 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Equilibria via Incentives: Simultaneous Design-and-Play Finds Global Optima
Oct 12, 2021
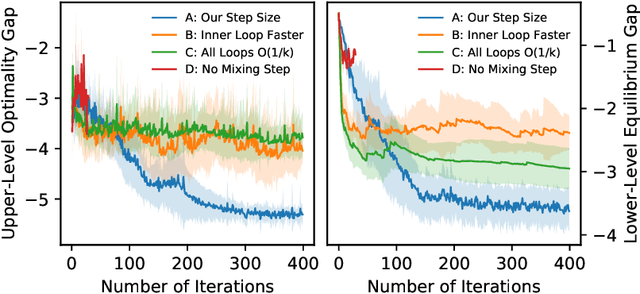
To regulate a social system comprised of self-interested agents, economic incentives (e.g., taxes, tolls, and subsidies) are often required to induce a desirable outcome. This incentive design problem naturally possesses a bi-level structure, in which an upper-level "designer" modifies the payoffs of the agents with incentives while anticipating the response of the agents at the lower level, who play a non-cooperative game that converges to an equilibrium. The existing bi-level optimization algorithms developed in machine learning raise a dilemma when applied to this problem: anticipating how incentives affect the agents at equilibrium requires solving the equilibrium problem repeatedly, which is computationally inefficient; bypassing the time-consuming step of equilibrium-finding can reduce the computational cost, but may lead the designer to a sub-optimal solution. To address such a dilemma, we propose a method that tackles the designer's and agents' problems simultaneously in a single loop. In particular, at each iteration, both the designer and the agents only move one step based on the first-order information. In the proposed scheme, although the designer does not solve the equilibrium problem repeatedly, it can anticipate the overall influence of the incentives on the agents, which guarantees optimality. We prove that the algorithm converges to the global optima at a sublinear rate for a broad class of games.
Learning to Coordinate in Multi-Agent Systems: A Coordinated Actor-Critic Algorithm and Finite-Time Guarantees
Oct 11, 2021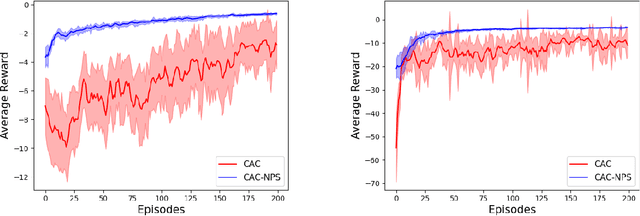
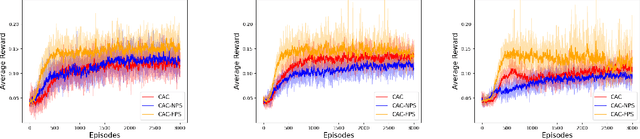
Multi-agent reinforcement learning (MARL) has attracted much research attention recently. However, unlike its single-agent counterpart, many theoretical and algorithmic aspects of MARL have not been well-understood. In this paper, we study the emergence of coordinated behavior by autonomous agents using an actor-critic (AC) algorithm. Specifically, we propose and analyze a class of coordinated actor-critic algorithms (CAC) in which individually parametrized policies have a {\it shared} part (which is jointly optimized among all agents) and a {\it personalized} part (which is only locally optimized). Such kind of {\it partially personalized} policy allows agents to learn to coordinate by leveraging peers' past experience and adapt to individual tasks. The flexibility in our design allows the proposed MARL-CAC algorithm to be used in a {\it fully decentralized} setting, where the agents can only communicate with their neighbors, as well as a {\it federated} setting, where the agents occasionally communicate with a server while optimizing their (partially personalized) local models. Theoretically, we show that under some standard regularity assumptions, the proposed MARL-CAC algorithm requires $\mathcal{O}(\epsilon^{-\frac{5}{2}})$ samples to achieve an $\epsilon$-stationary solution (defined as the solution whose squared norm of the gradient of the objective function is less than $\epsilon$). To the best of our knowledge, this work provides the first finite-sample guarantee for decentralized AC algorithm with partially personalized policies.
