 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojanGYM: A Detector-in-the-Loop LLM for Adaptive RTL Hardware Trojan Insertion
Jan 23, 2026Hardware Trojans (HTs) remain a critical threat because learning-based detectors often overfit to narrow trigger/payload patterns and small, stylized benchmarks. We introduce TrojanGYM, an agentic, LLM-driven framework that automatically curates HT insertions to expose detector blind spots while preserving design correctness. Given high-level HT specifications, a suite of cooperating LLM agents (instantiated with GPT-4, LLaMA-3.3-70B, and Gemini-2.5Pro) proposes and refines RTL modifications that realize diverse triggers and payloads without impacting normal functionality. TrojanGYM implements a feedback-driven benchmark generation loop co-designed with HT detectors, in which constraint-aware syntactic checking and GNN-based HT detectors provide feedback that iteratively refines HT specifications and insertion strategies to better surface detector blind spots. We further propose Robust-GNN4TJ, a new implementation of the GNN4TJ with improved graph extraction, training robustness, and prediction reliability, especially on LLM-generated HT designs. On the most challenging TrojanGYM-generated benchmarks, Robust-GNN4TJ raises HT detection rates from 0% to 60% relative to a prior GNN-based detector. We instantiate TrojanGYM on SRAM, AES-128, and UART designs at RTL level, and show that it systematically produces diverse, functionally correct HTs that reach up to 83.33% evasion rates against modern GNN-based detectors, revealing robustness gaps that are not apparent when these detectors are evaluated solely on existing TrustHub-style benchmarks. Post peer-review, we will release all codes and artifacts.
Quantum vs. Classical Machine Learning: A Benchmark Study for Financial Prediction
Jan 07, 2026In this paper, we present a reproducible benchmarking framework that systematically compares QML models with architecture-matched classical counterparts across three financial tasks: (i) directional return prediction on U.S. and Turkish equities, (ii) live-trading simulation with Quantum LSTMs versus classical LSTMs on the S\&P 500, and (iii) realized volatility forecasting using Quantum Support Vector Regression. By standardizing data splits, features, and evaluation metrics, our study provides a fair assessment of when current-generation QML models can match or exceed classical methods. Our results reveal that quantum approaches show performance gains when data structure and circuit design are well aligned. In directional classification, hybrid quantum neural networks surpass the parameter-matched ANN by \textbf{+3.8 AUC} and \textbf{+3.4 accuracy points} on \texttt{AAPL} stock and by \textbf{+4.9 AUC} and \textbf{+3.6 accuracy points} on Turkish stock \texttt{KCHOL}. In live trading, the QLSTM achieves higher risk-adjusted returns in \textbf{two of four} S\&P~500 regimes. For volatility forecasting, an angle-encoded QSVR attains the \textbf{lowest QLIKE} on \texttt{KCHOL} and remains within $\sim$0.02-0.04 QLIKE of the best classical kernels on \texttt{S\&P~500} and \texttt{AAPL}. Our benchmarking framework clearly identifies the scenarios where current QML architectures offer tangible improvements and where established classical methods continue to dominate.
QSLM: A Performance- and Memory-aware Quantization Framework with Tiered Search Strategy for Spike-driven Language Models
Jan 02, 2026Large Language Models (LLMs) have been emerging as prominent AI models for solving many natural language tasks due to their high performance (e.g., accuracy) and capabilities in generating high-quality responses to the given inputs. However, their large computational cost, huge memory footprints, and high processing power/energy make it challenging for their embedded deployments. Amid several tinyLLMs, recent works have proposed spike-driven language models (SLMs) for significantly reducing the processing power/energy of LLMs. However, their memory footprints still remain too large for low-cost and resource-constrained embedded devices. Manual quantization approach may effectively compress SLM memory footprints, but it requires a huge design time and compute power to find the quantization setting for each network, hence making this approach not-scalable for handling different networks, performance requirements, and memory budgets. To bridge this gap, we propose QSLM, a novel framework that performs automated quantization for compressing pre-trained SLMs, while meeting the performance and memory constraints. To achieve this, QSLM first identifies the hierarchy of the given network architecture and the sensitivity of network layers under quantization, then employs a tiered quantization strategy (e.g., global-, block-, and module-level quantization) while leveraging a multi-objective performance-and-memory trade-off function to select the final quantization setting. Experimental results indicate that our QSLM reduces memory footprint by up to 86.5%, reduces power consumption by up to 20%, maintains high performance across different tasks (i.e., by up to 84.4% accuracy of sentiment classification on the SST-2 dataset and perplexity score of 23.2 for text generation on the WikiText-2 dataset) close to the original non-quantized model while meeting the performance and memory constraints.
