 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-Based Attention Guided Bottom-Up Approach for Video Instance Segmentation
Apr 22, 2022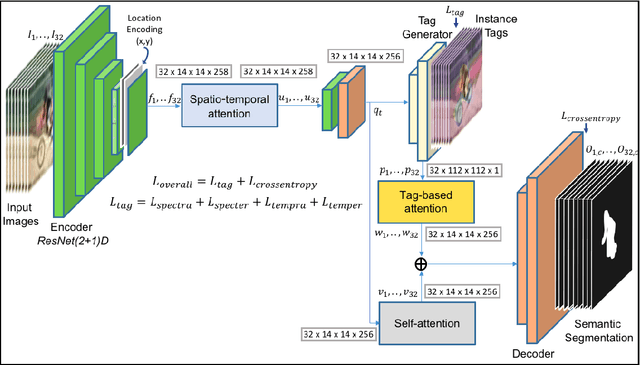
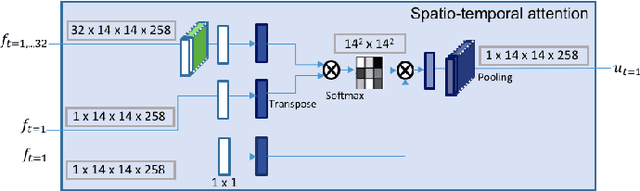
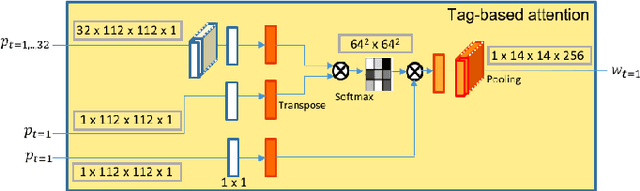
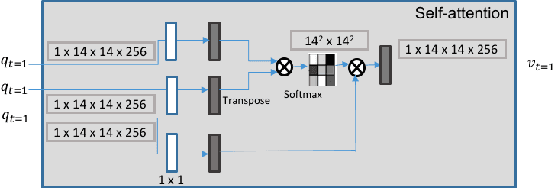
Video Instance Segmentation is a fundamental computer vision task that deals with segmenting and tracking object instances across a video sequence. Most existing methods typically accomplish this task by employing a multi-stage top-down approach that usually involves separate networks to detect and segment objects in each frame, followed by associating these detections in consecutive frames using a learned tracking head. In this work, however, we introduce a simple end-to-end trainable bottom-up approach to achieve instance mask predictions at the pixel-level granularity, instead of the typical region-proposals-based approach. Unlike contemporary frame-based models, our network pipeline processes an input video clip as a single 3D volume to incorporate temporal information. The central idea of our formulation is to solve the video instance segmentation task as a tag assignment problem, such that generating distinct tag values essentially separates individual object instances across the video sequence (here each tag could be any arbitrary value between 0 and 1). To this end, we propose a novel spatio-temporal tagging loss that allows for sufficient separation of different objects as well as necessary identification of different instances of the same object. Furthermore, we present a tag-based attention module that improves instance tags, while concurrently learning instance propagation within a video. Evaluations demonstrate that our method provides competitive results on YouTube-VIS and DAVIS-19 datasets, and has minimum run-time compared to other state-of-the-art performance methods.
