 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Goal Generation using Dynamical Distance Learning
Nov 07, 2021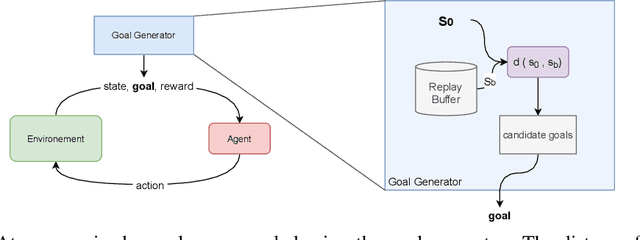
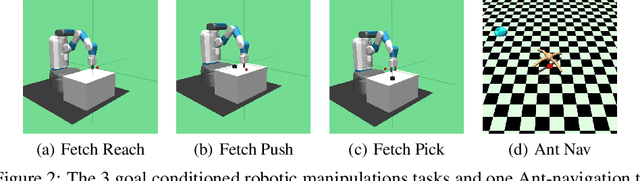
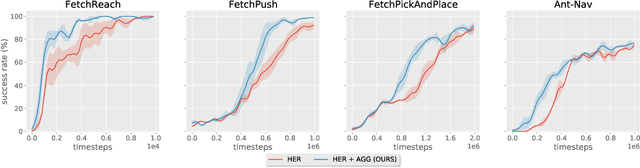

Reinforcement Learning (RL) agents can learn to solve complex sequential decision making tasks by interacting with the environment. However, sample efficiency remains a major challenge. In the field of multi-goal RL, where agents are required to reach multiple goals to solve complex tasks, improving sample efficiency can be especially challenging. On the other hand, humans or other biological agents learn such tasks in a much more strategic way, following a curriculum where tasks are sampled with increasing difficulty level in order to make gradual and efficient learning progress. In this work, we propose a method for automatic goal generation using a dynamical distance function (DDF) in a self-supervised fashion. DDF is a function which predicts the dynamical distance between any two states within a markov decision process (MDP). With this, we generate a curriculum of goals at the appropriate difficulty level to facilitate efficient learning throughout the training process. We evaluate this approach on several goal-conditioned robotic manipulation and navigation tasks, and show improvements in sample efficiency over a baseline method which only uses random goal sampling.
On games and simulators as a platform for development of artificial intelligence for command and control
Oct 21, 2021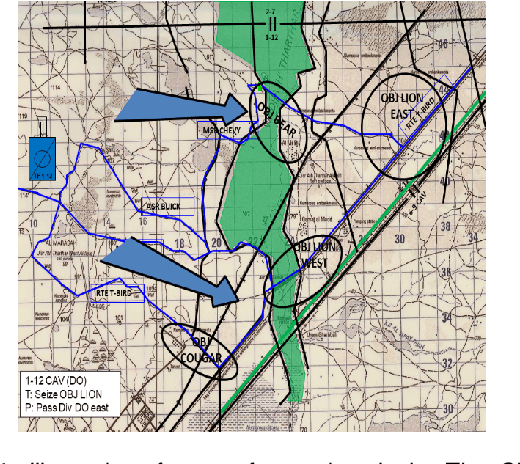

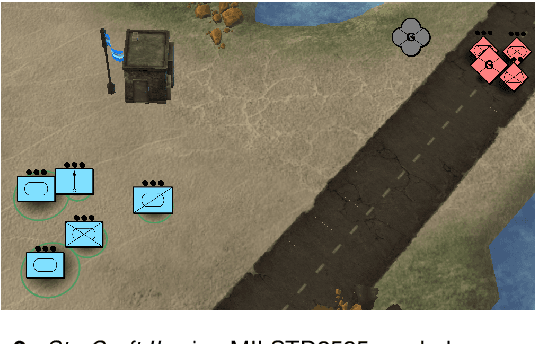
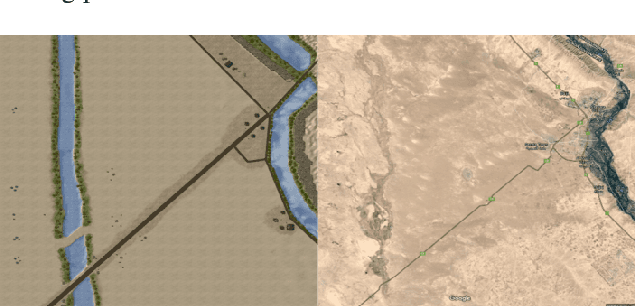
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.
