 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdMLP: Weakly-Supervised Crowd Counting via Multi-Granularity MLP
Mar 15, 2022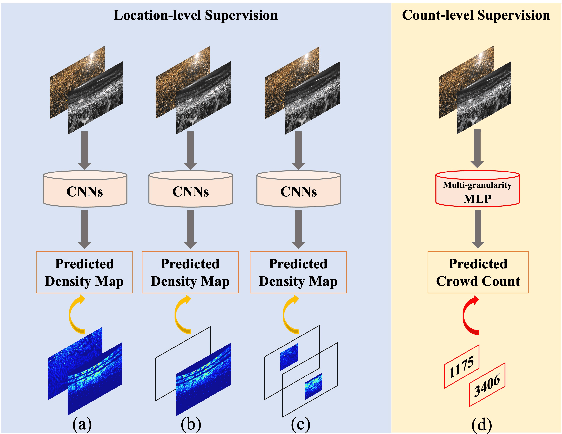
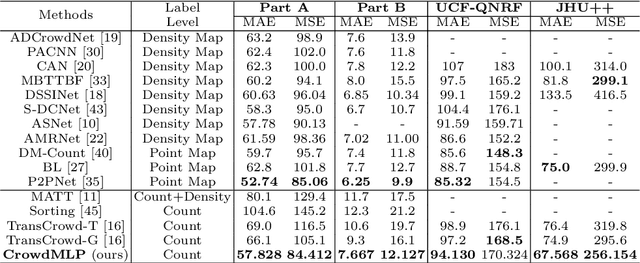
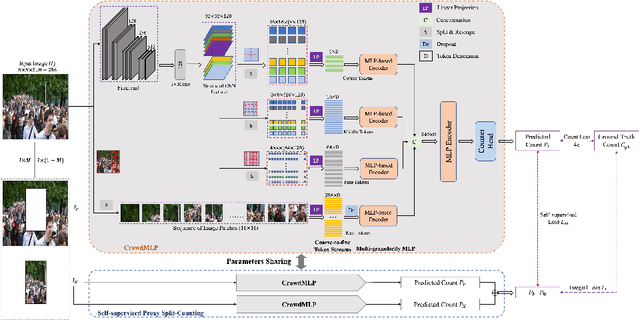
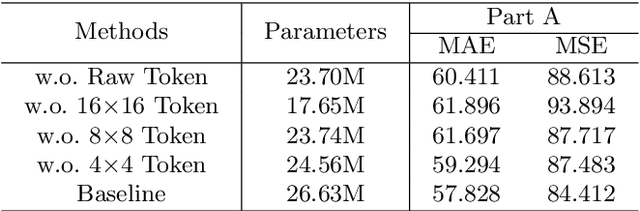
Existing state-of-the-art crowd counting algorithms rely excessively on location-level annotations, which are burdensome to acquire. When only count-level (weak) supervisory signals are available, it is arduous and error-prone to regress total counts due to the lack of explicit spatial constraints. To address this issue, a novel and efficient counter (referred to as CrowdMLP) is presented, which probes into modelling global dependencies of embeddings and regressing total counts by devising a multi-granularity MLP regressor. In specific, a locally-focused pre-trained frontend is cascaded to extract crude feature maps with intrinsic spatial cues, which prevent the model from collapsing into trivial outcomes. The crude embeddings, along with raw crowd scenes, are tokenized at different granularity levels. The multi-granularity MLP then proceeds to mix tokens at the dimensions of cardinality, channel, and spatial for mining global information. An effective proxy task, namely Split-Counting, is also proposed to evade the barrier of limited samples and the shortage of spatial hints in a self-supervised manner. Extensive experiments demonstrate that CrowdMLP significantly outperforms existing weakly-supervised counting algorithms and performs on par with state-of-the-art location-level supervised approaches.
3D Pose Estimation and Future Motion Prediction from 2D Images
Nov 26, 2021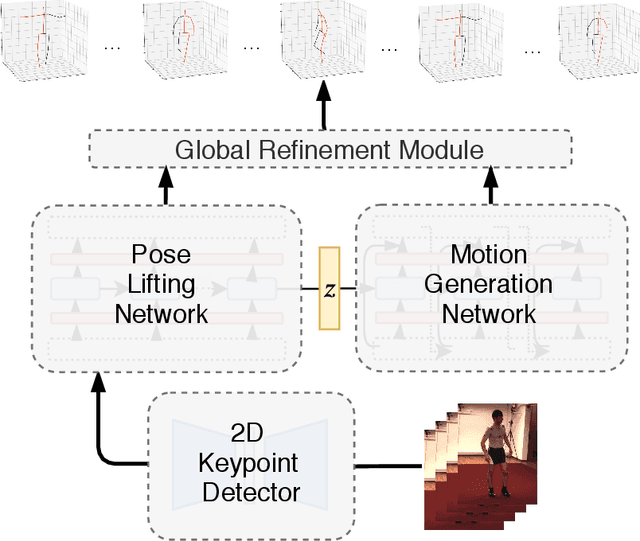
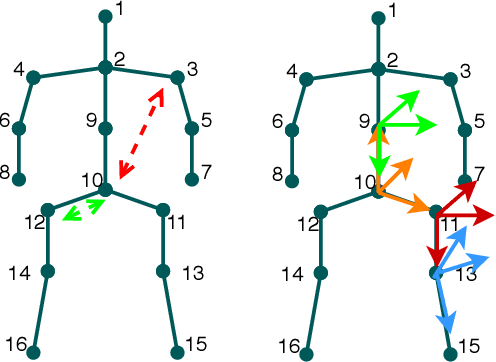