Understanding Clipping for Federated Learning: Convergence and Client-Level Differential Privacy
Jun 25, 2021



Providing privacy protection has been one of the primary motivations of Federated Learning (FL). Recently, there has been a line of work on incorporating the formal privacy notion of differential privacy with FL. To guarantee the client-level differential privacy in FL algorithms, the clients' transmitted model updates have to be clipped before adding privacy noise. Such clipping operation is substantially different from its counterpart of gradient clipping in the centralized differentially private SGD and has not been well-understood. In this paper, we first empirically demonstrate that the clipped FedAvg can perform surprisingly well even with substantial data heterogeneity when training neural networks, which is partly because the clients' updates become similar for several popular deep architectures. Based on this key observation, we provide the convergence analysis of a differential private (DP) FedAvg algorithm and highlight the relationship between clipping bias and the distribution of the clients' updates. To the best of our knowledge, this is the first work that rigorously investigates theoretical and empirical issues regarding the clipping operation in FL algorithms.
STEM: A Stochastic Two-Sided Momentum Algorithm Achieving Near-Optimal Sample and Communication Complexities for Federated Learning
Jun 19, 2021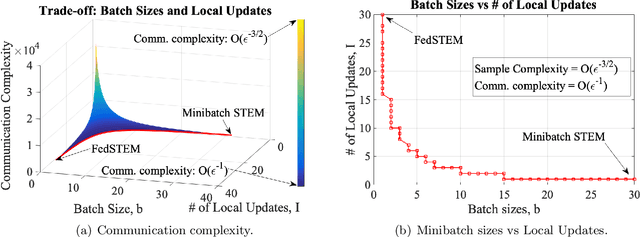
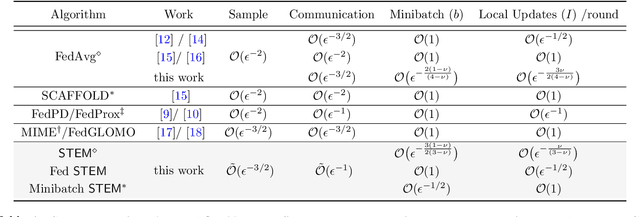
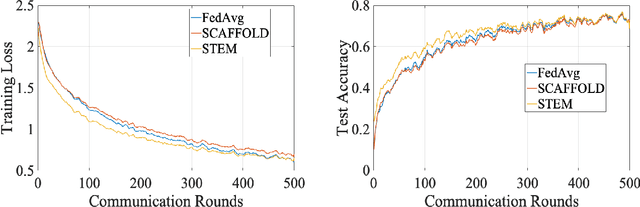
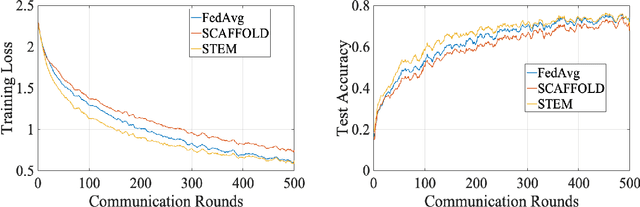
Federated Learning (FL) refers to the paradigm where multiple worker nodes (WNs) build a joint model by using local data. Despite extensive research, for a generic non-convex FL problem, it is not clear, how to choose the WNs' and the server's update directions, the minibatch sizes, and the local update frequency, so that the WNs use the minimum number of samples and communication rounds to achieve the desired solution. This work addresses the above question and considers a class of stochastic algorithms where the WNs perform a few local updates before communication. We show that when both the WN's and the server's directions are chosen based on a stochastic momentum estimator, the algorithm requires $\tilde{\mathcal{O}}(\epsilon^{-3/2})$ samples and $\tilde{\mathcal{O}}(\epsilon^{-1})$ communication rounds to compute an $\epsilon$-stationary solution. To the best of our knowledge, this is the first FL algorithm that achieves such {\it near-optimal} sample and communication complexities simultaneously. Further, we show that there is a trade-off curve between local update frequencies and local minibatch sizes, on which the above sample and communication complexities can be maintained. Finally, we show that for the classical FedAvg (a.k.a. Local SGD, which is a momentum-less special case of the STEM), a similar trade-off curve exists, albeit with worse sample and communication complexities. Our insights on this trade-off provides guidelines for choosing the four important design elements for FL algorithms, the update frequency, directions, and minibatch sizes to achieve the best performance.
