 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Navigate in Complex Environments
Jan 13, 2017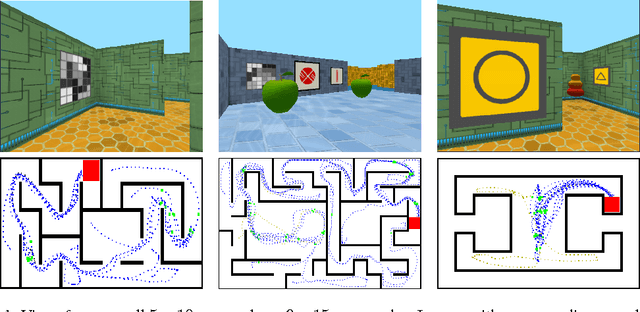
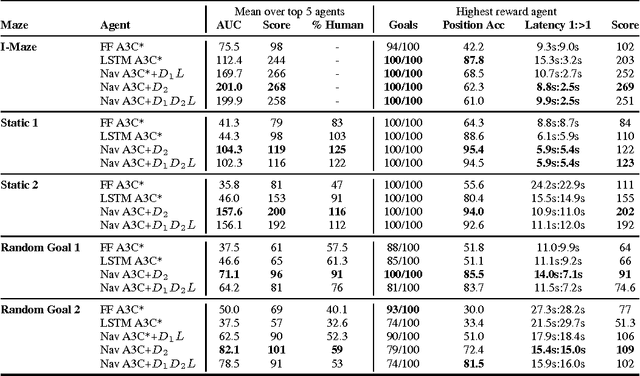
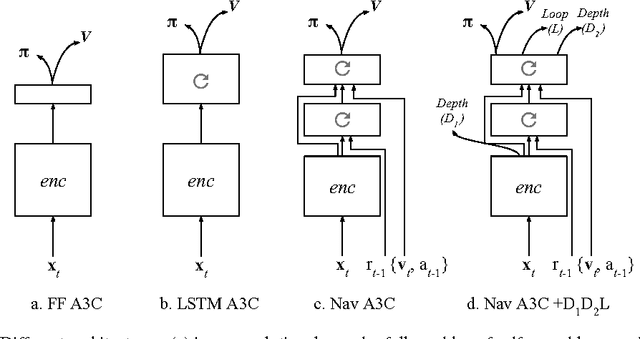
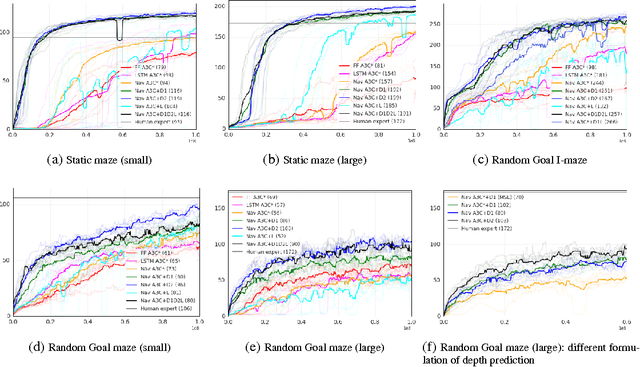
Learning to navigate in complex environments with dynamic elements is an important milestone in developing AI agents. In this work we formulate the navigation question as a reinforcement learning problem and show that data efficiency and task performance can be dramatically improved by relying on additional auxiliary tasks leveraging multimodal sensory inputs. In particular we consider jointly learning the goal-driven reinforcement learning problem with auxiliary depth prediction and loop closure classification tasks. This approach can learn to navigate from raw sensory input in complicated 3D mazes, approaching human-level performance even under conditions where the goal location changes frequently. We provide detailed analysis of the agent behaviour, its ability to localise, and its network activity dynamics, showing that the agent implicitly learns key navigation abilities.