Video Action Detection: Analysing Limitations and Challenges
Apr 17, 2022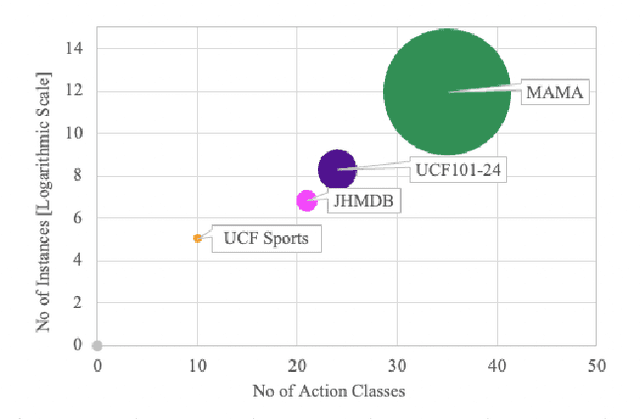
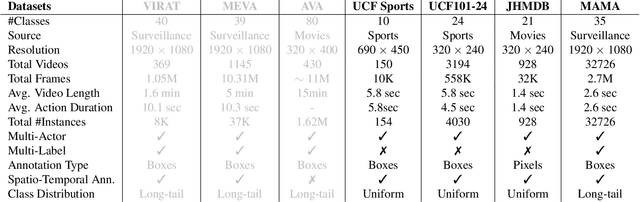

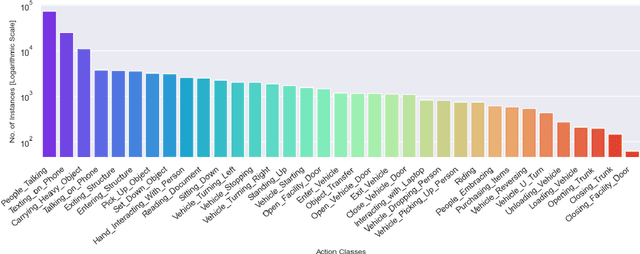
Beyond possessing large enough size to feed data hungry machines (eg, transformers), what attributes measure the quality of a dataset? Assuming that the definitions of such attributes do exist, how do we quantify among their relative existences? Our work attempts to explore these questions for video action detection. The task aims to spatio-temporally localize an actor and assign a relevant action class. We first analyze the existing datasets on video action detection and discuss their limitations. Next, we propose a new dataset, Multi Actor Multi Action (MAMA) which overcomes these limitations and is more suitable for real world applications. In addition, we perform a biasness study which analyzes a key property differentiating videos from static images: the temporal aspect. This reveals if the actions in these datasets really need the motion information of an actor, or whether they predict the occurrence of an action even by looking at a single frame. Finally, we investigate the widely held assumptions on the importance of temporal ordering: is temporal ordering important for detecting these actions? Such extreme experiments show existence of biases which have managed to creep into existing methods inspite of careful modeling.
PSTR: End-to-End One-Step Person Search With Transformers