Interactive Hierarchical Guidance using Language
Oct 09, 2021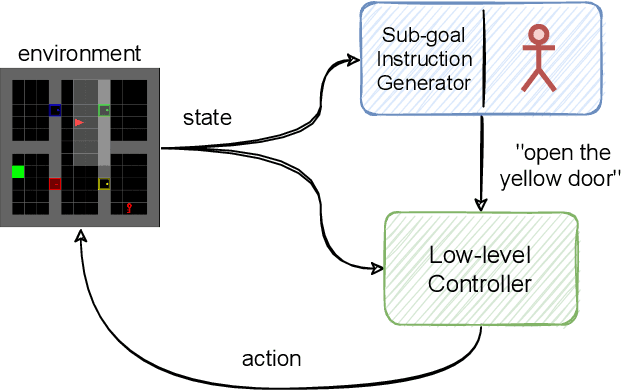
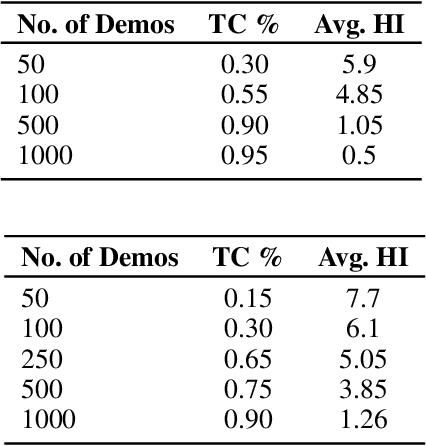


Reinforcement learning has been successful in many tasks ranging from robotic control, games, energy management etc. In complex real world environments with sparse rewards and long task horizons, sample efficiency is still a major challenge. Most complex tasks can be easily decomposed into high-level planning and low level control. Therefore, it is important to enable agents to leverage the hierarchical structure and decompose bigger tasks into multiple smaller sub-tasks. We introduce an approach where we use language to specify sub-tasks and a high-level planner issues language commands to a low level controller. The low-level controller executes the sub-tasks based on the language commands. Our experiments show that this method is able to solve complex long horizon planning tasks with limited human supervision. Using language has added benefit of interpretability and ability for expert humans to take over the high-level planning task and provide language commands if necessary.
Mobile Manipulation Leveraging Multiple Views
Oct 02, 2021
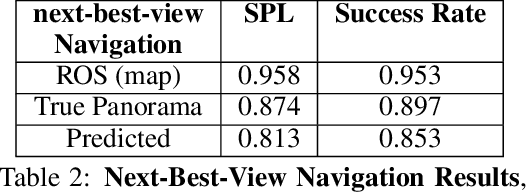

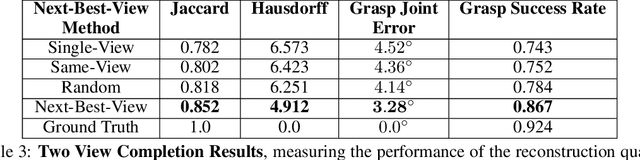
While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.
