 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
Jul 18, 2024



Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script. This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks. We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts. Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam's potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
WojoodNER 2024: The Second Arabic Named Entity Recognition Shared Task
Jul 13, 2024We present WojoodNER-2024, the second Arabic Named Entity Recognition (NER) Shared Task. In WojoodNER-2024, we focus on fine-grained Arabic NER. We provided participants with a new Arabic fine-grained NER dataset called wojoodfine, annotated with subtypes of entities. WojoodNER-2024 encompassed three subtasks: (i) Closed-Track Flat Fine-Grained NER, (ii) Closed-Track Nested Fine-Grained NER, and (iii) an Open-Track NER for the Israeli War on Gaza. A total of 43 unique teams registered for this shared task. Five teams participated in the Flat Fine-Grained Subtask, among which two teams tackled the Nested Fine-Grained Subtask and one team participated in the Open-Track NER Subtask. The winning teams achieved F-1 scores of 91% and 92% in the Flat Fine-Grained and Nested Fine-Grained Subtasks, respectively. The sole team in the Open-Track Subtask achieved an F-1 score of 73.7%.
Arabic Automatic Story Generation with Large Language Models
Jul 10, 2024


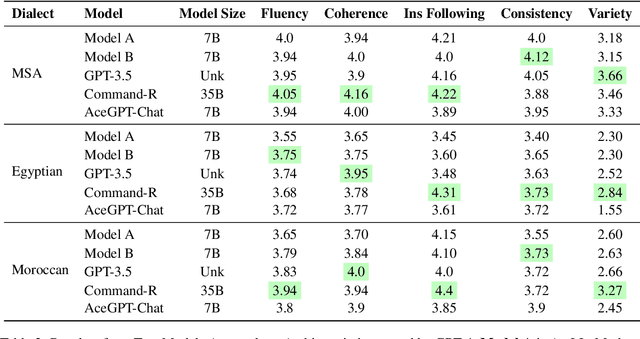
Large language models (LLMs) have recently emerged as a powerful tool for a wide range of language generation tasks. Nevertheless, this progress has been slower in Arabic. In this work, we focus on the task of generating stories from LLMs. For our training, we use stories acquired through machine translation (MT) as well as GPT-4. For the MT data, we develop a careful pipeline that ensures we acquire high-quality stories. For our GPT-41 data, we introduce crafted prompts that allow us to generate data well-suited to the Arabic context in both Modern Standard Arabic (MSA) and two Arabic dialects (Egyptian and Moroccan). For example, we generate stories tailored to various Arab countries on a wide host of topics. Our manual evaluation shows that our model fine-tuned on these training datasets can generate coherent stories that adhere to our instructions. We also conduct an extensive automatic and human evaluation comparing our models against state-of-the-art proprietary and open-source models. Our datasets and models will be made publicly available at https: //github.com/UBC-NLP/arastories.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Toucan: Many-to-Many Translation for 150 African Language Pairs
Jul 05, 2024We address a notable gap in Natural Language Processing (NLP) by introducing a collection of resources designed to improve Machine Translation (MT) for low-resource languages, with a specific focus on African languages. First, We introduce two language models (LMs), Cheetah-1.2B and Cheetah-3.7B, with 1.2 billion and 3.7 billion parameters respectively. Next, we finetune the aforementioned models to create toucan, an Afrocentric machine translation model designed to support 156 African language pairs. To evaluate Toucan, we carefully develop an extensive machine translation benchmark, dubbed AfroLingu-MT, tailored for evaluating machine translation. Toucan significantly outperforms other models, showcasing its remarkable performance on MT for African languages. Finally, we train a new model, spBLEU-1K, to enhance translation evaluation metrics, covering 1K languages, including 614 African languages. This work aims to advance the field of NLP, fostering cross-cultural understanding and knowledge exchange, particularly in regions with limited language resources such as Africa. The GitHub repository for the Toucan project is available at https://github.com/UBC-NLP/Toucan.
uDistil-Whisper: Label-Free Data Filtering for Knowledge Distillation via Large-Scale Pseudo Labelling
Jul 01, 2024Recent work on distilling Whisper's knowledge into small models using pseudo-labels shows promising performance while reducing the size by up to 50\%. This results in small, efficient, and dedicated models. However, a critical step of distillation from pseudo-labels involves filtering high-quality predictions and using only those during training. This step requires ground truth to compare and filter bad examples making the whole process supervised. In addition to that, the distillation process requires a large amount of data thereby limiting the ability to distil models in low-resource settings. To address this challenge, we propose an unsupervised or label-free framework for distillation, thus eliminating the requirement for labeled data altogether. Through experimentation, we show that our best distilled models outperform the teacher model by 5-7 points in terms of WER. Additionally, our models are on par with or better than similar supervised data filtering setup. When we scale the data, our models significantly outperform all zero-shot and supervised models. In this work, we demonstrate that it's possible to distill large Whisper models into relatively small models without using any labeled data. As a result, our distilled models are 25-50\% more compute and memory efficient while maintaining performance equal to or better than the teacher model.
Towards Zero-Shot Text-To-Speech for Arabic Dialects
Jun 25, 2024



Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTS\footnote{https://docs.coqui.ai/en/latest/models/xtts.html}\footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}\footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Jun 14, 2024



Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
To Distill or Not to Distill? On the Robustness of Robust Knowledge Distillation
Jun 06, 2024Arabic is known to present unique challenges for Automatic Speech Recognition (ASR). On one hand, its rich linguistic diversity and wide range of dialects complicate the development of robust, inclusive models. On the other, current multilingual ASR models are compute-intensive and lack proper comprehensive evaluations. In light of these challenges, we distill knowledge from large teacher models into smaller student variants that are more efficient. We also introduce a novel human-annotated dataset covering five under-represented Arabic dialects for evaluation. We further evaluate both our models and existing SoTA multilingual models on both standard available benchmarks and our new dialectal data. Our best-distilled model's overall performance ($45.0$\% WER) surpasses that of a SoTA model twice its size (SeamlessM4T-large-v2, WER=$47.0$\%) and its teacher model (Whisper-large-v2, WER=$55.1$\%), and its average performance on our new dialectal data ($56.9$\% WER) outperforms all other models. To gain more insight into the poor performance of these models on dialectal data, we conduct an error analysis and report the main types of errors the different models tend to make. The GitHub repository for the project is available at \url{https://github.com/UBC-NLP/distill-whisper-ar}.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.