 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Backward Compatible Embeddings
Jun 07, 2022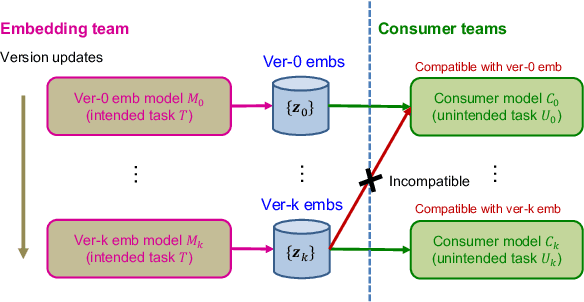
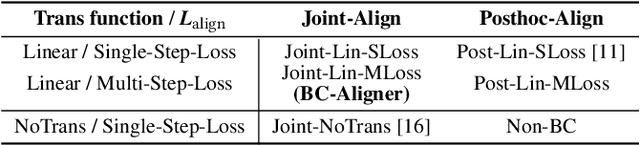
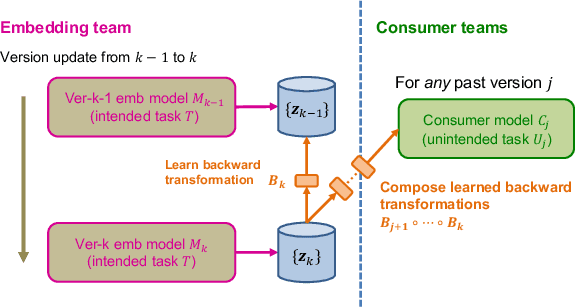

Embeddings, low-dimensional vector representation of objects, are fundamental in building modern machine learning systems. In industrial settings, there is usually an embedding team that trains an embedding model to solve intended tasks (e.g., product recommendation). The produced embeddings are then widely consumed by consumer teams to solve their unintended tasks (e.g., fraud detection). However, as the embedding model gets updated and retrained to improve performance on the intended task, the newly-generated embeddings are no longer compatible with the existing consumer models. This means that historical versions of the embeddings can never be retired or all consumer teams have to retrain their models to make them compatible with the latest version of the embeddings, both of which are extremely costly in practice. Here we study the problem of embedding version updates and their backward compatibility. We formalize the problem where the goal is for the embedding team to keep updating the embedding version, while the consumer teams do not have to retrain their models. We develop a solution based on learning backward compatible embeddings, which allows the embedding model version to be updated frequently, while also allowing the latest version of the embedding to be quickly transformed into any backward compatible historical version of it, so that consumer teams do not have to retrain their models. Under our framework, we explore six methods and systematically evaluate them on a real-world recommender system application. We show that the best method, which we call BC-Aligner, maintains backward compatibility with existing unintended tasks even after multiple model version updates. Simultaneously, BC-Aligner achieves the intended task performance similar to the embedding model that is solely optimized for the intended task.
Task-Agnostic Graph Explanations
Feb 16, 2022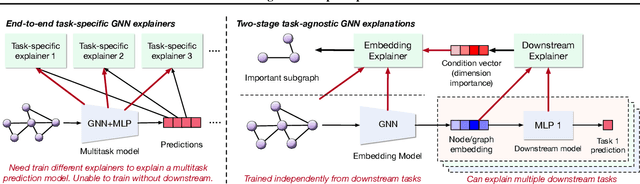

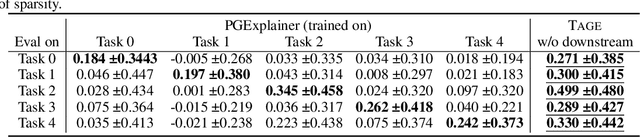
Graph Neural Networks (GNNs) have emerged as powerful tools to encode graph structured data. Due to their broad applications, there is an increasing need to develop tools to explain how GNNs make decisions given graph structured data. Existing learning-based GNN explanation approaches are task-specific in training and hence suffer from crucial drawbacks. Specifically, they are incapable of producing explanations for a multitask prediction model with a single explainer. They are also unable to provide explanations in cases where the GNN is trained in a self-supervised manner, and the resulting representations are used in future downstream tasks. To address these limitations, we propose a Task-Agnostic GNN Explainer (TAGE) trained under self-supervision with no knowledge of downstream tasks. TAGE enables the explanation of GNN embedding models without downstream tasks and allows efficient explanation of multitask models. Our extensive experiments show that TAGE can significantly speed up the explanation efficiency by using the same model to explain predictions for multiple downstream tasks while achieving explanation quality as good as or even better than current state-of-the-art GNN explanation approaches.
