 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColonoscopy Navigation using End-to-End Deep Visuomotor Control: A User Study
Jun 30, 2022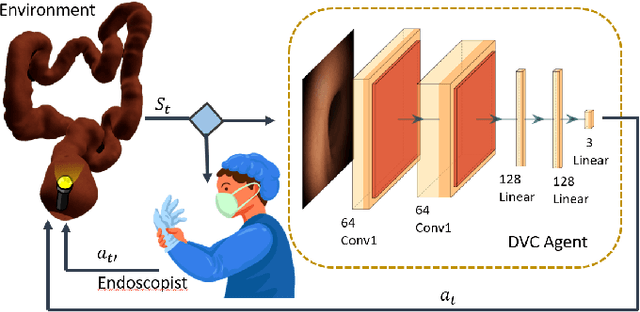
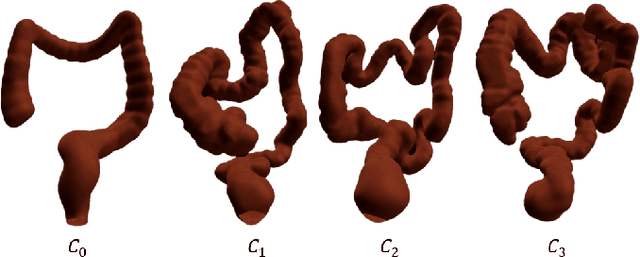
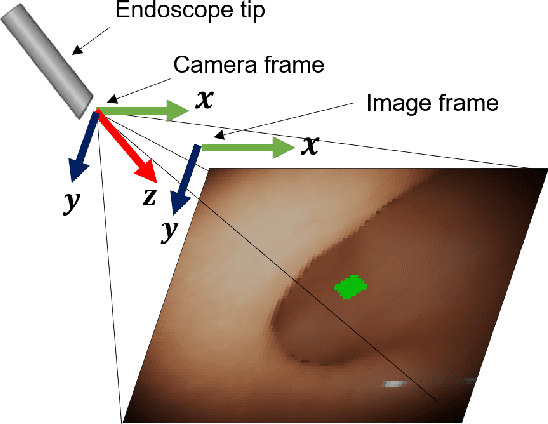
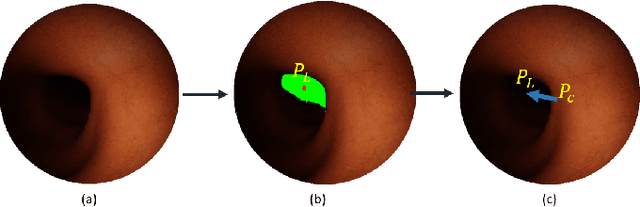
Flexible endoscopes for colonoscopy present several limitations due to their inherent complexity, resulting in patient discomfort and lack of intuitiveness for clinicians. Robotic devices together with autonomous control represent a viable solution to reduce the workload of endoscopists and the training time while improving the overall procedure outcome. Prior works on autonomous endoscope control use heuristic policies that limit their generalisation to the unstructured and highly deformable colon environment and require frequent human intervention. This work proposes an image-based control of the endoscope using Deep Reinforcement Learning, called Deep Visuomotor Control (DVC), to exhibit adaptive behaviour in convoluted sections of the colon tract. DVC learns a mapping between the endoscopic images and the control signal of the endoscope. A first user study of 20 expert gastrointestinal endoscopists was carried out to compare their navigation performance with DVC policies using a realistic virtual simulator. The results indicate that DVC shows equivalent performance on several assessment parameters, being more safer. Moreover, a second user study with 20 novice participants was performed to demonstrate easier human supervision compared to a state-of-the-art heuristic control policy. Seamless supervision of colonoscopy procedures would enable interventionists to focus on the medical decision rather than on the control problem of the endoscope.