Learning to Continuously Optimize Wireless Resource in a Dynamic Environment: A Bilevel Optimization Perspective
May 03, 2021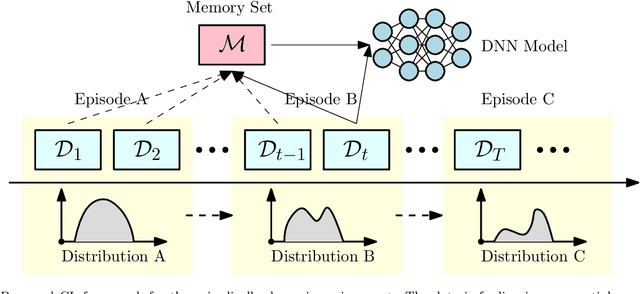
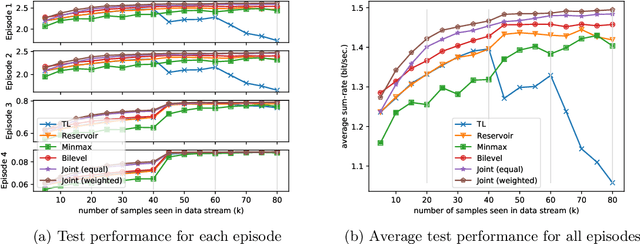
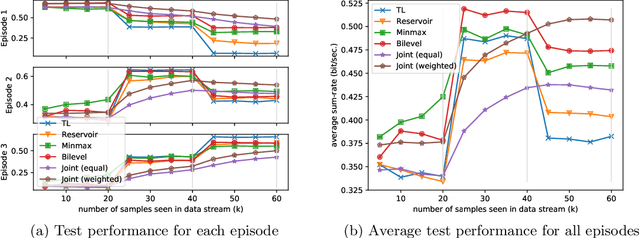
There has been a growing interest in developing data-driven, and in particular deep neural network (DNN) based methods for modern communication tasks. For a few popular tasks such as power control, beamforming, and MIMO detection, these methods achieve state-of-the-art performance while requiring less computational efforts, less resources for acquiring channel state information (CSI), etc. However, it is often challenging for these approaches to learn in a dynamic environment. This work develops a new approach that enables data-driven methods to continuously learn and optimize resource allocation strategies in a dynamic environment. Specifically, we consider an ``episodically dynamic" setting where the environment statistics change in ``episodes", and in each episode the environment is stationary. We propose to build the notion of continual learning (CL) into wireless system design, so that the learning model can incrementally adapt to the new episodes, {\it without forgetting} knowledge learned from the previous episodes. Our design is based on a novel bilevel optimization formulation which ensures certain ``fairness" across different data samples. We demonstrate the effectiveness of the CL approach by integrating it with two popular DNN based models for power control and beamforming, respectively, and testing using both synthetic and ray-tracing based data sets. These numerical results show that the proposed CL approach is not only able to adapt to the new scenarios quickly and seamlessly, but importantly, it also maintains high performance over the previously encountered scenarios as well.