Cold Brew: Distilling Graph Node Representations with Incomplete or Missing Neighborhoods
Nov 10, 2021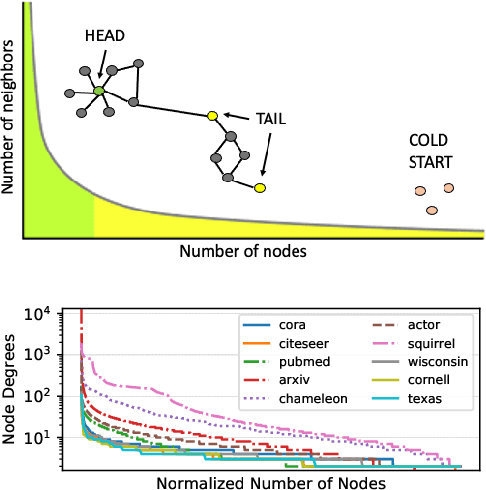
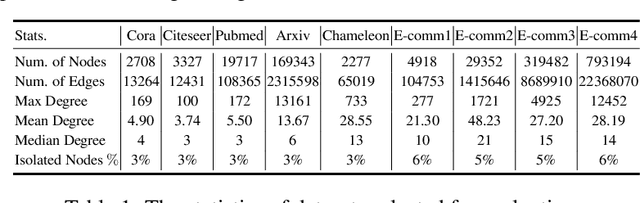
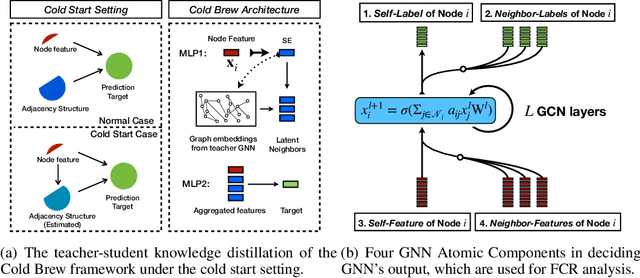
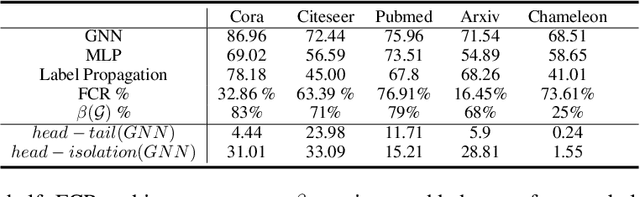
Graph Neural Networks (GNNs) have achieved state of the art performance in node classification, regression, and recommendation tasks. GNNs work well when high-quality and rich connectivity structure is available. However, this requirement is not satisfied in many real world graphs where the node degrees have power-law distributions as many nodes have either fewer or noisy connections. The extreme case of this situation is a node may have no neighbors at all, called Strict Cold Start (SCS) scenario. This forces the prediction models to rely completely on the node's input features. We propose Cold Brew to address the SCS and noisy neighbor setting compared to pointwise and other graph-based models via a distillation approach. We introduce feature-contribution ratio (FCR), a metric to study the viability of using inductive GNNs to solve the SCS problem and to select the best architecture for SCS generalization. We experimentally show FCR disentangles the contributions of various components of graph datasets and demonstrate the superior performance of Cold Brew on several public benchmarks and proprietary e-commerce datasets. The source code for our approach is available at: https://github.com/amazon-research/gnn-tail-generalization.