Apr 07, 2022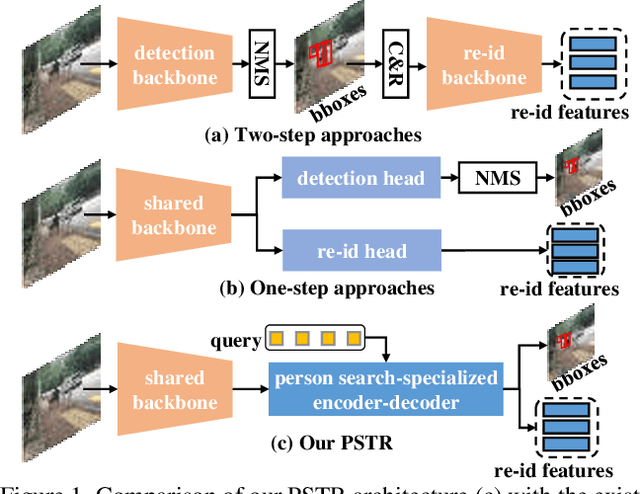
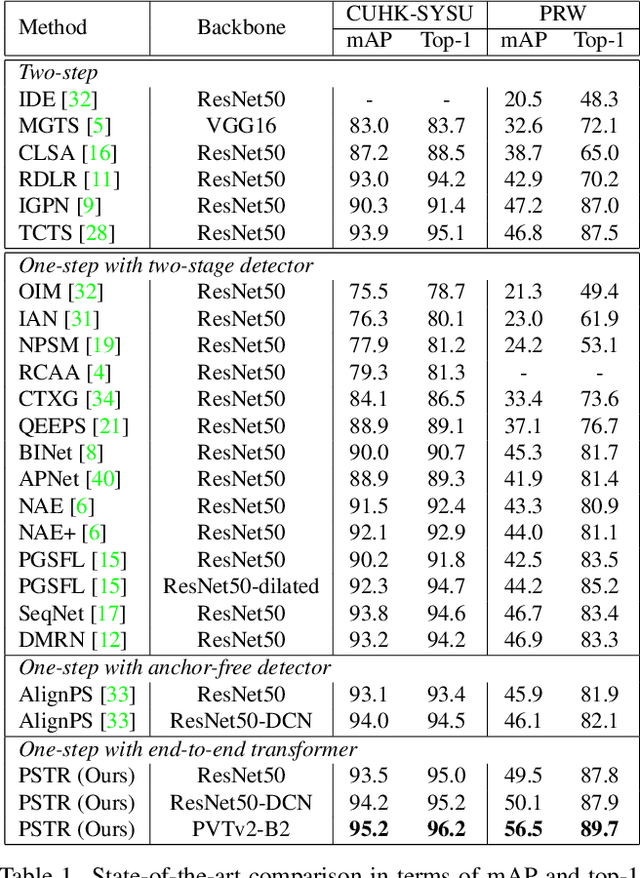
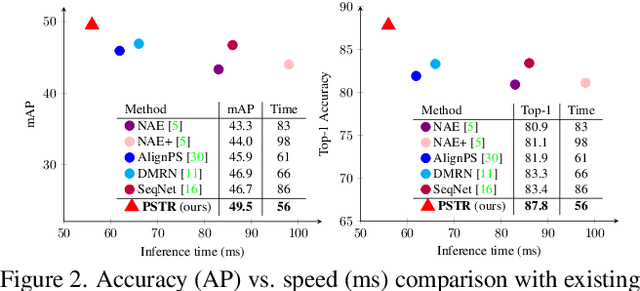
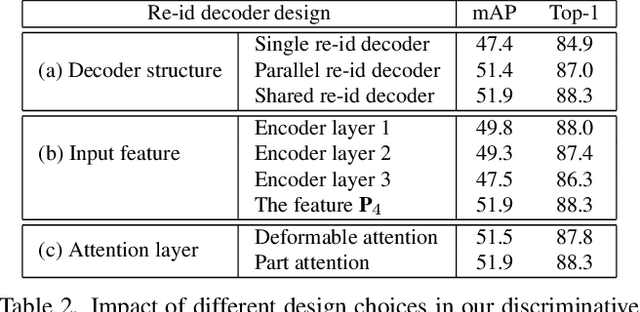
We propose a novel one-step transformer-based person search framework, PSTR, that jointly performs person detection and re-identification (re-id) in a single architecture. PSTR comprises a person search-specialized (PSS) module that contains a detection encoder-decoder for person detection along with a discriminative re-id decoder for person re-id. The discriminative re-id decoder utilizes a multi-level supervision scheme with a shared decoder for discriminative re-id feature learning and also comprises a part attention block to encode relationship between different parts of a person. We further introduce a simple multi-scale scheme to support re-id across person instances at different scales. PSTR jointly achieves the diverse objectives of object-level recognition (detection) and instance-level matching (re-id). To the best of our knowledge, we are the first to propose an end-to-end one-step transformer-based person search framework. Experiments are performed on two popular benchmarks: CUHK-SYSU and PRW. Our extensive ablations reveal the merits of the proposed contributions. Further, the proposed PSTR sets a new state-of-the-art on both benchmarks. On the challenging PRW benchmark, PSTR achieves a mean average precision (mAP) score of 56.5%. The source code is available at \url{https://github.com/JialeCao001/PSTR}.
UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning
Apr 05, 2022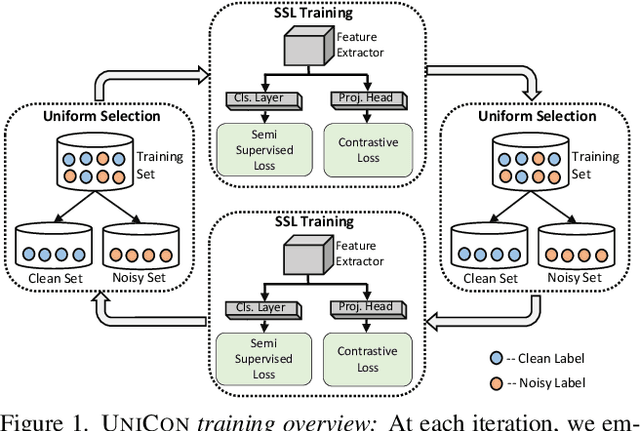

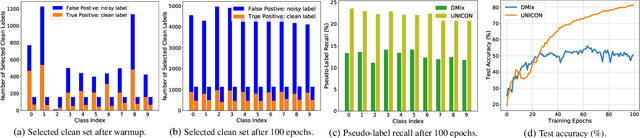
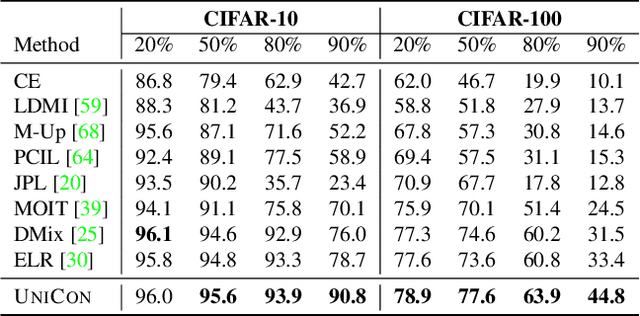
Supervised deep learning methods require a large repository of annotated data; hence, label noise is inevitable. Training with such noisy data negatively impacts the generalization performance of deep neural networks. To combat label noise, recent state-of-the-art methods employ some sort of sample selection mechanism to select a possibly clean subset of data. Next, an off-the-shelf semi-supervised learning method is used for training where rejected samples are treated as unlabeled data. Our comprehensive analysis shows that current selection methods disproportionately select samples from easy (fast learnable) classes while rejecting those from relatively harder ones. This creates class imbalance in the selected clean set and in turn, deteriorates performance under high label noise. In this work, we propose UNICON, a simple yet effective sample selection method which is robust to high label noise. To address the disproportionate selection of easy and hard samples, we introduce a Jensen-Shannon divergence based uniform selection mechanism which does not require any probabilistic modeling and hyperparameter tuning. We complement our selection method with contrastive learning to further combat the memorization of noisy labels. Extensive experimentation on multiple benchmark datasets demonstrates the effectiveness of UNICON; we obtain an 11.4% improvement over the current state-of-the-art on CIFAR100 dataset with a 90% noise rate. Our code is publicly available
TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization
Mar 31, 2022

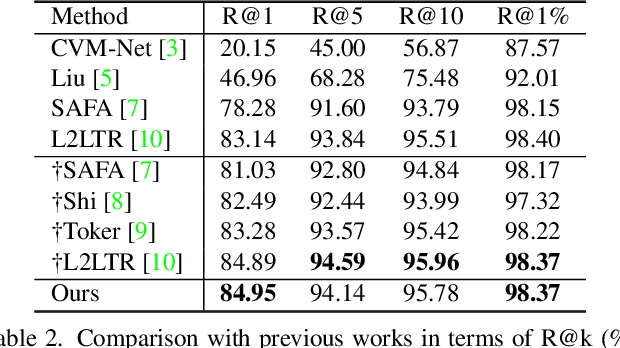
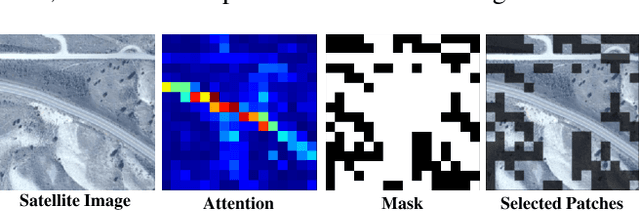
The dominant CNN-based methods for cross-view image geo-localization rely on polar transform and fail to model global correlation. We propose a pure transformer-based approach (TransGeo) to address these limitations from a different perspective. TransGeo takes full advantage of the strengths of transformer related to global information modeling and explicit position information encoding. We further leverage the flexibility of transformer input and propose an attention-guided non-uniform cropping method, so that uninformative image patches are removed with negligible drop on performance to reduce computation cost. The saved computation can be reallocated to increase resolution only for informative patches, resulting in performance improvement with no additional computation cost. This "attend and zoom-in" strategy is highly similar to human behavior when observing images. Remarkably, TransGeo achieves state-of-the-art results on both urban and rural datasets, with significantly less computation cost than CNN-based methods. It does not rely on polar transform and infers faster than CNN-based methods. Code is available at https://github.com/Jeff-Zilence/TransGeo2022.
