 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
A Step to Decouple Optimization in 3DGS
Jan 26, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.
Skrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
May 26, 2025Long-context supervised fine-tuning (Long-SFT) plays a vital role in enhancing the performance of large language models (LLMs) on long-context tasks. To smoothly adapt LLMs to long-context scenarios, this process typically entails training on mixed datasets containing both long and short sequences. However, this heterogeneous sequence length distribution poses significant challenges for existing training systems, as they fail to simultaneously achieve high training efficiency for both long and short sequences, resulting in sub-optimal end-to-end system performance in Long-SFT. In this paper, we present a novel perspective on data scheduling to address the challenges posed by the heterogeneous data distributions in Long-SFT. We propose Skrull, a dynamic data scheduler specifically designed for efficient long-SFT. Through dynamic data scheduling, Skrull balances the computation requirements of long and short sequences, improving overall training efficiency. Furthermore, we formulate the scheduling process as a joint optimization problem and thoroughly analyze the trade-offs involved. Based on those analysis, Skrull employs a lightweight scheduling algorithm to achieve near-zero cost online scheduling in Long-SFT. Finally, we implement Skrull upon DeepSpeed, a state-of-the-art distributed training system for LLMs. Experimental results demonstrate that Skrull outperforms DeepSpeed by 3.76x on average (up to 7.54x) in real-world long-SFT scenarios.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Structure Enhanced Graph Neural Networks for Link Prediction
Jan 14, 2022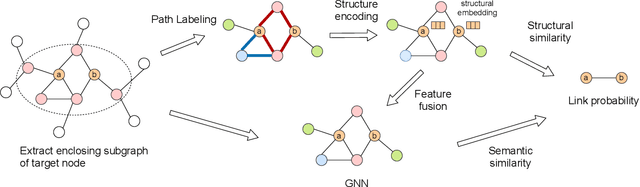
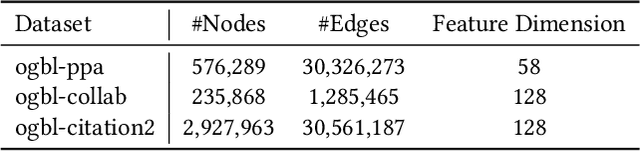
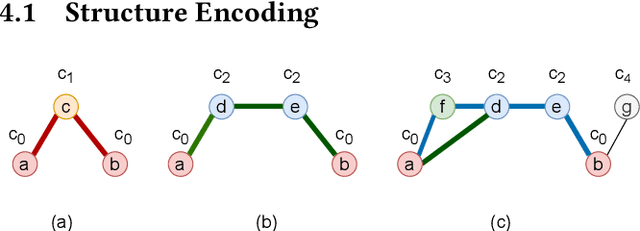
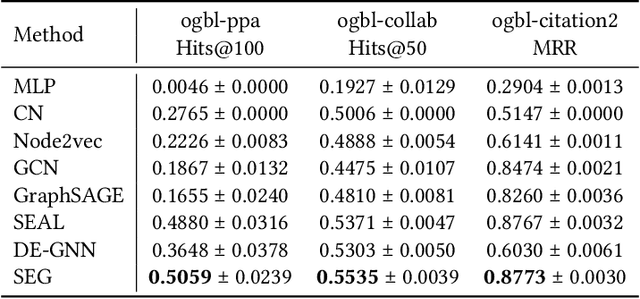
Graph Neural Networks (GNNs) have shown promising results in various tasks, among which link prediction is an important one. GNN models usually follow a node-centric message passing procedure that aggregates the neighborhood information to the central node recursively. Following this paradigm, features of nodes are passed through edges without caring about where the nodes are located and which role they played. However, the neglected topological information is shown to be valuable for link prediction tasks. In this paper, we propose Structure Enhanced Graph neural network (SEG) for link prediction. SEG introduces the path labeling method to capture surrounding topological information of target nodes and then incorporates the structure into an ordinary GNN model. By jointly training the structure encoder and deep GNN model, SEG fuses topological structures and node features to take full advantage of graph information. Experiments on the OGB link prediction datasets demonstrate that SEG achieves state-of-the-art results among all three public datasets.