 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Predefined Experts: Maximizing Data Usage on Vertical Federated Learning
Feb 13, 2026Vertical Federated Learning (VFL) has emerged as a critical paradigm for collaborative model training in privacy-sensitive domains such as finance and healthcare. However, most existing VFL frameworks rely on the idealized assumption of full sample alignment across participants, a premise that rarely holds in real-world scenarios. To bridge this gap, this work introduces Split-MoPE, a novel framework that integrates Split Learning with a specialized Mixture of Predefined Experts (MoPE) architecture. Unlike standard Mixture of Experts (MoE), where routing is learned dynamically, MoPE uses predefined experts to process specific data alignments, effectively maximizing data usage during both training and inference without requiring full sample overlap. By leveraging pretrained encoders for target data domains, Split-MoPE achieves state-of-the-art performance in a single communication round, significantly reducing the communication footprint compared to multi-round end-to-end training. Furthermore, unlike existing proposals that address sample misalignment, this novel architecture provides inherent robustness against malicious or noisy participants and offers per-sample interpretability by quantifying each collaborator's contribution to each prediction. Extensive evaluations on vision (CIFAR-10/100) and tabular (Breast Cancer Wisconsin) datasets demonstrate that Split-MoPE consistently outperforms state-of-the-art systems such as LASER and Vertical SplitNN, particularly in challenging scenarios with high data missingness.
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
May 23, 2024Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
How Much Is Hidden in the NAS Benchmarks? Few-Shot Adaptation of a NAS Predictor
Nov 30, 2023



Neural architecture search has proven to be a powerful approach to designing and refining neural networks, often boosting their performance and efficiency over manually-designed variations, but comes with computational overhead. While there has been a considerable amount of research focused on lowering the cost of NAS for mainstream tasks, such as image classification, a lot of those improvements stem from the fact that those tasks are well-studied in the broader context. Consequently, applicability of NAS to emerging and under-represented domains is still associated with a relatively high cost and/or uncertainty about the achievable gains. To address this issue, we turn our focus towards the recent growth of publicly available NAS benchmarks in an attempt to extract general NAS knowledge, transferable across different tasks and search spaces. We borrow from the rich field of meta-learning for few-shot adaptation and carefully study applicability of those methods to NAS, with a special focus on the relationship between task-level correlation (domain shift) and predictor transferability; which we deem critical for improving NAS on diverse tasks. In our experiments, we use 6 NAS benchmarks in conjunction, spanning in total 16 NAS settings -- our meta-learning approach not only shows superior (or matching) performance in the cross-validation experiments but also successful extrapolation to a new search space and tasks.
Mitigating Memory Wall Effects in CNN Engines with On-the-Fly Weights Generation
Jul 25, 2023



The unprecedented accuracy of convolutional neural networks (CNNs) across a broad range of AI tasks has led to their widespread deployment in mobile and embedded settings. In a pursuit for high-performance and energy-efficient inference, significant research effort has been invested in the design of FPGA-based CNN accelerators. In this context, single computation engines constitute a popular approach to support diverse CNN modes without the overhead of fabric reconfiguration. Nevertheless, this flexibility often comes with significantly degraded performance on memory-bound layers and resource underutilisation due to the suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. This paper presents unzipFPGA, a novel CNN inference system that counteracts the limitations of existing CNN engines. The proposed framework comprises a novel CNN hardware architecture that introduces a weights generator module that enables the on-chip on-the-fly generation of weights, alleviating the negative impact of limited bandwidth on memory-bound layers. We further enhance unzipFPGA with an automated hardware-aware methodology that tailors the weights generation mechanism to the target CNN-device pair, leading to an improved accuracy-performance balance. Finally, we introduce an input selective processing element (PE) design that balances the load between PEs in suboptimally mapped layers. The proposed framework yields hardware designs that achieve an average of 2.57x performance efficiency gain over highly optimised GPU designs for the same power constraints and up to 3.94x higher performance density over a diverse range of state-of-the-art FPGA-based CNN accelerators.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022



Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.