SPAct: Self-supervised Privacy Preservation for Action Recognition
Mar 29, 2022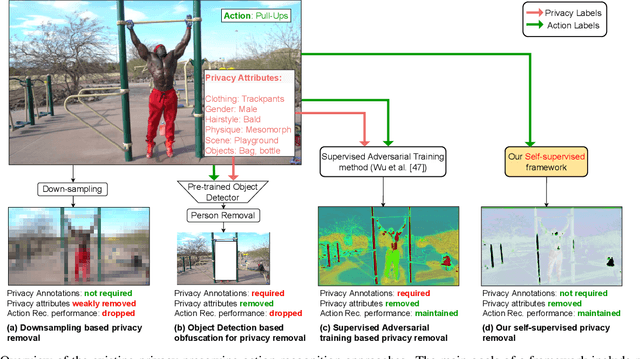
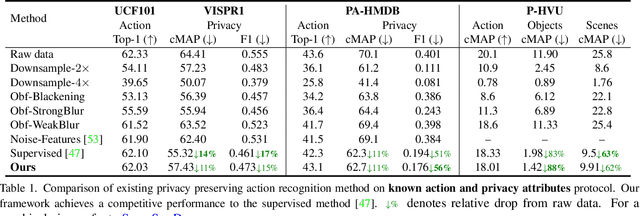
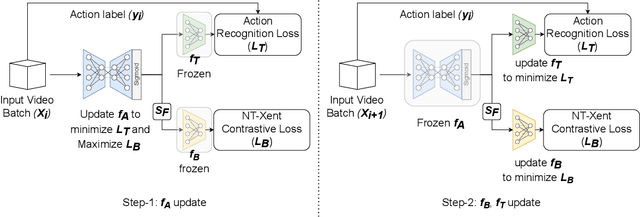
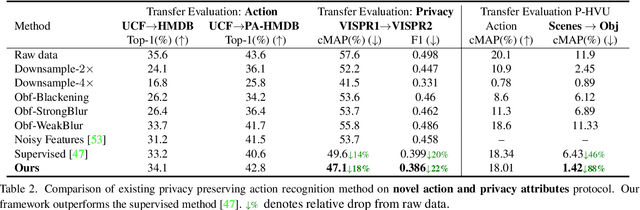
Visual private information leakage is an emerging key issue for the fast growing applications of video understanding like activity recognition. Existing approaches for mitigating privacy leakage in action recognition require privacy labels along with the action labels from the video dataset. However, annotating frames of video dataset for privacy labels is not feasible. Recent developments of self-supervised learning (SSL) have unleashed the untapped potential of the unlabeled data. For the first time, we present a novel training framework which removes privacy information from input video in a self-supervised manner without requiring privacy labels. Our training framework consists of three main components: anonymization function, self-supervised privacy removal branch, and action recognition branch. We train our framework using a minimax optimization strategy to minimize the action recognition cost function and maximize the privacy cost function through a contrastive self-supervised loss. Employing existing protocols of known-action and privacy attributes, our framework achieves a competitive action-privacy trade-off to the existing state-of-the-art supervised methods. In addition, we introduce a new protocol to evaluate the generalization of learned the anonymization function to novel-action and privacy attributes and show that our self-supervised framework outperforms existing supervised methods. Code available at: https://github.com/DAVEISHAN/SPAct
OW-DETR: Open-world Detection Transformer
