 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTMGF: An Effective Spatial-Temporal Multi-Granularity Framework for Traffic Forecasting
Apr 08, 2024



Accurate Traffic Prediction is a challenging task in intelligent transportation due to the spatial-temporal aspects of road networks. The traffic of a road network can be affected by long-distance or long-term dependencies where existing methods fall short in modeling them. In this paper, we introduce a novel framework known as Spatial-Temporal Multi-Granularity Framework (STMGF) to enhance the capture of long-distance and long-term information of the road networks. STMGF makes full use of different granularity information of road networks and models the long-distance and long-term information by gathering information in a hierarchical interactive way. Further, it leverages the inherent periodicity in traffic sequences to refine prediction results by matching with recent traffic data. We conduct experiments on two real-world datasets, and the results demonstrate that STMGF outperforms all baseline models and achieves state-of-the-art performance.
RouterBench: A Benchmark for Multi-LLM Routing System
Mar 28, 2024



As the range of applications for Large Language Models (LLMs) continues to grow, the demand for effective serving solutions becomes increasingly critical. Despite the versatility of LLMs, no single model can optimally address all tasks and applications, particularly when balancing performance with cost. This limitation has led to the development of LLM routing systems, which combine the strengths of various models to overcome the constraints of individual LLMs. Yet, the absence of a standardized benchmark for evaluating the performance of LLM routers hinders progress in this area. To bridge this gap, we present RouterBench, a novel evaluation framework designed to systematically assess the efficacy of LLM routing systems, along with a comprehensive dataset comprising over 405k inference outcomes from representative LLMs to support the development of routing strategies. We further propose a theoretical framework for LLM routing, and deliver a comparative analysis of various routing approaches through RouterBench, highlighting their potentials and limitations within our evaluation framework. This work not only formalizes and advances the development of LLM routing systems but also sets a standard for their assessment, paving the way for more accessible and economically viable LLM deployments. The code and data are available at https://github.com/withmartian/routerbench.
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Mar 22, 2024



The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.
Scaling Up Dynamic Human-Scene Interaction Modeling
Mar 13, 2024Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS, we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.
On the Curses of Future and History in Future-dependent Value Functions for Off-policy Evaluation
Feb 22, 2024We study off-policy evaluation (OPE) in partially observable environments with complex observations, with the goal of developing estimators whose guarantee avoids exponential dependence on the horizon. While such estimators exist for MDPs and POMDPs can be converted to history-based MDPs, their estimation errors depend on the state-density ratio for MDPs which becomes history ratios after conversion, an exponential object. Recently, Uehara et al. (2022) proposed future-dependent value functions as a promising framework to address this issue, where the guarantee for memoryless policies depends on the density ratio over the latent state space. However, it also depends on the boundedness of the future-dependent value function and other related quantities, which we show could be exponential-in-length and thus erasing the advantage of the method. In this paper, we discover novel coverage assumptions tailored to the structure of POMDPs, such as outcome coverage and belief coverage. These assumptions not only enable polynomial bounds on the aforementioned quantities, but also lead to the discovery of new algorithms with complementary properties.
A Theoretical Analysis of Nash Learning from Human Feedback under General KL-Regularized Preference
Feb 11, 2024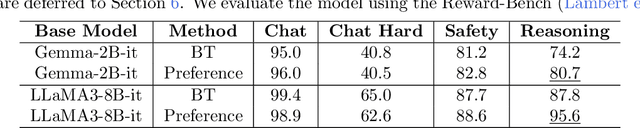
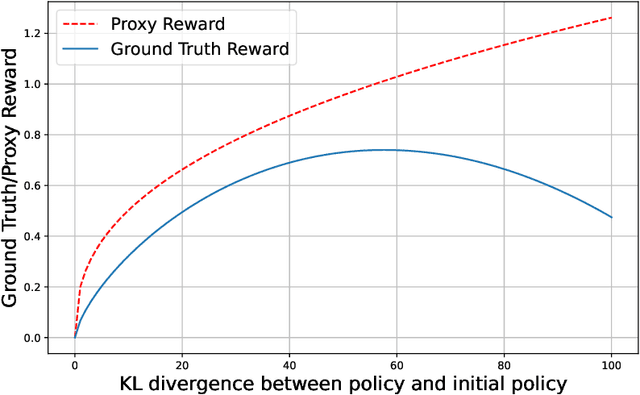