PatchBlock: A Lightweight Defense Against Adversarial Patches for Embedded EdgeAI Devices
Jan 01, 2026Adversarial attacks pose a significant challenge to the reliable deployment of machine learning models in EdgeAI applications, such as autonomous driving and surveillance, which rely on resource-constrained devices for real-time inference. Among these, patch-based adversarial attacks, where small malicious patches (e.g., stickers) are applied to objects, can deceive neural networks into making incorrect predictions with potentially severe consequences. In this paper, we present PatchBlock, a lightweight framework designed to detect and neutralize adversarial patches in images. Leveraging outlier detection and dimensionality reduction, PatchBlock identifies regions affected by adversarial noise and suppresses their impact. It operates as a pre-processing module at the sensor level, efficiently running on CPUs in parallel with GPU inference, thus preserving system throughput while avoiding additional GPU overhead. The framework follows a three-stage pipeline: splitting the input into chunks (Chunking), detecting anomalous regions via a redesigned isolation forest with targeted cuts for faster convergence (Separating), and applying dimensionality reduction on the identified outliers (Mitigating). PatchBlock is both model- and patch-agnostic, can be retrofitted to existing pipelines, and integrates seamlessly between sensor inputs and downstream models. Evaluations across multiple neural architectures, benchmark datasets, attack types, and diverse edge devices demonstrate that PatchBlock consistently improves robustness, recovering up to 77% of model accuracy under strong patch attacks such as the Google Adversarial Patch, while maintaining high portability and minimal clean accuracy loss. Additionally, PatchBlock outperforms the state-of-the-art defenses in efficiency, in terms of computation time and energy consumption per sample, making it suitable for EdgeAI applications.
Graph-Based Bayesian Optimization for Quantum Circuit Architecture Search with Uncertainty Calibrated Surrogates
Dec 10, 2025



Quantum circuit design is a key bottleneck for practical quantum machine learning on complex, real-world data. We present an automated framework that discovers and refines variational quantum circuits (VQCs) using graph-based Bayesian optimization with a graph neural network (GNN) surrogate. Circuits are represented as graphs and mutated and selected via an expected improvement acquisition function informed by surrogate uncertainty with Monte Carlo dropout. Candidate circuits are evaluated with a hybrid quantum-classical variational classifier on the next generation firewall telemetry and network internet of things (NF-ToN-IoT-V2) cybersecurity dataset, after feature selection and scaling for quantum embedding. We benchmark our pipeline against an MLP-based surrogate, random search, and greedy GNN selection. The GNN-guided optimizer consistently finds circuits with lower complexity and competitive or superior classification accuracy compared to all baselines. Robustness is assessed via a noise study across standard quantum noise channels, including amplitude damping, phase damping, thermal relaxation, depolarizing, and readout bit flip noise. The implementation is fully reproducible, with time benchmarking and export of best found circuits, providing a scalable and interpretable route to automated quantum circuit discovery.
