 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Platypus: Quick, Cheap, and Powerful Refinement of LLMs
Aug 14, 2023



We present $\textbf{Platypus}$, a family of fine-tuned and merged Large Language Models (LLMs) that achieves the strongest performance and currently stands at first place in HuggingFace's Open LLM Leaderboard as of the release date of this work. In this work we describe (1) our curated dataset $\textbf{Open-Platypus}$, that is a subset of other open datasets and which $\textit{we release to the public}$ (2) our process of fine-tuning and merging LoRA modules in order to conserve the strong prior of pretrained LLMs, while bringing specific domain knowledge to the surface (3) our efforts in checking for test data leaks and contamination in the training data, which can inform future research. Specifically, the Platypus family achieves strong performance in quantitative LLM metrics across model sizes, topping the global Open LLM leaderboard while using just a fraction of the fine-tuning data and overall compute that are required for other state-of-the-art fine-tuned LLMs. In particular, a 13B Platypus model can be trained on $\textit{a single}$ A100 GPU using 25k questions in 5 hours. This is a testament of the quality of our Open-Platypus dataset, and opens opportunities for more improvements in the field. Project page: https://platypus-llm.github.io
HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Jul 13, 2023



Personalization has emerged as a prominent aspect within the field of generative AI, enabling the synthesis of individuals in diverse contexts and styles, while retaining high-fidelity to their identities. However, the process of personalization presents inherent challenges in terms of time and memory requirements. Fine-tuning each personalized model needs considerable GPU time investment, and storing a personalized model per subject can be demanding in terms of storage capacity. To overcome these challenges, we propose HyperDreamBooth-a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person's face in various contexts and styles, with high subject details while also preserving the model's crucial knowledge of diverse styles and semantic modifications. Our method achieves personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. Also our method yields a model that is 10000x smaller than a normal DreamBooth model. Project page: https://hyperdreambooth.github.io
Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
Jun 30, 2023



Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional neural networks (CNNs). Although the jury is still out on which model type is superior, each has unique inductive biases that shape their learning and generalization performance. For example, ViTs have interesting properties with respect to early layer non-local feature dependence, as well as self-attention mechanisms which enhance learning flexibility, enabling them to ignore out-of-context image information more effectively. We hypothesize that this power to ignore out-of-context information (which we name $\textit{patch selectivity}$), while integrating in-context information in a non-local manner in early layers, allows ViTs to more easily handle occlusion. In this study, our aim is to see whether we can have CNNs $\textit{simulate}$ this ability of patch selectivity by effectively hardwiring this inductive bias using Patch Mixing data augmentation, which consists of inserting patches from another image onto a training image and interpolating labels between the two image classes. Specifically, we use Patch Mixing to train state-of-the-art ViTs and CNNs, assessing its impact on their ability to ignore out-of-context patches and handle natural occlusions. We find that ViTs do not improve nor degrade when trained using Patch Mixing, but CNNs acquire new capabilities to ignore out-of-context information and improve on occlusion benchmarks, leaving us to conclude that this training method is a way of simulating in CNNs the abilities that ViTs already possess. We will release our Patch Mixing implementation and proposed datasets for public use. Project page: https://arielnlee.github.io/PatchMixing/
StyleDrop: Text-to-Image Generation in Any Style
Jun 01, 2023



Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language and out-of-distribution effects make it hard to synthesize image styles, that leverage a specific design pattern, texture or material. In this paper, we introduce StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than $1\%$ of total model parameters) and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image that specifies the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop implemented on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: https://styledrop.github.io
Subject-driven Text-to-Image Generation via Apprenticeship Learning
Apr 14, 2023



