 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexGR: Efficient Generative Recommendation Serving at Scale
Dec 19, 2025Recommendation system delivers substantial economic benefits by providing personalized predictions. Generative recommendation (GR) integrates LLMs to enhance the understanding of long user-item sequences. Despite employing attention-based architectures, GR's workload differs markedly from that of LLM serving. GR typically processes long prompt while producing short, fixed-length outputs, yet the computational cost of each decode phase is especially high due to the large beam width. In addition, since the beam search involves a vast item space, the sorting overhead becomes particularly time-consuming. We propose xGR, a GR-oriented serving system that meets strict low-latency requirements under highconcurrency scenarios. First, xGR unifies the processing of prefill and decode phases through staged computation and separated KV cache. Second, xGR enables early sorting termination and mask-based item filtering with data structure reuse. Third, xGR reconstructs the overall pipeline to exploit multilevel overlap and multi-stream parallelism. Our experiments with real-world recommendation service datasets demonstrate that xGR achieves at least 3.49x throughput compared to the state-of-the-art baseline under strict latency constraints.
Flexible Operator Fusion for Fast Sparse Transformer with Diverse Masking on GPU
Jun 06, 2025Large language models are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. Moreover, rule-based mechanisms ignore the fusion opportunities of mixed-type operators and fail to adapt to various sequence lengths. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU. We firstly unify the storage format and kernel implementation for the multi-head attention. Then, we map fusion schemes to compilation templates and determine the optimal parameter setting through a two-stage search engine. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.7x in MHA computation and 1.5x in end-to-end inference.
The Deep Learning Compiler: A Comprehensive Survey
Feb 27, 2020
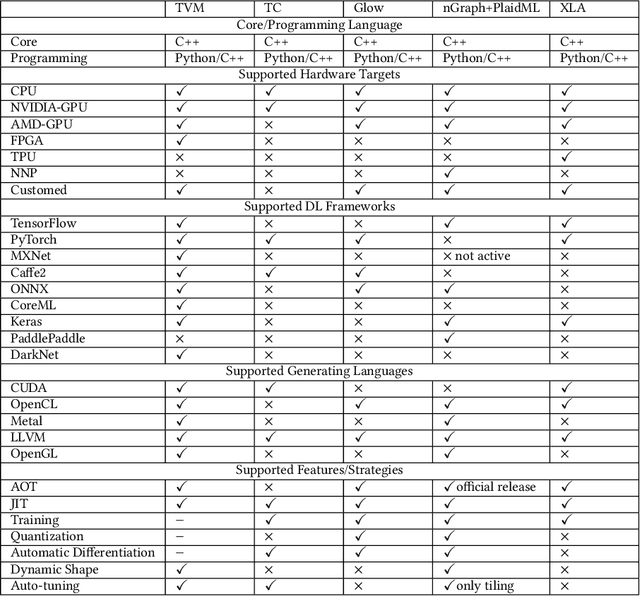
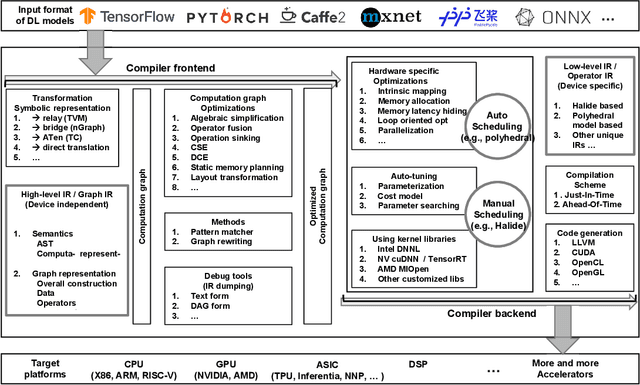
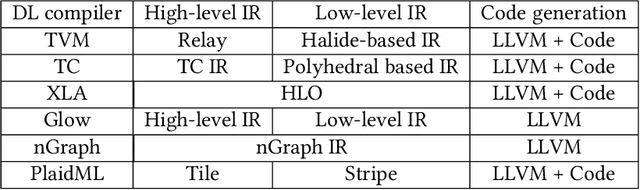
The difficulty of deploying various deep learning (DL) models on diverse DL hardware has boosted the research and development of DL compilers in the community. Several DL compilers have been proposed from both industry and academia such as Tensorflow XLA and TVM. Similarly, the DL compilers take the DL models described in different DL frameworks as input, and then generate optimized codes for diverse DL hardware as output. However, none of the existing survey has analyzed the unique design of the DL compilers comprehensively. In this paper, we perform a comprehensive survey of existing DL compilers by dissecting the commonly adopted design in details, with emphasis on the DL oriented multi-level IRs, and frontend/backend optimizations. Specifically, we provide a comprehensive comparison among existing DL compilers from various aspects. In addition, we present detailed analysis of the multi-level IR design and compiler optimization techniques. Finally, several insights are highlighted as the potential research directions of DL compiler. This is the first survey paper focusing on the unique design of DL compiler, which we hope can pave the road for future research towards the DL compiler.