 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Information Bottleneck guided Privacy-Protective JSCC for Image Transmission
Sep 19, 2023



Joint source and channel coding (JSCC) has attracted increasing attention due to its robustness and high efficiency. However, JSCC is vulnerable to privacy leakage due to the high relevance between the source image and channel input. In this paper, we propose a disentangled information bottleneck guided privacy-protective JSCC (DIB-PPJSCC) for image transmission, which aims at protecting private information as well as achieving superior communication performance at the legitimate receiver. In particular, we propose a DIB objective to disentangle private and public information. The goal is to compress the private information in the public subcodewords, preserve the private information in the private subcodewords and improve the reconstruction quality simultaneously. In order to optimize JSCC neural networks using the DIB objective, we derive a differentiable estimation of the DIB objective based on the variational approximation and the density-ratio trick. Additionally, we design a password-based privacy-protective (PP) algorithm which can be jointly optimized with JSCC neural networks to encrypt the private subcodewords. Specifically, we employ a private information encryptor to encrypt the private subcodewords before transmission, and a corresponding decryptor to recover the private information at the legitimate receiver. A loss function for jointly training the encryptor, decryptor and JSCC decoder is derived based on the maximum entropy principle, which aims at maximizing the eavesdropping uncertainty as well as improving the reconstruction quality. Experimental results show that DIB-PPJSCC can reduce the eavesdropping accuracy on private information up to $15\%$ and reduce $10\%$ inference time compared to existing privacy-protective JSCC and traditional separate methods.
Privacy-Aware Joint Source-Channel Coding for image transmission based on Disentangled Information Bottleneck
Sep 15, 2023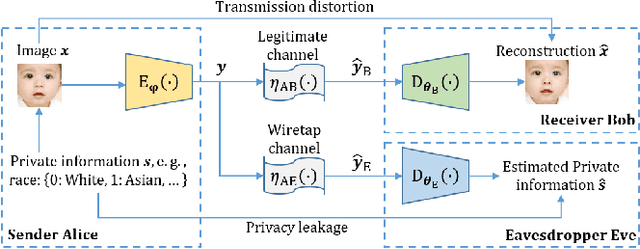



Current privacy-aware joint source-channel coding (JSCC) works aim at avoiding private information transmission by adversarially training the JSCC encoder and decoder under specific signal-to-noise ratios (SNRs) of eavesdroppers. However, these approaches incur additional computational and storage requirements as multiple neural networks must be trained for various eavesdroppers' SNRs to determine the transmitted information. To overcome this challenge, we propose a novel privacy-aware JSCC for image transmission based on disentangled information bottleneck (DIB-PAJSCC). In particular, we derive a novel disentangled information bottleneck objective to disentangle private and public information. Given the separate information, the transmitter can transmit only public information to the receiver while minimizing reconstruction distortion. Since DIB-PAJSCC transmits only public information regardless of the eavesdroppers' SNRs, it can eliminate additional training adapted to eavesdroppers' SNRs. Experimental results show that DIB-PAJSCC can reduce the eavesdropping accuracy on private information by up to 20\% compared to existing methods.
Cross-Layer Federated Learning Optimization in MIMO Networks
Feb 04, 2023



In this paper, the performance optimization of federated learning (FL), when deployed over a realistic wireless multiple-input multiple-output (MIMO) communication system with digital modulation and over-the-air computation (AirComp) is studied. In particular, an MIMO system is considered in which edge devices transmit their local FL models (trained using their locally collected data) to a parameter server (PS) using beamforming to maximize the number of devices scheduled for transmission. The PS, acting as a central controller, generates a global FL model using the received local FL models and broadcasts it back to all devices. Due to the limited bandwidth in a wireless network, AirComp is adopted to enable efficient wireless data aggregation. However, fading of wireless channels can produce aggregate distortions in an AirComp-based FL scheme. To tackle this challenge, we propose a modified federated averaging (FedAvg) algorithm that combines digital modulation with AirComp to mitigate wireless fading while ensuring the communication efficiency. This is achieved by a joint transmit and receive beamforming design, which is formulated as a optimization problem to dynamically adjust the beamforming matrices based on current FL model parameters so as to minimize the transmitting error and ensure the FL performance. To achieve this goal, we first analytically characterize how the beamforming matrices affect the performance of the FedAvg in different iterations. Based on this relationship, an artificial neural network (ANN) is used to estimate the local FL models of all devices and adjust the beamforming matrices at the PS for future model transmission. The algorithmic advantages and improved performance of the proposed methodologies are demonstrated through extensive numerical experiments.
