 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
FSViewFusion: Few-Shots View Generation of Novel Objects
Mar 13, 2024



Novel view synthesis has observed tremendous developments since the arrival of NeRFs. However, Nerf models overfit on a single scene, lacking generalization to out of distribution objects. Recently, diffusion models have exhibited remarkable performance on introducing generalization in view synthesis. Inspired by these advancements, we explore the capabilities of a pretrained stable diffusion model for view synthesis without explicit 3D priors. Specifically, we base our method on a personalized text to image model, Dreambooth, given its strong ability to adapt to specific novel objects with a few shots. Our research reveals two interesting findings. First, we observe that Dreambooth can learn the high level concept of a view, compared to arguably more complex strategies which involve finetuning diffusions on large amounts of multi-view data. Second, we establish that the concept of a view can be disentangled and transferred to a novel object irrespective of the original object's identify from which the views are learnt. Motivated by this, we introduce a learning strategy, FSViewFusion, which inherits a specific view through only one image sample of a single scene, and transfers the knowledge to a novel object, learnt from few shots, using low rank adapters. Through extensive experiments we demonstrate that our method, albeit simple, is efficient in generating reliable view samples for in the wild images. Code and models will be released.
CodaMal: Contrastive Domain Adaptation for Malaria Detection in Low-Cost Microscopes
Feb 16, 2024



Malaria is a major health issue worldwide, and its diagnosis requires scalable solutions that can work effectively with low-cost microscopes (LCM). Deep learning-based methods have shown success in computer-aided diagnosis from microscopic images. However, these methods need annotated images that show cells affected by malaria parasites and their life stages. Annotating images from LCM significantly increases the burden on medical experts compared to annotating images from high-cost microscopes (HCM). For this reason, a practical solution would be trained on HCM images which should generalize well on LCM images during testing. While earlier methods adopted a multi-stage learning process, they did not offer an end-to-end approach. In this work, we present an end-to-end learning framework, named CodaMal (Contrastive Domain Adpation for Malaria). In order to bridge the gap between HCM (training) and LCM (testing), we propose a domain adaptive contrastive loss. It reduces the domain shift by promoting similarity between the representations of HCM and its corresponding LCM image, without imposing an additional annotation burden. In addition, the training objective includes object detection objectives with carefully designed augmentations, ensuring the accurate detection of malaria parasites. On the publicly available large-scale M5-dataset, our proposed method shows a significant improvement of 16% over the state-of-the-art methods in terms of the mean average precision metric (mAP), provides 21x speed up during inference, and requires only half learnable parameters than the prior methods. Our code is publicly available.
No More Shortcuts: Realizing the Potential of Temporal Self-Supervision
Dec 20, 2023Self-supervised approaches for video have shown impressive results in video understanding tasks. However, unlike early works that leverage temporal self-supervision, current state-of-the-art methods primarily rely on tasks from the image domain (e.g., contrastive learning) that do not explicitly promote the learning of temporal features. We identify two factors that limit existing temporal self-supervision: 1) tasks are too simple, resulting in saturated training performance, and 2) we uncover shortcuts based on local appearance statistics that hinder the learning of high-level features. To address these issues, we propose 1) a more challenging reformulation of temporal self-supervision as frame-level (rather than clip-level) recognition tasks and 2) an effective augmentation strategy to mitigate shortcuts. Our model extends a representation of single video frames, pre-trained through contrastive learning, with a transformer that we train through temporal self-supervision. We demonstrate experimentally that our more challenging frame-level task formulations and the removal of shortcuts drastically improve the quality of features learned through temporal self-supervision. The generalization capability of our self-supervised video method is evidenced by its state-of-the-art performance in a wide range of high-level semantic tasks, including video retrieval, action classification, and video attribute recognition (such as object and scene identification), as well as low-level temporal correspondence tasks like video object segmentation and pose tracking. Additionally, we show that the video representations learned through our method exhibit increased robustness to the input perturbations.
DVANet: Disentangling View and Action Features for Multi-View Action Recognition
Dec 10, 2023In this work, we present a novel approach to multi-view action recognition where we guide learned action representations to be separated from view-relevant information in a video. When trying to classify action instances captured from multiple viewpoints, there is a higher degree of difficulty due to the difference in background, occlusion, and visibility of the captured action from different camera angles. To tackle the various problems introduced in multi-view action recognition, we propose a novel configuration of learnable transformer decoder queries, in conjunction with two supervised contrastive losses, to enforce the learning of action features that are robust to shifts in viewpoints. Our disentangled feature learning occurs in two stages: the transformer decoder uses separate queries to separately learn action and view information, which are then further disentangled using our two contrastive losses. We show that our model and method of training significantly outperforms all other uni-modal models on four multi-view action recognition datasets: NTU RGB+D, NTU RGB+D 120, PKU-MMD, and N-UCLA. Compared to previous RGB works, we see maximal improvements of 1.5\%, 4.8\%, 2.2\%, and 4.8\% on each dataset, respectively.
Multiview Aerial Visual Recognition (MAVREC): Can Multi-view Improve Aerial Visual Perception?
Dec 07, 2023



