 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Retraining by Recycling Parameter-Efficient Prompts
Aug 10, 2022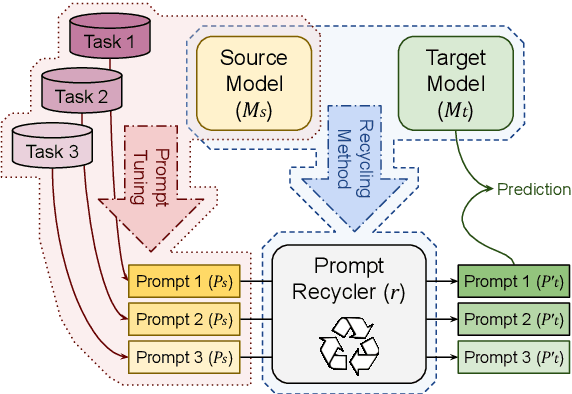
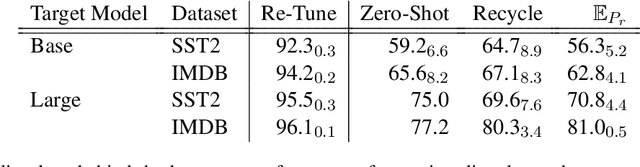
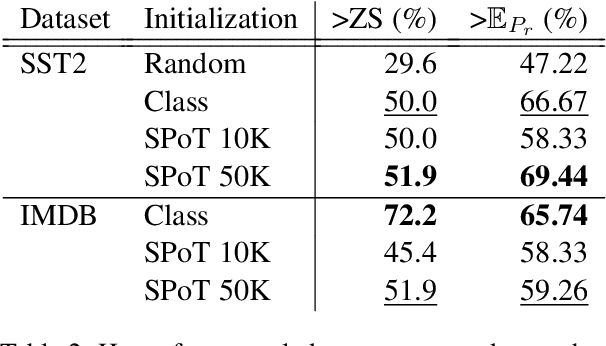
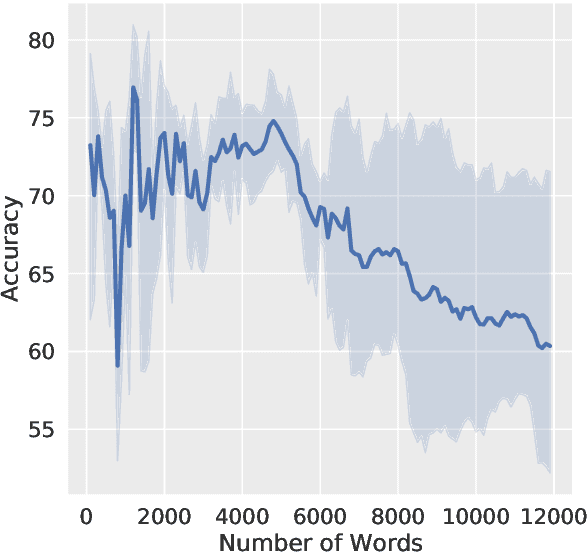
Parameter-efficient methods are able to use a single frozen pre-trained large language model (LLM) to perform many tasks by learning task-specific soft prompts that modulate model behavior when concatenated to the input text. However, these learned prompts are tightly coupled to a given frozen model -- if the model is updated, corresponding new prompts need to be obtained. In this work, we propose and investigate several approaches to "Prompt Recycling'" where a prompt trained on a source model is transformed to work with the new target model. Our methods do not rely on supervised pairs of prompts, task-specific data, or training updates with the target model, which would be just as costly as re-tuning prompts with the target model from scratch. We show that recycling between models is possible (our best settings are able to successfully recycle $88.9\%$ of prompts, producing a prompt that out-performs baselines), but significant performance headroom remains, requiring improved recycling techniques.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation
May 25, 2022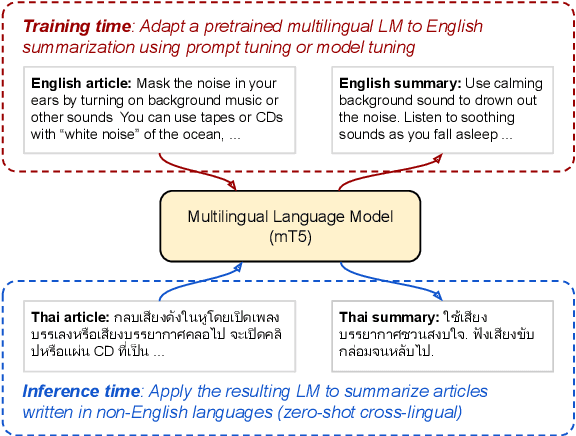
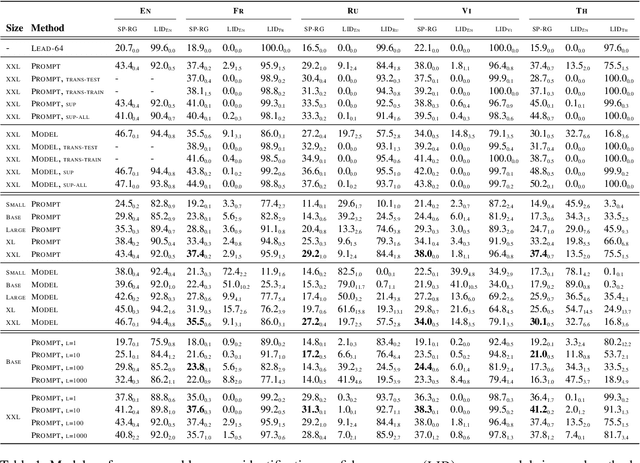