Energy Efficient Semantic Communication over Wireless Networks with Rate Splitting
Jan 05, 2023In this paper, the problem of wireless resource allocation and semantic information extraction for energy efficient semantic communications over wireless networks with rate splitting is investigated. In the considered model, a base station (BS) first extracts semantic information from its large-scale data, and then transmits the small-sized semantic information to each user which recovers the original data based on its local common knowledge. At the BS side, the probability graph is used to extract multi-level semantic information. In the downlink transmission, a rate splitting scheme is adopted, while the private small-sized semantic information is transmitted through private message and the common knowledge is transmitted through common message. Due to limited wireless resource, both computation energy and transmission energy are considered. This joint computation and communication problem is formulated as an optimization problem aiming to minimize the total communication and computation energy consumption of the network under computation, latency, and transmit power constraints. To solve this problem, an alternating algorithm is proposed where the closed-form solutions for semantic information extraction ratio and computation frequency are obtained at each step. Numerical results verify the effectiveness of the proposed algorithm.
Secure Semantic Communications: Fundamentals and Challenges
Jan 04, 2023Semantic communication allows the receiver to know the intention instead of the bit information itself, which is an emerging technique to support real-time human-machine and machine-to-machine interactions for future wireless communications. In semantic communications, both transmitter and receiver share some common knowledge, which can be used to extract small-size information at the transmitter and recover the original information at the receiver. Due to different design purposes, security issues in semantic communications have two unique features compared to standard bit-wise communications. First, an attacker in semantic communications considers not only the amount of stolen data but also the meanings of stolen data. Second, an attacker in semantic communication systems can attack not only semantic information transmission as done in standard communication systems but also attacks machine learning (ML) models used for semantic information extraction since most of semantic information is generated using ML based methods. Due to these unique features, in this paper, we present an overview on the fundamentals and key challenges in the design of secure semantic communication. We first provide various methods to define and extract semantic information. Then, we focus on secure semantic communication techniques in two areas: information security and semantic ML model security. For each area, we identify the main problems and challenges. Then, we will provide a comprehensive treatment of these problems. In a nutshell,this article provides a holistic set of guidelines on how to design secure semantic communication systems over real-world wireless communication networks.
Optimization of Image Transmission in a Cooperative Semantic Communication Networks
Jan 01, 2023



In this paper, a semantic communication framework for image transmission is developed. In the investigated framework, a set of servers cooperatively transmit images to a set of users utilizing semantic communication techniques. To evaluate the performance of studied semantic communication system, a multimodal metric is proposed to measure the correlation between the extracted semantic information and the original image. To meet the ISS requirement of each user, each server must jointly determine the semantic information to be transmitted and the resource blocks (RBs) used for semantic information transmission. We formulate this problem as an optimization problem aiming to minimize each server's transmission latency while reaching the ISS requirement. To solve this problem, a value decomposition based entropy-maximized multi-agent reinforcement learning (RL) is proposed, which enables servers to coordinate for training and execute RB allocation in a distributed manner to approach to a globally optimal performance with less training iterations. Compared to traditional multi-agent RL, the proposed RL improves the valuable action exploration of servers and the probability of finding a globally optimal RB allocation policy based on local observation. Simulation results show that the proposed algorithm can reduce the transmission delay by up to 16.1% compared to traditional multi-agent RL.
