 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart at what cost? Characterising Mobile Deep Neural Networks in the wild
Sep 28, 2021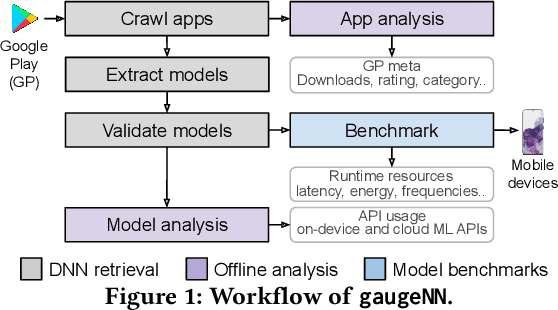
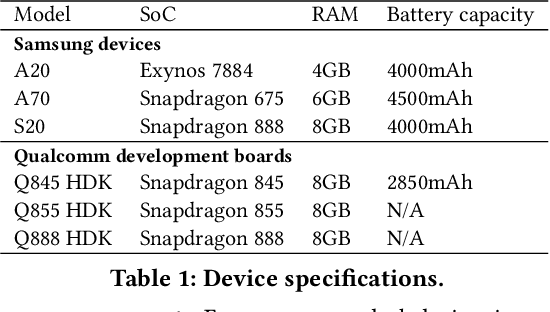
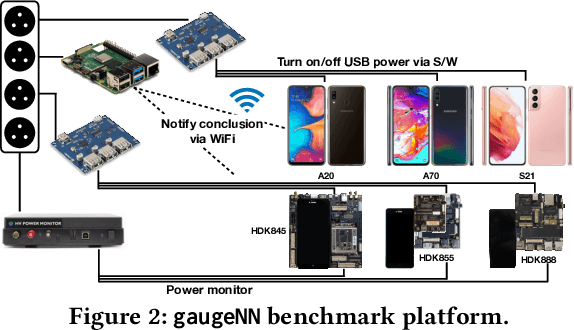
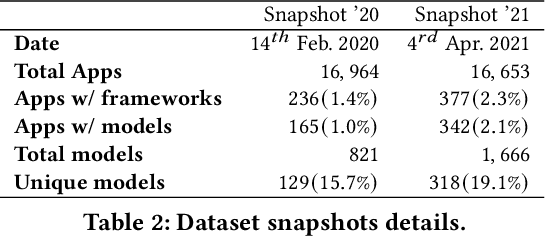
With smartphones' omnipresence in people's pockets, Machine Learning (ML) on mobile is gaining traction as devices become more powerful. With applications ranging from visual filters to voice assistants, intelligence on mobile comes in many forms and facets. However, Deep Neural Network (DNN) inference remains a compute intensive workload, with devices struggling to support intelligence at the cost of responsiveness.On the one hand, there is significant research on reducing model runtime requirements and supporting deployment on embedded devices. On the other hand, the strive to maximise the accuracy of a task is supported by deeper and wider neural networks, making mobile deployment of state-of-the-art DNNs a moving target. In this paper, we perform the first holistic study of DNN usage in the wild in an attempt to track deployed models and match how these run on widely deployed devices. To this end, we analyse over 16k of the most popular apps in the Google Play Store to characterise their DNN usage and performance across devices of different capabilities, both across tiers and generations. Simultaneously, we measure the models' energy footprint, as a core cost dimension of any mobile deployment. To streamline the process, we have developed gaugeNN, a tool that automates the deployment, measurement and analysis of DNNs on devices, with support for different frameworks and platforms. Results from our experience study paint the landscape of deep learning deployments on smartphones and indicate their popularity across app developers. Furthermore, our study shows the gap between bespoke techniques and real-world deployments and the need for optimised deployment of deep learning models in a highly dynamic and heterogeneous ecosystem.