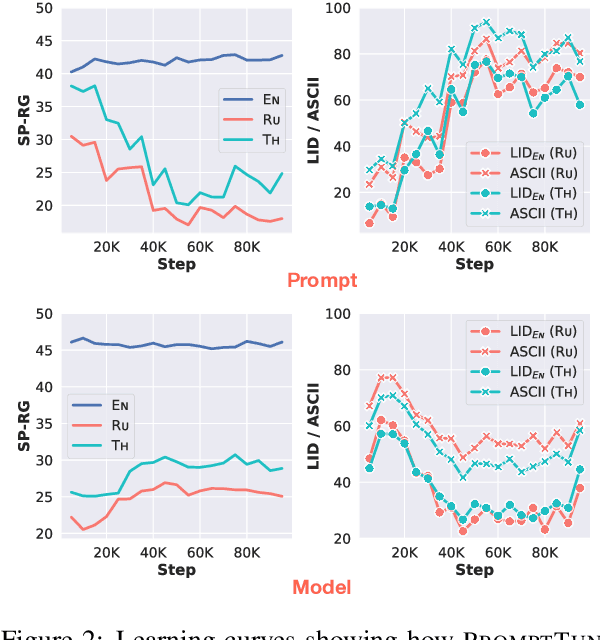
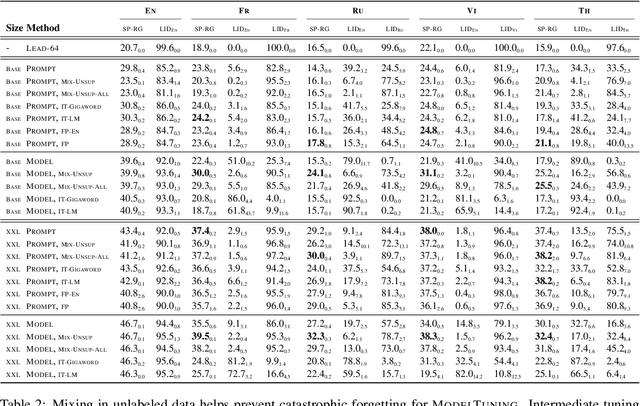
In this paper, we explore the challenging problem of performing a generative task (i.e., summarization) in a target language when labeled data is only available in English. We assume a strict setting with no access to parallel data or machine translation. Prior work has shown, and we confirm, that standard transfer learning techniques struggle in this setting, as a generative multilingual model fine-tuned purely on English catastrophically forgets how to generate non-English. Given the recent rise of parameter-efficient adaptation techniques (e.g., prompt tuning), we conduct the first investigation into how well these methods can overcome catastrophic forgetting to enable zero-shot cross-lingual generation. We find that parameter-efficient adaptation provides gains over standard fine-tuning when transferring between less-related languages, e.g., from English to Thai. However, a significant gap still remains between these methods and fully-supervised baselines. To improve cross-lingual transfer further, we explore three approaches: (1) mixing in unlabeled multilingual data, (2) pre-training prompts on target language data, and (3) explicitly factoring prompts into recombinable language and task components. Our methods can provide further quality gains, suggesting that robust zero-shot cross-lingual generation is within reach.