Deliberation in autonomous robotic surgery: a framework for handling anatomical uncertainty
Mar 10, 2022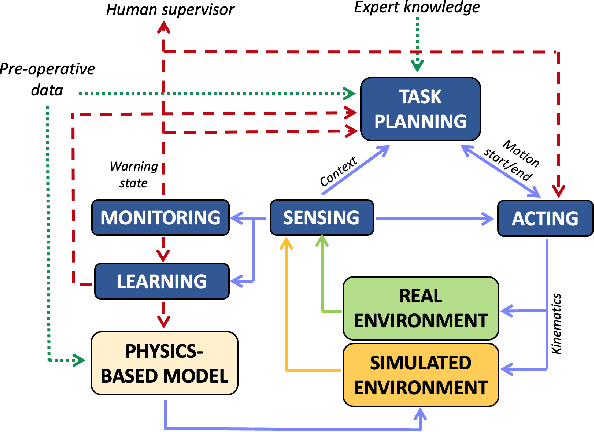


Autonomous robotic surgery requires deliberation, i.e. the ability to plan and execute a task adapting to uncertain and dynamic environments. Uncertainty in the surgical domain is mainly related to the partial pre-operative knowledge about patient-specific anatomical properties. In this paper, we introduce a logic-based framework for surgical tasks with deliberative functions of monitoring and learning. The DEliberative Framework for Robot-Assisted Surgery (DEFRAS) estimates a pre-operative patient-specific plan, and executes it while continuously measuring the applied force obtained from a biomechanical pre-operative model. Monitoring module compares this model with the actual situation reconstructed from sensors. In case of significant mismatch, the learning module is invoked to update the model, thus improving the estimate of the exerted force. DEFRAS is validated both in simulated and real environment with da Vinci Research Kit executing soft tissue retraction. Compared with state-of-the art related works, the success rate of the task is improved while minimizing the interaction with the tissue to prevent unintentional damage.
Data Stream Stabilization for Optical Coherence Tomography Volumetric Scanning
Dec 02, 2021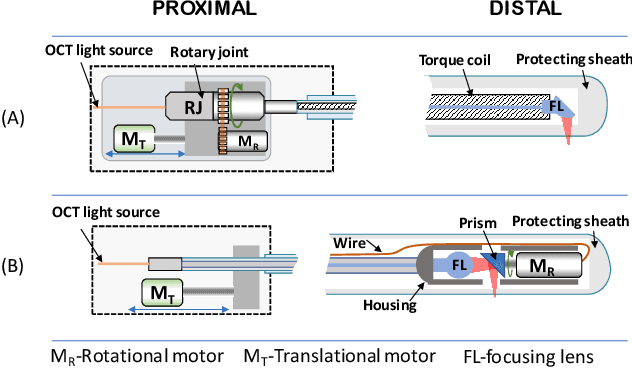
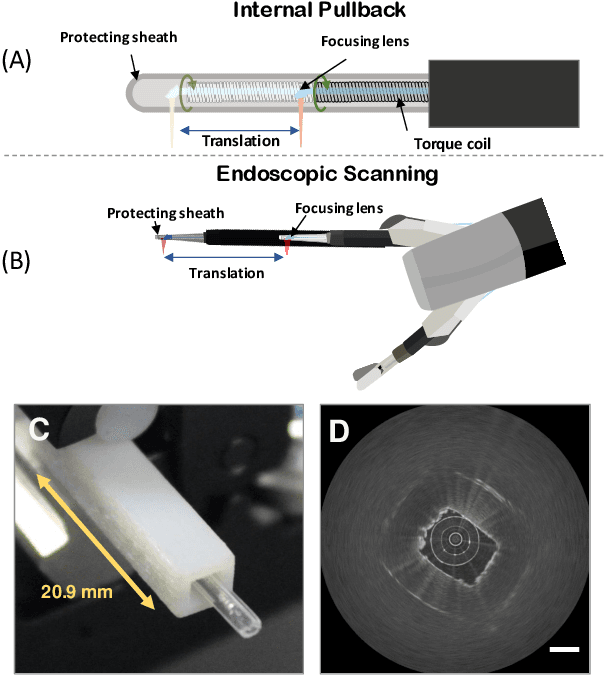
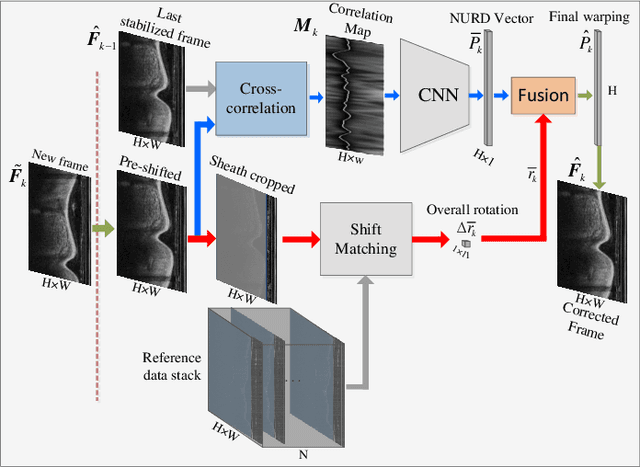
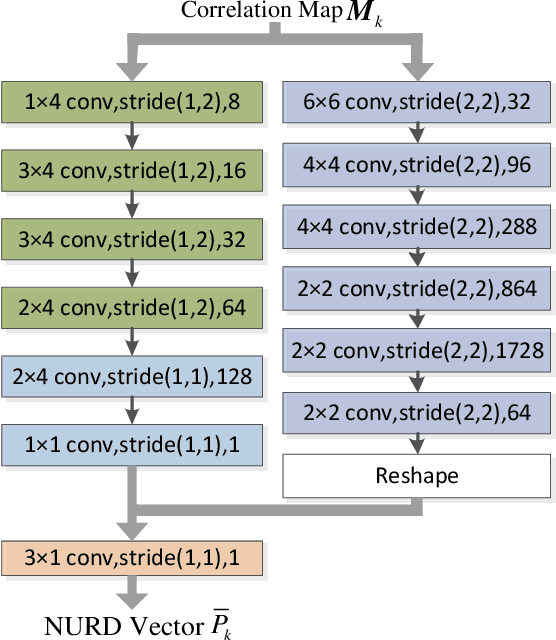
Optical Coherence Tomography (OCT) is an emerging medical imaging modality for luminal organ diagnosis. The non-constant rotation speed of optical components in the OCT catheter tip causes rotational distortion in OCT volumetric scanning. By improving the scanning process, this instability can be partially reduced. To further correct the rotational distortion in the OCT image, a volumetric data stabilization algorithm is proposed. The algorithm first estimates the Non-Uniform Rotational Distortion (NURD) for each B-scan by using a