AgreementLearning: An End-to-End Framework for Learning with Multiple Annotators without Groundtruth
Sep 08, 2021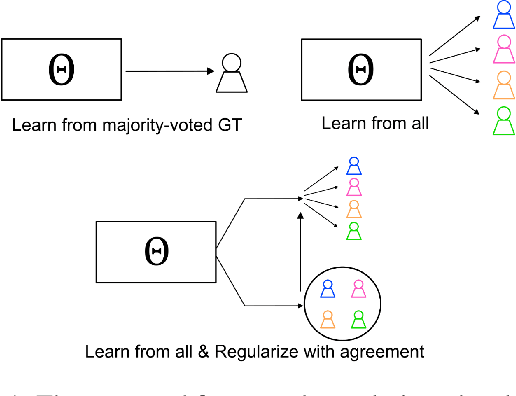
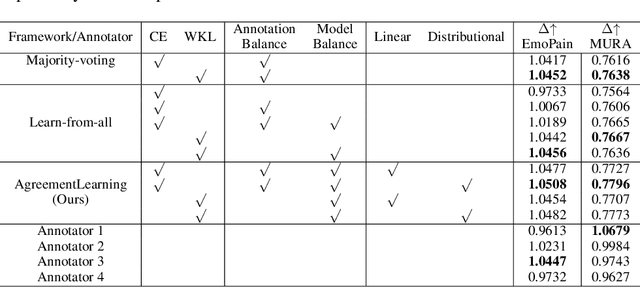
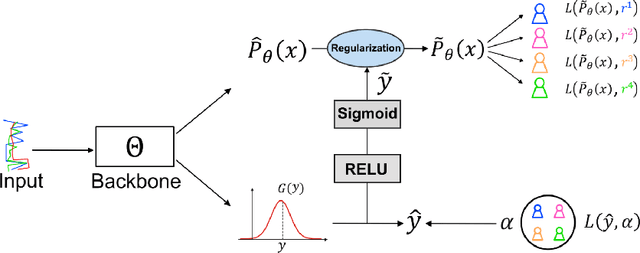
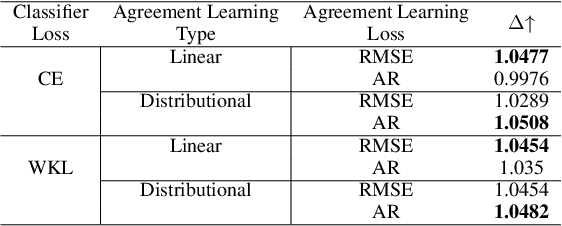
The annotation of domain experts is important for some medical applications where the objective groundtruth is ambiguous to define, e.g., the rehabilitation for some chronic diseases, and the prescreening of some musculoskeletal abnormalities without further medical examinations. However, improper uses of the annotations may hinder developing reliable models. On one hand, forcing the use of a single groundtruth generated from multiple annotations is less informative for the modeling. On the other hand, feeding the model with all the annotations without proper regularization is noisy given existing disagreements. For such issues, we propose a novel agreement learning framework to tackle the challenge of learning from multiple annotators without objective groundtruth. The framework has two streams, with one stream fitting with the multiple annotators and the other stream learning agreement information between the annotators. In particular, the agreement learning stream produces regularization information to the classifier stream, tuning its decision to be better in line with the agreement between the annotators. The proposed method can be easily plugged to existing backbones developed with majority-voted groundtruth or multiple annotations. Thereon, experiments on two medical datasets demonstrate improved agreement levels with annotators.