Learning to learn by gradient descent by gradient descent
Nov 30, 2016
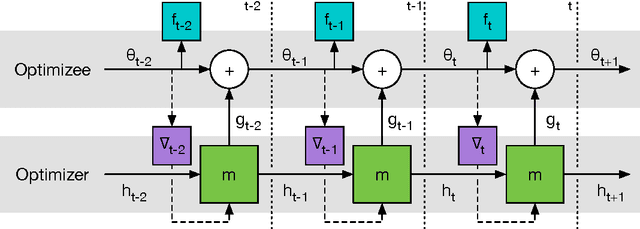
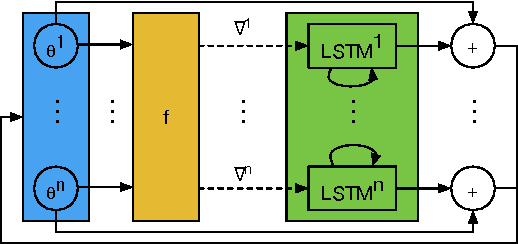
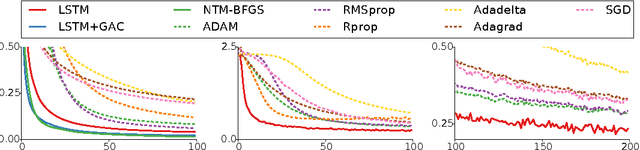
The move from hand-designed features to learned features in machine learning has been wildly successful. In spite of this, optimization algorithms are still designed by hand. In this paper we show how the design of an optimization algorithm can be cast as a learning problem, allowing the algorithm to learn to exploit structure in the problems of interest in an automatic way. Our learned algorithms, implemented by LSTMs, outperform generic, hand-designed competitors on the tasks for which they are trained, and also generalize well to new tasks with similar structure. We demonstrate this on a number of tasks, including simple convex problems, training neural networks, and styling images with neural art.
Noisy Activation Functions
Apr 03, 2016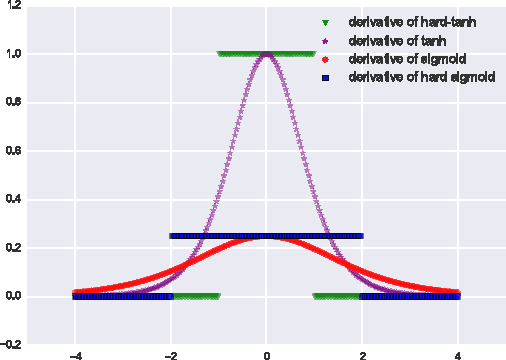


Common nonlinear activation functions used in neural networks can cause training difficulties due to the saturation behavior of the activation function, which may hide dependencies that are not visible to vanilla-SGD (using first order gradients only). Gating mechanisms that use softly saturating activation functions to emulate the discrete switching of digital logic circuits are good examples of this. We propose to exploit the injection of appropriate noise so that the gradients may flow easily, even if the noiseless application of the activation function would yield zero gradient. Large noise will dominate the noise-free gradient and allow stochastic gradient descent toexplore more. By adding noise only to the problematic parts of the activation function, we allow the optimization procedure to explore the boundary between the degenerate (saturating) and the well-behaved parts of the activation function. We also establish connections to simulated annealing, when the amount of noise is annealed down, making it easier to optimize hard objective functions. We find experimentally that replacing such saturating activation functions by noisy variants helps training in many contexts, yielding state-of-the-art or competitive results on different datasets and task, especially when training seems to be the most difficult, e.g., when curriculum learning is necessary to obtain good results.