Dec 09, 2021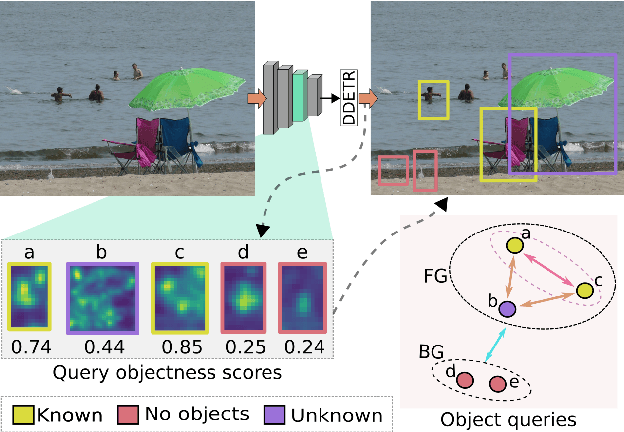
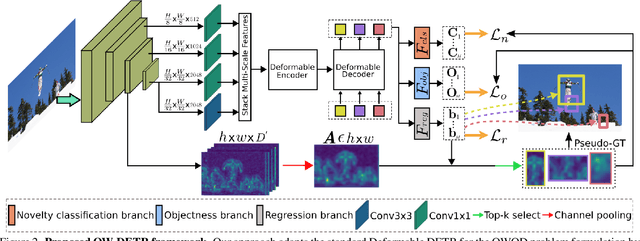
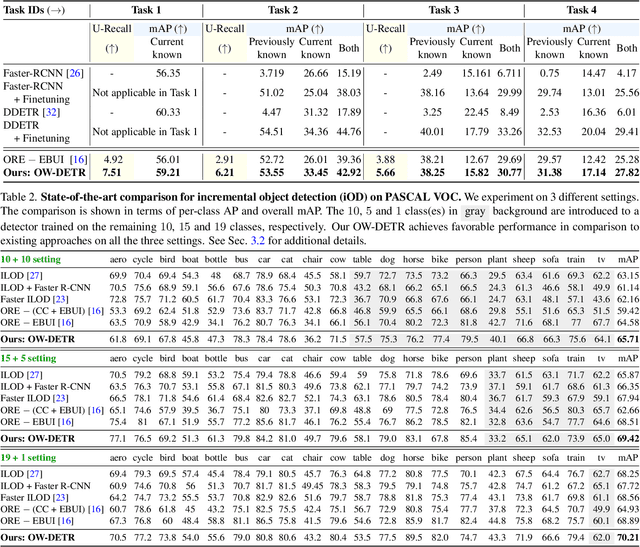
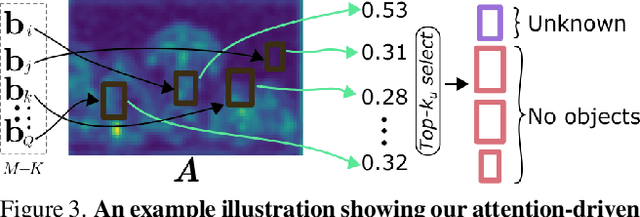
Open-world object detection (OWOD) is a challenging computer vision problem, where the task is to detect a known set of object categories while simultaneously identifying unknown objects. Additionally, the model must incrementally learn new classes that become known in the next training episodes. Distinct from standard object detection, the OWOD setting poses significant challenges for generating quality candidate proposals on potentially unknown objects, separating the unknown objects from the background and detecting diverse unknown objects. Here, we introduce a novel end-to-end transformer-based framework, OW-DETR, for open-world object detection. The proposed OW-DETR comprises three dedicated components namely, attention-driven pseudo-labeling, novelty classification and objectness scoring to explicitly address the aforementioned OWOD challenges. Our OW-DETR explicitly encodes multi-scale contextual information, possesses less inductive bias, enables knowledge transfer from known classes to the unknown class and can better discriminate between unknown objects and background. Comprehensive experiments are performed on two benchmarks: MS-COCO and PASCAL VOC. The extensive ablations reveal the merits of our proposed contributions. Further, our model outperforms the recently introduced OWOD approach, ORE, with absolute gains ranging from 1.8% to 3.3% in terms of unknown recall on the MS-COCO benchmark. In the case of incremental object detection, OW-DETR outperforms the state-of-the-art for all settings on the PASCAL VOC benchmark. Our codes and models will be publicly released.
