 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Near-Optimal Hypothesis Selection
Aug 17, 2021



Hypothesis Selection is a fundamental distribution learning problem where given a comparator-class $Q=\{q_1,\ldots, q_n\}$ of distributions, and a sampling access to an unknown target distribution $p$, the goal is to output a distribution $q$ such that $\mathsf{TV}(p,q)$ is close to $opt$, where $opt = \min_i\{\mathsf{TV}(p,q_i)\}$ and $\mathsf{TV}(\cdot, \cdot)$ denotes the total-variation distance. Despite the fact that this problem has been studied since the 19th century, its complexity in terms of basic resources, such as number of samples and approximation guarantees, remains unsettled (this is discussed, e.g., in the charming book by Devroye and Lugosi `00). This is in stark contrast with other (younger) learning settings, such as PAC learning, for which these complexities are well understood. We derive an optimal $2$-approximation learning strategy for the Hypothesis Selection problem, outputting $q$ such that $\mathsf{TV}(p,q) \leq2 \cdot opt + \eps$, with a (nearly) optimal sample complexity of~$\tilde O(\log n/\epsilon^2)$. This is the first algorithm that simultaneously achieves the best approximation factor and sample complexity: previously, Bousquet, Kane, and Moran (COLT `19) gave a learner achieving the optimal $2$-approximation, but with an exponentially worse sample complexity of $\tilde O(\sqrt{n}/\epsilon^{2.5})$, and Yatracos~(Annals of Statistics `85) gave a learner with optimal sample complexity of $O(\log n /\epsilon^2)$ but with a sub-optimal approximation factor of $3$.
A Theory of Universal Learning
Nov 09, 2020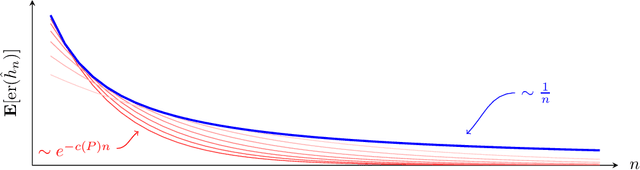
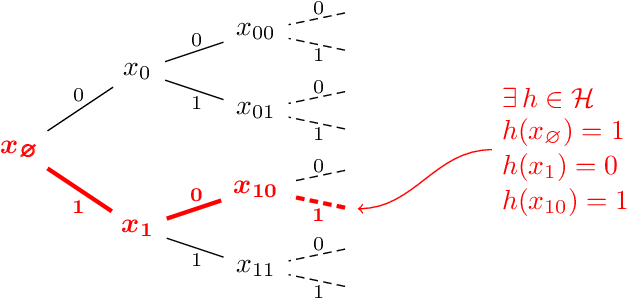
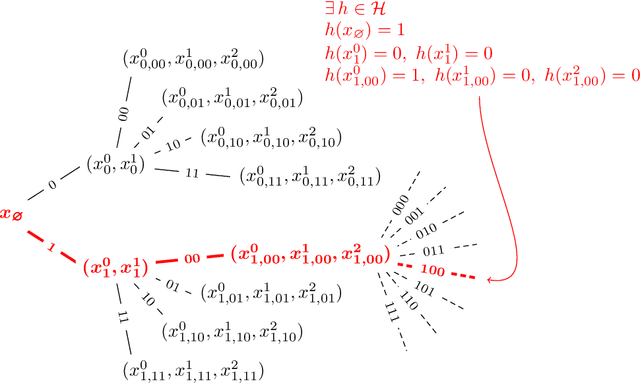
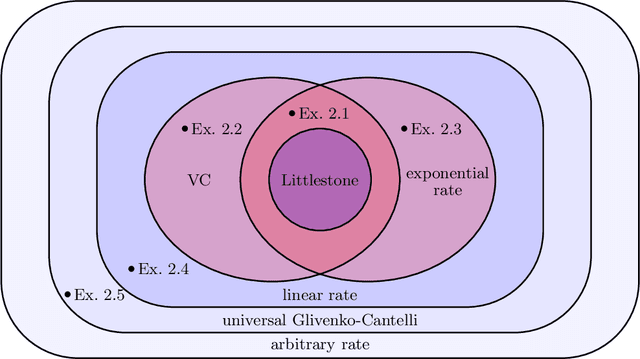
How quickly can a given class of concepts be learned from examples? It is common to measure the performance of a supervised machine learning algorithm by plotting its "learning curve", that is, the decay of the error rate as a function of the number of training examples. However, the classical theoretical framework for understanding learnability, the PAC model of Vapnik-Chervonenkis and Valiant, does not explain the behavior of learning curves: the distribution-free PAC model of learning can only bound the upper envelope of the learning curves over all possible data distributions. This does not match the practice of machine learning, where the data source is typically fixed in any given scenario, while the learner may choose the number of training examples on the basis of factors such as computational resources and desired accuracy. In this paper, we study an alternative learning model that better captures such practical aspects of machine learning, but still gives rise to a complete theory of the learnable in the spirit of the PAC model. More precisely, we consider the problem of universal learning, which aims to understand the performance of learning algorithms on every data distribution, but without requiring uniformity over the distribution. The main result of this paper is a remarkable trichotomy: there are only three possible rates of universal learning. More precisely, we show that the learning curves of any given concept class decay either at an exponential, linear, or arbitrarily slow rates. Moreover, each of these cases is completely characterized by appropriate combinatorial parameters, and we exhibit optimal learning algorithms that achieve the best possible rate in each case. For concreteness, we consider in this paper only the realizable case, though analogous results are expected to extend to more general learning scenarios.