Temporal Kernel Consistency for Blind Video Super-Resolution
Aug 18, 2021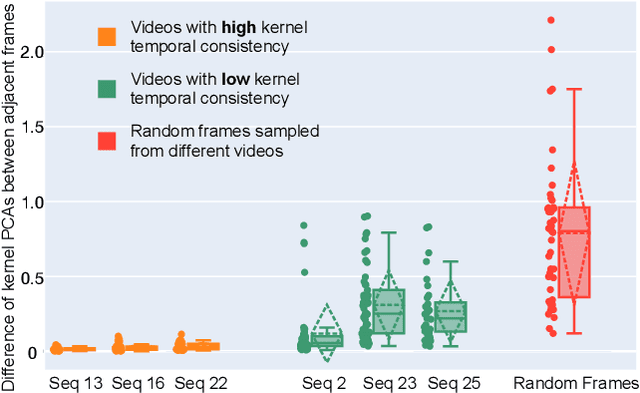
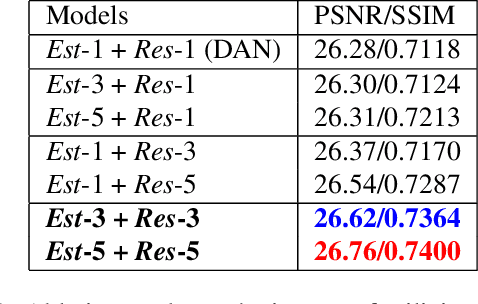

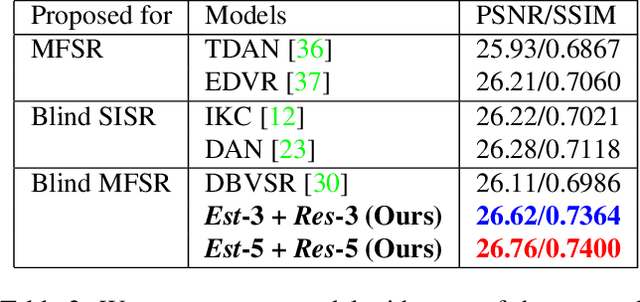
Deep learning-based blind super-resolution (SR) methods have recently achieved unprecedented performance in upscaling frames with unknown degradation. These models are able to accurately estimate the unknown downscaling kernel from a given low-resolution (LR) image in order to leverage the kernel during restoration. Although these approaches have largely been successful, they are predominantly image-based and therefore do not exploit the temporal properties of the kernels across multiple video frames. In this paper, we investigated the temporal properties of the kernels and highlighted its importance in the task of blind video super-resolution. Specifically, we measured the kernel temporal consistency of real-world videos and illustrated how the estimated kernels might change per frame in videos of varying dynamicity of the scene and its objects. With this new insight, we revisited previous popular video SR approaches, and showed that previous assumptions of using a fixed kernel throughout the restoration process can lead to visual artifacts when upscaling real-world videos. In order to counteract this, we tailored existing single-image and video SR techniques to leverage kernel consistency during both kernel estimation and video upscaling processes. Extensive experiments on synthetic and real-world videos show substantial restoration gains quantitatively and qualitatively, achieving the new state-of-the-art in blind video SR and underlining the potential of exploiting kernel temporal consistency.
Zero-Cost Proxies Meet Differentiable Architecture Search
Jun 12, 2021

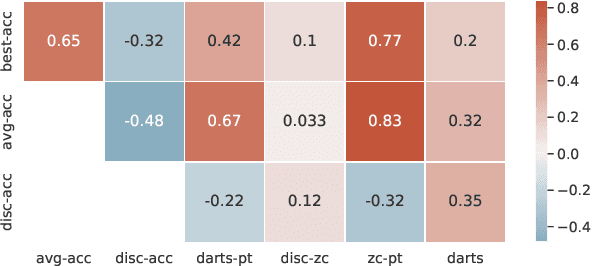

Differentiable neural architecture search (NAS) has attracted significant attention in recent years due to its ability to quickly discover promising architectures of deep neural networks even in very large search spaces. Despite its success, DARTS lacks robustness in certain cases, e.g. it may degenerate to trivial architectures with excessive parametric-free operations such as skip connection or random noise, leading to inferior performance. In particular, operation selection based on the magnitude of architectural parameters was recently proven to be fundamentally wrong showcasing the need to rethink this aspect. On the other hand, zero-cost proxies have been recently studied in the context of sample-based NAS showing promising results -- speeding up the search process drastically in some cases but also failing on some of the large search spaces typical for differentiable NAS. In this work we propose a novel operation selection paradigm in the context of differentiable NAS which utilises zero-cost proxies. Our perturbation-based zero-cost operation selection (Zero-Cost-PT) improves searching time and, in many cases, accuracy compared to the best available differentiable architecture search, regardless of the search space size. Specifically, we are able to find comparable architectures to DARTS-PT on the DARTS CNN search space while being over 40x faster (total searching time 25 minutes on a single GPU).