Probabilistic Entity Representation Model for Reasoning over Knowledge Graphs
Oct 30, 2021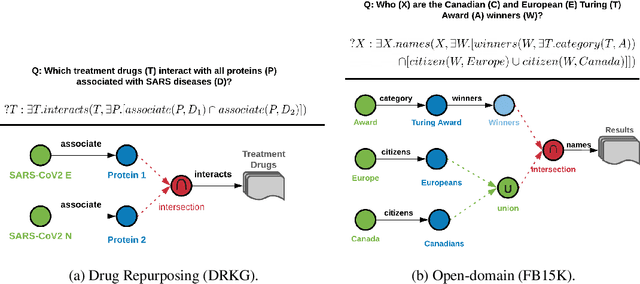
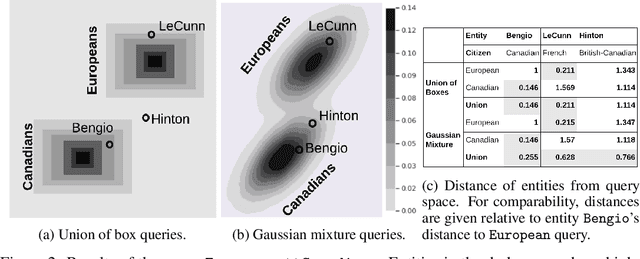
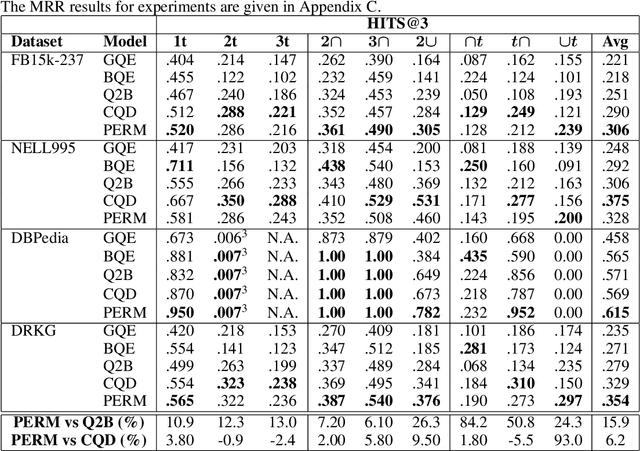
Logical reasoning over Knowledge Graphs (KGs) is a fundamental technique that can provide efficient querying mechanism over large and incomplete databases. Current approaches employ spatial geometries such as boxes to learn query representations that encompass the answer entities and model the logical operations of projection and intersection. However, their geometry is restrictive and leads to non-smooth strict boundaries, which further results in ambiguous answer entities. Furthermore, previous works propose transformation tricks to handle unions which results in non-closure and, thus, cannot be chained in a stream. In this paper, we propose a Probabilistic Entity Representation Model (PERM) to encode entities as a Multivariate Gaussian density with mean and covariance parameters to capture its semantic position and smooth decision boundary, respectively. Additionally, we also define the closed logical operations of projection, intersection, and union that can be aggregated using an end-to-end objective function. On the logical query reasoning problem, we demonstrate that the proposed PERM significantly outperforms the state-of-the-art methods on various public benchmark KG datasets on standard evaluation metrics. We also evaluate PERM's competence on a COVID-19 drug-repurposing case study and show that our proposed work is able to recommend drugs with substantially better F1 than current methods. Finally, we demonstrate the working of our PERM's query answering process through a low-dimensional visualization of the Gaussian representations.