What Do Neural Networks Learn When Trained With Random Labels?
Jun 18, 2020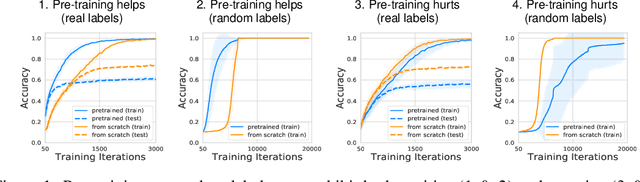
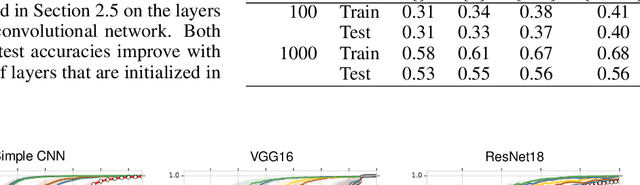
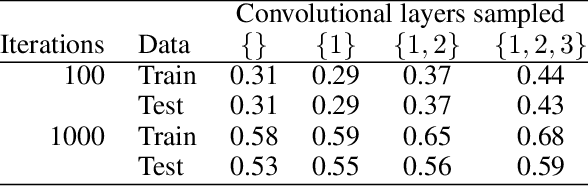
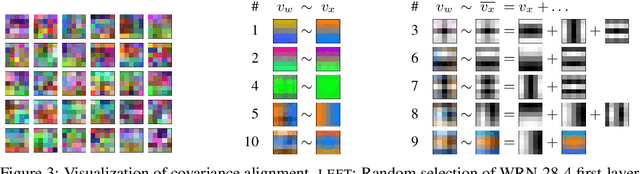
We study deep neural networks (DNNs) trained on natural image data with entirely random labels. Despite its popularity in the literature, where it is often used to study memorization, generalization, and other phenomena, little is known about what DNNs learn in this setting. In this paper, we show analytically for convolutional and fully connected networks that an alignment between the principal components of network parameters and data takes place when training with random labels. We study this alignment effect by investigating neural networks pre-trained on randomly labelled image data and subsequently fine-tuned on disjoint datasets with random or real labels. We show how this alignment produces a positive transfer: networks pre-trained with random labels train faster downstream compared to training from scratch even after accounting for simple effects, such as weight scaling. We analyze how competing effects, such as specialization at later layers, may hide the positive transfer. These effects are studied in several network architectures, including VGG16 and ResNet18, on CIFAR10 and ImageNet.
Proper Learning, Helly Number, and an Optimal SVM Bound
May 24, 2020
The classical PAC sample complexity bounds are stated for any Empirical Risk Minimizer (ERM) and contain an extra logarithmic factor $\log(1/{\epsilon})$ which is known to be necessary for ERM in general. It has been recently shown by Hanneke (2016) that the optimal sample complexity of PAC learning for any VC class C is achieved by a particular improper learning algorithm, which outputs a specific majority-vote of hypotheses in C. This leaves the question of when this bound can be achieved by proper learning algorithms, which are restricted to always output a hypothesis from C. In this paper we aim to characterize the classes for which the optimal sample complexity can be achieved by a proper learning algorithm. We identify that these classes can be characterized by the dual Helly number, which is a combinatorial parameter that arises in discrete geometry and abstract convexity. In particular, under general conditions on C, we show that the dual Helly number is bounded if and only if there is a proper learner that obtains the optimal joint dependence on $\epsilon$ and $\delta$. As further implications of our techniques we resolve a long-standing open problem posed by Vapnik and Chervonenkis (1974) on the performance of the Support Vector Machine by proving that the sample complexity of SVM in the realizable case is $\Theta((n/{\epsilon})+(1/{\epsilon})\log(1/{\delta}))$, where $n$ is the dimension. This gives the first optimal PAC bound for Halfspaces achieved by a proper learning algorithm, and moreover is computationally efficient.