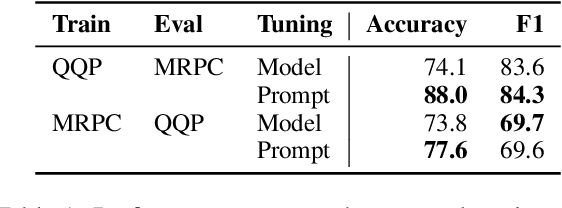
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Oct 15, 2021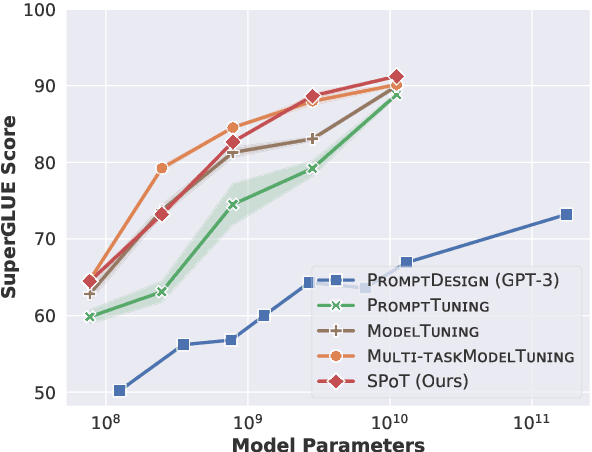
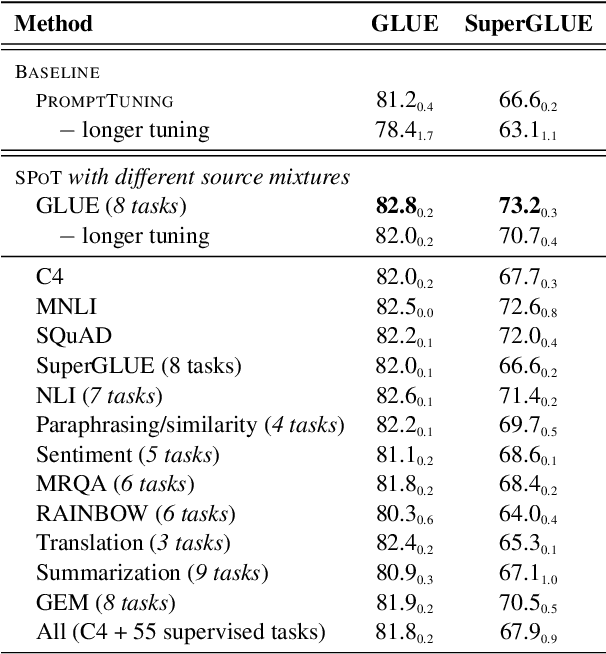
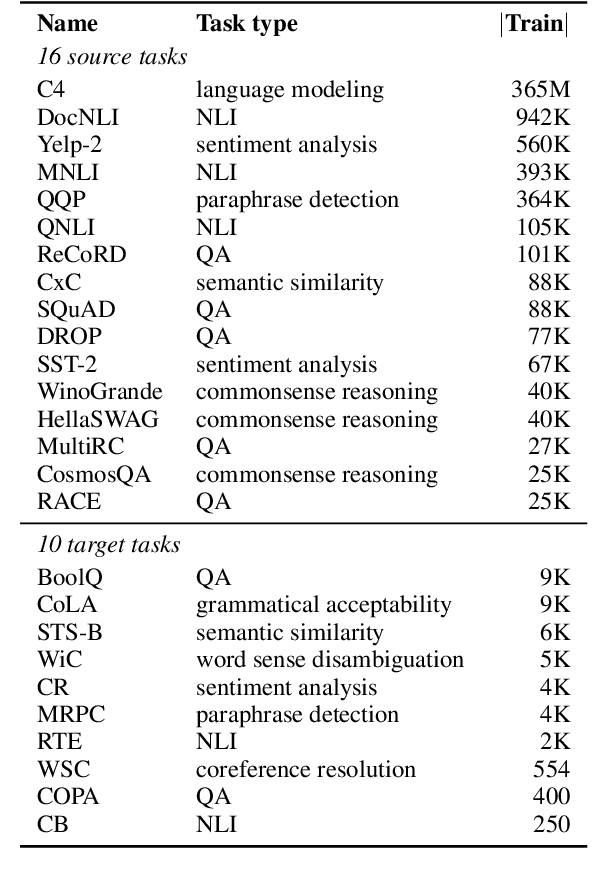
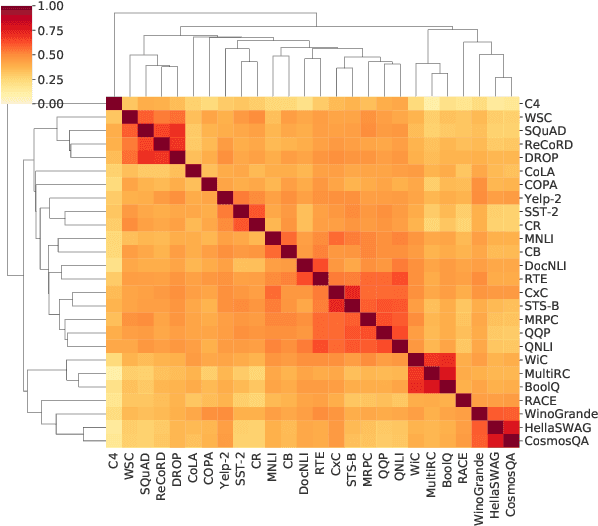
As pre-trained language models have gotten larger, there has been growing interest in parameter-efficient methods to apply these models to downstream tasks. Building on the PromptTuning approach of Lester et al. (2021), which learns task-specific soft prompts to condition a frozen language model to perform downstream tasks, we propose a novel prompt-based transfer learning approach called SPoT: Soft Prompt Transfer. SPoT first learns a prompt on one or more source tasks and then uses it to initialize the prompt for a target task. We show that SPoT significantly boosts the performance of PromptTuning across many tasks. More importantly, SPoT either matches or outperforms ModelTuning, which fine-tunes the entire model on each individual task, across all model sizes while being more parameter-efficient (up to 27,000x fewer task-specific parameters). We further conduct a large-scale study on task transferability with 26 NLP tasks and 160 combinations of source-target tasks, and demonstrate that tasks can often benefit each other via prompt transfer. Finally, we propose a simple yet efficient retrieval approach that interprets task prompts as task embeddings to identify the similarity between tasks and predict the most transferable source tasks for a given novel target task.