A Narration-based Reward Shaping Approach using Grounded Natural Language Commands
Oct 31, 2019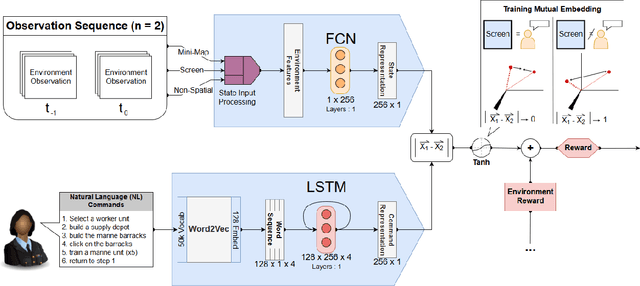
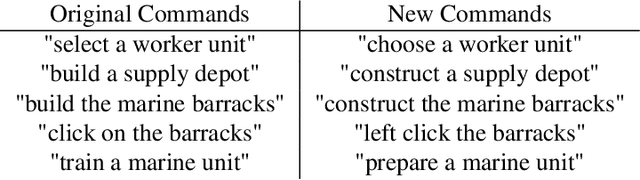
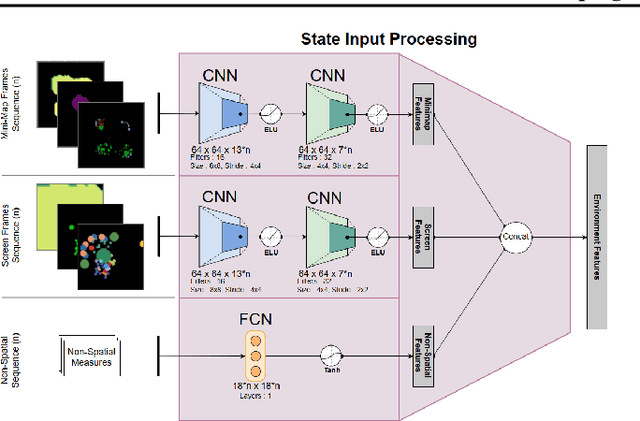
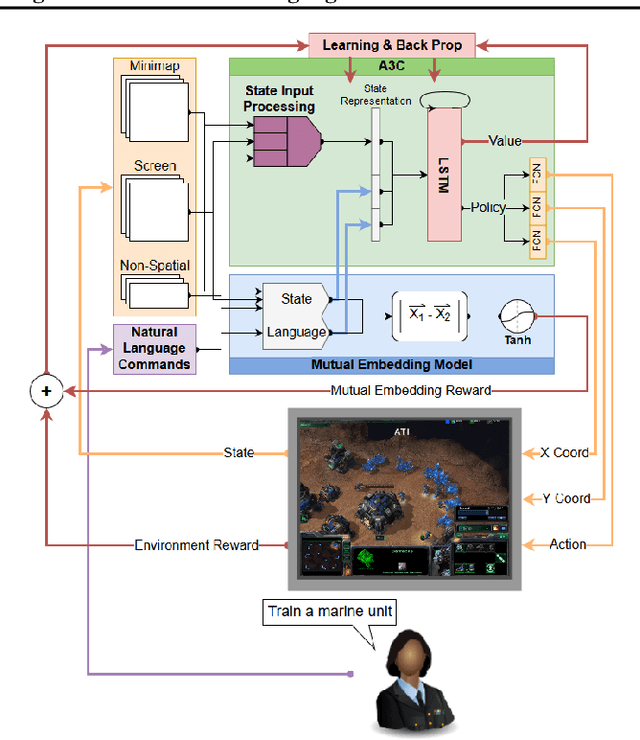
While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of reward sparsity. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we develop a technique that can provide the benefits of reward shaping using natural language commands. Our narration-guided RL agent projects sequences of natural-language commands into the same high-dimensional representation space as corresponding goal states. We show that we can get improved performance with our method compared to traditional reward-shaping approaches. Additionally, we demonstrate the ability of our method to generalize to unseen natural-language commands.
Learning from Observations Using a Single Video Demonstration and Human Feedback
Sep 29, 2019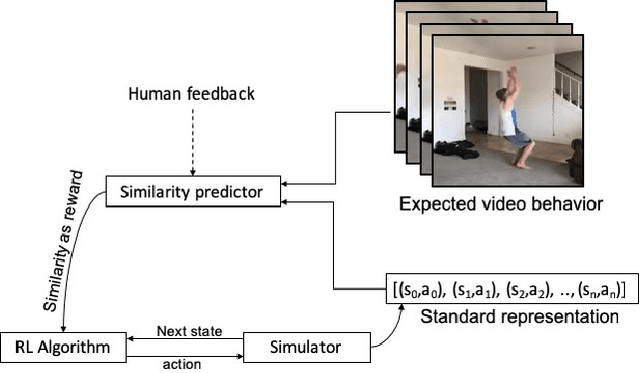
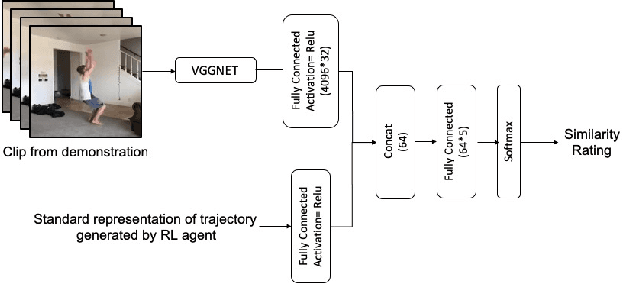
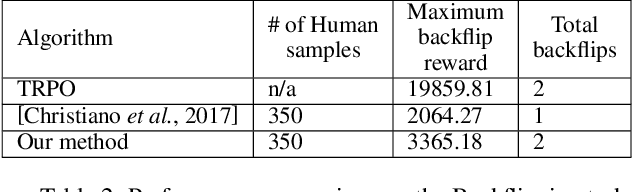
In this paper, we present a method for learning from video demonstrations by using human feedback to construct a mapping between the standard representation of the agent and the visual representation of the demonstration. In this way, we leverage the advantages of both these representations, i.e., we learn the policy using standard state representations, but are able to specify the expected behavior using video demonstration. We train an autonomous agent using a single video demonstration and use human feedback (using numerical similarity rating) to map the standard representation to the visual representation with a neural network. We show the effectiveness of our method by teaching a hopper agent in the MuJoCo to perform a backflip using a single video demonstration generated in MuJoCo as well as from a real-world YouTube video of a person performing a backflip. Additionally, we show that our method can transfer to new tasks, such as hopping, with very little human feedback.