Adaptive Inference through Early-Exit Networks: Design, Challenges and Directions
Jun 09, 2021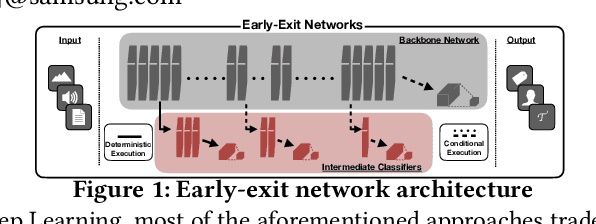
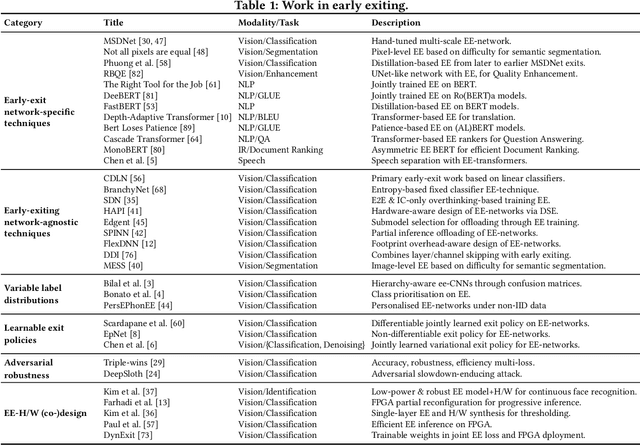
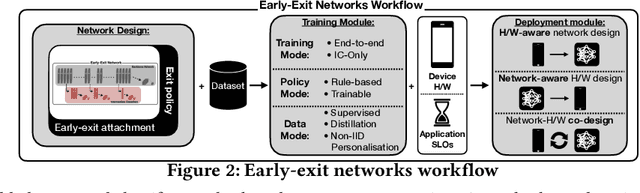
DNNs are becoming less and less over-parametrised due to recent advances in efficient model design, through careful hand-crafted or NAS-based methods. Relying on the fact that not all inputs require the same amount of computation to yield a confident prediction, adaptive inference is gaining attention as a prominent approach for pushing the limits of efficient deployment. Particularly, early-exit networks comprise an emerging direction for tailoring the computation depth of each input sample at runtime, offering complementary performance gains to other efficiency optimisations. In this paper, we decompose the design methodology of early-exit networks to its key components and survey the recent advances in each one of them. We also position early-exiting against other efficient inference solutions and provide our insights on the current challenges and most promising future directions for research in the field.
Deep Neural Network-based Enhancement for Image and Video Streaming Systems: A Survey and Future Directions
Jun 07, 2021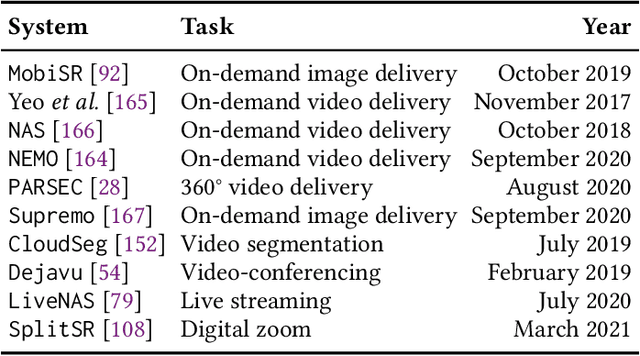
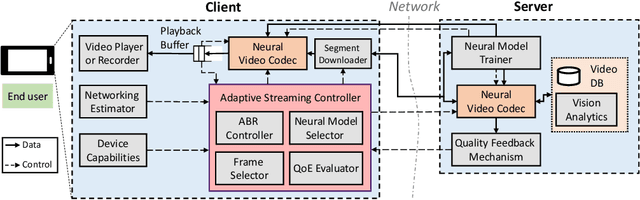
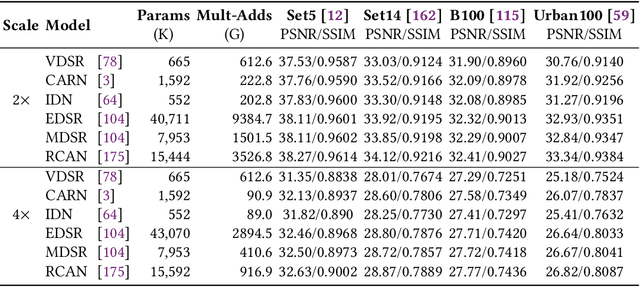
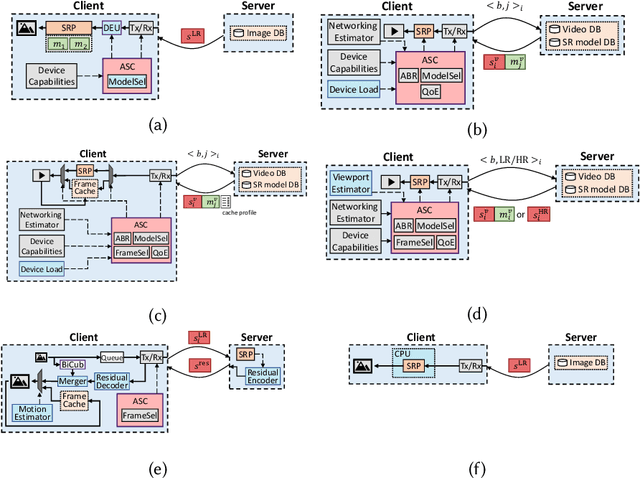
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360{\deg} videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the components and architecture of existing content delivery systems, highlighting their challenges and motivating the use of neural enhancement models as a countermeasure. We then cover the deployment challenges of these models and analyze