Performance Optimization for Variable Bitwidth Federated Learning in Wireless Networks
Sep 21, 2022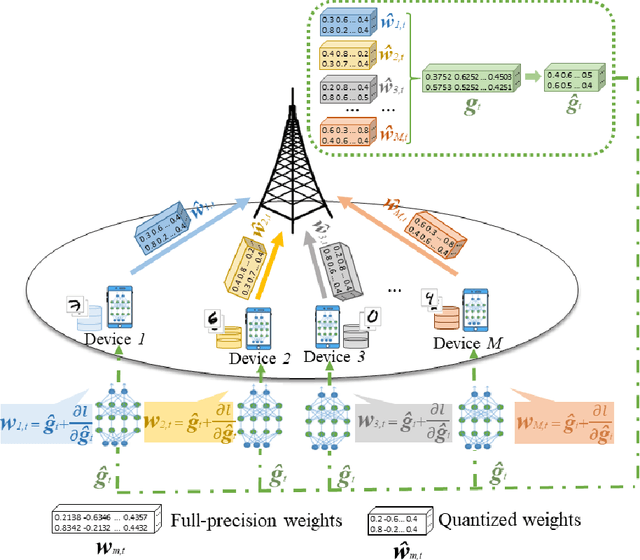
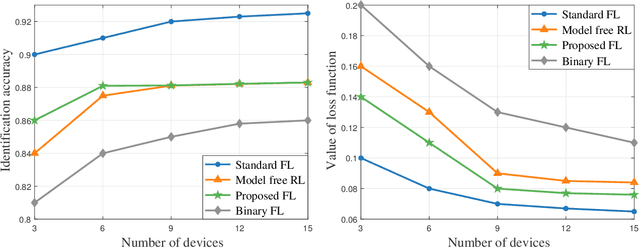
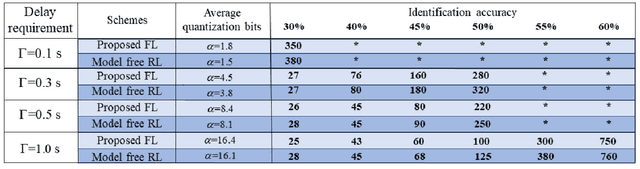
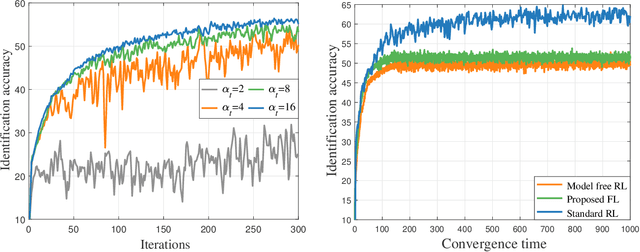
This paper considers improving wireless communication and computation efficiency in federated learning (FL) via model quantization. In the proposed bitwidth FL scheme, edge devices train and transmit quantized versions of their local FL model parameters to a coordinating server, which, in turn, aggregates them into a quantized global model and synchronizes the devices. The goal is to jointly determine the bitwidths employed for local FL model quantization and the set of devices participating in FL training at each iteration. This problem is posed as an optimization problem whose goal is to minimize the training loss of quantized FL under a per-iteration device sampling budget and delay requirement. To derive the solution, an analytical characterization is performed in order to show how the limited wireless resources and induced quantization errors affect the performance of the proposed FL method. The analytical results show that the improvement of FL training loss between two consecutive iterations depends on the device selection and quantization scheme as well as on several parameters inherent to the model being learned. Given linear regression-based estimates of these model properties, it is shown that the FL training process can be described as a Markov decision process (MDP), and, then, a model-based reinforcement learning (RL) method is proposed to optimize action selection over iterations. Compared to model-free RL, this model-based RL approach leverages the derived mathematical characterization of the FL training process