ACDC: A Structured Efficient Linear Layer
Mar 19, 2016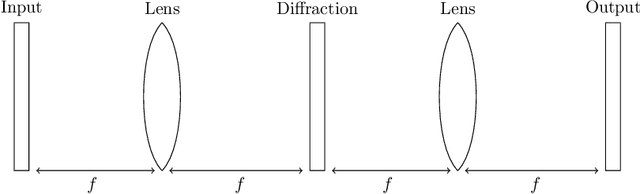
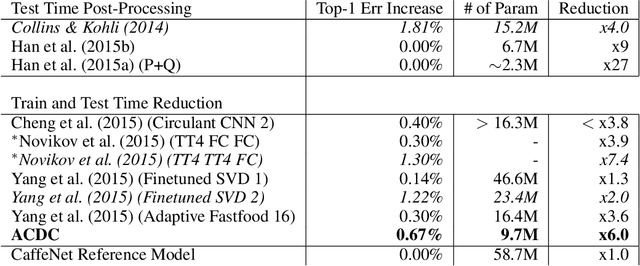

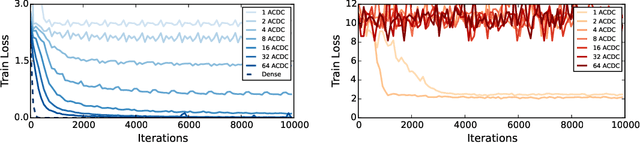
The linear layer is one of the most pervasive modules in deep learning representations. However, it requires $O(N^2)$ parameters and $O(N^2)$ operations. These costs can be prohibitive in mobile applications or prevent scaling in many domains. Here, we introduce a deep, differentiable, fully-connected neural network module composed of diagonal matrices of parameters, $\mathbf{A}$ and $\mathbf{D}$, and the discrete cosine transform $\mathbf{C}$. The core module, structured as $\mathbf{ACDC^{-1}}$, has $O(N)$ parameters and incurs $O(N log N )$ operations. We present theoretical results showing how deep cascades of ACDC layers approximate linear layers. ACDC is, however, a stand-alone module and can be used in combination with any other types of module. In our experiments, we show that it can indeed be successfully interleaved with ReLU modules in convolutional neural networks for image recognition. Our experiments also study critical factors in the training of these structured modules, including initialization and depth. Finally, this paper also provides a connection between structured linear transforms used in deep learning and the field of Fourier optics, illustrating how ACDC could in principle be implemented with lenses and diffractive elements.
Deep Fried Convnets
Jul 17, 2015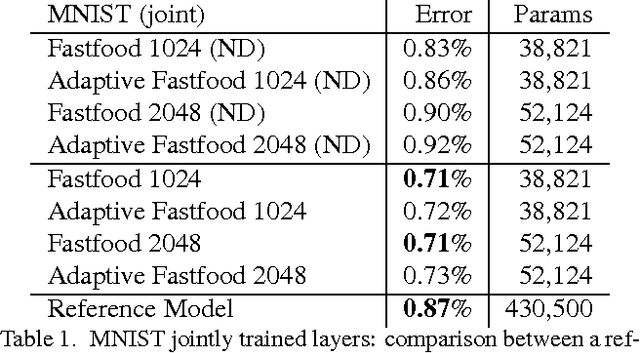
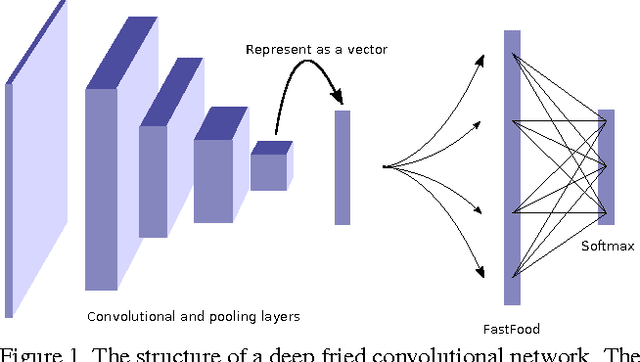
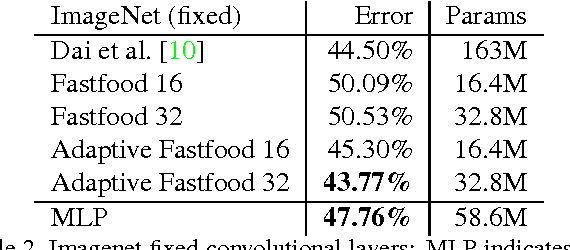
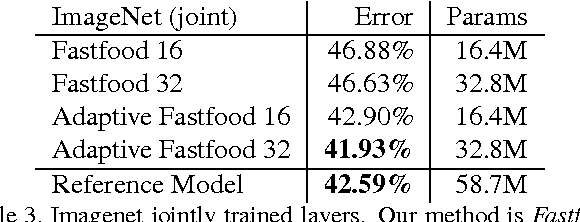
The fully connected layers of a deep convolutional neural network typically contain over 90% of the network parameters, and consume the majority of the memory required to store the network parameters. Reducing the number of parameters while preserving essentially the same predictive performance is critically important for operating deep neural networks in memory constrained environments such as GPUs or embedded devices. In this paper we show how kernel methods, in particular a single Fastfood layer, can be used to replace all fully connected layers in a deep convolutional neural network. This novel Fastfood layer is also end-to-end trainable in conjunction with convolutional layers, allowing us to combine them into a new architecture, named deep fried convolutional networks, which substantially reduces the memory footprint of convolutional networks trained on MNIST and ImageNet with no drop in predictive performance.