Predicting Neural Network Accuracy from Weights
Feb 26, 2020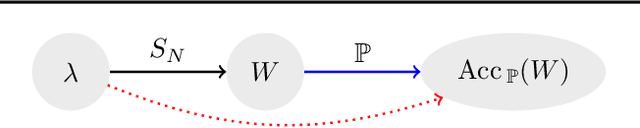
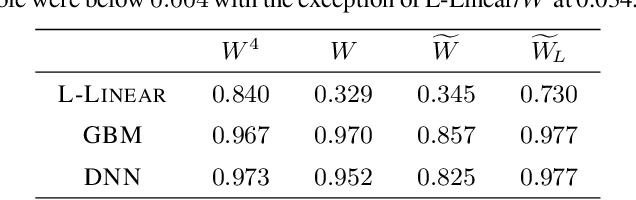
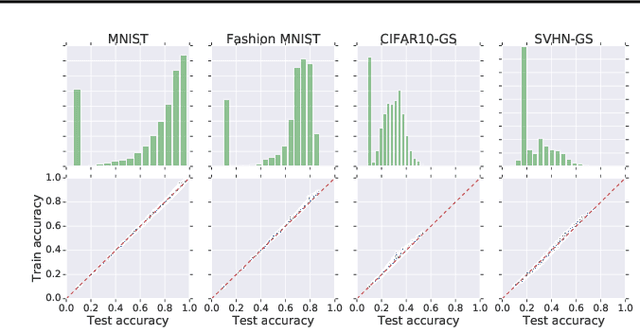
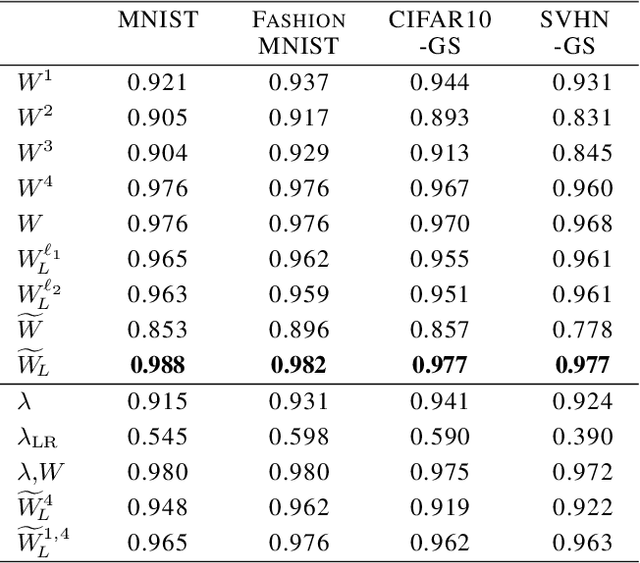
We study the prediction of the accuracy of a neural network given only its weights with the goal of better understanding network training and performance. To do so, we propose a formal setting which frames this task and connects to previous work in this area. We collect (and release) a large dataset of almost 80k convolutional neural networks trained on four image datasets. We demonstrate that strong predictors of accuracy exist. Moreover, they can achieve good predictions while only using simple statistics of the weights. Surprisingly, these predictors are able to rank networks trained on unobserved datasets or using different architectures.
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Dec 20, 2019

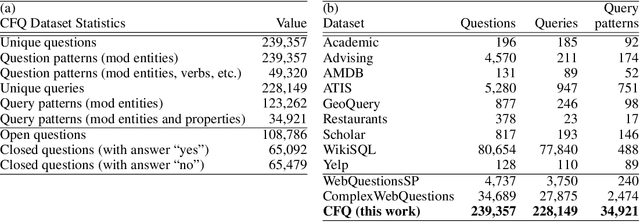
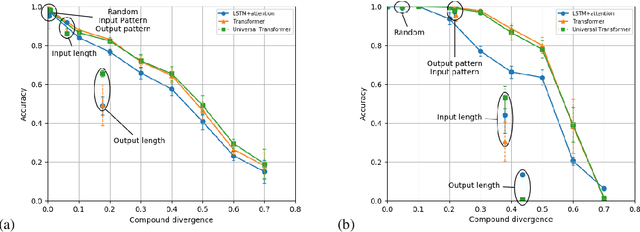
State-of-the-art machine learning methods exhibit limited compositional generalization. At the same time, there is a lack of realistic benchmarks that comprehensively measure this ability, which makes it challenging to find and evaluate improvements. We introduce a novel method to systematically construct such benchmarks by maximizing compound divergence while guaranteeing a small atom divergence between train and test sets, and we quantitatively compare this method to other approaches for creating compositional generalization benchmarks. We present a large and realistic natural language question answering dataset that is constructed according to this method, and we use it to analyze the compositional generalization ability of three machine learning architectures. We find that they fail to generalize compositionally and that there is a surprisingly strong negative correlation between compound divergence and accuracy. We also demonstrate how our method can be used to create new compositionality benchmarks on top of the existing SCAN dataset, which confirms these findings.