to discover an effective device selection and quantization scheme without imposing additional device communication overhead. Simulation results show that the proposed FL algorithm can reduce 29% and 63% convergence time compared to a model free RL method and the standard FL method, respectively.
On Differential Privacy for Federated Learning in Wireless Systems with Multiple Base Stations
Aug 25, 2022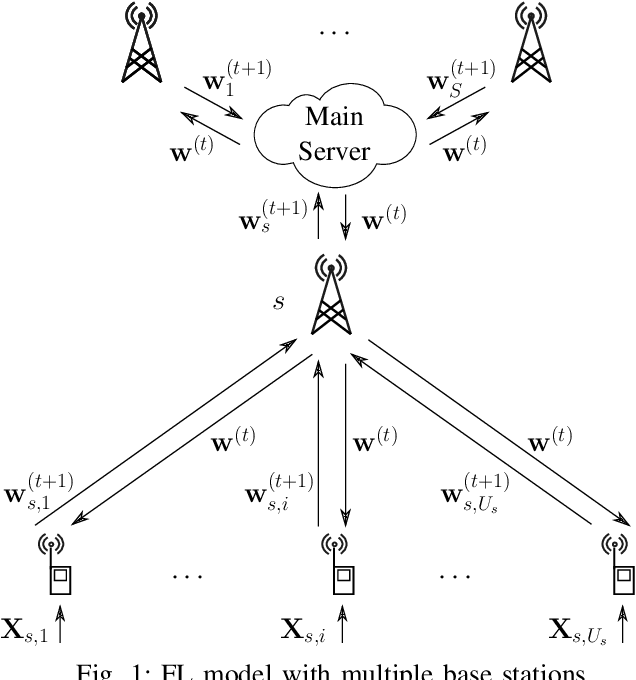
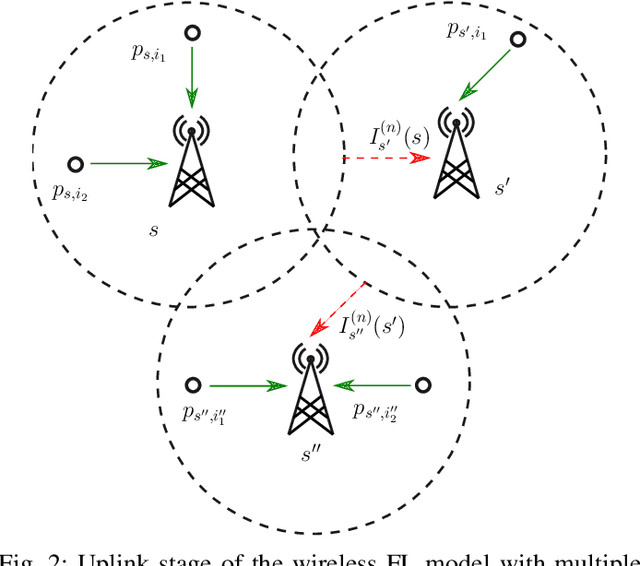
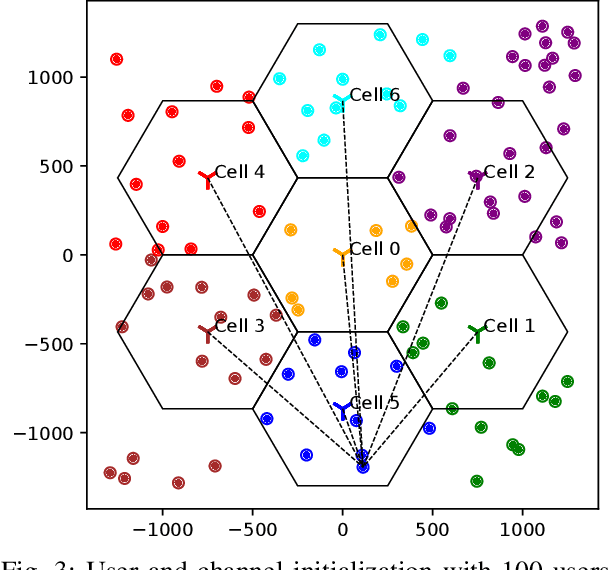
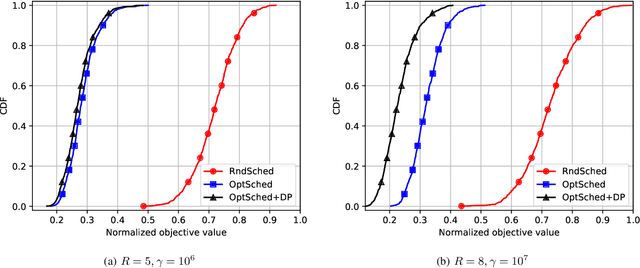
In this work, we consider a federated learning model in a wireless system with multiple base stations and inter-cell interference. We apply a differential private scheme to transmit information from users to their corresponding base station during the learning phase. We show the convergence behavior of the learning process by deriving an upper bound on its optimality gap. Furthermore, we define an optimization problem to reduce this upper bound and the total privacy leakage. To find the locally optimal solutions of this problem, we first propose an algorithm that schedules the resource blocks and users. We then extend this scheme to reduce the total privacy leakage by optimizing the differential privacy artificial noise. We apply the solutions of these two procedures as parameters of a federated learning system. In this setting, we assume that each user is equipped with a classifier. Moreover, the communication cells are assumed to have mostly fewer resource blocks than numbers of users. The simulation results show that our proposed scheduler improves the average accuracy of the predictions compared with a random scheduler. Furthermore, its extended version with noise optimizer significantly reduces the amount of privacy leakage.
