 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriLens: Semantic Retrieval in Agricultural Texts Using Topic Modeling and Language Models
Jan 13, 2026As the volume of unstructured text continues to grow across domains, there is an urgent need for scalable methods that enable interpretable organization, summarization, and retrieval of information. This work presents a unified framework for interpretable topic modeling, zero-shot topic labeling, and topic-guided semantic retrieval over large agricultural text corpora. Leveraging BERTopic, we extract semantically coherent topics. Each topic is converted into a structured prompt, enabling a language model to generate meaningful topic labels and summaries in a zero-shot manner. Querying and document exploration are supported via dense embeddings and vector search, while a dedicated evaluation module assesses topical coherence and bias. This framework supports scalable and interpretable information access in specialized domains where labeled data is limited.
Stacked ensemble\-based mutagenicity prediction model using multiple modalities with graph attention network
Sep 04, 2024



Mutagenicity is a concern due to its association with genetic mutations which can result in a variety of negative consequences, including the development of cancer. Earlier identification of mutagenic compounds in the drug development process is therefore crucial for preventing the progression of unsafe candidates and reducing development costs. While computational techniques, especially machine learning models have become increasingly prevalent for this endpoint, they rely on a single modality. In this work, we introduce a novel stacked ensemble based mutagenicity prediction model which incorporate multiple modalities such as simplified molecular input line entry system (SMILES) and molecular graph. These modalities capture diverse information about molecules such as substructural, physicochemical, geometrical and topological. To derive substructural, geometrical and physicochemical information, we use SMILES, while topological information is extracted through a graph attention network (GAT) via molecular graph. Our model uses a stacked ensemble of machine learning classifiers to make predictions using these multiple features. We employ the explainable artificial intelligence (XAI) technique SHAP (Shapley Additive Explanations) to determine the significance of each classifier and the most relevant features in the prediction. We demonstrate that our method surpasses SOTA methods on two standard datasets across various metrics. Notably, we achieve an area under the curve of 95.21\% on the Hansen benchmark dataset, affirming the efficacy of our method in predicting mutagenicity. We believe that this research will captivate the interest of both clinicians and computational biologists engaged in translational research.
Advancements in Molecular Property Prediction: A Survey of Single and Multimodal Approaches
Aug 22, 2024



Molecular Property Prediction (MPP) plays a pivotal role across diverse domains, spanning drug discovery, material science, and environmental chemistry. Fueled by the exponential growth of chemical data and the evolution of artificial intelligence, recent years have witnessed remarkable strides in MPP. However, the multifaceted nature of molecular data, such as molecular structures, SMILES notation, and molecular images, continues to pose a fundamental challenge in its effective representation. To address this, representation learning techniques are instrumental as they acquire informative and interpretable representations of molecular data. This article explores recent AI/-based approaches in MPP, focusing on both single and multiple modality representation techniques. It provides an overview of various molecule representations and encoding schemes, categorizes MPP methods by their use of modalities, and outlines datasets and tools available for feature generation. The article also analyzes the performance of recent methods and suggests future research directions to advance the field of MPP.
Exploring learning environments for label\-efficient cancer diagnosis
Aug 15, 2024



Despite significant research efforts and advancements, cancer remains a leading cause of mortality. Early cancer prediction has become a crucial focus in cancer research to streamline patient care and improve treatment outcomes. Manual tumor detection by histopathologists can be time consuming, prompting the need for computerized methods to expedite treatment planning. Traditional approaches to tumor detection rely on supervised learning, necessitates a large amount of annotated data for model training. However, acquiring such extensive labeled data can be laborious and time\-intensive. This research examines the three learning environments: supervised learning (SL), semi\-supervised learning (Semi\-SL), and self\-supervised learning (Self\-SL): to predict kidney, lung, and breast cancer. Three pre\-trained deep learning models (Residual Network\-50, Visual Geometry Group\-16, and EfficientNetB0) are evaluated based on these learning settings using seven carefully curated training sets. To create the first training set (TS1), SL is applied to all annotated image samples. Five training sets (TS2\-TS6) with different ratios of labeled and unlabeled cancer images are used to evaluateSemi\-SL. Unlabeled cancer images from the final training set (TS7) are utilized for Self\-SL assessment. Among different learning environments, outcomes from the Semi\-SL setting show a strong degree of agreement with the outcomes achieved in the SL setting. The uniform pattern of observations from the pre\-trained models across all three datasets validates the methodology and techniques of the research. Based on modest number of labeled samples and minimal computing cost, our study suggests that the Semi\-SL option can be a highly viable replacement for the SL option under label annotation constraint scenarios.
JMI at SemEval 2024 Task 3: Two-step approach for multimodal ECAC using in-context learning with GPT and instruction-tuned Llama models
Mar 05, 2024This paper presents our system development for SemEval-2024 Task 3: "The Competition of Multimodal Emotion Cause Analysis in Conversations". Effectively capturing emotions in human conversations requires integrating multiple modalities such as text, audio, and video. However, the complexities of these diverse modalities pose challenges for developing an efficient multimodal emotion cause analysis (ECA) system. Our proposed approach addresses these challenges by a two-step framework. We adopt two different approaches in our implementation. In Approach 1, we employ instruction-tuning with two separate Llama 2 models for emotion and cause prediction. In Approach 2, we use GPT-4V for conversation-level video description and employ in-context learning with annotated conversation using GPT 3.5. Our system wins rank 4, and system ablation experiments demonstrate that our proposed solutions achieve significant performance gains. All the experimental codes are available on Github.
InterPrompt: Interpretable Prompting for Interrelated Interpersonal Risk Factors in Reddit Posts
Nov 21, 2023



