 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive Alignment: Artificial Intelligence for Human Flourishing
May 11, 2026Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology's focus on mental illness: necessary but incomplete. What we call Positive Alignment is the development of AI systems that (i) actively support human and ecological flourishing in a pluralistic, polycentric, context-sensitive, and user-authored way while (ii) remaining safe and cooperative. It is a distinct and necessary agenda within AI alignment research. We argue that several existing failures of alignment (e.g., engagement hacking, loss of human autonomy, failures in truth-seeking, low epistemic humility, error correction, lack of diverse viewpoints, and being primarily reactive rather than proactive) may be better addressed through positive alignment, including cultivating virtues and maximizing human flourishing. We highlight a range of challenges, open questions, and technical directions (e.g., data filtering and upsampling, pre- and post-training, evaluations, collaborative value collection) for different phases of the LLM and agents lifecycle. We end with design principles for promoting disagreement and decentralization through contextual grounding, community customization, continual adaptation, and polycentric governance; that is, many legitimate centers of oversight rather than one institutional or moral chokepoint.
Contemplative Wisdom for Superalignment
Apr 21, 2025As artificial intelligence (AI) improves, traditional alignment strategies may falter in the face of unpredictable self-improvement, hidden subgoals, and the sheer complexity of intelligent systems. Rather than externally constraining behavior, we advocate designing AI with intrinsic morality built into its cognitive architecture and world model. Inspired by contemplative wisdom traditions, we show how four axiomatic principles can instil a resilient Wise World Model in AI systems. First, mindfulness enables self-monitoring and recalibration of emergent subgoals. Second, emptiness forestalls dogmatic goal fixation and relaxes rigid priors. Third, non-duality dissolves adversarial self-other boundaries. Fourth, boundless care motivates the universal reduction of suffering. We find that prompting AI to reflect on these principles improves performance on the AILuminate Benchmark using GPT-4o, particularly when combined. We offer detailed implementation strategies for state-of-the-art models, including contemplative architectures, constitutions, and reinforcement of chain-of-thought. For future systems, the active inference framework may offer the self-organizing and dynamic coupling capabilities needed to enact these insights in embodied agents. This interdisciplinary approach offers a self-correcting and resilient alternative to prevailing brittle control schemes.
Causal blankets: Theory and algorithmic framework
Sep 29, 2020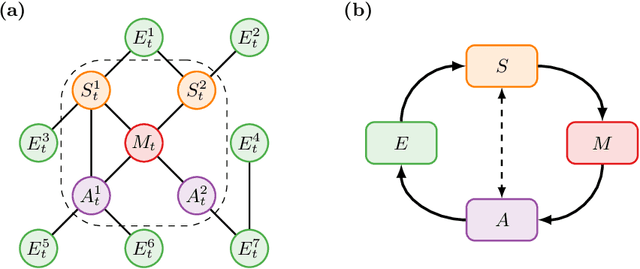
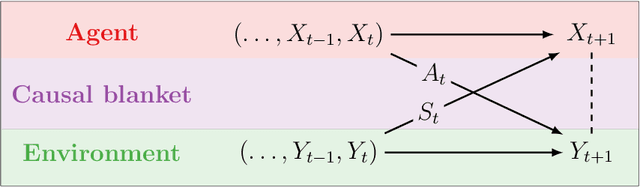
We introduce a novel framework to identify perception-action loops (PALOs) directly from data based on the principles of computational mechanics. Our approach is based on the notion of causal blanket, which captures sensory and active variables as dynamical sufficient statistics -- i.e. as the "differences that make a difference." Moreover, our theory provides a broadly applicable procedure to construct PALOs that requires neither a steady-state nor Markovian dynamics. Using our theory, we show that every bipartite stochastic process has a causal blanket, but the extent to which this leads to an effective PALO formulation varies depending on the integrated information of the bipartition.