Match to Win: Analysing Sequences Lengths for Efficient Self-supervised Learning in Speech and Audio
Oct 03, 2022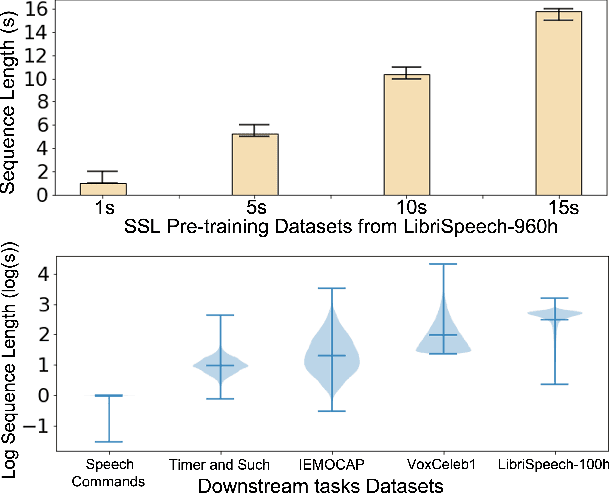

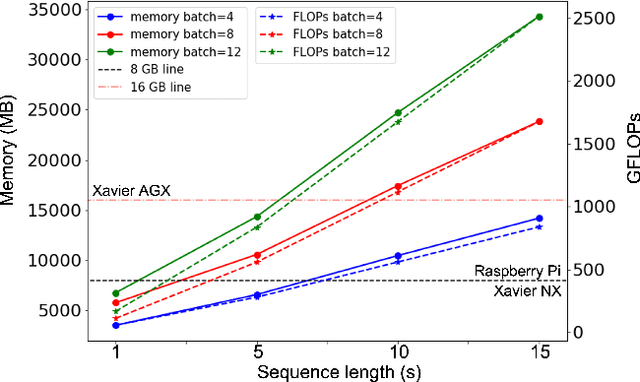
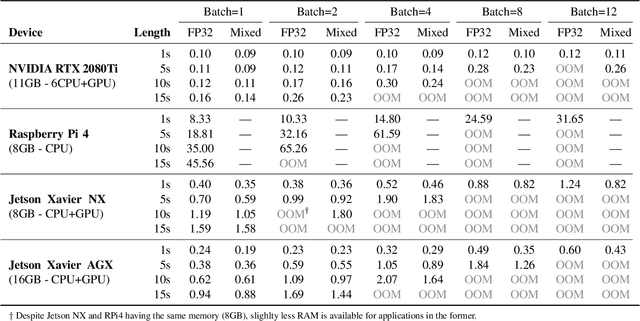
Self-supervised learning (SSL) has proven vital in speech and audio-related applications. The paradigm trains a general model on unlabeled data that can later be used to solve specific downstream tasks. This type of model is costly to train as it requires manipulating long input sequences that can only be handled by powerful centralised servers. Surprisingly, despite many attempts to increase training efficiency through model compression, the effects of truncating input sequence lengths to reduce computation have not been studied. In this paper, we provide the first empirical study of SSL pre-training for different specified sequence lengths and link this to various downstream tasks. We find that training on short sequences can dramatically reduce resource costs while retaining a satisfactory performance for all tasks. This simple one-line change would promote the migration of SSL training from data centres to user-end edge devices for more realistic and personalised applications.
ZeroFL: Efficient On-Device Training for Federated Learning with Local Sparsity
Aug 04, 2022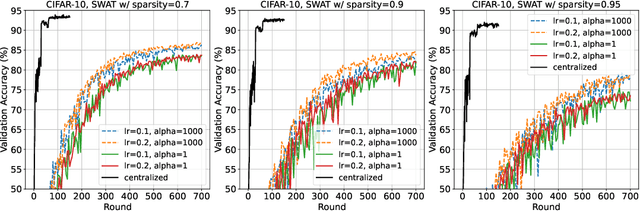
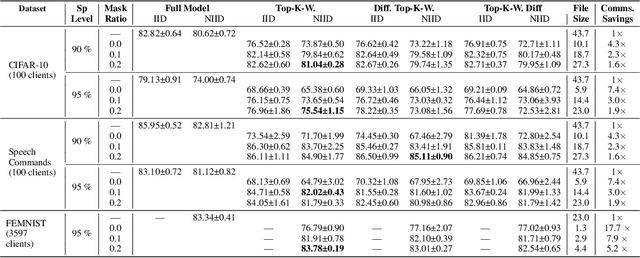
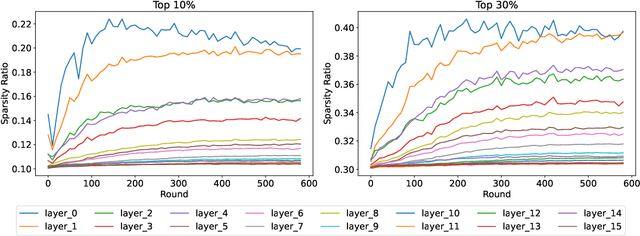
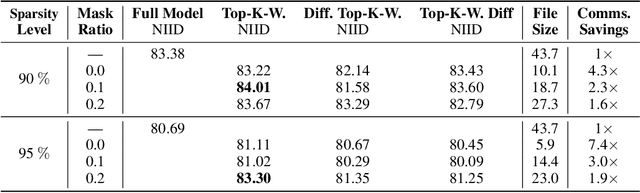
When the available hardware cannot meet the memory and compute requirements to efficiently train high performing machine learning models, a compromise in either the training quality or the model complexity is needed. In Federated Learning (FL), nodes are orders of magnitude more constrained than traditional server-grade hardware and are often battery powered, severely limiting the sophistication of models that can be trained under this paradigm. While most research has focused on designing better aggregation strategies to improve convergence rates and in alleviating the communication costs of FL, fewer efforts have been devoted to accelerating on-device training. Such stage, which repeats hundreds of times (i.e. every round) and can involve thousands of devices, accounts for the majority of the time required to train federated models and, the totality of the energy consumption at the client side. In this work, we present the first study on the unique aspects that arise when introducing sparsity at training time in FL workloads. We then propose ZeroFL, a framework that relies on highly sparse operations to accelerate on-device training. Models trained with ZeroFL and 95% sparsity achieve up to 2.3% higher accuracy compared to competitive baselines obtained from adapting a state-of-the-art sparse training framework to the FL setting.