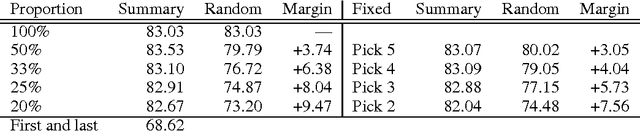
Extraction of Salient Sentences from Labelled Documents
Feb 28, 2015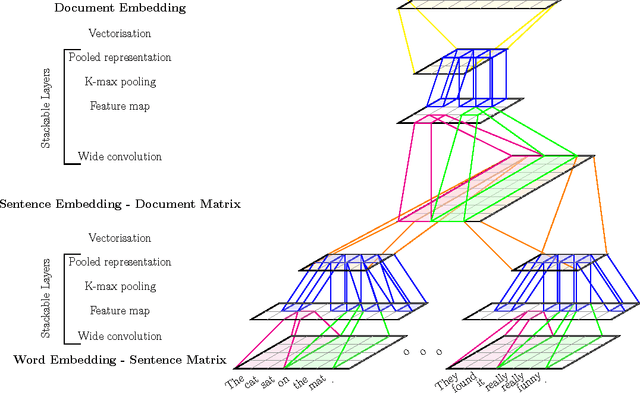
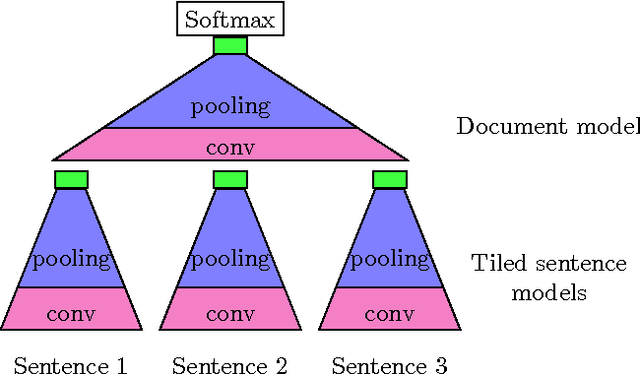
We present a hierarchical convolutional document model with an architecture designed to support introspection of the document structure. Using this model, we show how to use visualisation techniques from the computer vision literature to identify and extract topic-relevant sentences. We also introduce a new scalable evaluation technique for automatic sentence extraction systems that avoids the need for time consuming human annotation of validation data.
Deep Multi-Instance Transfer Learning
Dec 10, 2014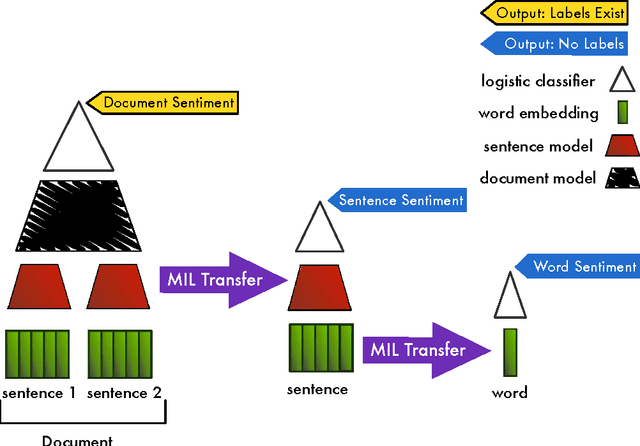


We present a new approach for transferring knowledge from groups to individuals that comprise them. We evaluate our method in text, by inferring the ratings of individual sentences using full-review ratings. This approach, which combines ideas from transfer learning, deep learning and multi-instance learning, reduces the need for laborious human labelling of fine-grained data when abundant labels are available at the group level.