Geometric Feature Learning for 3D Meshes
Dec 03, 2021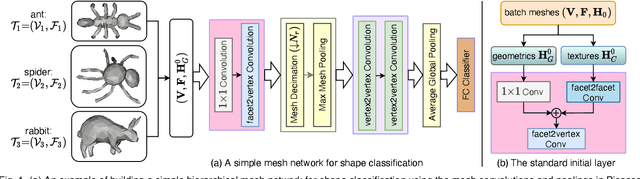
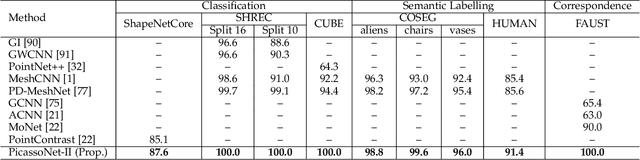
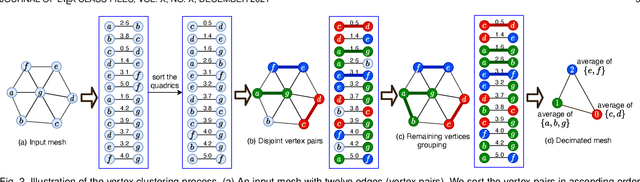
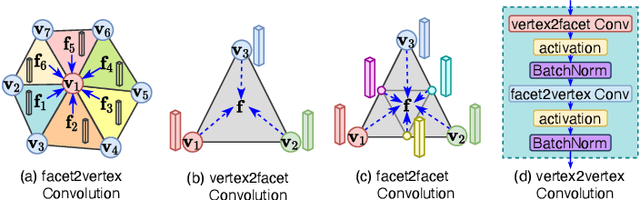
Geometric feature learning for 3D meshes is central to computer graphics and highly important for numerous vision applications. However, deep learning currently lags in hierarchical modeling of heterogeneous 3D meshes due to the lack of required operations and/or their efficient implementations. In this paper, we propose a series of modular operations for effective geometric deep learning over heterogeneous 3D meshes. These operations include mesh convolutions, (un)pooling and efficient mesh decimation. We provide open source implementation of these operations, collectively termed \textit{Picasso}. The mesh decimation module of Picasso is GPU-accelerated, which can process a batch of meshes on-the-fly for deep learning. Our (un)pooling operations compute features for newly-created neurons across network layers of varying resolution. Our mesh convolutions include facet2vertex, vertex2facet, and facet2facet convolutions that exploit vMF mixture and Barycentric interpolation to incorporate fuzzy modelling. Leveraging the modular operations of Picasso, we contribute a novel hierarchical neural network, PicassoNet-II, to learn highly discriminative features from 3D meshes. PicassoNet-II accepts primitive geometrics and fine textures of mesh facets as input features, while processing full scene meshes. Our network achieves highly competitive performance for shape analysis and scene parsing on a variety of benchmarks. We release Picasso and PicassoNet-II on Github https://github.com/EnyaHermite/Picasso.
Routing with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021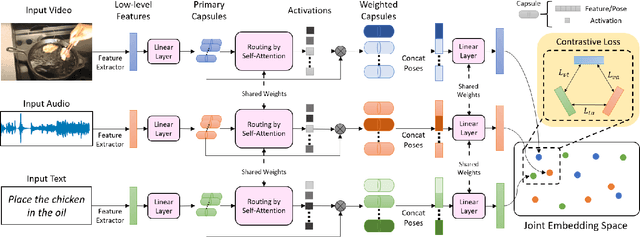
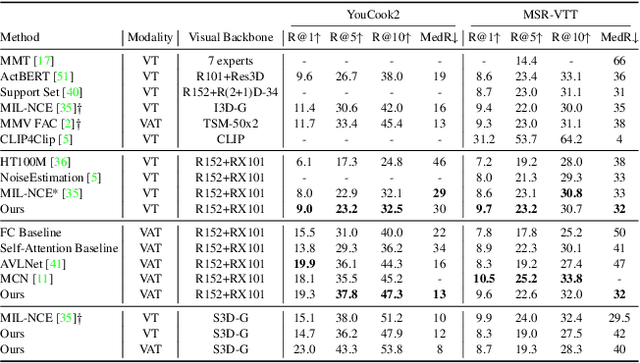
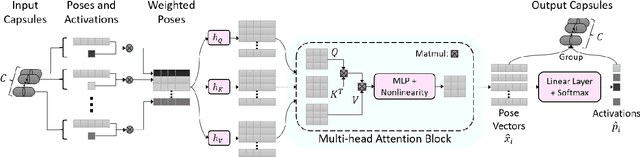
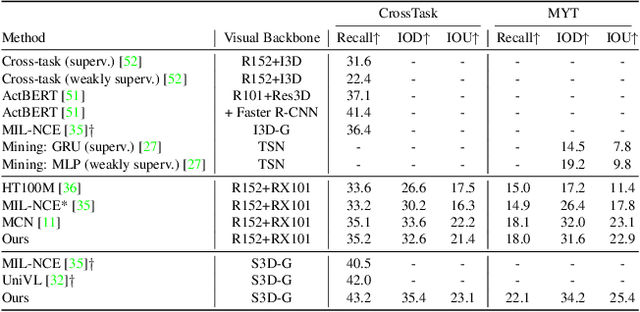
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.
Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
Nov 19, 2021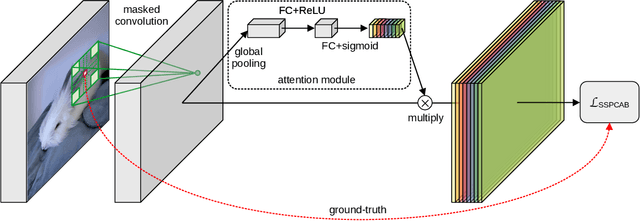
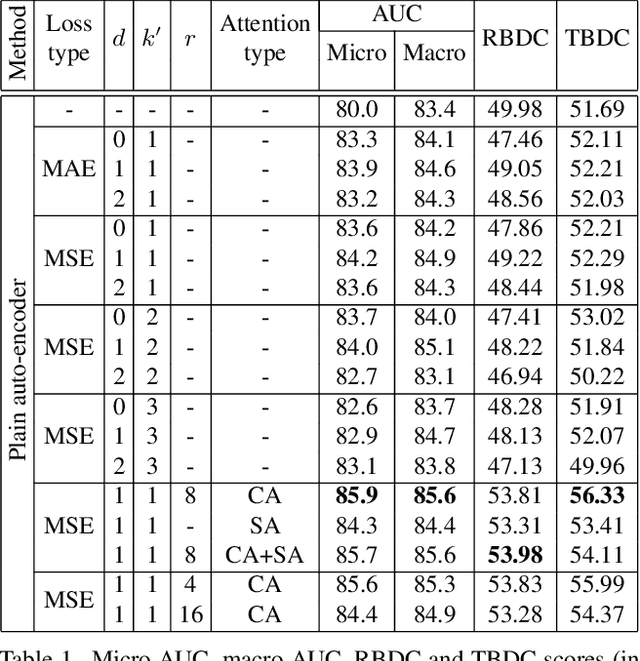
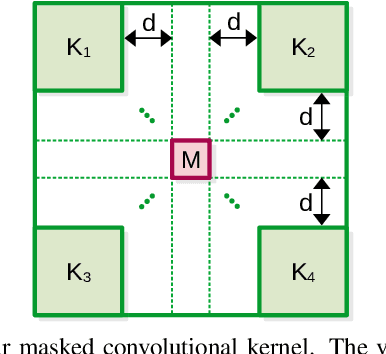
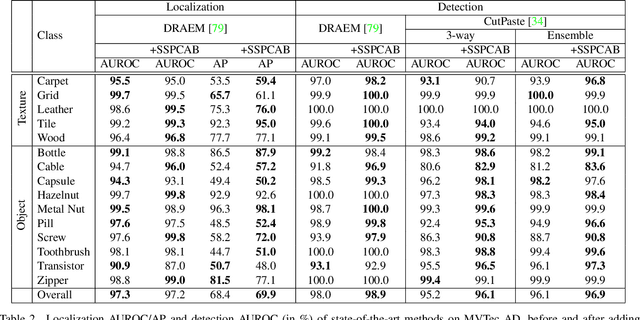
Anomaly detection is commonly pursued as a one-class classification problem, where models can only learn from normal training samples, while being evaluated on both normal and abnormal test samples. Among the successful approaches for anomaly detection, a distinguished category of methods relies on predicting masked information (e.g. patches, future frames, etc.) and leveraging the reconstruction error with respect to the masked information as an abnormality score. Different from related methods, we propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods. Our block starts with a convolutional layer with dilated filters, where the center area of the receptive field is masked. The resulting activation maps are passed through a channel attention module. Our block is equipped with a loss that minimizes the reconstruction error with respect to the masked area in the receptive field. We demonstrate the generality of our block by integrating it into several state-of-the-art frameworks for anomaly detection on image and video, providing empirical evidence that shows considerable performance improvements on MVTec AD, Avenue, and ShanghaiTech.