Cluster-and-Conquer: A Framework For Time-Series Forecasting
Oct 26, 2021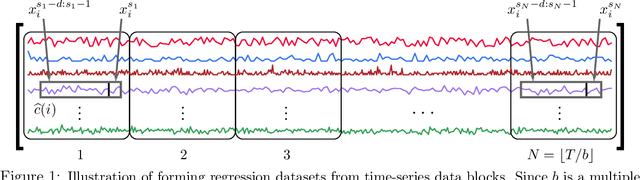
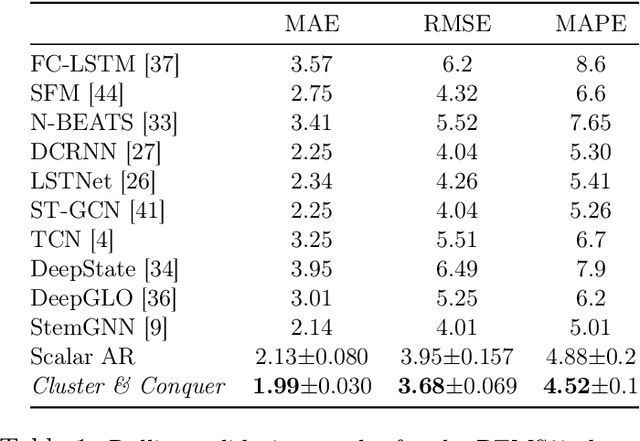
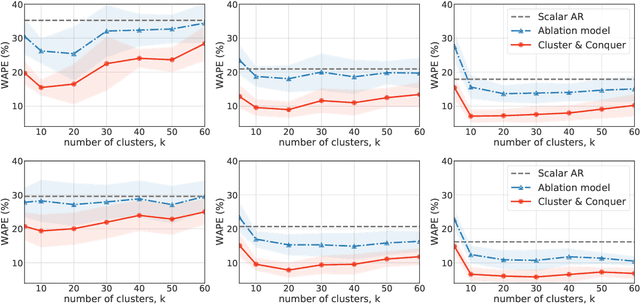
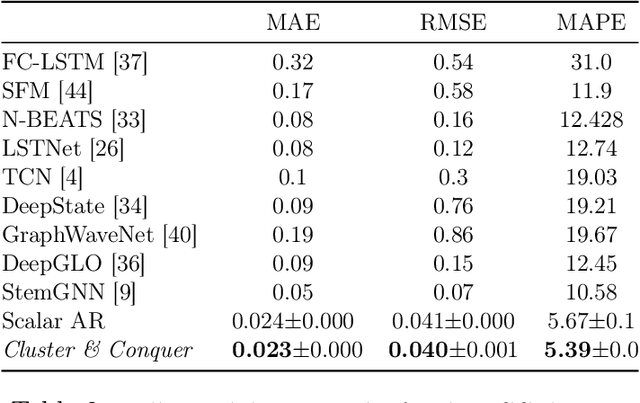
We propose a three-stage framework for forecasting high-dimensional time-series data. Our method first estimates parameters for each univariate time series. Next, we use these parameters to cluster the time series. These clusters can be viewed as multivariate time series, for which we then compute parameters. The forecasted values of a single time series can depend on the history of other time series in the same cluster, accounting for intra-cluster similarity while minimizing potential noise in predictions by ignoring inter-cluster effects. Our framework -- which we refer to as "cluster-and-conquer" -- is highly general, allowing for any time-series forecasting and clustering method to be used in each step. It is computationally efficient and embarrassingly parallel. We motivate our framework with a theoretical analysis in an idealized mixed linear regression setting, where we provide guarantees on the quality of the estimates. We accompany these guarantees with experimental results that demonstrate the advantages of our framework: when instantiated with simple linear autoregressive models, we are able to achieve state-of-the-art results on several benchmark datasets, sometimes outperforming deep-learning-based approaches.
Scalable Feature Selection for (Multitask) Gradient Boosted Trees
Sep 05, 2021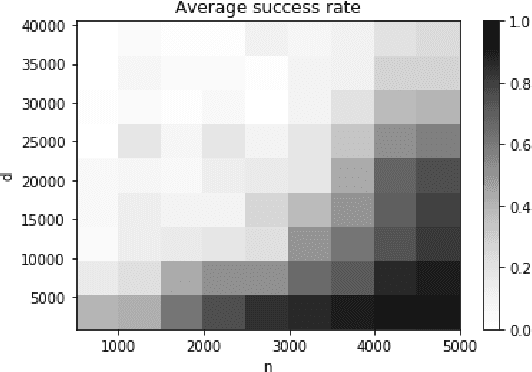
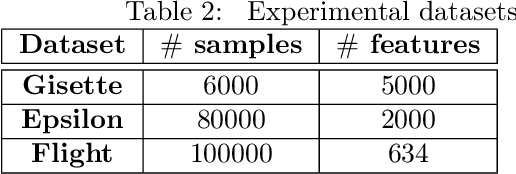
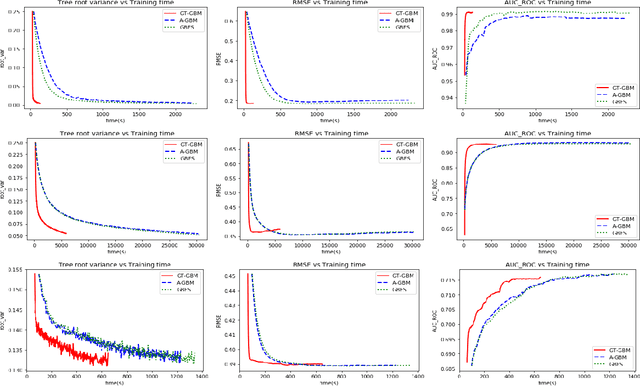
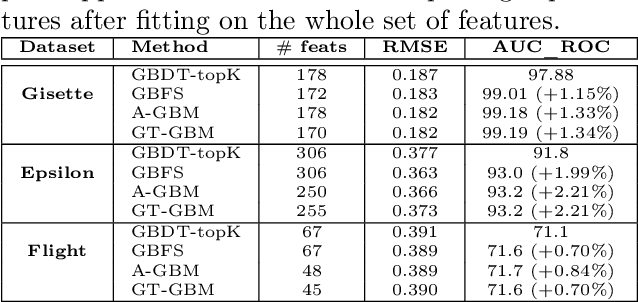
