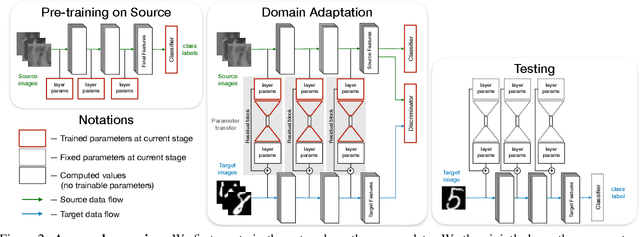

The goal of Deep Domain Adaptation is to make it possible to use Deep Nets trained in one domain where there is enough annotated training data in another where there is little or none. Most current approaches have focused on learning feature representations that are invariant to the changes that occur when going from one domain to the other, which means using the same network parameters in both domains. While some recent algorithms explicitly model the changes by adapting the network parameters, they either severely restrict the possible domain changes, or significantly increase the number of model parameters. By contrast, we introduce a network architecture that includes auxiliary residual networks, which we train to predict the parameters in the domain with little annotated data from those in the other one. This architecture enables us to flexibly preserve the similarities between domains where they exist and model the differences when necessary. We demonstrate that our approach yields higher accuracy than state-of-the-art methods without undue complexity.