Performance Optimization for Semantic Communications: An Attention-based Reinforcement Learning Approach
Aug 17, 2022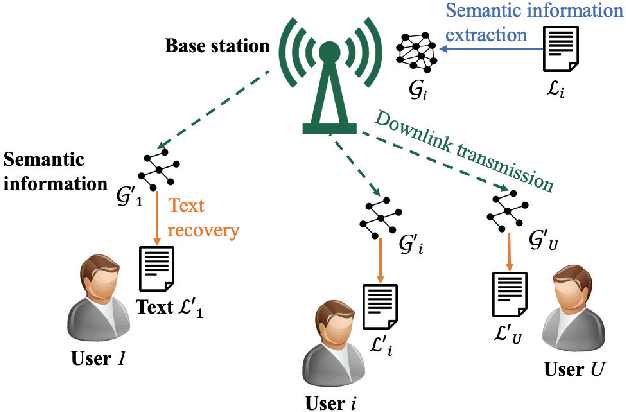
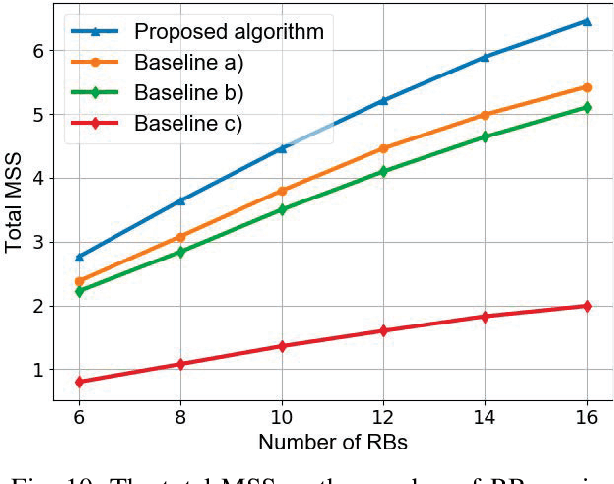
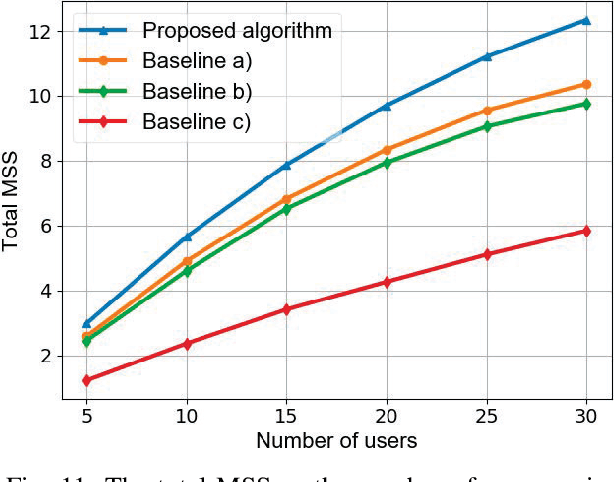
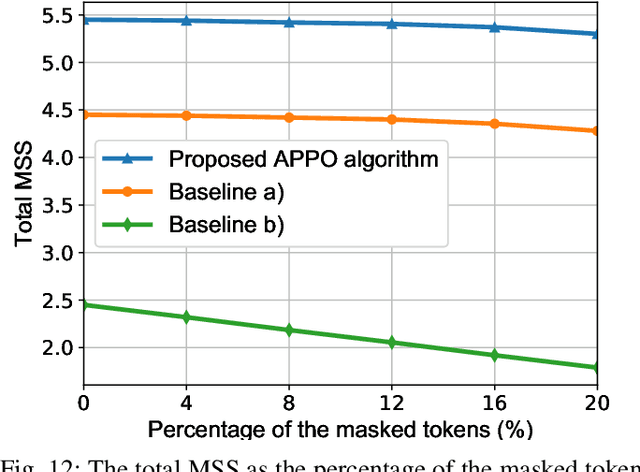
In this paper, a semantic communication framework is proposed for textual data transmission. In the studied model, a base station (BS) extracts the semantic information from textual data, and transmits it to each user. The semantic information is modeled by a knowledge graph (KG) that consists of a set of semantic triples. After receiving the semantic information, each user recovers the original text using a graph-to-text generation model. To measure the performance of the considered semantic communication framework, a metric of semantic similarity (MSS) that jointly captures the semantic accuracy and completeness of the recovered text is proposed. Due to wireless resource limitations, the BS may not be able to transmit the entire semantic information to each user and satisfy the transmission delay constraint. Hence, the BS must select an appropriate resource block for each user as well as determine and transmit part of the semantic information to the users. As such, we formulate an optimization problem whose goal is to maximize the total MSS by jointly optimizing the resource allocation policy and determining the partial semantic information to be transmitted. To solve this problem, a proximal-policy-optimization-based reinforcement learning (RL) algorithm integrated with an attention network is proposed. The proposed algorithm can evaluate the importance of each triple in the semantic information using an attention network and then, build a relationship between the importance distribution of the triples in the semantic information and the total MSS. Compared to traditional RL algorithms, the proposed algorithm can dynamically adjust its learning rate thus ensuring convergence to a locally optimal solution.