Gradient Boosted Decision Trees (GBDTs) are widely used for building ranking and relevance models in search and recommendation. Considerations such as latency and interpretability dictate the use of as few features as possible to train these models. Feature selection in GBDT models typically involves heuristically ranking the features by importance and selecting the top few, or by performing a full backward feature elimination routine. On-the-fly feature selection methods proposed previously scale suboptimally with the number of features, which can be daunting in high dimensional settings. We develop a scalable forward feature selection variant for GBDT, via a novel group testing procedure that works well in high dimensions, and enjoys favorable theoretical performance and computational guarantees. We show via extensive experiments on both public and proprietary datasets that the proposed method offers significant speedups in training time, while being as competitive as existing GBDT methods in terms of model performance metrics. We also extend the method to the multitask setting, allowing the practitioner to select common features across tasks, as well as selecting task-specific features.
* Correct a mistake in the proof of Lemma B1 in http://proceedings.mlr.press/v108/han20a.html
Pure Exploration in Multi-armed Bandits with Graph Side Information
Aug 02, 2021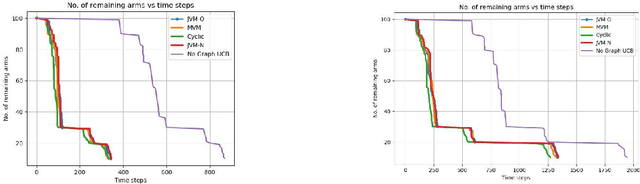
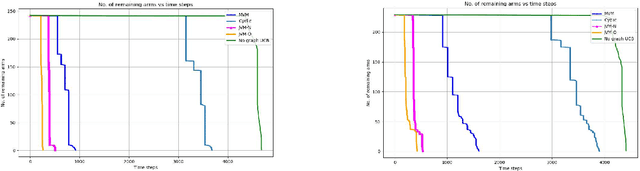
We study pure exploration in multi-armed bandits with graph side-information. In particular, we consider the best arm (and near-best arm) identification problem in the fixed confidence setting under the assumption that the arm rewards are smooth with respect to a given arbitrary graph. This captures a range of real world pure-exploration scenarios where one often has information about the similarity of the options or actions under consideration. We propose a novel algorithm GRUB (GRaph based UcB) for this problem and provide a theoretical characterization of its performance that elicits the benefit of the graph-side information. We complement our theory with experimental results that show that capitalizing on available graph side information yields significant improvements over pure exploration methods that are unable to use this information.
