 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaD Physics: Evaluating information seeking under constraints in physical environments
May 11, 2026Scientific discovery is fundamentally a resource-constrained process that requires navigating complex trade-offs between the quality and quantity of measurements due to physical and cost constraints. Measurements drive the scientific process by revealing novel phenomena to improve our understanding. Existing benchmarks for evaluating agents for scientific discovery focus on either static knowledge-based reasoning or unconstrained experimental design tasks, and do not capture the ability to make measurements and plan under constraints. To bridge this gap, we propose Measuring and Discovering Physics (MaD Physics), a benchmark to evaluate the ability of agents to make informative measurements and conclusions subject to constraints on the quality and quantity of measurements. The benchmark consists of three environments, each based on a distinct physical law. To mitigate contamination from existing knowledge, MaD Physics includes altered physical laws. In each trial, the agent makes measurements of the system until it exhausts an allotted budget and then the agent has to infer the underlying physical law to make predictions about the state of the system in the future. MaD Physics evaluates two fundamental capabilities of scientific agents: inferring models from data and planning under constraints. We also demonstrate how MaD Physics can be used to evaluate other capabilities such as multimodality and in-context learning. We benchmark agents on MaD Physics using four Gemini models (2.5 Flash Lite, 2.5 Flash, 2.5 Pro, and 3 Flash), identifying shortcomings in their structured exploration and data collection capabilities and highlighting directions to improve their scientific reasoning.
Randomized Positional Encodings Boost Length Generalization of Transformers
May 26, 2023