Reinforcement Learning from Human Feedback (RLHF) learns from the preference signal provided by a probabilistic preference model, which takes a prompt and two responses as input, and produces a score indicating the preference of one response against another. So far, the most popular RLHF paradigm is reward-based, which starts with an initial step of reward modeling, and the constructed reward is then used to provide a reward signal for the subsequent reward optimization stage. However, the existence of a reward function is a strong assumption and the reward-based RLHF is limited in expressivity and cannot capture the real-world complicated human preference. In this work, we provide theoretical insights for a recently proposed learning paradigm, Nash learning from human feedback (NLHF), which considered a general preference model and formulated the alignment process as a game between two competitive LLMs. The learning objective is to find a policy that consistently generates responses preferred over any competing policy while staying close to the initial model. The objective is defined as the Nash equilibrium (NE) of the KL-regularized preference model. We aim to make the first attempt to study the theoretical learnability of the KL-regularized NLHF by considering both offline and online settings. For the offline learning from a pre-collected dataset, we propose algorithms that are efficient under suitable coverage conditions of the dataset. For batch online learning from iterative interactions with a preference oracle, our proposed algorithm enjoys a finite sample guarantee under the structural condition of the underlying preference model. Our results connect the new NLHF paradigm with traditional RL theory, and validate the potential of reward-model-free learning under general preference.
Vertical Symbolic Regression via Deep Policy Gradient
Feb 01, 2024Vertical Symbolic Regression (VSR) recently has been proposed to expedite the discovery of symbolic equations with many independent variables from experimental data. VSR reduces the search spaces following the vertical discovery path by building from reduced-form equations involving a subset of independent variables to full-fledged ones. Proved successful by many symbolic regressors, deep neural networks are expected to further scale up VSR. Nevertheless, directly combining VSR with deep neural networks will result in difficulty in passing gradients and other engineering issues. We propose Vertical Symbolic Regression using Deep Policy Gradient (VSR-DPG) and demonstrate that VSR-DPG can recover ground-truth equations involving multiple input variables, significantly beyond both deep reinforcement learning-based approaches and previous VSR variants. Our VSR-DPG models symbolic regression as a sequential decision-making process, in which equations are built from repeated applications of grammar rules. The integrated deep model is trained to maximize a policy gradient objective. Experimental results demonstrate that our VSR-DPG significantly outperforms popular baselines in identifying both algebraic equations and ordinary differential equations on a series of benchmarks.
Harnessing Density Ratios for Online Reinforcement Learning
Jan 18, 2024The theories of offline and online reinforcement learning, despite having evolved in parallel, have begun to show signs of the possibility for a unification, with algorithms and analysis techniques for one setting often having natural counterparts in the other. However, the notion of density ratio modeling, an emerging paradigm in offline RL, has been largely absent from online RL, perhaps for good reason: the very existence and boundedness of density ratios relies on access to an exploratory dataset with good coverage, but the core challenge in online RL is to collect such a dataset without having one to start. In this work we show -- perhaps surprisingly -- that density ratio-based algorithms have online counterparts. Assuming only the existence of an exploratory distribution with good coverage, a structural condition known as coverability (Xie et al., 2023), we give a new algorithm (GLOW) that uses density ratio realizability and value function realizability to perform sample-efficient online exploration. GLOW addresses unbounded density ratios via careful use of truncation, and combines this with optimism to guide exploration. GLOW is computationally inefficient; we complement it with a more efficient counterpart, HyGLOW, for the Hybrid RL setting (Song et al., 2022) wherein online RL is augmented with additional offline data. HyGLOW is derived as a special case of a more general meta-algorithm that provides a provable black-box reduction from hybrid RL to offline RL, which may be of independent interest.
Vertical Symbolic Regression
Dec 19, 2023Automating scientific discovery has been a grand goal of Artificial Intelligence (AI) and will bring tremendous societal impact. Learning symbolic expressions from experimental data is a vital step in AI-driven scientific discovery. Despite exciting progress, most endeavors have focused on the horizontal discovery paths, i.e., they directly search for the best expression in the full hypothesis space involving all the independent variables. Horizontal paths are challenging due to the exponentially large hypothesis space involving all the independent variables. We propose Vertical Symbolic Regression (VSR) to expedite symbolic regression. The VSR starts by fitting simple expressions involving a few independent variables under controlled experiments where the remaining variables are held constant. It then extends the expressions learned in previous rounds by adding new independent variables and using new control variable experiments allowing these variables to vary. The first few steps in vertical discovery are significantly cheaper than the horizontal path, as their search is in reduced hypothesis spaces involving a small set of variables. As a consequence, vertical discovery has the potential to supercharge state-of-the-art symbolic regression approaches in handling complex equations with many contributing factors. Theoretically, we show that the search space of VSR can be exponentially smaller than that of horizontal approaches when learning a class of expressions. Experimentally, VSR outperforms several baselines in learning symbolic expressions involving many independent variables.
Gibbs Sampling from Human Feedback: A Provable KL- constrained Framework for RLHF
Dec 18, 2023



This paper studies the theoretical framework of the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its theoretical properties both in offline and online settings and propose efficient algorithms with finite-sample theoretical guarantees. Our work bridges the gap between theory and practice by linking our theoretical insights with existing practical alignment algorithms such as Direct Preference Optimization (DPO) and Rejection Sampling Optimization (RSO). Furthermore, these findings and connections also offer both theoretical and practical communities new tools and insights for future algorithmic design of alignment algorithms.