Convolutional Neural Network (CNN). A correlation map between two successive B-scans is computed and provided as input to the CNN. To solve the problem of accumulative error in iterative frame stream processing, we deploy an overall rotation estimation between reference orientation and actual OCT image orientation. We train the network with synthetic OCT videos by intentionally adding rotational distortion into real OCT images. As part of this article we discuss the proposed method in two different scanning modes: the first is a conventional pullback mode where the optical components move along the protection sheath, and the second is a self-designed scanning mode where the catheter is globally translated by using an external actuator. The efficiency and robustness of the proposed method are evaluated with synthetic scans as well as real scans under two scanning modes.
* 11pages, 5 figures
Learning from Demonstrations for Autonomous Soft-tissue Retraction
Oct 01, 2021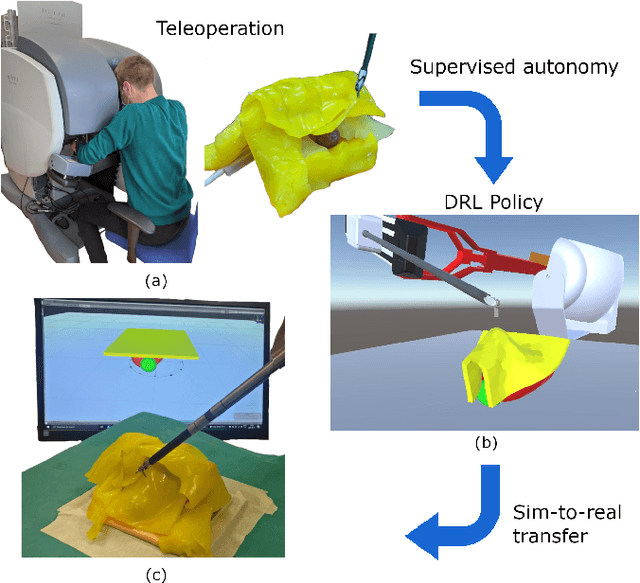
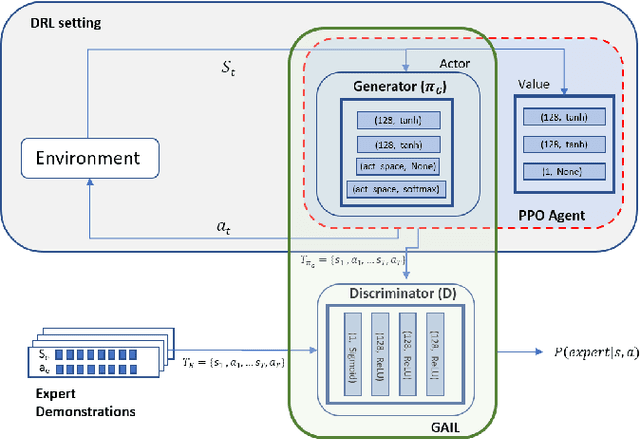
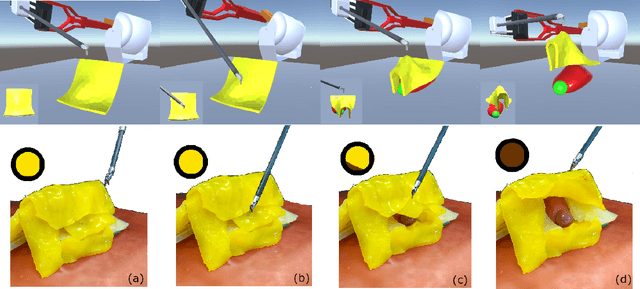
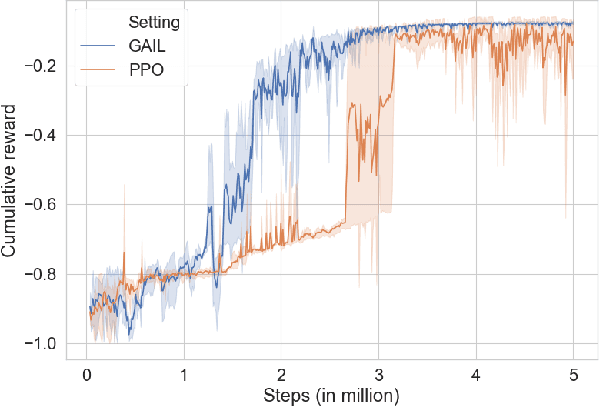
The current research focus in Robot-Assisted Minimally Invasive Surgery (RAMIS) is directed towards increasing the level of robot autonomy, to place surgeons in a supervisory position. Although Learning from Demonstrations (LfD) approaches are among the preferred ways for an autonomous surgical system to learn expert gestures, they require a high number of demonstrations and show poor generalization to the variable conditions of the surgical environment. In this work, we propose an LfD methodology based on Generative Adversarial Imitation Learning (GAIL) that is built on a Deep Reinforcement Learning (DRL) setting. GAIL combines generative adversarial networks to learn the distribution of expert trajectories with a DRL setting to ensure generalisation of trajectories providing human-like behaviour. We consider automation of tissue retraction, a common RAMIS task that involves soft tissues manipulation to expose a region of interest. In