Deep Spectrum Cartography: Completing Radio Map Tensors Using Learned Neural Models
May 01, 2021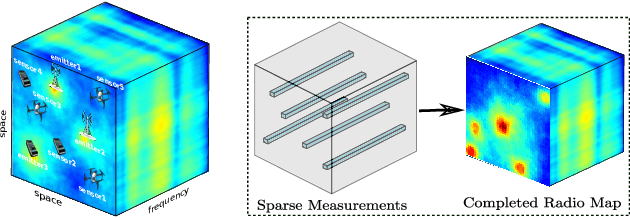
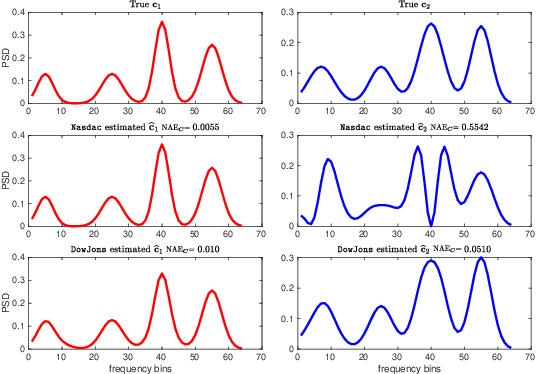
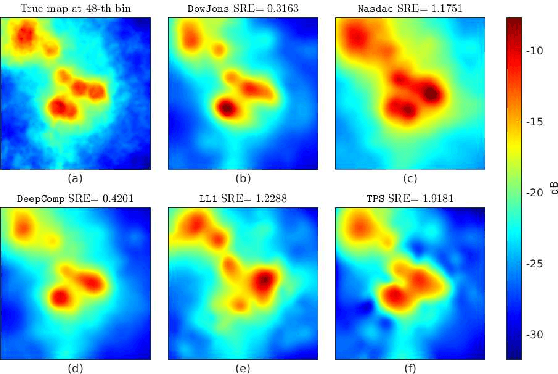
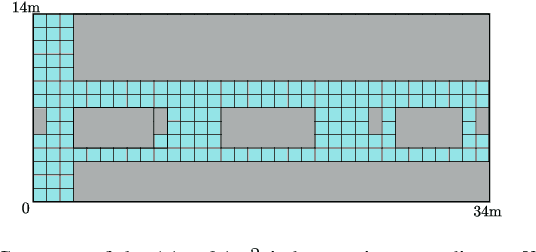
The spectrum cartography (SC) technique constructs multi-domain (e.g., frequency, space, and time) radio frequency (RF) maps from limited measurements, which can be viewed as an ill-posed tensor completion problem. Model-based cartography techniques often rely on handcrafted priors (e.g., sparsity, smoothness and low-rank structures) for the completion task. Such priors may be inadequate to capture the essence of complex wireless environments -- especially when severe shadowing happens. To circumvent such challenges, offline-trained deep neural models of radio maps were considered for SC, as deep neural networks (DNNs) are able to "learn" intricate underlying structures from data. However, such deep learning (DL)-based SC approaches encounter serious challenges in both off-line model learning (training) and completion (generalization), possibly because the latent state space for generating the radio maps is prohibitively large. In this work, an emitter radio map disaggregation-based approach is proposed, under which only individual emitters' radio maps are modeled by DNNs. This way, the learning and generalization challenges can both be substantially alleviated. Using the learned DNNs, a fast nonnegative matrix factorization-based two-stage SC method and a performance-enhanced iterative optimization algorithm are proposed. Theoretical aspects -- such as recoverability of the radio tensor, sample complexity, and noise robustness -- under the proposed framework are characterized, and such theoretical properties have been elusive in the context of DL-based radio tensor completion. Experiments using synthetic and real-data from indoor and heavily shadowed environments are employed to showcase the effectiveness of the proposed methods.
