 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONA: Muon Optimizer with Nesterov Acceleration for Scalable Language Model Training
May 26, 2026The Muon optimizer has recently offered a promising alternative to AdamW for large language model training, leveraging matrix orthogonalization to produce geometry-aware updates. However, like all first-order methods, Muon can become trapped in sharp local minima. In this work, we present MONA, an optimizer that bridges Muon's orthogonalization framework with curvature-aware acceleration. MONA adds an acceleration term directly into Muon's gradient processing pipeline. This term is calculated from the exponential moving average of gradient differences. We provide a detailed convergence analysis for MONA, showing that the acceleration term enables escape from sharp minima while preserving Muon's spectral-norm regularization. Empirically, MONA achieves better convergence and downstream task performance compared to both Muon and AdamW across three scales of Mixture-of-Experts pretraining, spanning from 1B to 68B parameters, with the largest model trained on 1 trillion tokens. Furthermore, we conduct supervised fine-tuning on the MOE-68B-A3B model and evaluate it on general capability, mathematical reasoning, and code generation benchmarks, where MONA achieves SOTA performance.
SparseBalance: Load-Balanced Long Context Training with Dynamic Sparse Attention
Apr 15, 2026While sparse attention mitigates the computational bottleneck of long-context LLM training, its distributed training process exhibits extreme heterogeneity in both \textit{1)} sequence length and \textit{2)} sparsity sensitivity, leading to a severe imbalance problem and sub-optimal model accuracy. Existing algorithms and training frameworks typically focus on single issue, failing to systematically co-optimize these two problems. Therefore, we propose SparseBalance, a novel algorithm-system co-design framework, which exploits the sparsity and sequence heterogeneity to optimize model accuracy and system efficiency jointly. First, we propose workload-aware dynamic sparsity tuning, which employs a bidirectional sparsity adjustment to eliminate stragglers and exploit inherent bubbles for free accuracy. Second, we propose a sparsity-aware batching strategy to achieve coarse-grained balance, which complements dynamic sparsity tuning. Experimental results demonstrate that SparseBalance achieves up to a 1.33$\times$ end-to-end speedup while still improving the long-context capability by 0.46\% on the LongBench benchmark.
Skrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
May 26, 2025Long-context supervised fine-tuning (Long-SFT) plays a vital role in enhancing the performance of large language models (LLMs) on long-context tasks. To smoothly adapt LLMs to long-context scenarios, this process typically entails training on mixed datasets containing both long and short sequences. However, this heterogeneous sequence length distribution poses significant challenges for existing training systems, as they fail to simultaneously achieve high training efficiency for both long and short sequences, resulting in sub-optimal end-to-end system performance in Long-SFT. In this paper, we present a novel perspective on data scheduling to address the challenges posed by the heterogeneous data distributions in Long-SFT. We propose Skrull, a dynamic data scheduler specifically designed for efficient long-SFT. Through dynamic data scheduling, Skrull balances the computation requirements of long and short sequences, improving overall training efficiency. Furthermore, we formulate the scheduling process as a joint optimization problem and thoroughly analyze the trade-offs involved. Based on those analysis, Skrull employs a lightweight scheduling algorithm to achieve near-zero cost online scheduling in Long-SFT. Finally, we implement Skrull upon DeepSpeed, a state-of-the-art distributed training system for LLMs. Experimental results demonstrate that Skrull outperforms DeepSpeed by 3.76x on average (up to 7.54x) in real-world long-SFT scenarios.
MC-UNet Multi-module Concatenation based on U-shape Network for Retinal Blood Vessels Segmentation
Apr 07, 2022

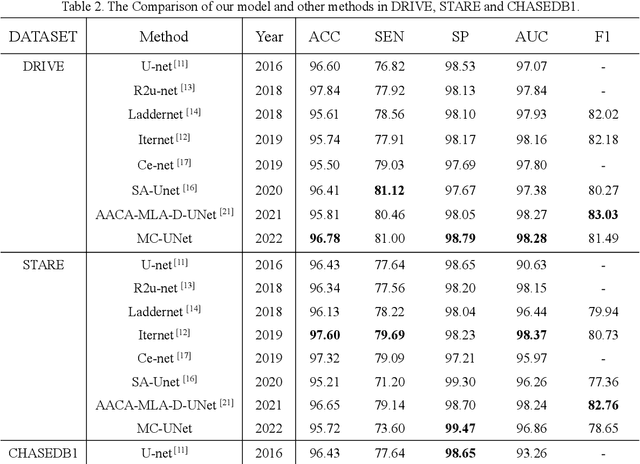
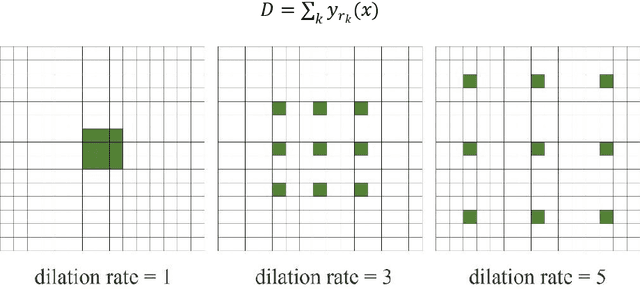
Accurate segmentation of the blood vessels of the retina is an important step in clinical diagnosis of ophthalmic diseases. Many deep learning frameworks have come up for retinal blood vessels segmentation tasks. However, the complex vascular structure and uncertain pathological features make the blood vessel segmentation still very challenging. A novel U-shaped network named Multi-module Concatenation which is based on Atrous convolution and multi-kernel pooling is put forward to retinal vessels segmentation in this paper. The proposed network structure retains three layers the essential structure of U-Net, in which the atrous convolution combining the multi-kernel pooling blocks are designed to obtain more contextual information. The spatial attention module is concatenated with dense atrous convolution module and multi-kernel pooling module to form a multi-module concatenation. And different dilation rates are selected by cascading to acquire a larger receptive field in atrous convolution. Adequate comparative experiments are conducted on these public retinal datasets: DRIVE, STARE and CHASE_DB1. The results show that the proposed method is effective, especially for microvessels. The code will be put out at https://github.com/Rebeccala/MC-UNet