Transformers have impressive generalization capabilities on tasks with a fixed context length. However, they fail to generalize to sequences of arbitrary length, even for seemingly simple tasks such as duplicating a string. Moreover, simply training on longer sequences is inefficient due to the quadratic computation complexity of the global attention mechanism. In this work, we demonstrate that this failure mode is linked to positional encodings being out-of-distribution for longer sequences (even for relative encodings) and introduce a novel family of positional encodings that can overcome this problem. Concretely, our randomized positional encoding scheme simulates the positions of longer sequences and randomly selects an ordered subset to fit the sequence's length. Our large-scale empirical evaluation of 6000 models across 15 algorithmic reasoning tasks shows that our method allows Transformers to generalize to sequences of unseen length (increasing test accuracy by 12.0% on average).
A Generalist Neural Algorithmic Learner
Sep 22, 2022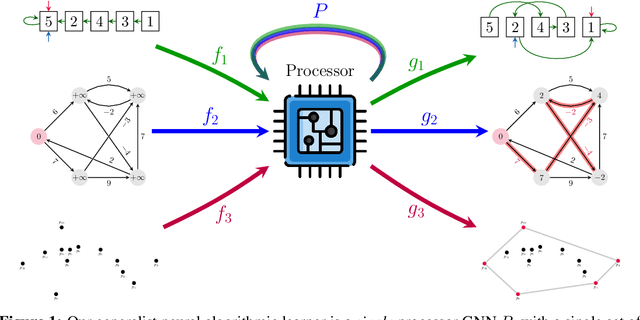
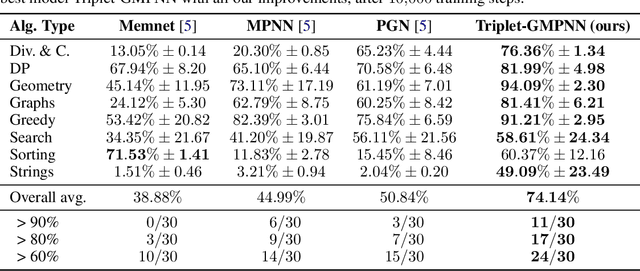
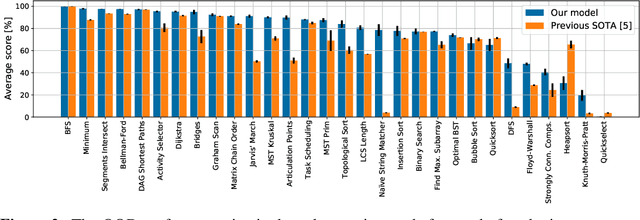
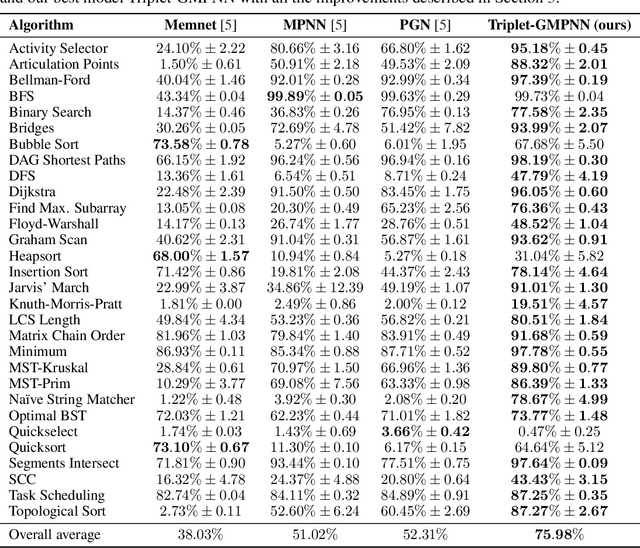
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
A Theoretical Analysis of Catastrophic Forgetting through the NTK Overlap Matrix
Oct 07, 2020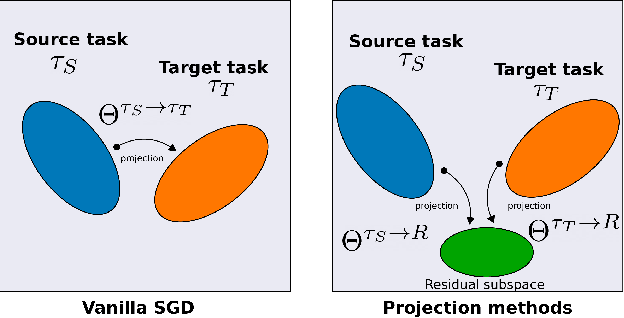
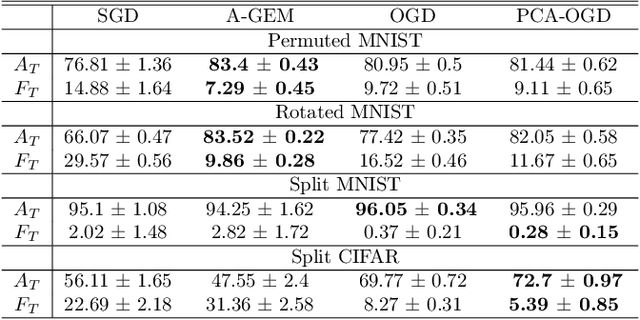
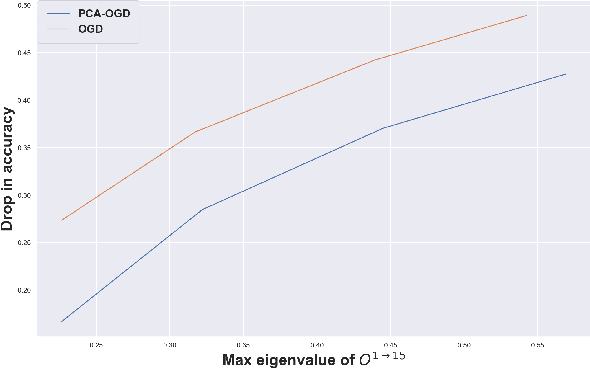

Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data during its entire lifetime. Although major advances have been made in the field, one recurring problem which remains unsolved is that of Catastrophic Forgetting (CF). While the issue has been extensively studied empirically, little attention has been paid from a theoretical angle. In this paper, we show that the impact of CF increases as two tasks increasingly align. We introduce a measure of task similarity called the NTK overlap matrix which is at the core of CF. We analyze common projected gradient algorithms and demonstrate how they mitigate forgetting. Then, we propose a variant of Orthogonal Gradient Descent (OGD) which leverages structure of the data through Principal Component Analysis (PCA). Experiments support our theoretical findings and show how our method reduces CF on classical CL datasets.