Stochastic Mirror Descent for Low-Rank Tensor Decomposition Under Non-Euclidean Losses
Apr 29, 2021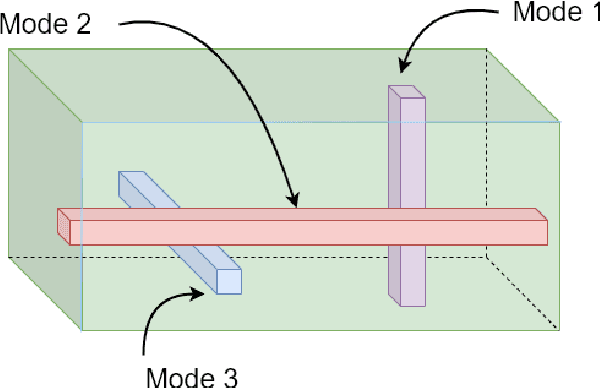
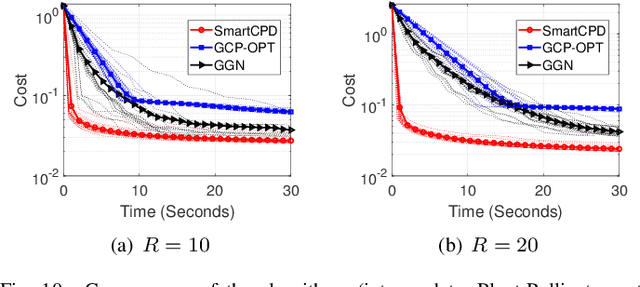
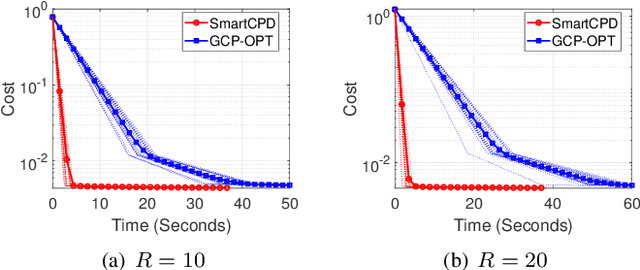
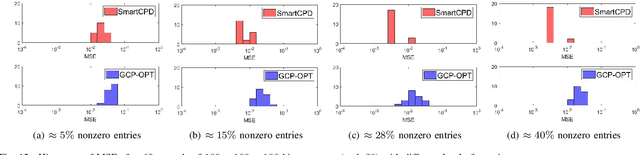
This work considers low-rank canonical polyadic decomposition (CPD) under a class of non-Euclidean loss functions that frequently arise in statistical machine learning and signal processing. These loss functions are often used for certain types of tensor data, e.g., count and binary tensors, where the least squares loss is considered unnatural.Compared to the least squares loss, the non-Euclidean losses are generally more challenging to handle. Non-Euclidean CPD has attracted considerable interests and a number of prior works exist. However, pressing computational and theoretical challenges, such as scalability and convergence issues, still remain. This work offers a unified stochastic algorithmic framework for large-scale CPD decomposition under a variety of non-Euclidean loss functions. Our key contribution lies in a tensor fiber sampling strategy-based flexible stochastic mirror descent framework. Leveraging the sampling scheme and the multilinear algebraic structure of low-rank tensors, the proposed lightweight algorithm ensures global convergence to a stationary point under reasonable conditions. Numerical results show that our framework attains promising non-Euclidean CPD performance. The proposed framework also exhibits substantial computational savings compared to state-of-the-art methods.