Recent text-to-image generation models like DreamBooth have made remarkable progress in generating highly customized images of a target subject, by fine-tuning an ``expert model'' for a given subject from a few examples. However, this process is expensive, since a new expert model must be learned for each subject. In this paper, we present SuTI, a Subject-driven Text-to-Image generator that replaces subject-specific fine tuning with \emph{in-context} learning. Given a few demonstrations of a new subject, SuTI can instantly generate novel renditions of the subject in different scenes, without any subject-specific optimization. SuTI is powered by {\em apprenticeship learning}, where a single apprentice model is learned from data generated by massive amount of subject-specific expert models. Specifically, we mine millions of image clusters from the Internet, each centered around a specific visual subject. We adopt these clusters to train massive amount of expert models specialized on different subjects. The apprentice model SuTI then learns to mimic the behavior of these experts through the proposed apprenticeship learning algorithm. SuTI can generate high-quality and customized subject-specific images 20x faster than optimization-based SoTA methods. On the challenging DreamBench and DreamBench-v2, our human evaluation shows that SuTI can significantly outperform existing approaches like InstructPix2Pix, Textual Inversion, Imagic, Prompt2Prompt, Re-Imagen while performing on par with DreamBooth.
DreamBooth3D: Subject-Driven Text-to-3D Generation
Mar 27, 2023We present DreamBooth3D, an approach to personalize text-to-3D generative models from as few as 3-6 casually captured images of a subject. Our approach combines recent advances in personalizing text-to-image models (DreamBooth) with text-to-3D generation (DreamFusion). We find that naively combining these methods fails to yield satisfactory subject-specific 3D assets due to personalized text-to-image models overfitting to the input viewpoints of the subject. We overcome this through a 3-stage optimization strategy where we jointly leverage the 3D consistency of neural radiance fields together with the personalization capability of text-to-image models. Our method can produce high-quality, subject-specific 3D assets with text-driven modifications such as novel poses, colors and attributes that are not seen in any of the input images of the subject.
Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing
Nov 29, 2022