Self-Supervised Hyperboloid Representations from Logical Queries over Knowledge Graphs
Dec 23, 2020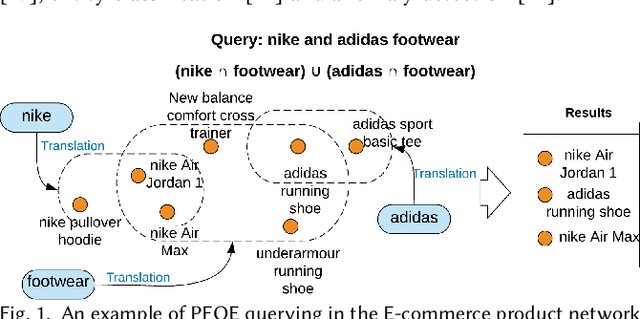
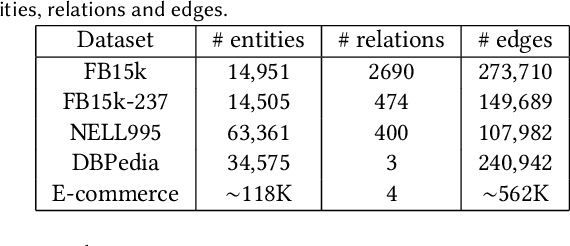
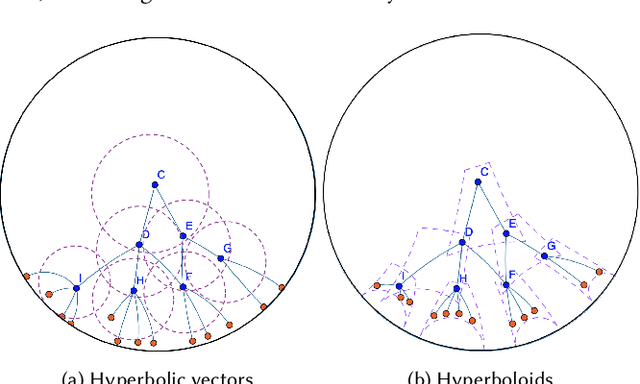
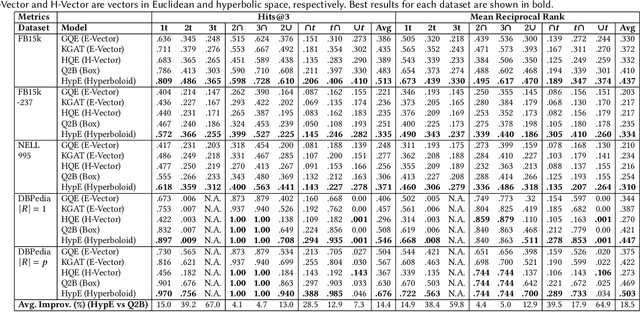
Knowledge Graphs (KGs) are ubiquitous structures for information storagein several real-world applications such as web search, e-commerce, social networks, and biology. Querying KGs remains a foundational and challenging problem due to their size and complexity. Promising approaches to tackle this problem include embedding the KG units (e.g., entities and relations) in a Euclidean space such that the query embedding contains the information relevant to its results. These approaches, however, fail to capture the hierarchical nature and semantic information of the entities present in the graph. Additionally, most of these approaches only utilize multi-hop queries (that can be modeled by simple translation operations) to learn embeddings and ignore more complex operations such as intersection and union of simpler queries. To tackle such complex operations, in this paper, we formulate KG representation learning as a self-supervised logical query reasoning problem that utilizes translation, intersection and union queries over KGs. We propose Hyperboloid Embeddings (HypE), a novel self-supervised dynamic reasoning framework, that utilizes positive first-order existential queries on a KG to learn representations of its entities and relations as hyperboloids in a Poincar\'e ball. HypE models the positive first-order queries as geometrical translation, intersection, and union. For the problem of KG reasoning in real-world datasets, the proposed HypE model significantly outperforms the state-of-the art results. We also apply HypE to an anomaly detection task on a popular e-commerce website product taxonomy as well as hierarchically organized web articles and demonstrate significant performance improvements compared to existing baseline methods. Finally, we also visualize the learned HypE embeddings in a Poincar\'e ball to clearly interpret and comprehend the representation space.