On Instabilities of Conventional Multi-Coil MRI Reconstruction to Small Adverserial Perturbations
Feb 25, 2021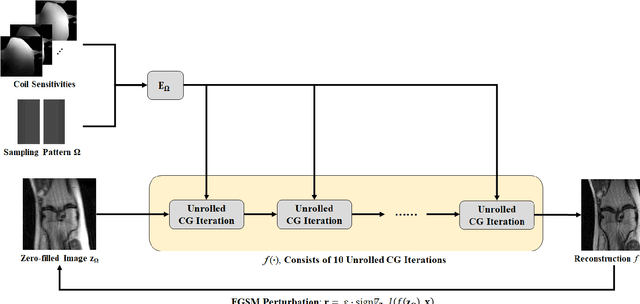
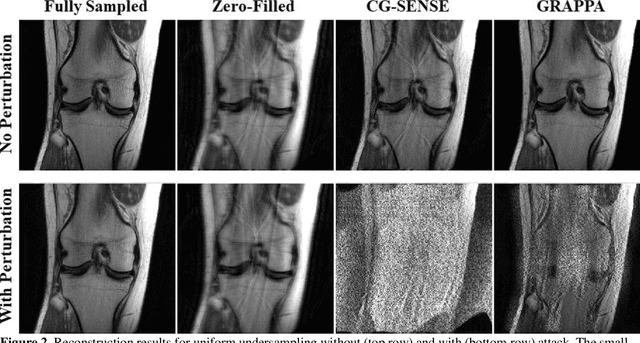
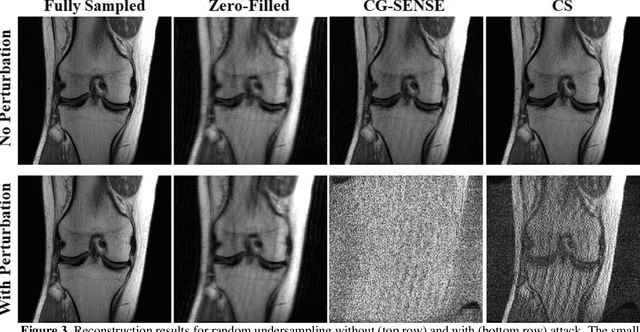
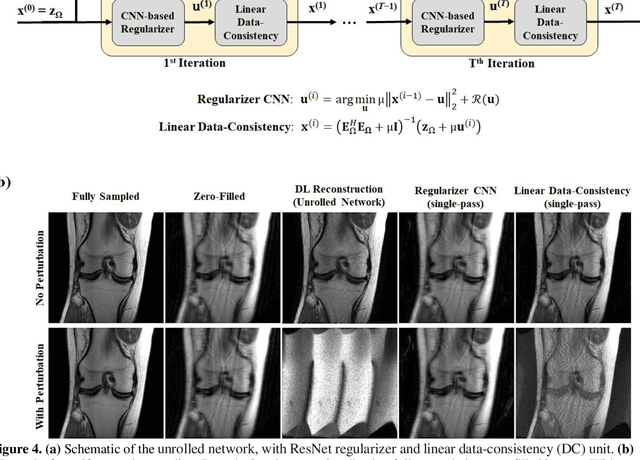
Although deep learning (DL) has received much attention in accelerated MRI, recent studies suggest small perturbations may lead to instabilities in DL-based reconstructions, leading to concern for their clinical application. However, these works focus on single-coil acquisitions, which is not practical. We investigate instabilities caused by small adversarial attacks for multi-coil acquisitions. Our results suggest that, parallel imaging and multi-coil CS exhibit considerable instabilities against small adversarial perturbations.