Modern deep neural networks tend to be evaluated on static test sets. One shortcoming of this is the fact that these deep neural networks cannot be easily evaluated for robustness issues with respect to specific scene variations. For example, it is hard to study the robustness of these networks to variations of object scale, object pose, scene lighting and 3D occlusions. The main reason is that collecting real datasets with fine-grained naturalistic variations of sufficient scale can be extremely time-consuming and expensive. In this work, we present Counterfactual Simulation Testing, a counterfactual framework that allows us to study the robustness of neural networks with respect to some of these naturalistic variations by building realistic synthetic scenes that allow us to ask counterfactual questions to the models, ultimately providing answers to questions such as "Would your classification still be correct if the object were viewed from the top?" or "Would your classification still be correct if the object were partially occluded by another object?". Our method allows for a fair comparison of the robustness of recently released, state-of-the-art Convolutional Neural Networks and Vision Transformers, with respect to these naturalistic variations. We find evidence that ConvNext is more robust to pose and scale variations than Swin, that ConvNext generalizes better to our simulated domain and that Swin handles partial occlusion better than ConvNext. We also find that robustness for all networks improves with network scale and with data scale and variety. We release the Naturalistic Variation Object Dataset (NVD), a large simulated dataset of 272k images of everyday objects with naturalistic variations such as object pose, scale, viewpoint, lighting and occlusions. Project page: https://counterfactualsimulation.github.io
Human Body Measurement Estimation with Adversarial Augmentation
Oct 11, 2022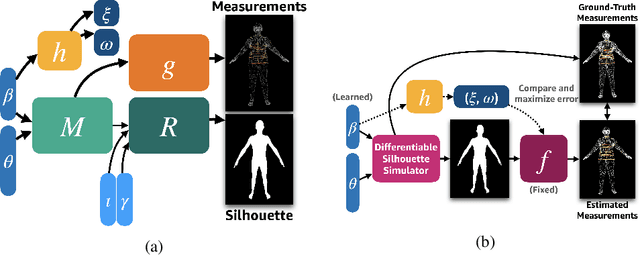
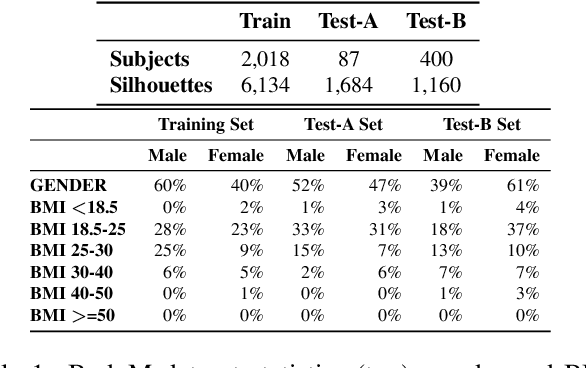
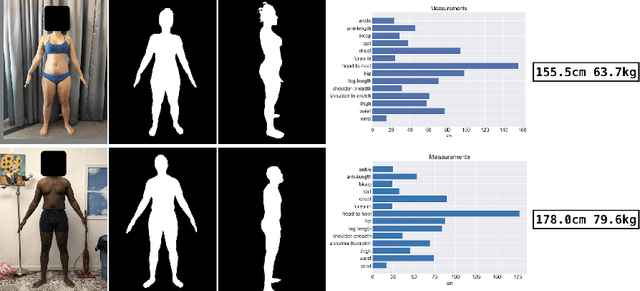
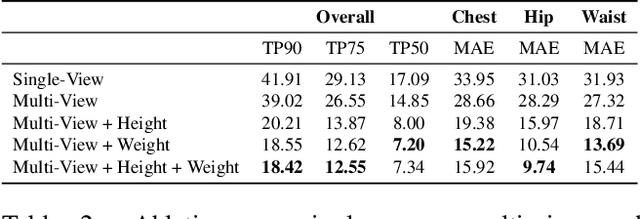
We present a Body Measurement network (BMnet) for estimating 3D anthropomorphic measurements of the human body shape from silhouette images. Training of BMnet is performed on data from real human subjects, and augmented with a novel adversarial body simulator (ABS) that finds and synthesizes challenging body shapes. ABS is based on the skinned multiperson linear (SMPL) body model, and aims to maximize BMnet measurement prediction error with respect to latent SMPL shape parameters. ABS is fully differentiable with respect to these parameters, and trained end-to-end via backpropagation with BMnet in the loop. Experiments show that ABS effectively discovers adversarial examples, such as bodies with extreme body mass indices (BMI), consistent with the rarity of extreme-BMI bodies in BMnet's training set. Thus ABS is able to reveal gaps in training data and potential failures in predicting under-represented body shapes. Results show that training BMnet with ABS improves measurement prediction accuracy on real bodies by up to 10%, when compared to no augmentation or random body shape sampling. Furthermore, our method significantly outperforms SOTA measurement estimation methods by as much as 3x. Finally, we release BodyM, the first challenging, large-scale dataset of photo silhouettes and body measurements of real human subjects, to further promote research in this area. Project website: https://adversarialbodysim.github.io
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Aug 25, 2022
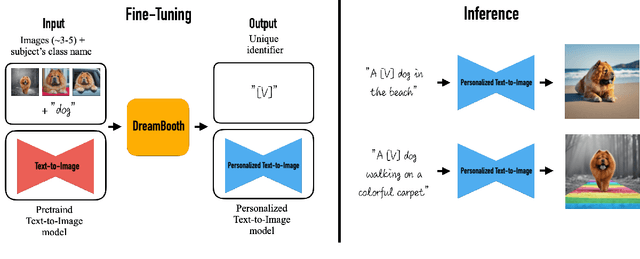
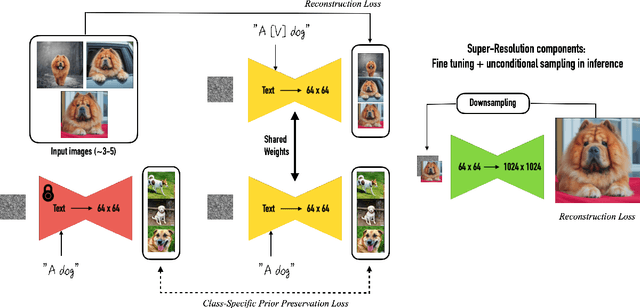

Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for "personalization" of text-to-image diffusion models (specializing them to users' needs). Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, appearance modification, and artistic rendering (all while preserving the subject's key features). Project page: https://dreambooth.github.io/