existing systems and their design decisions in efficiently overcoming these technical challenges. Additionally, we underline the key trends and common approaches across systems that target diverse use-cases. Finally, we present promising future directions based on the latest insights from deep learning research to further boost the quality of experience of content delivery systems.
Multi-Exit Semantic Segmentation Networks
Jun 07, 2021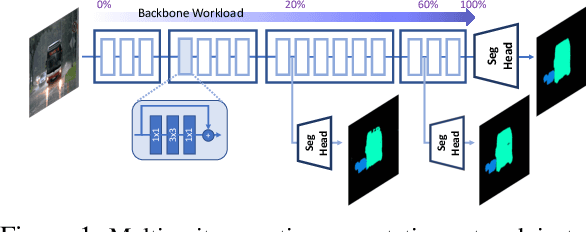
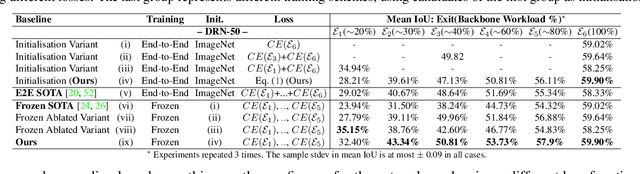
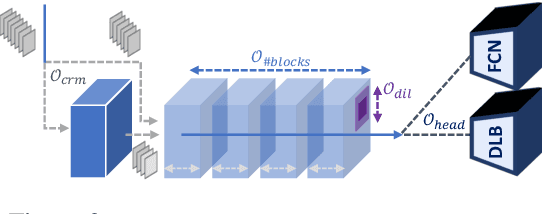
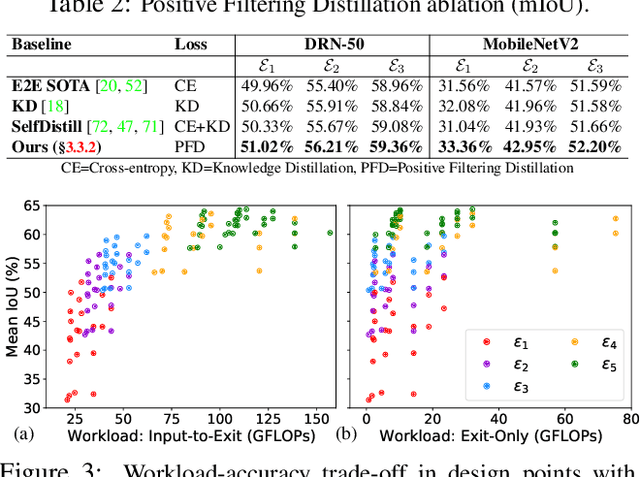
Semantic segmentation arises as the backbone of many vision systems, spanning from self-driving cars and robot navigation to augmented reality and teleconferencing. Frequently operating under stringent latency constraints within a limited resource envelope, optimising for efficient execution becomes important. To this end, we propose a framework for converting state-of-the-art segmentation models to MESS networks; specially trained CNNs that employ parametrised early exits along their depth to save computation during inference on easier samples. Designing and training such networks naively can hurt performance. Thus, we propose a two-staged training process that pushes semantically important features early in the network. We co-optimise the number, placement and architecture of the attached segmentation heads, along with the exit policy, to adapt to the device capabilities and application-specific requirements. Optimising for speed, MESS networks can achieve latency gains of up to 2.83x over state-of-the-art methods with no accuracy degradation. Accordingly, optimising for accuracy, we achieve an improvement of up to 5.33 pp, under the same computational budget.