Predicting Parameters in Deep Learning
Oct 27, 2014

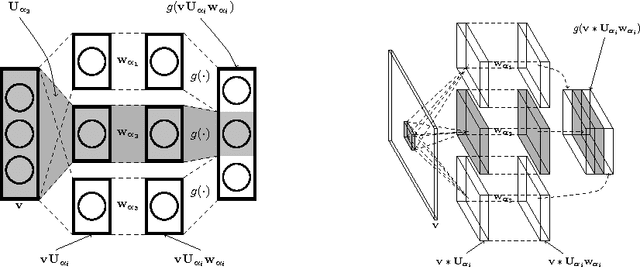
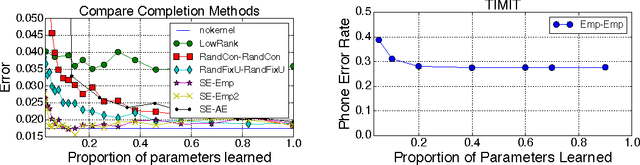
We demonstrate that there is significant redundancy in the parameterization of several deep learning models. Given only a few weight values for each feature it is possible to accurately predict the remaining values. Moreover, we show that not only can the parameter values be predicted, but many of them need not be learned at all. We train several different architectures by learning only a small number of weights and predicting the rest. In the best case we are able to predict more than 95% of the weights of a network without any drop in accuracy.
Modelling, Visualising and Summarising Documents with a Single Convolutional Neural Network
Jun 15, 2014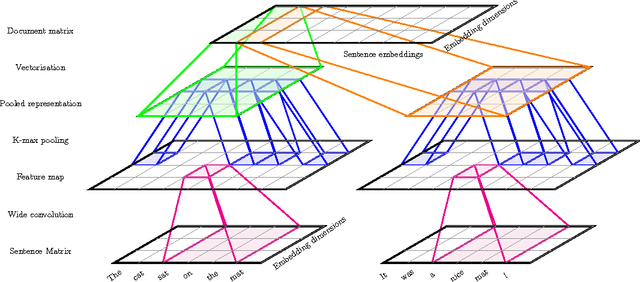

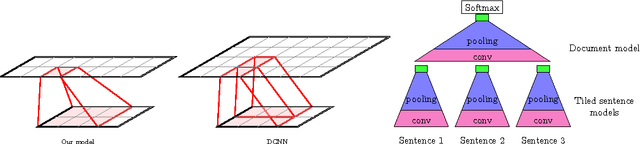
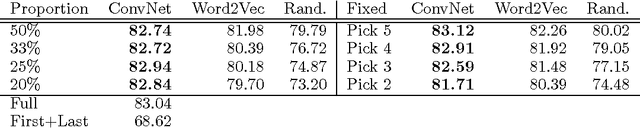
Capturing the compositional process which maps the meaning of words to that of documents is a central challenge for researchers in Natural Language Processing and Information Retrieval. We introduce a model that is able to represent the meaning of documents by embedding them in a low dimensional vector space, while preserving distinctions of word and sentence order crucial for capturing nuanced semantics. Our model is based on an extended Dynamic Convolution Neural Network, which learns convolution filters at both the sentence and document level, hierarchically learning to capture and compose low level lexical features into high level semantic concepts. We demonstrate the effectiveness of this model on a range of document modelling tasks, achieving strong results with no feature engineering and with a more compact model. Inspired by recent advances in visualising deep convolution networks for computer vision, we present a novel visualisation technique for our document networks which not only provides insight into their learning process, but also can be interpreted to produce a compelling automatic summarisation system for texts.
Distributed Parameter Estimation in Probabilistic Graphical Models
Jun 11, 2014

This paper presents foundational theoretical results on distributed parameter estimation for undirected probabilistic graphical models. It introduces a general condition on composite likelihood decompositions of these models which guarantees the global consistency of distributed estimators, provided the local estimators are consistent.