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
Aug 26, 2021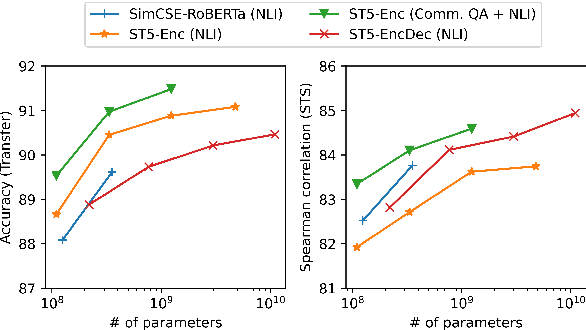
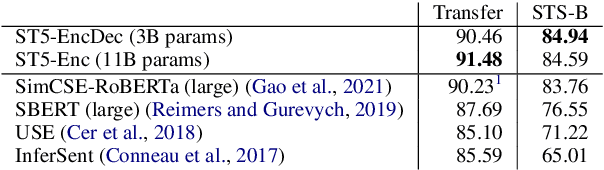
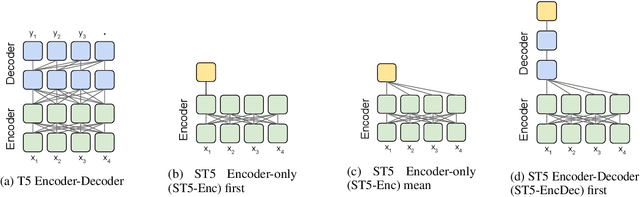
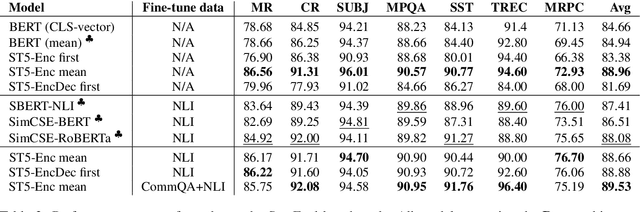
We provide the first exploration of text-to-text transformers (T5) sentence embeddings. Sentence embeddings are broadly useful for language processing tasks. While T5 achieves impressive performance on language tasks cast as sequence-to-sequence mapping problems, it is unclear how to produce sentence embeddings from encoder-decoder models. We investigate three methods for extracting T5 sentence embeddings: two utilize only the T5 encoder and one uses the full T5 encoder-decoder model. Our encoder-only models outperforms BERT-based sentence embeddings on both transfer tasks and semantic textual similarity (STS). Our encoder-decoder method achieves further improvement on STS. Scaling up T5 from millions to billions of parameters is found to produce consistent improvements on downstream tasks. Finally, we introduce a two-stage contrastive learning approach that achieves a new state-of-art on STS using sentence embeddings, outperforming both Sentence BERT and SimCSE.
