 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
Nov 22, 2023Extending image-based Large Multimodal Models (LMM) to videos is challenging due to the inherent complexity of video data. The recent approaches extending image-based LMM to videos either lack the grounding capabilities (e.g., VideoChat, Video-ChatGPT, Video-LLaMA) or do not utilize the audio-signals for better video understanding (e.g., Video-ChatGPT). Addressing these gaps, we propose Video-LLaVA, the first LMM with pixel-level grounding capability, integrating audio cues by transcribing them into text to enrich video-context understanding. Our framework uses an off-the-shelf tracker and a novel grounding module, enabling it to spatially and temporally localize objects in videos following user instructions. We evaluate Video-LLaVA using video-based generative and question-answering benchmarks and introduce new benchmarks specifically designed to measure prompt-based object grounding performance in videos. Further, we propose the use of Vicuna over GPT-3.5, as utilized in Video-ChatGPT, for video-based conversation benchmarking, ensuring reproducibility of results which is a concern with the proprietary nature of GPT-3.5. Our framework builds on SoTA image-based LLaVA model and extends its advantages to the video domain, delivering promising gains on video-based conversation and grounding tasks. Project Page: https://github.com/mbzuai-oryx/Video-LLaVA
Self-Supervised Learning for Fine-Grained Visual Categorization
May 18, 2021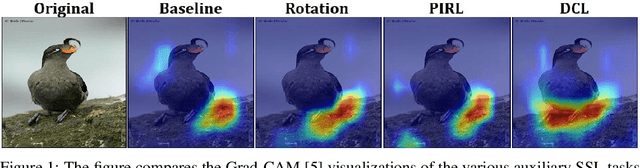

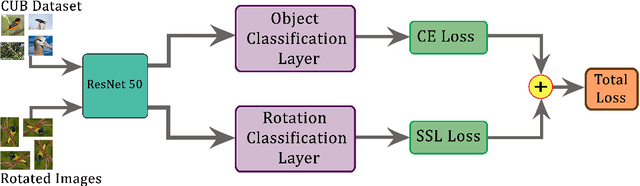
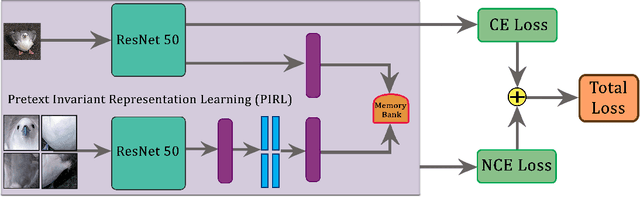
Recent research in self-supervised learning (SSL) has shown its capability in learning useful semantic representations from images for classification tasks. Through our work, we study the usefulness of SSL for Fine-Grained Visual Categorization (FGVC). FGVC aims to distinguish objects of visually similar sub categories within a general category. The small inter-class, but large intra-class variations within the dataset makes it a challenging task. The limited availability of annotated labels for such a fine-grained data encourages the need for SSL, where additional supervision can boost learning without the cost of extra annotations. Our baseline achieves $86.36\%$ top-1 classification accuracy on CUB-200-2011 dataset by utilizing random crop augmentation during training and center crop augmentation during testing. In this work, we explore the usefulness of various pretext tasks, specifically, rotation, pretext invariant representation learning (PIRL), and deconstruction and construction learning (DCL) for FGVC. Rotation as an auxiliary task promotes the model to learn global features, and diverts it from focusing on the subtle details. PIRL that uses jigsaw patches attempts to focus on discriminative local regions, but struggles to accurately localize them. DCL helps in learning local discriminating features and outperforms the baseline by achieving $87.41\%$ top-1 accuracy. The deconstruction learning forces the model to focus on local object parts, while reconstruction learning helps in learning the correlation between the parts. We perform extensive experiments to reason our findings. Our code is available at https://github.com/mmaaz60/ssl_for_fgvc.