Beamforming Design for the Performance Optimization of Intelligent Reflecting Surface Assisted Multicast MIMO Networks
Aug 15, 2022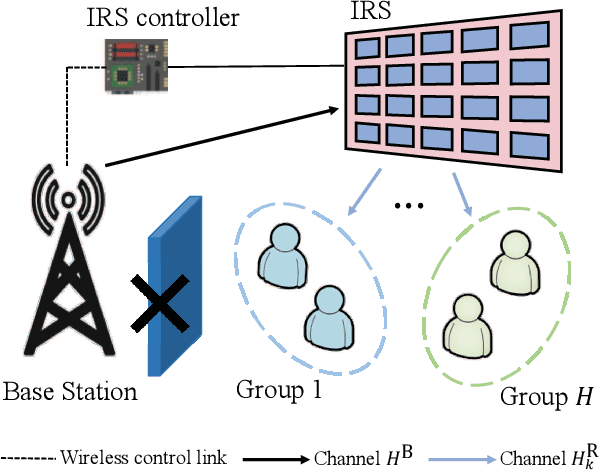
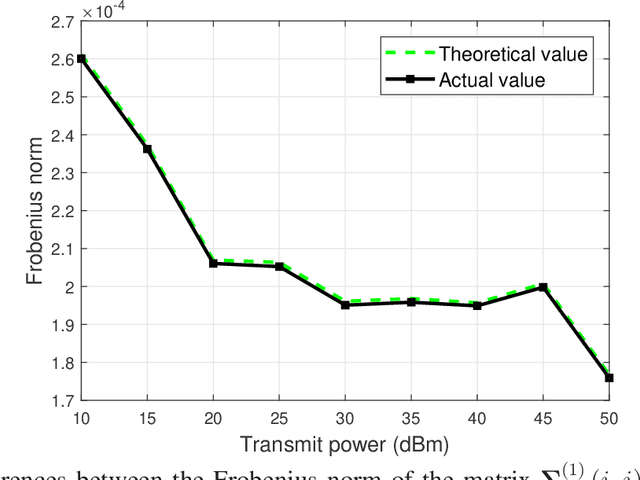
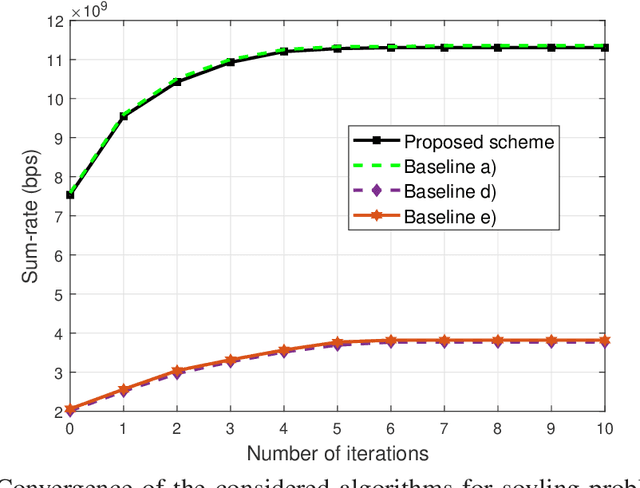
In this paper, the problem of maximizing the sum of data rates of all users in an intelligent reflecting surface (IRS)-assisted millimeter wave multicast multiple-input multiple-output communication system is studied. In the considered model, one IRS is deployed to assist the communication from a multiantenna base station (BS) to the multi-antenna users that are clustered into several groups. Our goal is to maximize the sum rate of all users by jointly optimizing the transmit beamforming matrices of the BS, the receive beamforming matrices of the users, and the phase shifts of the IRS. To solve this non-convex problem, we first use a block diagonalization method to represent the beamforming matrices of the BS and the users by the phase shifts of the IRS. Then, substituting the expressions of the beamforming matrices of the BS and the users, the original sum-rate maximization problem can be transformed into a problem that only needs to optimize the phase shifts of the IRS. To solve the transformed problem, a manifold method is used. Simulation results show that the proposed scheme can achieve up to 28.6% gain in terms of the sum rate of all users compared to the algorithm that optimizes the hybrid beamforming matrices of the BS and the users using our proposed scheme and randomly determines the phase shifts of the IRS.