End-to-End Speech Recognition from Federated Acoustic Models
Apr 29, 2021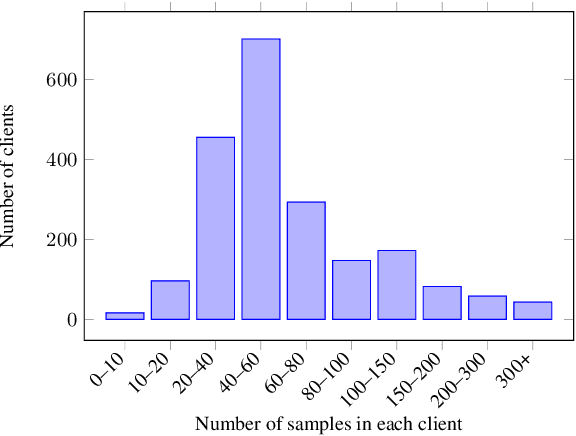

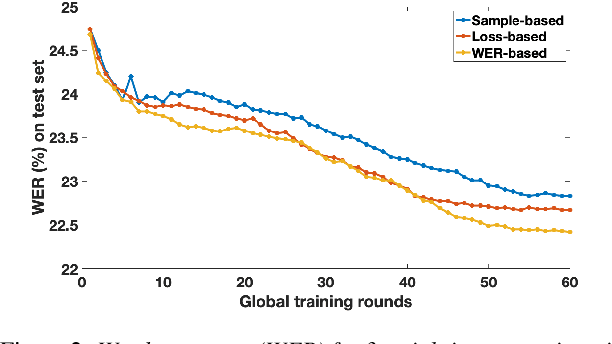
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.
DynO: Dynamic Onloading of Deep Neural Networks from Cloud to Device
Apr 20, 2021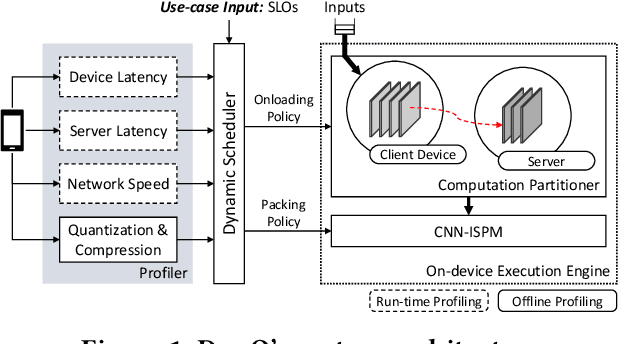

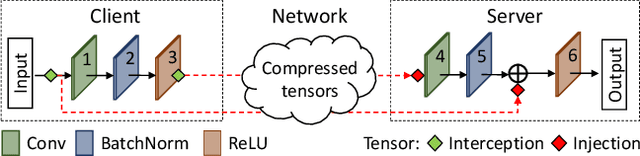
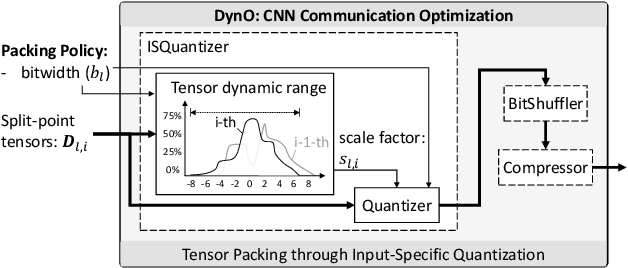
Recently, there has been an explosive growth of mobile and embedded applications using convolutional neural networks(CNNs). To alleviate their excessive computational demands, developers have traditionally resorted to cloud offloading, inducing high infrastructure costs and a strong dependence on networking conditions. On the other end, the emergence of powerful SoCs is gradually enabling on-device execution. Nonetheless, low- and mid-tier platforms still struggle to run state-of-the-art CNNs sufficiently. In this paper, we present DynO, a distributed inference framework that combines the best of both worlds to address several challenges, such as device heterogeneity, varying bandwidth and multi-objective requirements. Key components that enable this are its novel CNN-specific data packing method, which exploits the variability of precision needs in different parts of the CNN when onloading computation, and its novel scheduler that jointly tunes the partition point and transferred data precision at run time to adapt inference to its execution environment. Quantitative evaluation shows that DynO outperforms the current state-of-the-art, improving throughput by over an order of magnitude over device-only execution and up to 7.9x over competing CNN offloading systems, with up to 60x less data transferred.