FAQNAS: FLOPs-aware Hybrid Quantum Neural Architecture Search using Genetic Algorithm
Nov 13, 2025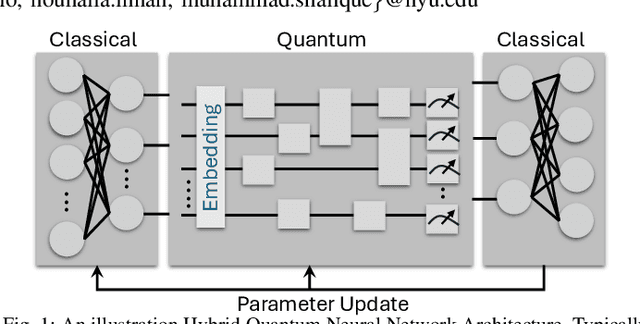
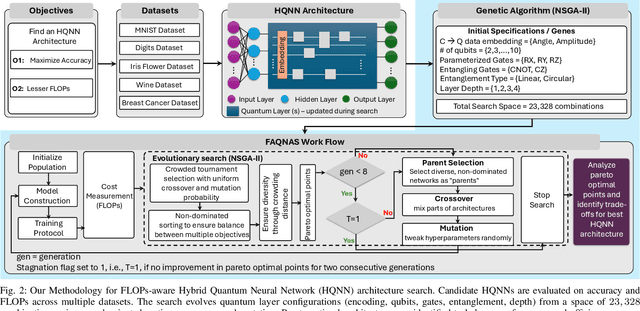
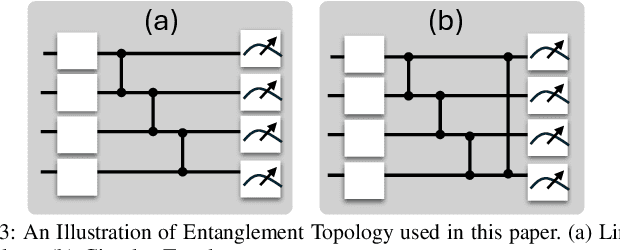
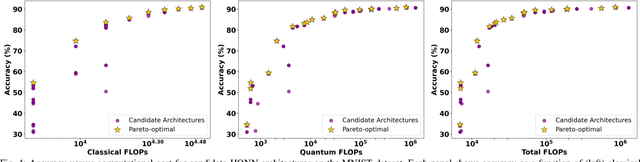
Hybrid Quantum Neural Networks (HQNNs), which combine parameterized quantum circuits with classical neural layers, are emerging as promising models in the noisy intermediate-scale quantum (NISQ) era. While quantum circuits are not naturally measured in floating point operations (FLOPs), most HQNNs (in NISQ era) are still trained on classical simulators where FLOPs directly dictate runtime and scalability. Hence, FLOPs represent a practical and viable metric to measure the computational complexity of HQNNs. In this work, we introduce FAQNAS, a FLOPs-aware neural architecture search (NAS) framework that formulates HQNN design as a multi-objective optimization problem balancing accuracy and FLOPs. Unlike traditional approaches, FAQNAS explicitly incorporates FLOPs into the optimization objective, enabling the discovery of architectures that achieve strong performance while minimizing computational cost. Experiments on five benchmark datasets (MNIST, Digits, Wine, Breast Cancer, and Iris) show that quantum FLOPs dominate accuracy improvements, while classical FLOPs remain largely fixed. Pareto-optimal solutions reveal that competitive accuracy can often be achieved with significantly reduced computational cost compared to FLOPs-agnostic baselines. Our results establish FLOPs-awareness as a practical criterion for HQNN design in the NISQ era and as a scalable principle for future HQNN systems.
RobQFL: Robust Quantum Federated Learning in Adversarial Environment
Sep 05, 2025Quantum Federated Learning (QFL) merges privacy-preserving federation with quantum computing gains, yet its resilience to adversarial noise is unknown. We first show that QFL is as fragile as centralized quantum learning. We propose Robust Quantum Federated Learning (RobQFL), embedding adversarial training directly into the federated loop. RobQFL exposes tunable axes: client coverage $\gamma$ (0-100\%), perturbation scheduling (fixed-$\varepsilon$ vs $\varepsilon$-mixes), and optimization (fine-tune vs scratch), and distils the resulting $\gamma \times \varepsilon$ surface into two metrics: Accuracy-Robustness Area and Robustness Volume. On 15-client simulations with MNIST and Fashion-MNIST, IID and Non-IID conditions, training only 20-50\% clients adversarially boosts $\varepsilon \leq 0.1$ accuracy $\sim$15 pp at $< 2$ pp clean-accuracy cost; fine-tuning adds 3-5 pp. With $\geq$75\% coverage, a moderate $\varepsilon$-mix is optimal, while high-$\varepsilon$ schedules help only at 100\% coverage. Label-sorted non-IID splits halve robustness, underscoring data heterogeneity as a dominant risk.