our proposed methodology, a small set of expert trajectories can be acquired through the da Vinci Research Kit (dVRK) and used to train the proposed LfD method inside a simulated environment. Results indicate that our methodology can accomplish the tissue retraction task with human-like behaviour while being more sample-efficient than the baseline DRL method. Towards the end, we show that the learnt policies can be successfully transferred to the real robotic platform and deployed for soft tissue retraction on a synthetic phantom.
Safe Reinforcement Learning using Formal Verification for Tissue Retraction in Autonomous Robotic-Assisted Surgery
Sep 06, 2021
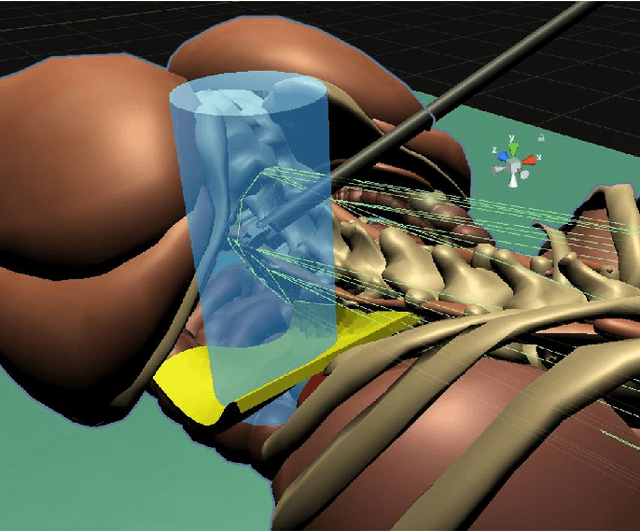
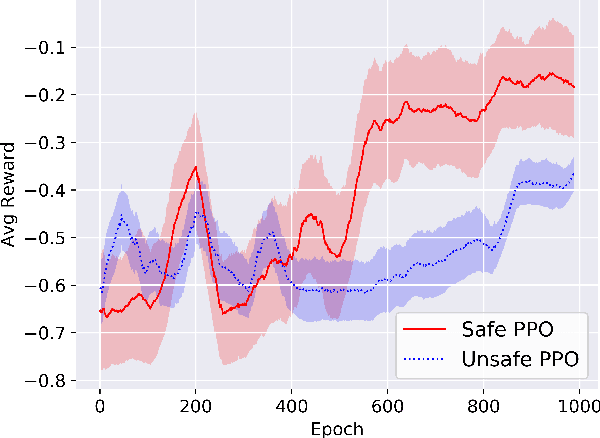
Deep Reinforcement Learning (DRL) is a viable solution for automating repetitive surgical subtasks due to its ability to learn complex behaviours in a dynamic environment. This task automation could lead to reduced surgeon's cognitive workload, increased precision in critical aspects of the surgery, and fewer patient-related complications. However, current DRL methods do not guarantee any safety criteria as they maximise cumulative rewards without considering the risks associated with the actions performed. Due to this limitation, the application of DRL in the safety-critical paradigm of robot-assisted Minimally Invasive Surgery (MIS) has been constrained. In this work, we introduce a Safe-DRL framework that incorporates safety constraints for the automation of surgical subtasks via DRL training. We validate our approach in a virtual scene that replicates a tissue retraction task commonly occurring in multiple phases of an MIS. Furthermore, to evaluate the safe behaviour of the robotic arms, we formulate a formal verification tool for DRL methods that provides the probability of unsafe configurations. Our results indicate that a formal analysis guarantees safety with high confidence such that the robotic instruments operate within the safe workspace and avoid hazardous interaction with other anatomical structures.