* Published as a conference paper at ICLR 2022
Protea: Client Profiling within Federated Systems using Flower
Jul 03, 2022
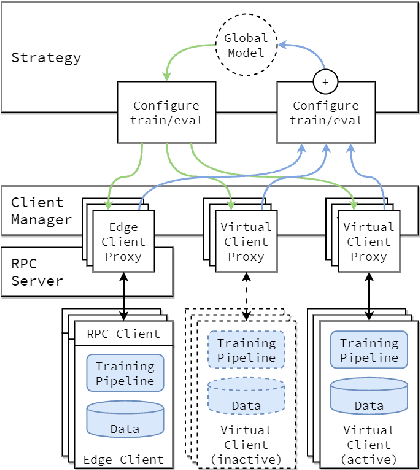
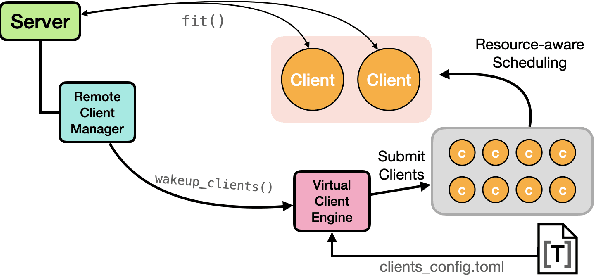
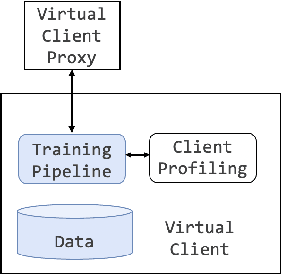
Federated Learning (FL) has emerged as a prospective solution that facilitates the training of a high-performing centralised model without compromising the privacy of users. While successful, research is currently limited by the possibility of establishing a realistic large-scale FL system at the early stages of experimentation. Simulation can help accelerate this process. To facilitate efficient scalable FL simulation of heterogeneous clients, we design and implement Protea, a flexible and lightweight client profiling component within federated systems using the FL framework Flower. It allows automatically collecting system-level statistics and estimating the resources needed for each client, thus running the simulation in a resource-aware fashion. The results show that our design successfully increases parallelism for 1.66 $\times$ faster wall-clock time and 2.6$\times$ better GPU utilisation, which enables large-scale experiments on heterogeneous clients.
FedorAS: Federated Architecture Search under system heterogeneity
Jun 23, 2022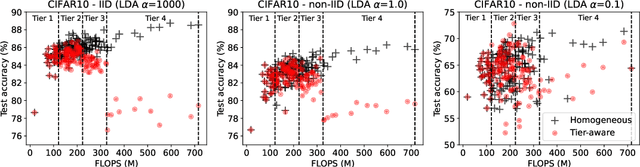
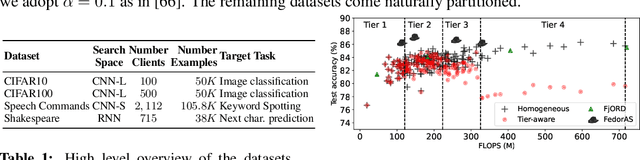
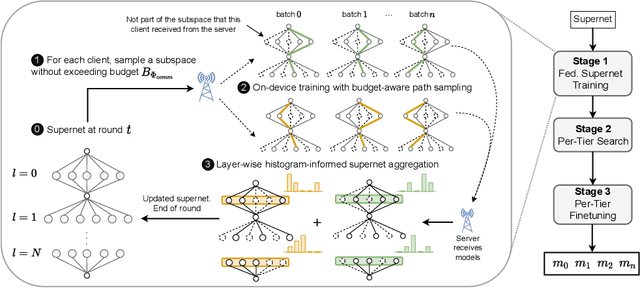
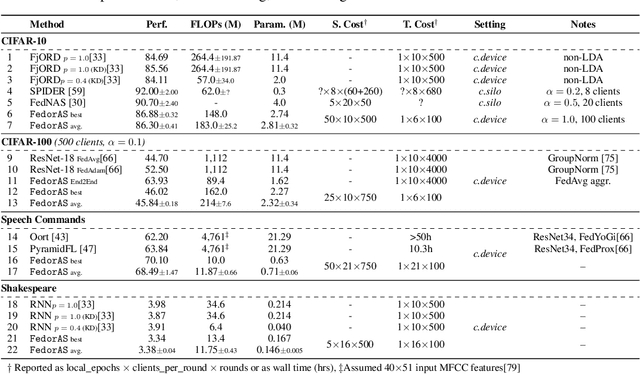
Federated learning (FL) has recently gained considerable attention due to its ability to use decentralised data while preserving privacy. However, it also poses additional challenges related to the heterogeneity of the participating devices, both in terms of their computational capabilities and contributed data. Meanwhile, Neural Architecture Search (NAS) has been successfully used with centralised datasets, producing state-of-the-art results in constrained (hardware-aware) and unconstrained settings. However, even