Mental health professionals and clinicians have observed the upsurge of mental disorders due to Interpersonal Risk Factors (IRFs). To simulate the human-in-the-loop triaging scenario for early detection of mental health disorders, we recognized textual indications to ascertain these IRFs : Thwarted Belongingness (TBe) and Perceived Burdensomeness (PBu) within personal narratives. In light of this, we use N-shot learning with GPT-3 model on the IRF dataset, and underscored the importance of fine-tuning GPT-3 model to incorporate the context-specific sensitivity and the interconnectedness of textual cues that represent both IRFs. In this paper, we introduce an Interpretable Prompting (InterPrompt)} method to boost the attention mechanism by fine-tuning the GPT-3 model. This allows a more sophisticated level of language modification by adjusting the pre-trained weights. Our model learns to detect usual patterns and underlying connections across both the IRFs, which leads to better system-level explainability and trustworthiness. The results of our research demonstrate that all four variants of GPT-3 model, when fine-tuned with InterPrompt, perform considerably better as compared to the baseline methods, both in terms of classification and explanation generation.
LonXplain: Lonesomeness as a Consequence of Mental Disturbance in Reddit Posts
May 30, 2023



Social media is a potential source of information that infers latent mental states through Natural Language Processing (NLP). While narrating real-life experiences, social media users convey their feeling of loneliness or isolated lifestyle, impacting their mental well-being. Existing literature on psychological theories points to loneliness as the major consequence of interpersonal risk factors, propounding the need to investigate loneliness as a major aspect of mental disturbance. We formulate lonesomeness detection in social media posts as an explainable binary classification problem, discovering the users at-risk, suggesting the need of resilience for early control. To the best of our knowledge, there is no existing explainable dataset, i.e., one with human-readable, annotated text spans, to facilitate further research and development in loneliness detection causing mental disturbance. In this work, three experts: a senior clinical psychologist, a rehabilitation counselor, and a social NLP researcher define annotation schemes and perplexity guidelines to mark the presence or absence of lonesomeness, along with the marking of text-spans in original posts as explanation, in 3,521 Reddit posts. We expect the public release of our dataset, LonXplain, and traditional classifiers as baselines via GitHub.
NLP as a Lens for Causal Analysis and Perception Mining to Infer Mental Health on Social Media
Feb 01, 2023



Interactions among humans on social media often convey intentions behind their actions, yielding a psychological language resource for Mental Health Analysis (MHA) of online users. The success of Computational Intelligence Techniques (CIT) for inferring mental illness from such social media resources points to NLP as a lens for causal analysis and perception mining. However, we argue that more consequential and explainable research is required for optimal impact on clinical psychology practice and personalized mental healthcare. To bridge this gap, we posit two significant dimensions: (1) Causal analysis to illustrate a cause and effect relationship in the user generated text; (2) Perception mining to infer psychological perspectives of social effects on online users intentions. Within the scope of Natural Language Processing (NLP), we further explore critical areas of inquiry associated with these two dimensions, specifically through recent advancements in discourse analysis. This position paper guides the community to explore solutions in this space and advance the state of practice in developing conversational agents for inferring mental health from social media. We advocate for a more explainable approach toward modeling computational psychology problems through the lens of language as we observe an increased number of research contributions in dataset and problem formulation for causal relation extraction and perception enhancements while inferring mental states.
Causal Categorization of Mental Health Posts using Transformers
Jan 16, 2023