Despite the commercial abundance of UAVs, aerial data acquisition remains challenging, and the existing Asia and North America-centric open-source UAV datasets are small-scale or low-resolution and lack diversity in scene contextuality. Additionally, the color content of the scenes, solar-zenith angle, and population density of different geographies influence the data diversity. These two factors conjointly render suboptimal aerial-visual perception of the deep neural network (DNN) models trained primarily on the ground-view data, including the open-world foundational models. To pave the way for a transformative era of aerial detection, we present Multiview Aerial Visual RECognition or MAVREC, a video dataset where we record synchronized scenes from different perspectives -- ground camera and drone-mounted camera. MAVREC consists of around 2.5 hours of industry-standard 2.7K resolution video sequences, more than 0.5 million frames, and 1.1 million annotated bounding boxes. This makes MAVREC the largest ground and aerial-view dataset, and the fourth largest among all drone-based datasets across all modalities and tasks. Through our extensive benchmarking on MAVREC, we recognize that augmenting object detectors with ground-view images from the corresponding geographical location is a superior pre-training strategy for aerial detection. Building on this strategy, we benchmark MAVREC with a curriculum-based semi-supervised object detection approach that leverages labeled (ground and aerial) and unlabeled (only aerial) images to enhance the aerial detection. We publicly release the MAVREC dataset: https://mavrec.github.io.
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
Nov 22, 2023Extending image-based Large Multimodal Models (LMM) to videos is challenging due to the inherent complexity of video data. The recent approaches extending image-based LMM to videos either lack the grounding capabilities (e.g., VideoChat, Video-ChatGPT, Video-LLaMA) or do not utilize the audio-signals for better video understanding (e.g., Video-ChatGPT). Addressing these gaps, we propose Video-LLaVA, the first LMM with pixel-level grounding capability, integrating audio cues by transcribing them into text to enrich video-context understanding. Our framework uses an off-the-shelf tracker and a novel grounding module, enabling it to spatially and temporally localize objects in videos following user instructions. We evaluate Video-LLaVA using video-based generative and question-answering benchmarks and introduce new benchmarks specifically designed to measure prompt-based object grounding performance in videos. Further, we propose the use of Vicuna over GPT-3.5, as utilized in Video-ChatGPT, for video-based conversation benchmarking, ensuring reproducibility of results which is a concern with the proprietary nature of GPT-3.5. Our framework builds on SoTA image-based LLaVA model and extends its advantages to the video domain, delivering promising gains on video-based conversation and grounding tasks. Project Page: https://github.com/mbzuai-oryx/Video-LLaVA
Videoprompter: an ensemble of foundational models for zero-shot video understanding
Oct 23, 2023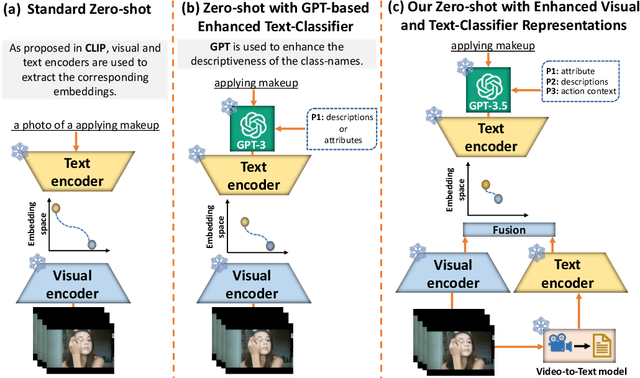