Industry 4.0 and Prospects of Circular Economy: A Survey of Robotic Assembly and Disassembly
Jun 14, 2021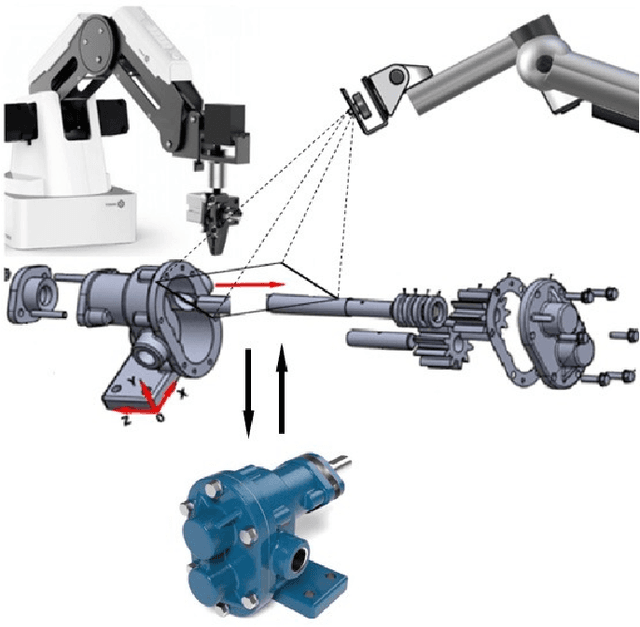
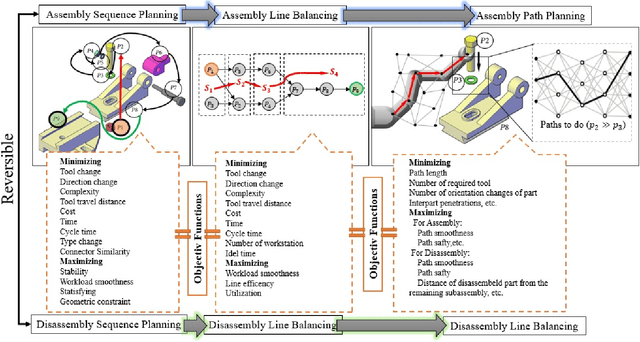
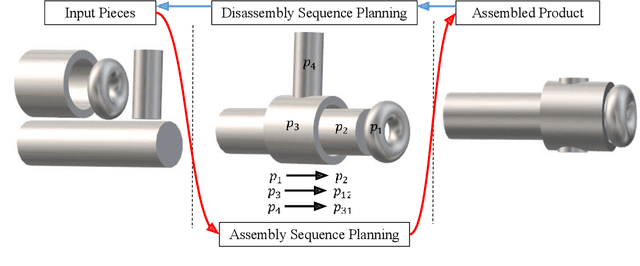

Despite their contributions to the financial efficiency and environmental sustainability of industrial processes, robotic assembly and disassembly have been understudied in the existing literature. This is in contradiction to their importance in realizing the Fourth Industrial Revolution. More specifically, although most of the literature has extensively discussed how to optimally assemble or disassemble given products, the role of other factors has been overlooked. For example, the types of robots involved in implementing the sequence plans, which should ideally be taken into account throughout the whole chain consisting of design, assembly, disassembly and reassembly. Isolating the foregoing operations from the rest of the components of the relevant ecosystems may lead to erroneous inferences toward both the necessity and efficiency of the underlying procedures. In this paper we try to alleviate these shortcomings by comprehensively investigating the state-of-the-art in robotic assembly and disassembly. We consider and review various aspects of manufacturing and remanufacturing frameworks while particularly focusing on their desirability for supporting a circular economy.
