 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIslamicMMLU: A Benchmark for Evaluating LLMs on Islamic Knowledge
Mar 24, 2026Large language models are increasingly consulted for Islamic knowledge, yet no comprehensive benchmark evaluates their performance across core Islamic disciplines. We introduce IslamicMMLU, a benchmark of 10,013 multiple-choice questions spanning three tracks: Quran (2,013 questions), Hadith (4,000 questions), and Fiqh (jurisprudence, 4,000 questions). Each track is formed of multiple types of questions to examine LLMs capabilities handling different aspects of Islamic knowledge. The benchmark is used to create the IslamicMMLU public leaderboard for evaluating LLMs, and we initially evaluate 26 LLMs, where their averaged accuracy across the three tracks varied between 39.8\% to 93.8\% (by Gemini 3 Flash). The Quran track shows the widest span (99.3\% to 32.4\%), while the Fiqh track includes a novel madhab (Islamic school of jurisprudence) bias detection task revealing variable school-of-thought preferences across models. Arabic-specific models show mixed results, but they all underperform compared to frontier models. The evaluation code and leaderboard are made publicly available.
Revisiting Common Assumptions about Arabic Dialects in NLP
May 27, 2025



Arabic has diverse dialects, where one dialect can be substantially different from the others. In the NLP literature, some assumptions about these dialects are widely adopted (e.g., ``Arabic dialects can be grouped into distinguishable regional dialects") and are manifested in different computational tasks such as Arabic Dialect Identification (ADI). However, these assumptions are not quantitatively verified. We identify four of these assumptions and examine them by extending and analyzing a multi-label dataset, where the validity of each sentence in 11 different country-level dialects is manually assessed by speakers of these dialects. Our analysis indicates that the four assumptions oversimplify reality, and some of them are not always accurate. This in turn might be hindering further progress in different Arabic NLP tasks.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Estimating the Level of Dialectness Predicts Interannotator Agreement in Multi-dialect Arabic Datasets
May 18, 2024


On annotating multi-dialect Arabic datasets, it is common to randomly assign the samples across a pool of native Arabic speakers. Recent analyses recommended routing dialectal samples to native speakers of their respective dialects to build higher-quality datasets. However, automatically identifying the dialect of samples is hard. Moreover, the pool of annotators who are native speakers of specific Arabic dialects might be scarce. Arabic Level of Dialectness (ALDi) was recently introduced as a quantitative variable that measures how sentences diverge from Standard Arabic. On randomly assigning samples to annotators, we hypothesize that samples of higher ALDi scores are harder to label especially if they are written in dialects that the annotators do not speak. We test this by analyzing the relation between ALDi scores and the annotators' agreement, on 15 public datasets having raw individual sample annotations for various sentence-classification tasks. We find strong evidence supporting our hypothesis for 11 of them. Consequently, we recommend prioritizing routing samples of high ALDi scores to native speakers of each sample's dialect, for which the dialect could be automatically identified at higher accuracies.
ALDi: Quantifying the Arabic Level of Dialectness of Text
Oct 20, 2023



Transcribed speech and user-generated text in Arabic typically contain a mixture of Modern Standard Arabic (MSA), the standardized language taught in schools, and Dialectal Arabic (DA), used in daily communications. To handle this variation, previous work in Arabic NLP has focused on Dialect Identification (DI) on the sentence or the token level. However, DI treats the task as binary, whereas we argue that Arabic speakers perceive a spectrum of dialectness, which we operationalize at the sentence level as the Arabic Level of Dialectness (ALDi), a continuous linguistic variable. We introduce the AOC-ALDi dataset (derived from the AOC dataset), containing 127,835 sentences (17% from news articles and 83% from user comments on those articles) which are manually labeled with their level of dialectness. We provide a detailed analysis of AOC-ALDi and show that a model trained on it can effectively identify levels of dialectness on a range of other corpora (including dialects and genres not included in AOC-ALDi), providing a more nuanced picture than traditional DI systems. Through case studies, we illustrate how ALDi can reveal Arabic speakers' stylistic choices in different situations, a useful property for sociolinguistic analyses.
Arabic Dialect Identification under Scrutiny: Limitations of Single-label Classification
Oct 20, 2023



Automatic Arabic Dialect Identification (ADI) of text has gained great popularity since it was introduced in the early 2010s. Multiple datasets were developed, and yearly shared tasks have been running since 2018. However, ADI systems are reported to fail in distinguishing between the micro-dialects of Arabic. We argue that the currently adopted framing of the ADI task as a single-label classification problem is one of the main reasons for that. We highlight the limitation of the incompleteness of the Dialect labels and demonstrate how it impacts the evaluation of ADI systems. A manual error analysis for the predictions of an ADI, performed by 7 native speakers of different Arabic dialects, revealed that $\approx$ 66% of the validated errors are not true errors. Consequently, we propose framing ADI as a multi-label classification task and give recommendations for designing new ADI datasets.
DLAMA: A Framework for Curating Culturally Diverse Facts for Probing the Knowledge of Pretrained Language Models
Jun 08, 2023