the most recent work laying at the intersection of NAS and FL assumes homogeneous compute environment with datacenter-grade hardware and does not address the issues of working with constrained, heterogeneous devices. As a result, practical usage of NAS in a federated setting remains an open problem that we address in our work. We design our system, FedorAS, to discover and train promising architectures when dealing with devices of varying capabilities holding non-IID distributed data, and present empirical evidence of its effectiveness across different settings. Specifically, we evaluate FedorAS across datasets spanning three different modalities (vision, speech, text) and show its better performance compared to state-of-the-art federated solutions, while maintaining resource efficiency.
Federated Self-supervised Speech Representations: Are We There Yet?
Apr 06, 2022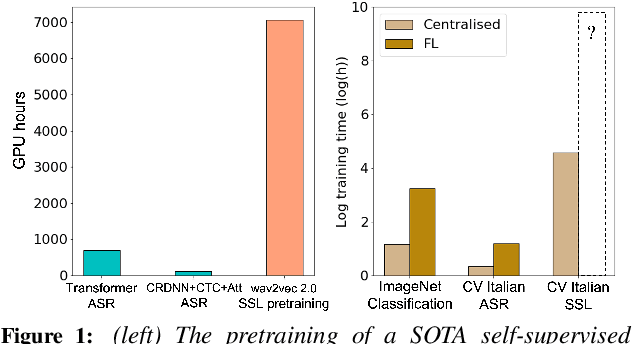
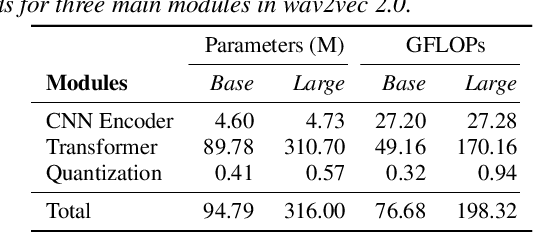
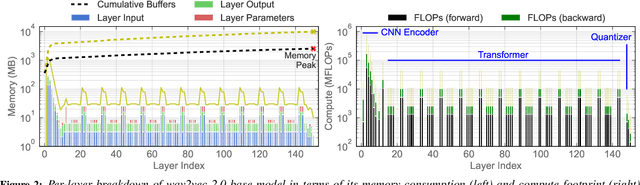
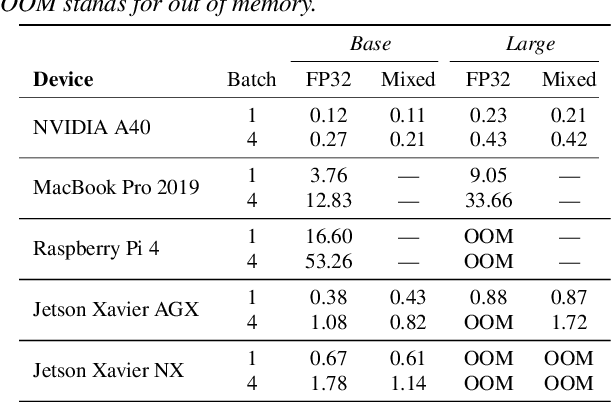
The ubiquity of microphone-enabled devices has lead to large amounts of unlabelled audio data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of speech representations. In this paper, we provide a first-of-its-kind systematic study of the feasibility and complexities for training speech SSL models under FL scenarios from the perspective of algorithms, hardware, and systems limits. Despite the high potential of their combination, we find existing system constraints and algorithmic behaviour make SSL and FL systems nearly impossible to build today. Yet critically, our results indicate specific performance bottlenecks and research opportunities that would allow this situation to be reversed. While our analysis suggests that, given existing trends in hardware, hybrid SSL and FL speech systems will not be viable until 2027. We believe this study can act as a roadmap to accelerate work towards reaching this milestone much earlier.