Towards Universality in Multilingual Text Rewriting
Jul 30, 2021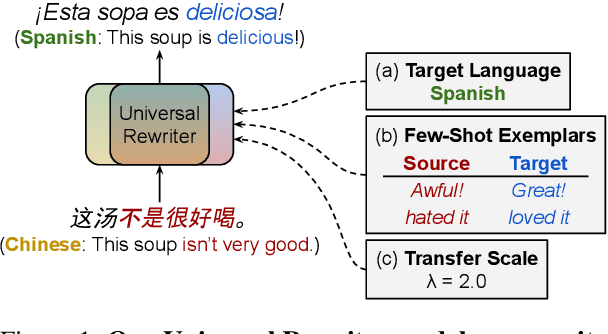
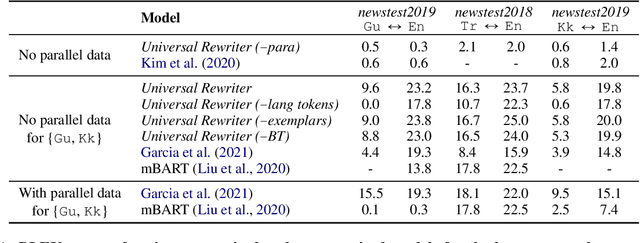
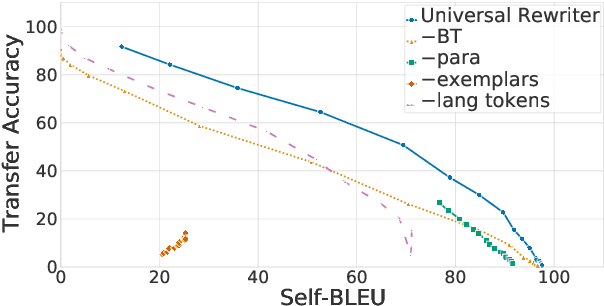

In this work, we take the first steps towards building a universal rewriter: a model capable of rewriting text in any language to exhibit a wide variety of attributes, including styles and languages, while preserving as much of the original semantics as possible. In addition to obtaining state-of-the-art results on unsupervised translation, we also demonstrate the ability to do zero-shot sentiment transfer in non-English languages using only English exemplars for sentiment. We then show that our model is able to modify multiple attributes at once, for example adjusting both language and sentiment jointly. Finally, we show that our model is capable of performing zero-shot formality-sensitive translation.
nmT5 -- Is parallel data still relevant for pre-training massively multilingual language models?
Jun 03, 2021
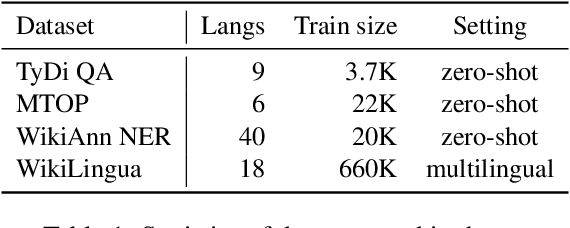
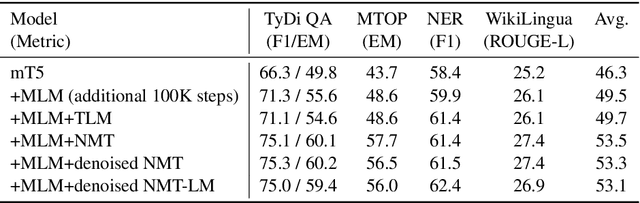
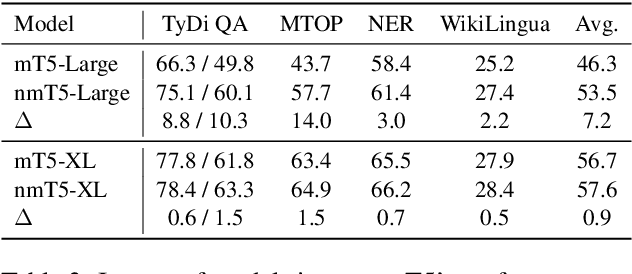
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime.