CognitiveArm: Enabling Real-Time EEG-Controlled Prosthetic Arm Using Embodied Machine Learning
Aug 11, 2025



Efficient control of prosthetic limbs via non-invasive brain-computer interfaces (BCIs) requires advanced EEG processing, including pre-filtering, feature extraction, and action prediction, performed in real time on edge AI hardware. Achieving this on resource-constrained devices presents challenges in balancing model complexity, computational efficiency, and latency. We present CognitiveArm, an EEG-driven, brain-controlled prosthetic system implemented on embedded AI hardware, achieving real-time operation without compromising accuracy. The system integrates BrainFlow, an open-source library for EEG data acquisition and streaming, with optimized deep learning (DL) models for precise brain signal classification. Using evolutionary search, we identify Pareto-optimal DL configurations through hyperparameter tuning, optimizer analysis, and window selection, analyzed individually and in ensemble configurations. We apply model compression techniques such as pruning and quantization to optimize models for embedded deployment, balancing efficiency and accuracy. We collected an EEG dataset and designed an annotation pipeline enabling precise labeling of brain signals corresponding to specific intended actions, forming the basis for training our optimized DL models. CognitiveArm also supports voice commands for seamless mode switching, enabling control of the prosthetic arm's 3 degrees of freedom (DoF). Running entirely on embedded hardware, it ensures low latency and real-time responsiveness. A full-scale prototype, interfaced with the OpenBCI UltraCortex Mark IV EEG headset, achieved up to 90% accuracy in classifying three core actions (left, right, idle). Voice integration enables multiplexed, variable movement for everyday tasks (e.g., handshake, cup picking), enhancing real-world performance and demonstrating CognitiveArm's potential for advanced prosthetic control.
TESSER: Transfer-Enhancing Adversarial Attacks from Vision Transformers via Spectral and Semantic Regularization
May 26, 2025



Adversarial transferability remains a critical challenge in evaluating the robustness of deep neural networks. In security-critical applications, transferability enables black-box attacks without access to model internals, making it a key concern for real-world adversarial threat assessment. While Vision Transformers (ViTs) have demonstrated strong adversarial performance, existing attacks often fail to transfer effectively across architectures, especially from ViTs to Convolutional Neural Networks (CNNs) or hybrid models. In this paper, we introduce \textbf{TESSER} -- a novel adversarial attack framework that enhances transferability via two key strategies: (1) \textit{Feature-Sensitive Gradient Scaling (FSGS)}, which modulates gradients based on token-wise importance derived from intermediate feature activations, and (2) \textit{Spectral Smoothness Regularization (SSR)}, which suppresses high-frequency noise in perturbations using a differentiable Gaussian prior. These components work in tandem to generate perturbations that are both semantically meaningful and spectrally smooth. Extensive experiments on ImageNet across 12 diverse architectures demonstrate that TESSER achieves +10.9\% higher attack succes rate (ASR) on CNNs and +7.2\% on ViTs compared to the state-of-the-art Adaptive Token Tuning (ATT) method. Moreover, TESSER significantly improves robustness against defended models, achieving 53.55\% ASR on adversarially trained CNNs. Qualitative analysis shows strong alignment between TESSER's perturbations and salient visual regions identified via Grad-CAM, while frequency-domain analysis reveals a 12\% reduction in high-frequency energy, confirming the effectiveness of spectral regularization.
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.