With recent developments in digitization of clinical psychology, NLP research community has revolutionized the field of mental health detection on social media. Existing research in mental health analysis revolves around the cross-sectional studies to classify users' intent on social media. For in-depth analysis, we investigate existing classifiers to solve the problem of causal categorization which suggests the inefficiency of learning based methods due to limited training samples. To handle this challenge, we use transformer models and demonstrate the efficacy of a pre-trained transfer learning on "CAMS" dataset. The experimental result improves the accuracy and depicts the importance of identifying cause-and-effect relationships in the underlying text.
Explainable Causal Analysis of Mental Health on Social Media Data
Oct 16, 2022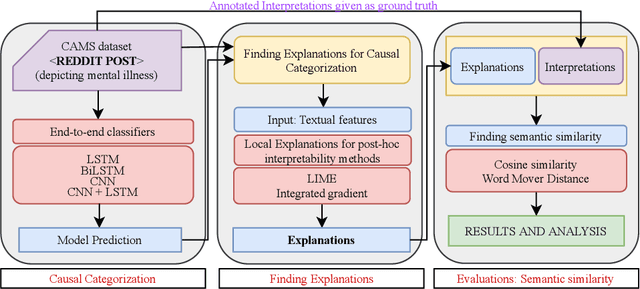

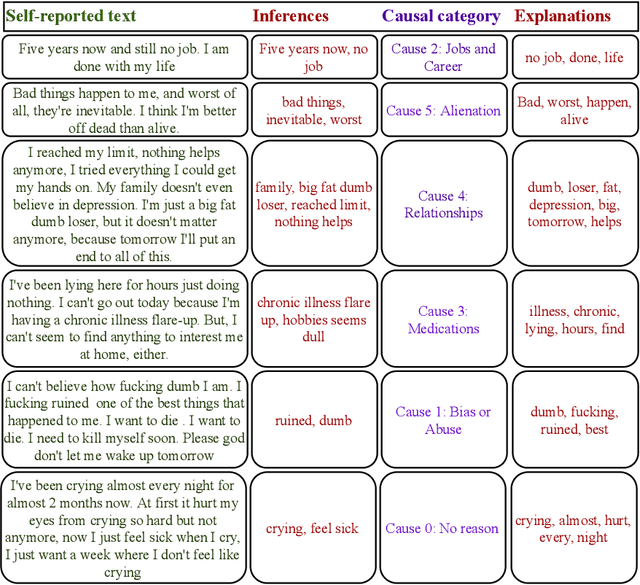
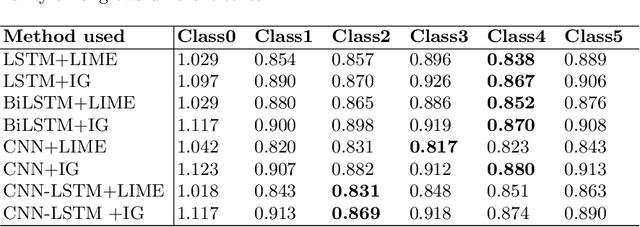
With recent developments in Social Computing, Natural Language Processing and Clinical Psychology, the social NLP research community addresses the challenge of automation in mental illness on social media. A recent extension to the problem of multi-class classification of mental health issues is to identify the cause behind the user's intention. However, multi-class causal categorization for mental health issues on social media has a major challenge of wrong prediction due to the overlapping problem of causal explanations. There are two possible mitigation techniques to solve this problem: (i) Inconsistency among causal explanations/ inappropriate human-annotated inferences in the dataset, (ii) in-depth analysis of arguments and stances in self-reported text using discourse analysis. In this research work, we hypothesise that if there exists the inconsistency among F1 scores of different classes, there must be inconsistency among corresponding causal explanations as well. In this task, we fine tune the classifiers and find explanations for multi-class causal categorization of mental illness on social media with LIME and Integrated Gradient (IG) methods. We test our methods with CAMS dataset and validate with annotated interpretations. A key contribution of this research work is to find the reason behind inconsistency in accuracy of multi-class causal categorization. The effectiveness of our methods is evident with the results obtained having category-wise average scores of $81.29 \%$ and $0.906$ using cosine similarity and word mover's distance, respectively.