ByT5: Towards a token-free future with pre-trained byte-to-byte models
May 28, 2021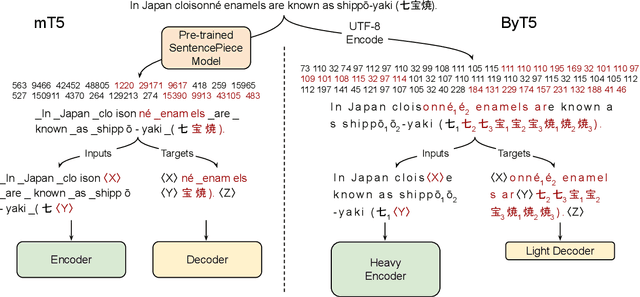
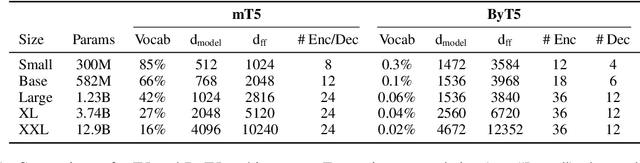
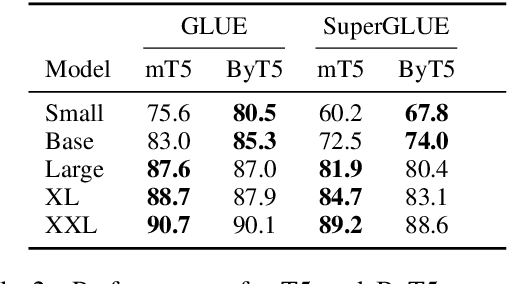
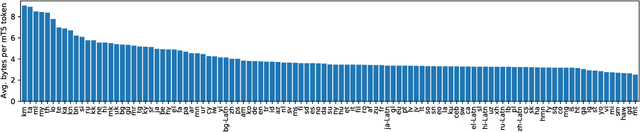
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
The Power of Scale for Parameter-Efficient Prompt Tuning
Apr 18, 2021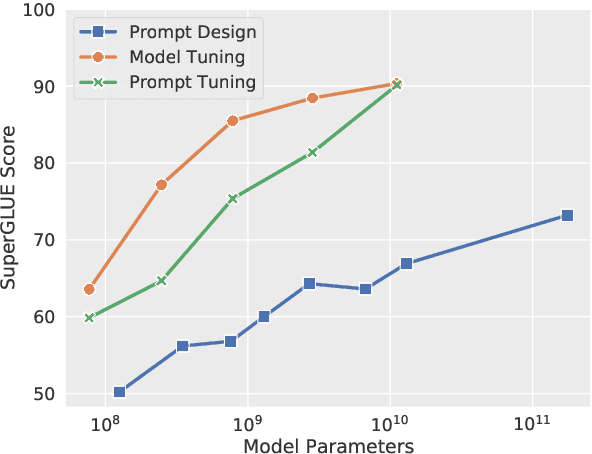
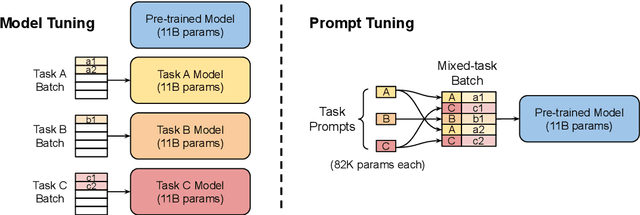
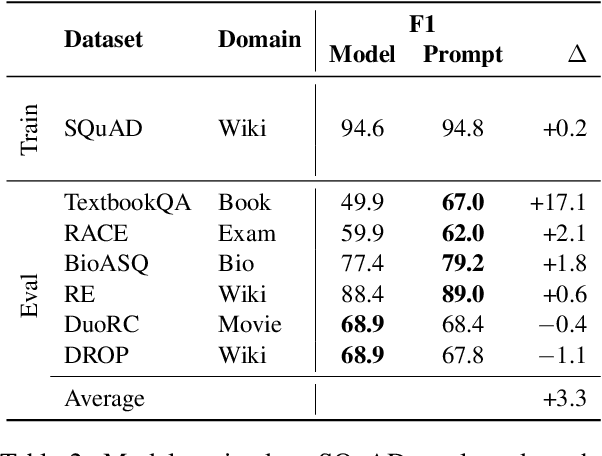
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signal from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3's "few-shot" learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method "closes the gap" and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant in that large models are costly to share and serve, and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed "prefix tuning" of Li and Liang (2021), and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer, as compared to full model tuning.
XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation
Apr 15, 2021
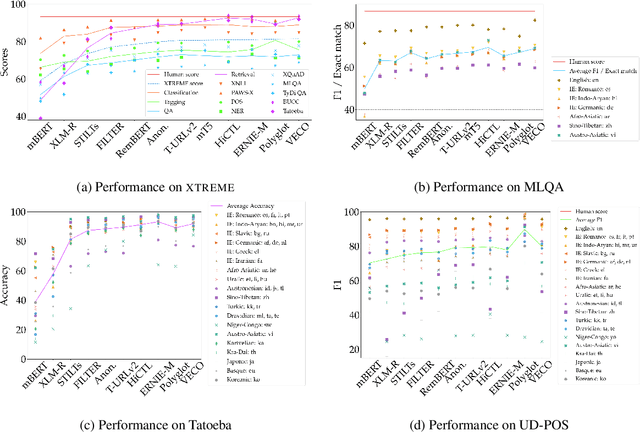
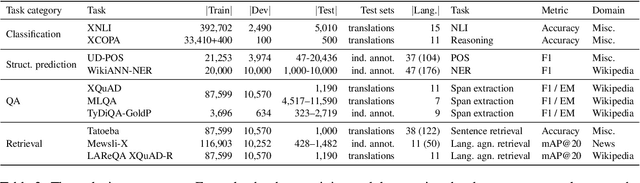
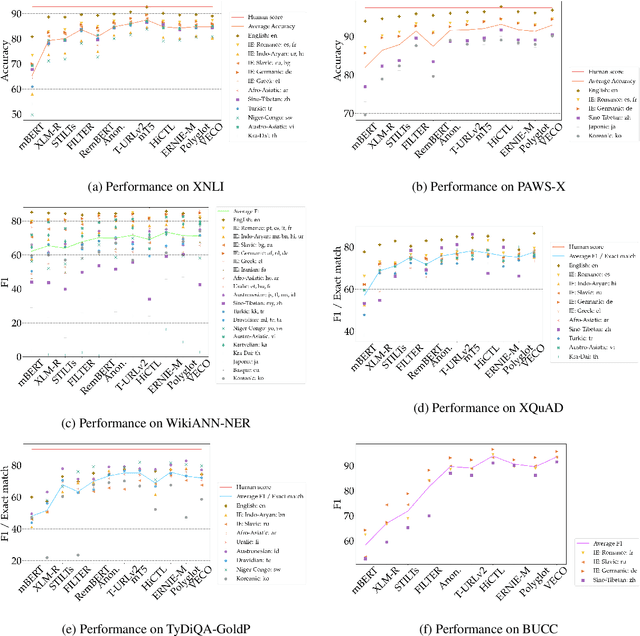
Machine learning has brought striking advances in multilingual natural language processing capabilities over the past year. For example, the latest techniques have improved the state-of-the-art performance on the XTREME multilingual benchmark by more than 13 points. While a sizeable gap to human-level performance remains, improvements have been easier to achieve in some tasks than in others. This paper analyzes the current state of cross-lingual transfer learning and summarizes some lessons learned. In order to catalyze meaningful progress, we extend XTREME to XTREME-R, which consists of an improved set of ten natural language understanding tasks, including challenging language-agnostic retrieval tasks, and covers 50 typologically diverse languages. In addition, we provide a massively multilingual diagnostic suite and fine-grained multi-dataset evaluation capabilities through an interactive public leaderboard to gain a better understanding of such models.