Learning Your Way Without Map or Compass: Panoramic Target Driven Visual Navigation
Sep 20, 2019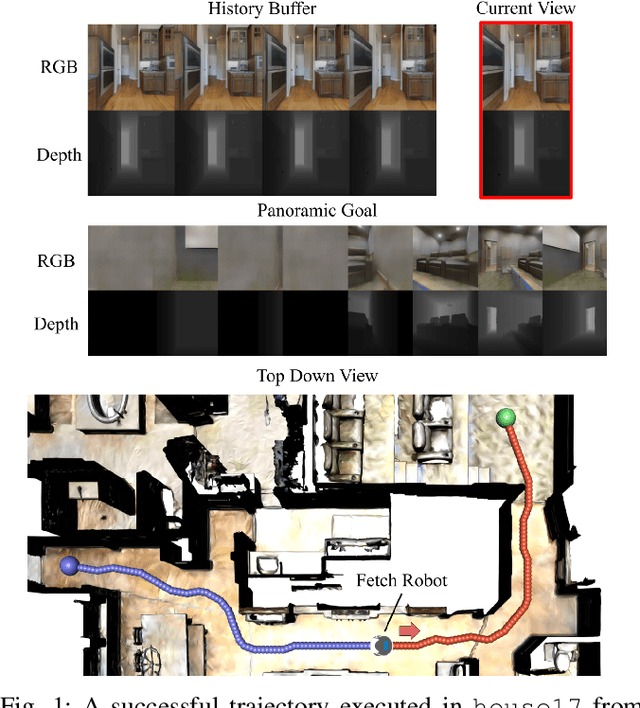
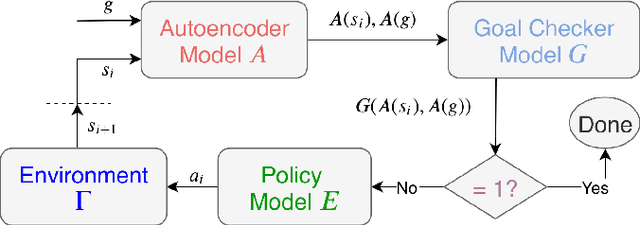

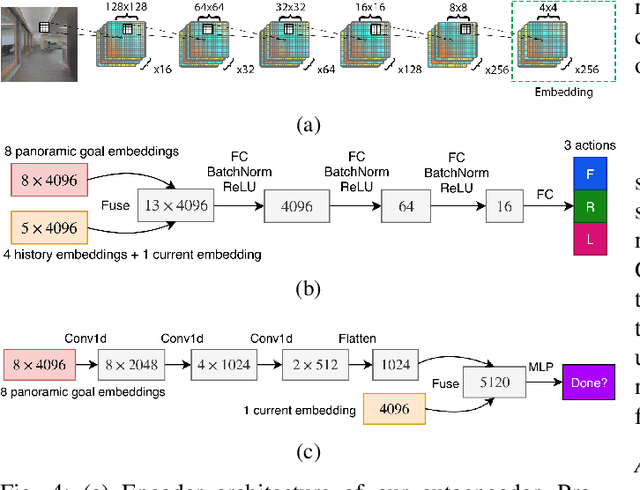
We present a robot navigation system that uses an imitation learning framework to successfully navigate in complex environments. Our framework takes a pre-built 3D scan of a real environment and trains an agent from pre-generated expert trajectories to navigate to any position given a panoramic view of the goal and the current visual input without relying on map, compass, odometry, GPS or relative position of the target at runtime. Our end-to-end trained agent uses RGB and depth (RGBD) information and can handle large environments (up to $1031m^2$) across multiple rooms (up to $40$) and generalizes to unseen targets. We show that when compared to several baselines using deep reinforcement learning and RGBD SLAM, our method (1) requires fewer training examples and less training time, (2) reaches the goal location with higher accuracy, (3) produces better solutions with shorter paths for long-range navigation tasks, and (4) generalizes to unseen environments given an RGBD map of the environment.