A Momentum-Assisted Single-Timescale Stochastic Approximation Algorithm for Bilevel Optimization
Feb 15, 2021
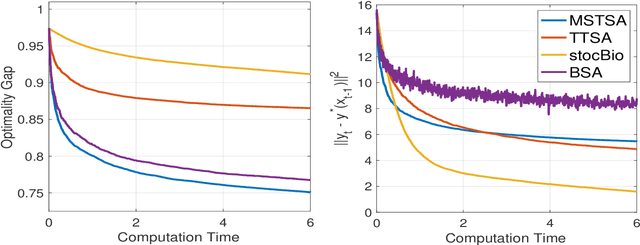
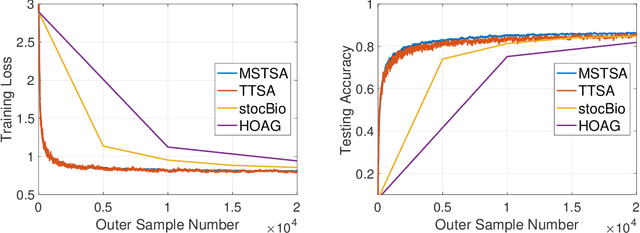

This paper proposes a new algorithm -- the Momentum-assisted Single-timescale Stochastic Approximation (MSTSA) -- for tackling unconstrained bilevel optimization problems. We focus on bilevel problems where the lower level subproblem is strongly-convex. Unlike prior works which rely on two timescale or double loop techniques that track the optimal solution to the lower level subproblem, we design a stochastic momentum assisted gradient estimator for the upper level subproblem's updates. The latter allows us to gradually control the error in stochastic gradient updates due to inaccurate solution to the lower level subproblem. We show that if the upper objective function is smooth but possibly non-convex (resp. strongly-convex), MSTSA requires $\mathcal{O}(\epsilon^{-2})$ (resp. $\mathcal{O}(\epsilon^{-1})$) iterations (each using constant samples) to find an $\epsilon$-stationary (resp. $\epsilon$-optimal) solution. This achieves the best-known guarantees for stochastic bilevel problems. We validate our theoretical results by showing the efficiency of the MSTSA algorithm on hyperparameter optimization and data hyper-cleaning problems.
Decentralized Riemannian Gradient Descent on the Stiefel Manifold
Feb 14, 2021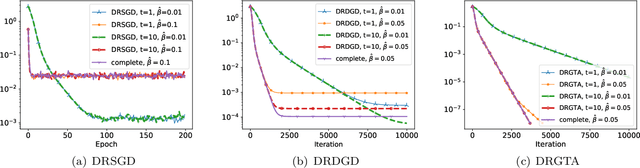
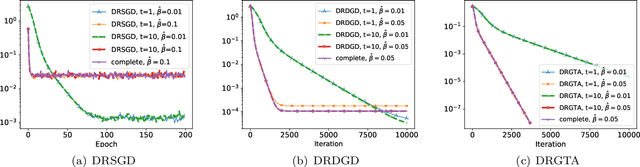
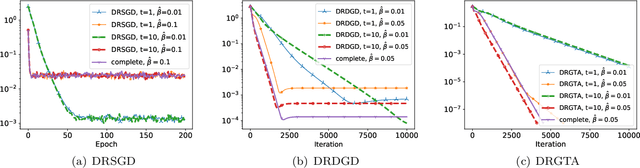
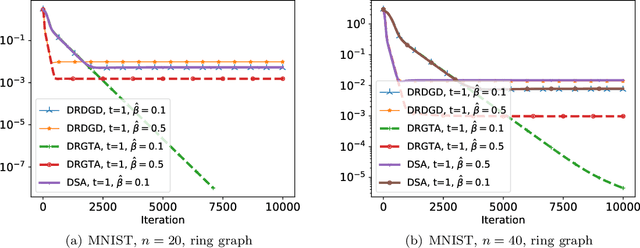
We consider a distributed non-convex optimization where a network of agents aims at minimizing a global function over the Stiefel manifold. The global function is represented as a finite sum of smooth local functions, where each local function is associated with one agent and agents communicate with each other over an undirected connected graph. The problem is non-convex as local functions are possibly non-convex (but smooth) and the Steifel manifold is a non-convex set. We present a decentralized Riemannian stochastic gradient method (DRSGD) with the convergence rate of $\mathcal{O}(1/\sqrt{K})$ to a stationary point. To have exact convergence with constant stepsize, we also propose a decentralized Riemannian gradient tracking algorithm (DRGTA) with the convergence rate of $\mathcal{O}(1/K)$ to a stationary point. We use multi-step consensus to preserve the iteration in the local (consensus) region. DRGTA is the first decentralized algorithm with exact convergence for distributed optimization on Stiefel manifold.