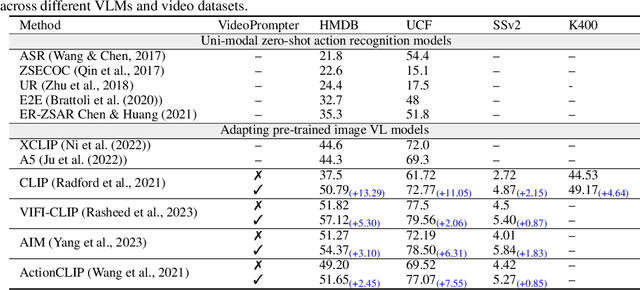
Vision-language models (VLMs) classify the query video by calculating a similarity score between the visual features and text-based class label representations. Recently, large language models (LLMs) have been used to enrich the text-based class labels by enhancing the descriptiveness of the class names. However, these improvements are restricted to the text-based classifier only, and the query visual features are not considered. In this paper, we propose a framework which combines pre-trained discriminative VLMs with pre-trained generative video-to-text and text-to-text models. We introduce two key modifications to the standard zero-shot setting. First, we propose language-guided visual feature enhancement and employ a video-to-text model to convert the query video to its descriptive form. The resulting descriptions contain vital visual cues of the query video, such as what objects are present and their spatio-temporal interactions. These descriptive cues provide additional semantic knowledge to VLMs to enhance their zeroshot performance. Second, we propose video-specific prompts to LLMs to generate more meaningful descriptions to enrich class label representations. Specifically, we introduce prompt techniques to create a Tree Hierarchy of Categories for class names, offering a higher-level action context for additional visual cues, We demonstrate the effectiveness of our approach in video understanding across three different zero-shot settings: 1) video action recognition, 2) video-to-text and textto-video retrieval, and 3) time-sensitive video tasks. Consistent improvements across multiple benchmarks and with various VLMs demonstrate the effectiveness of our proposed framework. Our code will be made publicly available.
GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization
Sep 27, 2023



Worldwide Geo-localization aims to pinpoint the precise location of images taken anywhere on Earth. This task has considerable challenges due to immense variation in geographic landscapes. The image-to-image retrieval-based approaches fail to solve this problem on a global scale as it is not feasible to construct a large gallery of images covering the entire world. Instead, existing approaches divide the globe into discrete geographic cells, transforming the problem into a classification task. However, their performance is limited by the predefined classes and often results in inaccurate localizations when an image's location significantly deviates from its class center. To overcome these limitations, we propose GeoCLIP, a novel CLIP-inspired Image-to-GPS retrieval approach that enforces alignment between the image and its corresponding GPS locations. GeoCLIP's location encoder models the Earth as a continuous function by employing positional encoding through random Fourier features and constructing a hierarchical representation that captures information at varying resolutions to yield a semantically rich high-dimensional feature suitable to use even beyond geo-localization. To the best of our knowledge, this is the first work employing GPS encoding for geo-localization. We demonstrate the efficacy of our method via extensive experiments and ablations on benchmark datasets. We achieve competitive performance with just 20% of training data, highlighting its effectiveness even in limited-data settings. Furthermore, we qualitatively demonstrate geo-localization using a text query by leveraging CLIP backbone of our image encoder.
Egocentric RGB+Depth Action Recognition in Industry-Like Settings
Sep 25, 2023



Action recognition from an egocentric viewpoint is a crucial perception task in robotics and enables a wide range of human-robot interactions. While most computer vision approaches prioritize the RGB camera, the Depth modality - which can further amplify the subtleties of actions from an egocentric perspective - remains underexplored. Our work focuses on recognizing actions from egocentric RGB and Depth modalities in an industry-like environment. To study this problem, we consider the recent MECCANO dataset, which provides a wide range of assembling actions. Our framework is based on the 3D Video SWIN Transformer to encode both RGB and Depth modalities effectively. To address the inherent skewness in real-world multimodal action occurrences, we propose a training strategy using an exponentially decaying variant of the focal loss modulating factor. Additionally, to leverage the information in both RGB and Depth modalities, we opt for late fusion to combine the predictions from each modality. We thoroughly evaluate our method on the action recognition task of the MECCANO dataset, and it significantly outperforms the prior work. Notably, our method also secured first place at the multimodal action recognition challenge at ICIAP 2023.