A few benchmarking datasets have been released to evaluate the factual knowledge of pretrained language models. These benchmarks (e.g., LAMA, and ParaRel) are mainly developed in English and later are translated to form new multilingual versions (e.g., mLAMA, and mParaRel). Results on these multilingual benchmarks suggest that using English prompts to recall the facts from multilingual models usually yields significantly better and more consistent performance than using non-English prompts. Our analysis shows that mLAMA is biased toward facts from Western countries, which might affect the fairness of probing models. We propose a new framework for curating factual triples from Wikidata that are culturally diverse. A new benchmark DLAMA-v1 is built of factual triples from three pairs of contrasting cultures having a total of 78,259 triples from 20 relation predicates. The three pairs comprise facts representing the (Arab and Western), (Asian and Western), and (South American and Western) countries respectively. Having a more balanced benchmark (DLAMA-v1) supports that mBERT performs better on Western facts than non-Western ones, while monolingual Arabic, English, and Korean models tend to perform better on their culturally proximate facts. Moreover, both monolingual and multilingual models tend to make a prediction that is culturally or geographically relevant to the correct label, even if the prediction is wrong.
AX-MABSA: A Framework for Extremely Weakly Supervised Multi-label Aspect Based Sentiment Analysis
Nov 07, 2022



Aspect Based Sentiment Analysis is a dominant research area with potential applications in social media analytics, business, finance, and health. Prior works in this area are primarily based on supervised methods, with a few techniques using weak supervision limited to predicting a single aspect category per review sentence. In this paper, we present an extremely weakly supervised multi-label Aspect Category Sentiment Analysis framework which does not use any labelled data. We only rely on a single word per class as an initial indicative information. We further propose an automatic word selection technique to choose these seed categories and sentiment words. We explore unsupervised language model post-training to improve the overall performance, and propose a multi-label generator model to generate multiple aspect category-sentiment pairs per review sentence. Experiments conducted on four benchmark datasets showcase our method to outperform other weakly supervised baselines by a significant margin.
Don't Take it Personally: Analyzing Gender and Age Differences in Ratings of Online Humor
Aug 23, 2022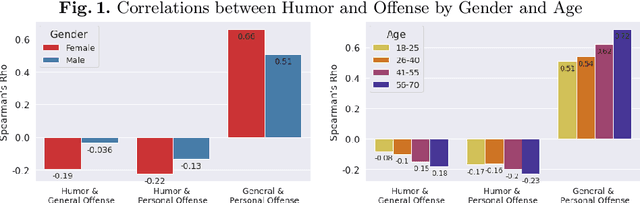

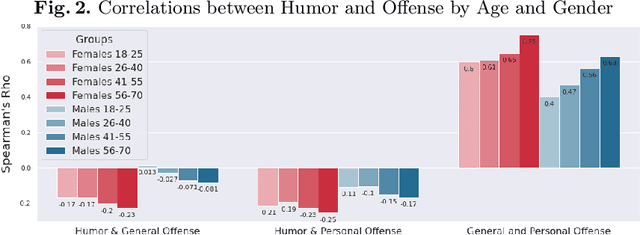

Computational humor detection systems rarely model the subjectivity of humor responses, or consider alternative reactions to humor - namely offense. We analyzed a large dataset of humor and offense ratings by male and female annotators of different age groups. We find that women link these two concepts more strongly than men, and they tend to give lower humor ratings and higher offense scores. We also find that the correlation between humor and offense increases with age. Although there were no gender or age differences in humor detection, women and older annotators signalled that they did not understand joke texts more often than men. We discuss implications for computational humor detection and downstream tasks.
Black or White but never neutral: How readers perceive identity from yellow or skin-toned emoji
May 12, 2021Research in sociology and linguistics shows that people use language not only to express their own identity but to understand the identity of others. Recent work established a connection between expression of identity and emoji usage on social media, through use of emoji skin tone modifiers. Motivated by that finding, this work asks if, as with language, readers are sensitive to such acts of self-expression and use them to understand the identity of authors. In behavioral experiments (n=488), where text and emoji content of social media posts were carefully controlled before being presented to participants, we find in the affirmative -- emoji are a salient signal of author identity. That signal is distinct from, and complementary to, the one encoded in language. Participant groups (based on self-identified ethnicity) showed no differences in how they perceive this signal, except in the case of the default yellow emoji. While both groups associate this with a White identity, the effect was stronger in White participants. Our finding that emoji can index social variables will have experimental applications for researchers but also implications for designers: supposedly ``neutral`` defaults may be more representative of some users than others.