Adaptive Filters and Aggregator Fusion for Efficient Graph Convolutions
Apr 10, 2021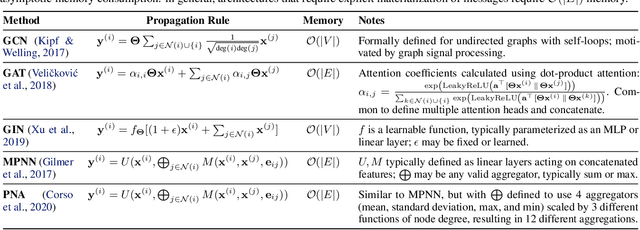
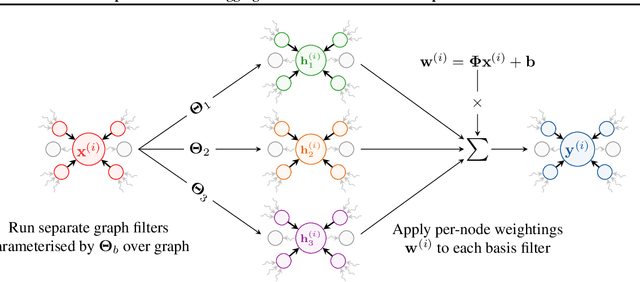
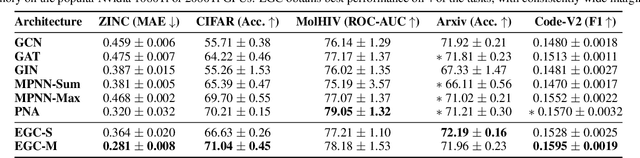
Training and deploying graph neural networks (GNNs) remains difficult due to their high memory consumption and inference latency. In this work we present a new type of GNN architecture that achieves state-of-the-art performance with lower memory consumption and latency, along with characteristics suited to accelerator implementation. Our proposal uses memory proportional to the number of vertices in the graph, in contrast to competing methods which require memory proportional to the number of edges; we find our efficient approach actually achieves higher accuracy than competing approaches across 5 large and varied datasets against strong baselines. We achieve our results by using a novel adaptive filtering approach inspired by signal processing; it can be interpreted as enabling each vertex to have its own weight matrix, and is not related to attention. Following our focus on efficient hardware usage, we propose aggregator fusion, a technique to enable GNNs to significantly boost their representational power, with only a small increase in latency of 19% over standard sparse matrix multiplication. Code and pretrained models can be found at this URL: https://github.com/shyam196/egc.