Inferring and Learning Multi-Robot Policies by Observing an Expert
Sep 17, 2019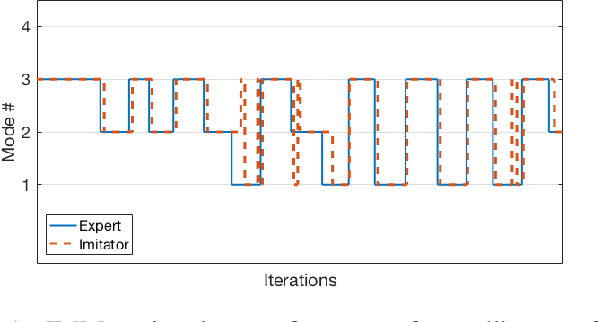
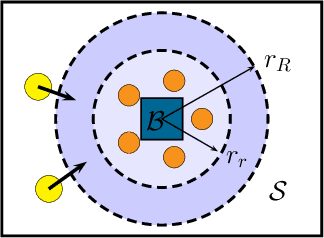
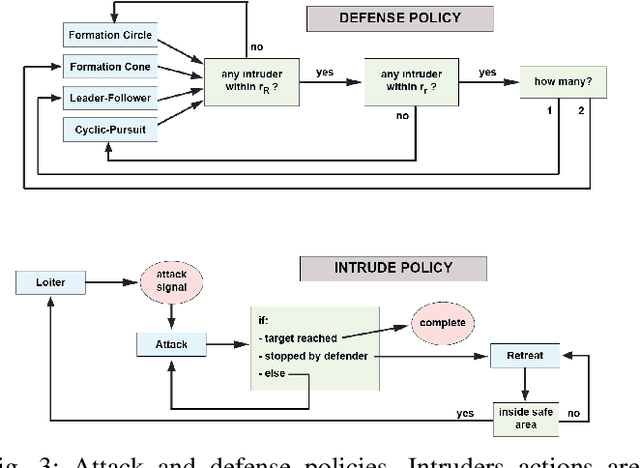
In this paper we present a technique for learning how to solve a multi-robot mission that requires interaction with an external environment by repeatedly observing an expert system executing the same mission. We define the expert system as a team of robots equipped with a library of controllers, each designed to solve a specific task, supervised by an expert policy that appropriately selects controllers based on the states of robots and environment. The objective is for an un-trained team of robots equipped with the same library of controllers, but agnostic to the expert policy, to execute the mission, with performances comparable to those of the expert system. From observations of the expert system, the Interactive Multiple Model technique is used to estimate individual controllers executed by the expert policy. Then, the history of estimated controllers and environmental state is used to learn a policy for the un-trained robots. Considering a perimeter protection scenario on a team of simulated differential-drive robots, we show that the learned policy endows the un-trained team with performances comparable to those of the expert system.
Grounding Natural Language Commands to StarCraft II Game States for Narration-Guided Reinforcement Learning
Apr 24, 2019While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of {\em reward sparsity}. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we investigate to what extent we can contextualize these narrations by grounding them to the goal-specific states. We present a mutual-embedding model using a multi-input deep-neural network that projects a sequence of natural language commands into the same high-dimensional representation space as corresponding goal states. We show that using this model we can learn an embedding space with separable and distinct clusters that accurately maps natural-language commands to corresponding game states . We also discuss how this model can allow for the use of narrations as a robust form of reward shaping to improve RL performance and efficiency.