Unsupervised identification of surgical robotic actions from small non homogeneous datasets
May 18, 2021

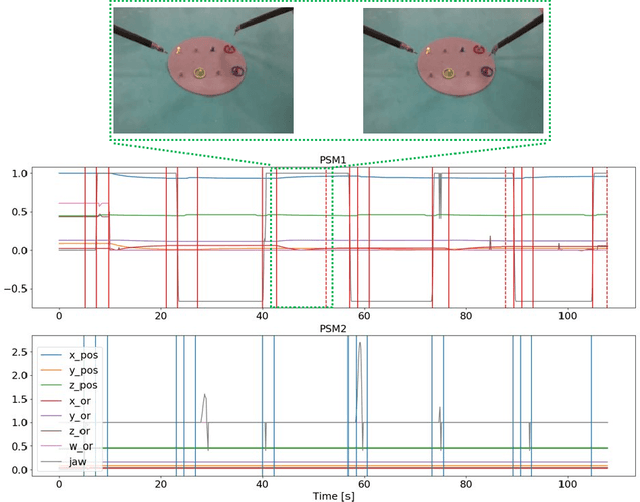
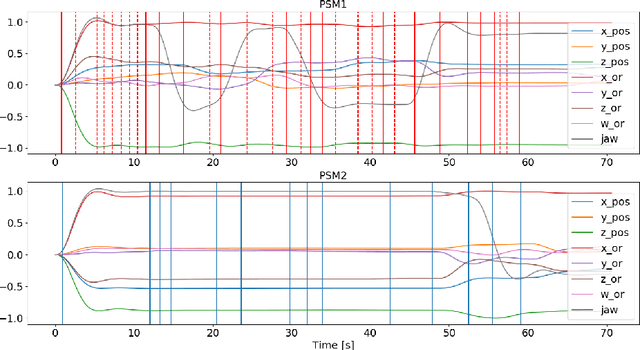
Robot-assisted surgery is an established clinical practice. The automatic identification of surgical actions is needed for a range of applications, including performance assessment of trainees and surgical process modeling for autonomous execution and monitoring. However, supervised action identification is not feasible, due to the burden of manually annotating recordings of potentially complex and long surgical executions. Moreover, often few example executions of a surgical procedure can be recorded. This paper proposes a novel algorithm for unsupervised identification of surgical actions in a standard surgical training task, the ring transfer, executed with da Vinci Research Kit. Exploiting kinematic and semantic visual features automatically extracted from a very limited dataset of executions, we are able to significantly outperform the state-of-the-art results for a similar application, improving the quality of segmentation (88% vs. 82% matching score) and clustering (67% vs. 54% F1-score) even in the presence of noise, short actions and non homogeneous workflows, i.e. non repetitive action sequences. Full action identification on hardware with standard commercial specifications is performed in less than 1 s for single execution.