Fast classification rates without standard margin assumptions
Oct 28, 2019We consider the classical problem of learning rates for classes with finite VC dimension. It is well known that fast learning rates are achievable by the empirical risk minimization algorithm (ERM) if one of the low noise/margin assumptions such as Tsybakov's and Massart's condition is satisfied. In this paper, we consider an alternative way of obtaining fast learning rates in classification if none of these conditions are met. We first consider Chow's reject option model and show that by lowering the impact of a small fraction of hard instances, fast learning rate is achievable in an agnostic model by a specific learning algorithm. Similar results were only known under special versions of margin assumptions. We also show that the learning algorithm achieving these rates is adaptive to standard margin assumptions and always satisfies the risk bounds achieved by ERM. Based on our results on Chow's model, we then analyze a particular family of VC classes, namely classes with finite combinatorial diameter. Using their special structure, we show that there is an improper learning algorithm that provides fast rates of convergence even in the (poorly understood) situations where ERM is suboptimal. This provides the first setup in which an improper learning algorithm may significantly improve the learning rates for non-convex losses. Finally, we discuss some implications of our techniques to the analysis of ERM.
Sharper bounds for uniformly stable algorithms
Oct 17, 2019The generalization bounds for stable algorithms is a classical question in learning theory taking its roots in the early works of Vapnik and Chervonenkis and Rogers and Wagner. In a series of recent breakthrough papers, Feldman and Vondrak have shown that the best known high probability upper bounds for uniformly stable learning algorithms due to Bousquet and Elisseeff are sub-optimal in some natural regimes. To do so, they proved two generalization bounds that significantly outperform the original generalization bound. Feldman and Vondrak also asked if it is possible to provide sharper bounds and prove corresponding high probability lower bounds. This paper is devoted to these questions: firstly, inspired by the original arguments of, we provide a short proof of the moment bound that implies the generalization bound stronger than both recent results. Secondly, we prove general lower bounds, showing that our moment bound is sharp (up to a logarithmic factor) unless some additional properties of the corresponding random variables are used. Our main probabilistic result is a general concentration inequality for weakly correlated random variables, which may be of independent interest.
The Visual Task Adaptation Benchmark
Oct 01, 2019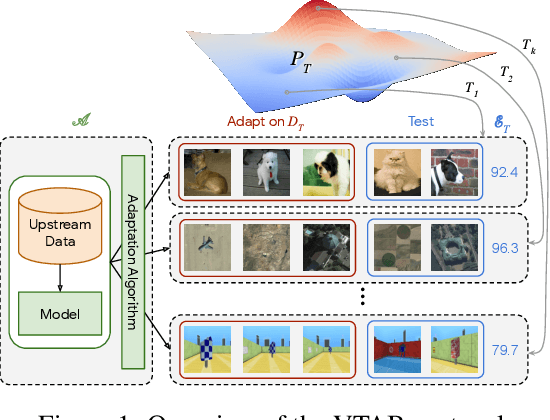
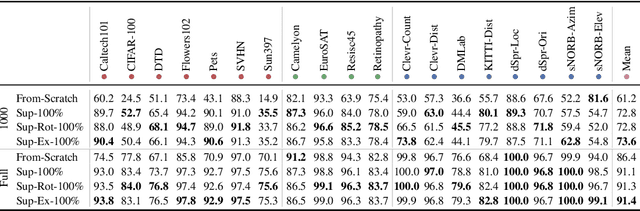
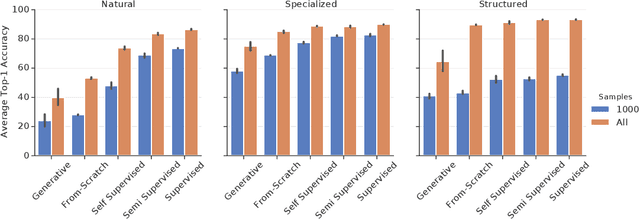
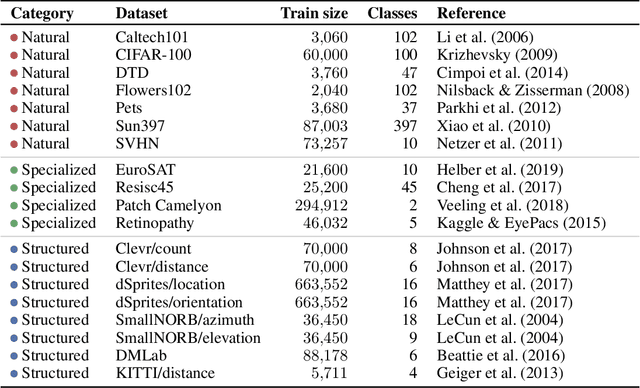
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
Google Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.