Learning Robust Models for e-Commerce Product Search
May 07, 2020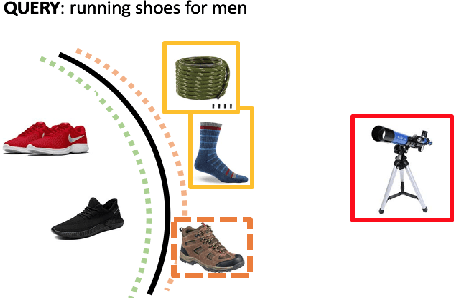
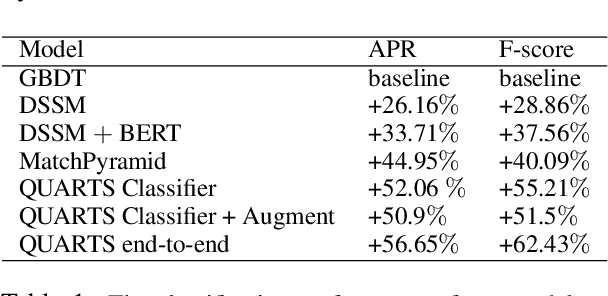
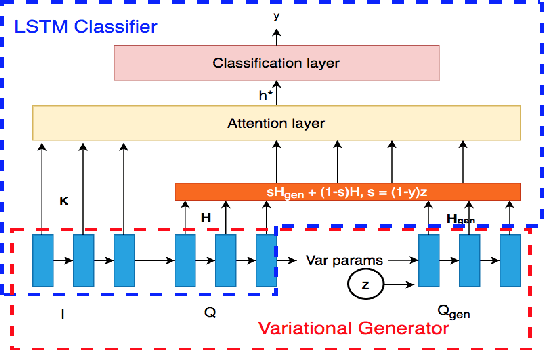

Showing items that do not match search query intent degrades customer experience in e-commerce. These mismatches result from counterfactual biases of the ranking algorithms toward noisy behavioral signals such as clicks and purchases in the search logs. Mitigating the problem requires a large labeled dataset, which is expensive and time-consuming to obtain. In this paper, we develop a deep, end-to-end model that learns to effectively classify mismatches and to generate hard mismatched examples to improve the classifier. We train the model end-to-end by introducing a latent variable into the cross-entropy loss that alternates between using the real and generated samples. This not only makes the classifier more robust but also boosts the overall ranking performance. Our model achieves a relative gain compared to baselines by over 26% in F-score, and over 17% in Area Under PR curve. On live search traffic, our model gains significant improvement in multiple countries.
Graph DNA: Deep Neighborhood Aware Graph Encoding for Collaborative Filtering
May 29, 2019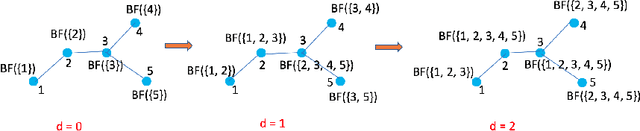
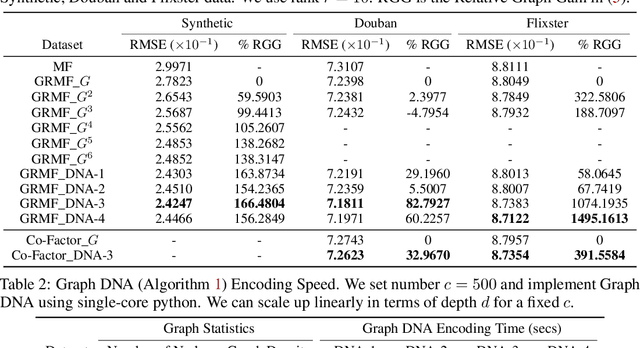
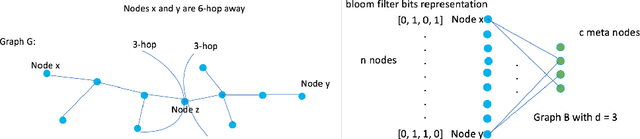

In this paper, we consider recommender systems with side information in the form of graphs. Existing collaborative filtering algorithms mainly utilize only immediate neighborhood information and have a hard time taking advantage of deeper neighborhoods beyond 1-2 hops. The main caveat of exploiting deeper graph information is the rapidly growing time and space complexity when incorporating information from these neighborhoods. In this paper, we propose using Graph DNA, a novel Deep Neighborhood Aware graph encoding algorithm, for exploiting deeper neighborhood information. DNA encoding computes approximate deep neighborhood information in linear time using Bloom filters, a space-efficient probabilistic data structure and results in a per-node encoding that is logarithmic in the number of nodes in the graph. It can be used in conjunction with both feature-based and graph-regularization-based collaborative filtering algorithms. Graph DNA has the advantages of being memory and time efficient and providing additional regularization when compared to directly using higher order graph information. We conduct experiments on real-world datasets, showing graph DNA can be easily used with 4 popular collaborative filtering algorithms and consistently leads to a performance boost with little computational and memory overhead.