Towards Hierarchical Task Decomposition using Deep Reinforcement Learning for Pick and Place Subtasks
Mar 01, 2021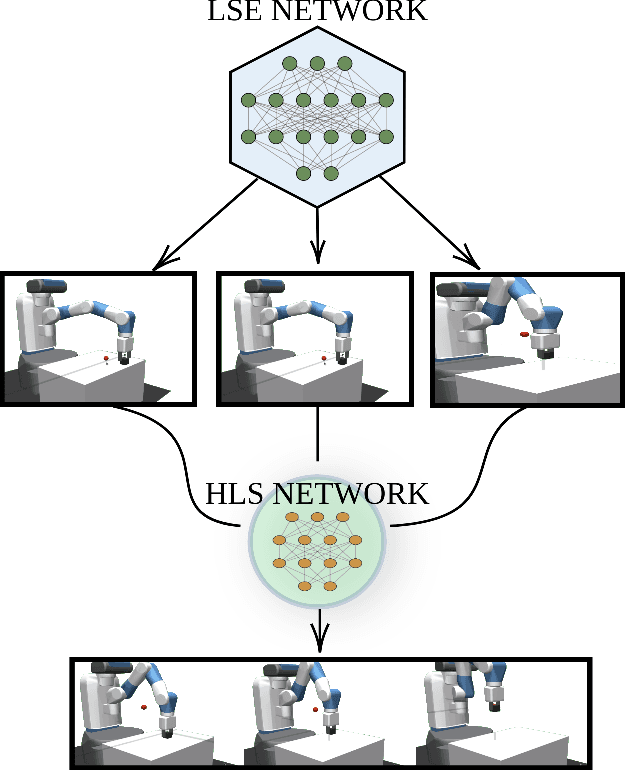
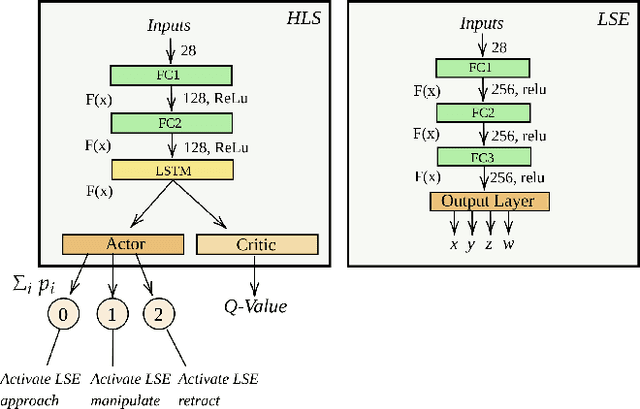
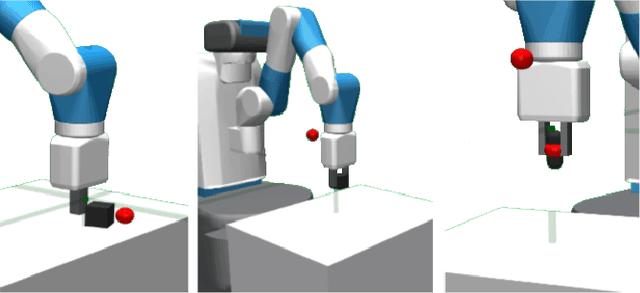
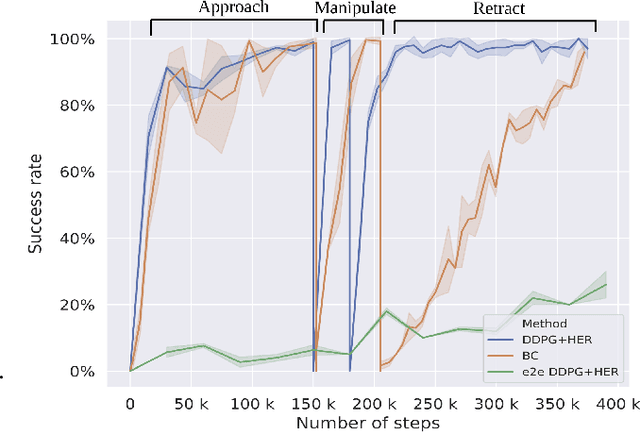
Deep Reinforcement Learning (DRL) is emerging as a promising approach to generate adaptive behaviors for robotic platforms. However, a major drawback of using DRL is the data-hungry training regime that requires millions of trial and error attempts, which is impractical when running experiments on robotic systems. To address this issue, we propose a multi-subtask reinforcement learning method where complex tasks are decomposed manually into low-level subtasks by leveraging human domain knowledge. These subtasks can be parametrized as expert networks and learned via existing DRL methods. Trained subtasks can then be composed with a high-level choreographer. As a testbed, we use a pick and place robotic simulator to demonstrate our methodology, and show that our method outperforms an imitation learning-based method and reaches a high success rate compared to an end-to-end learning approach. Moreover, we transfer the learned behavior in a different robotic environment that allows us to exploit sim-to-real transfer and demonstrate the trajectories in a real robotic system. Our training regime is carried out using a central processing unit (CPU)-based system, which demonstrates the data-efficient properties of our approach.