Improving Safety in Reinforcement Learning Using Model-Based Architectures and Human Intervention
Mar 22, 2019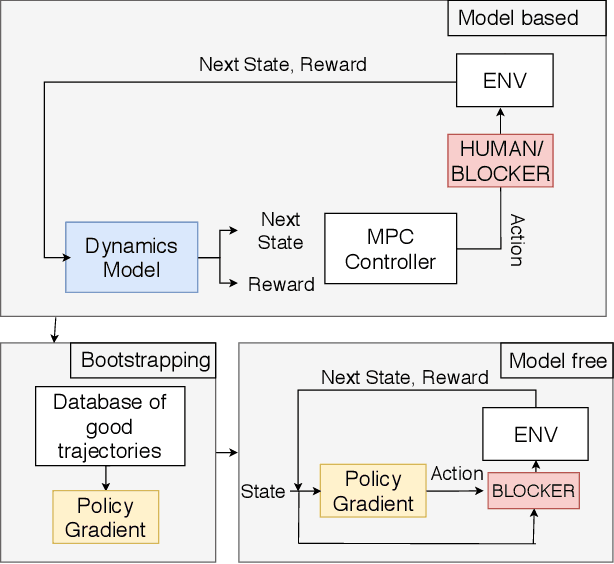
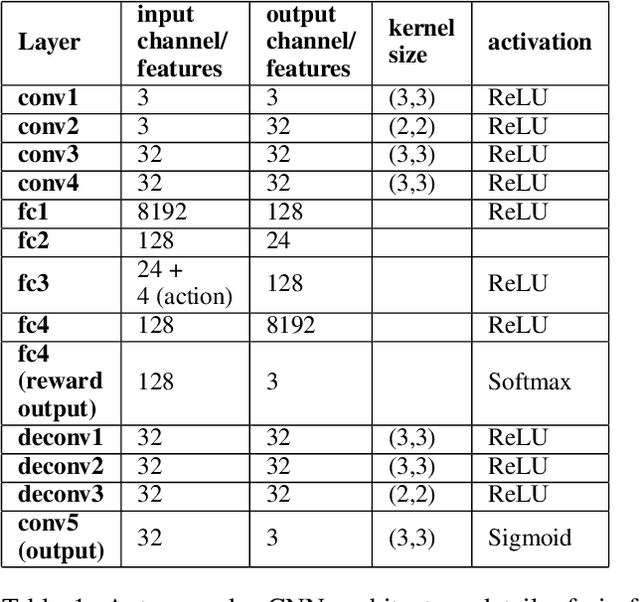
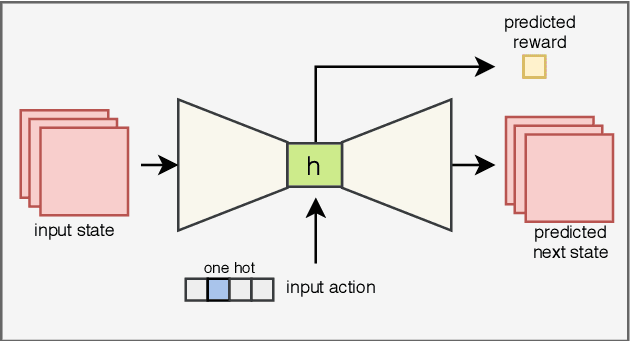
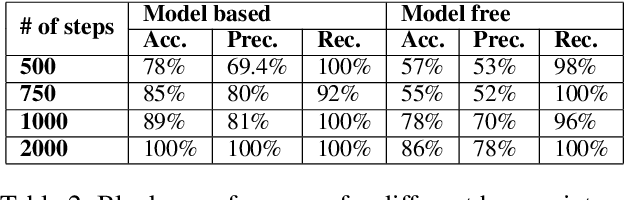
Recent progress in AI and Reinforcement learning has shown great success in solving complex problems with high dimensional state spaces. However, most of these successes have been primarily in simulated environments where failure is of little or no consequence. Most real-world applications, however, require training solutions that are safe to operate as catastrophic failures are inadmissible especially when there is human interaction involved. Currently, Safe RL systems use human oversight during training and exploration in order to make sure the RL agent does not go into a catastrophic state. These methods require a large amount of human labor and it is very difficult to scale up. We present a hybrid method for reducing the human intervention time by combining model-based approaches and training a supervised learner to improve sample efficiency while also ensuring safety. We evaluate these methods on various grid-world environments using both standard and visual representations and show that our approach achieves better performance in terms of sample efficiency, number of catastrophic states reached as well as overall task performance compared to traditional model-free approaches