Multi-Task Temporal Convolutional Networks for Joint Recognition of Surgical Phases and Steps in Gastric Bypass Procedures
Feb 24, 2021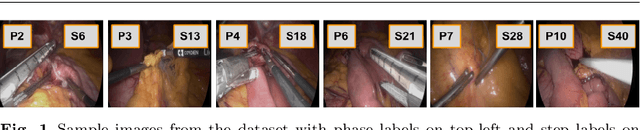
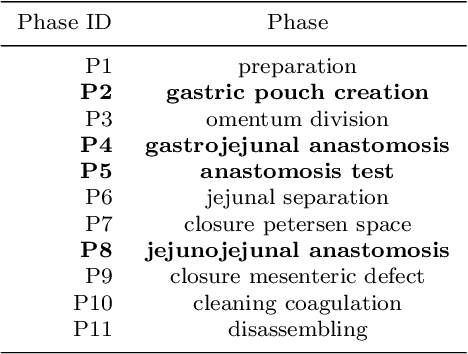
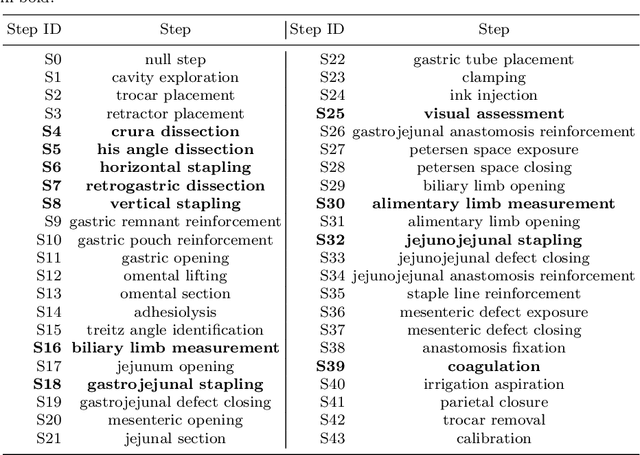
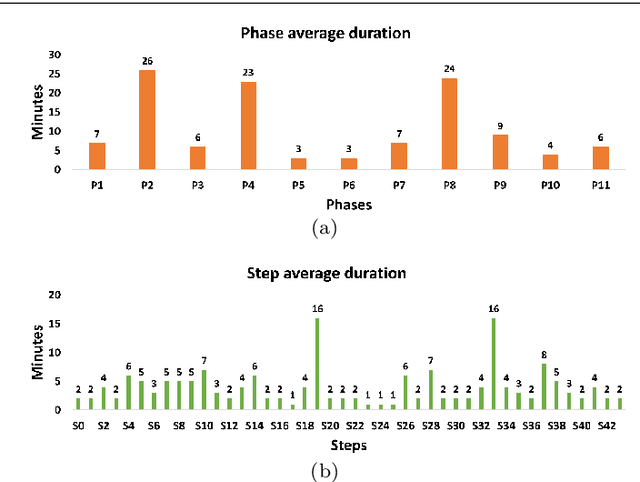
Purpose: Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps. Method: We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a Multi-task Multi-Stage Temporal Convolutional Network (MTMS-TCN) along with a multi-task Convolutional Neural Network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40). Results: We present experimental results from several baseline models for both phase and step recognition on the Bypass40 dataset. The proposed MTMS-TCN method outperforms in both phase and step recognition by 1-2% in accuracy, precision and recall, compared to single-task methods. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM based models in accuracy, precision, and recall. Conclusion: In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on the Bypass40 gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.
Improving rigid 3D calibration for robotic surgery
Jul 16, 2020
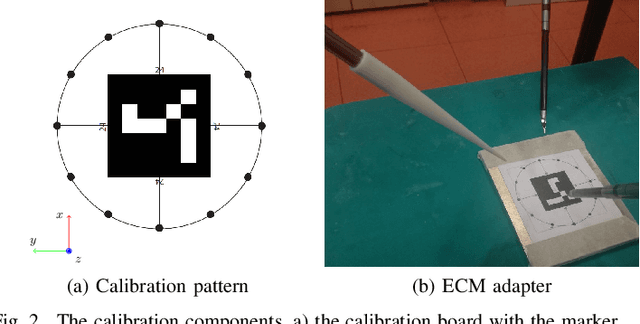

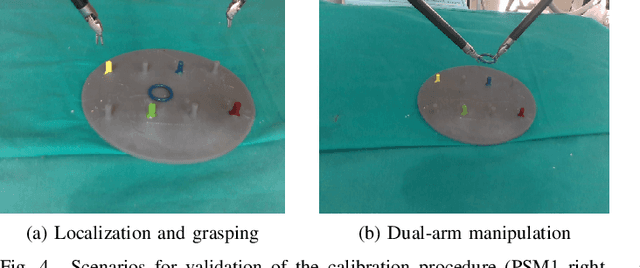
Autonomy is the frontier of research in robotic surgery and its aim is to improve the quality of surgical procedures in the next future. One fundamental requirement for autonomy is advanced perception capability through vision sensors. In this paper, we propose a novel calibration technique for a surgical scenario with da Vinci robot. Calibration of the camera and the robot is necessary for precise positioning of the tools in order to emulate the high performance surgeons. Our calibration technique is tailored for RGB-D camera. Different tests performed on relevant use cases for surgery prove that we significantly improve precision and accuracy with respect to the state of the art solutions for similar devices on a surgical-size setup. Moreover, our calibration method can be easily extended to standard surgical endoscope to prompt its use in real surgical scenario.