This paper considers to jointly tackle the highly correlated tasks of estimating 3D human body poses and predicting future 3D motions from RGB image sequences. Based on Lie algebra pose representation, a novel self-projection mechanism is proposed that naturally preserves human motion kinematics. This is further facilitated by a sequence-to-sequence multi-task architecture based on an encoder-decoder topology, which enables us to tap into the common ground shared by both tasks. Finally, a global refinement module is proposed to boost the performance of our framework. The effectiveness of our approach, called PoseMoNet, is demonstrated by ablation tests and empirical evaluations on Human3.6M and HumanEva-I benchmark, where competitive performance is obtained comparing to the state-of-the-arts.
Action2video: Generating Videos of Human 3D Actions
Nov 12, 2021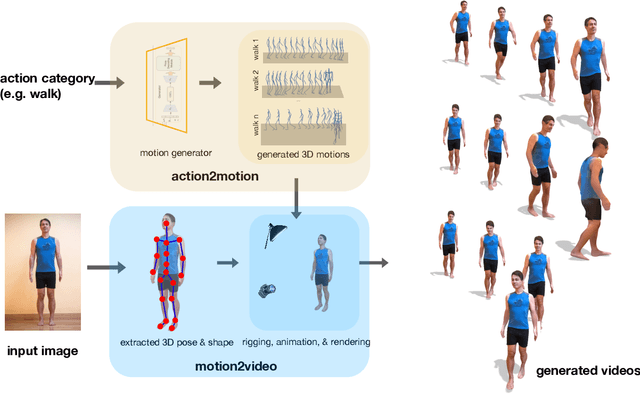
We aim to tackle the interesting yet challenging problem of generating videos of diverse and natural human motions from prescribed action categories. The key issue lies in the ability to synthesize multiple distinct motion sequences that are realistic in their visual appearances. It is achieved in this paper by a two-step process that maintains internal 3D pose and shape representations, action2motion and motion2video. Action2motion stochastically generates plausible 3D pose sequences of a prescribed action category, which are processed and rendered by motion2video to form 2D videos. Specifically, the Lie algebraic theory is engaged in representing natural human motions following the physical law of human kinematics; a temporal variational auto-encoder (VAE) is developed that encourages diversity of output motions. Moreover, given an additional input image of a clothed human character, an entire pipeline is proposed to extract his/her 3D detailed shape, and to render in videos the plausible motions from different views. This is realized by improving existing methods to extract 3D human shapes and textures from single 2D images, rigging, animating, and rendering to form 2D videos of human motions. It also necessitates the curation and reannotation of 3D human motion datasets for training purpose. Thorough empirical experiments including ablation study, qualitative and quantitative evaluations manifest the applicability of our approach, and demonstrate its competitiveness in addressing related tasks, where components of our approach are compared favorably to the state-of-the-arts.
Human Pose and Shape Estimation from Single Polarization Images
Aug 15, 2021



This paper focuses on a new problem of estimating human pose and shape from single polarization images. Polarization camera is known to be able to capture the polarization of reflected lights that preserves rich geometric cues of an object surface. Inspired by the recent applications in surface normal reconstruction from polarization images, in this paper, we attempt to estimate human pose and shape from single polarization images by leveraging the polarization-induced geometric cues. A dedicated two-stage pipeline is proposed: given a single polarization image, stage one (Polar2Normal) focuses on the fine detailed human body surface normal estimation; stage two (Polar2Shape) then reconstructs clothed human shape from the polarization image and the estimated surface normal. To empirically validate our approach, a dedicated dataset (PHSPD) is constructed, consisting of over 500K frames with accurate pose and shape annotations. Empirical evaluations on this real-world dataset as well as a synthetic dataset, SURREAL, demonstrate the effectiveness of our approach. It suggests polarization camera as a promising alternative to the more conventional RGB camera for human pose and shape estimation.
EventHPE: Event-based 3D Human Pose and Shape Estimation
Aug 15, 2021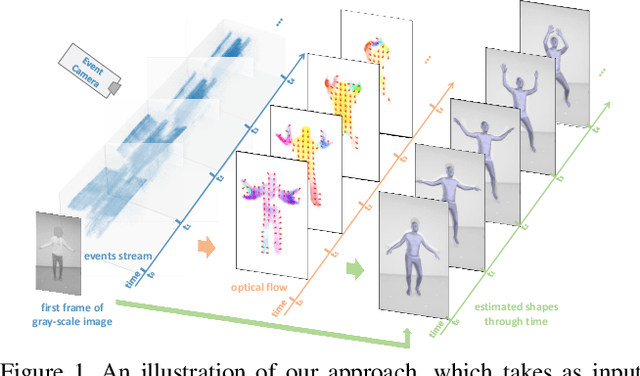

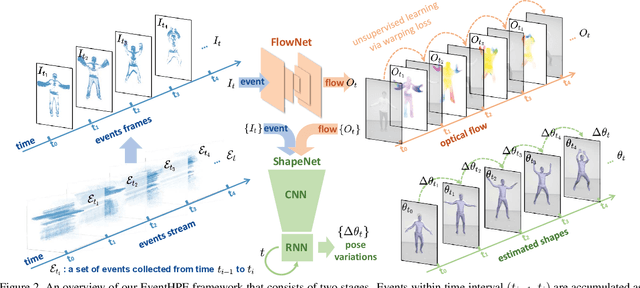
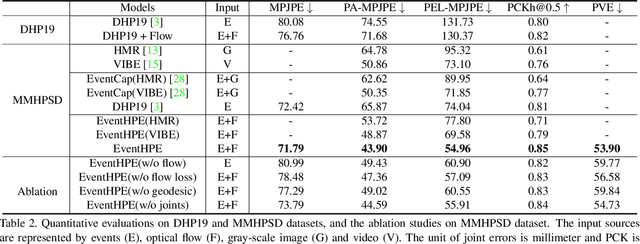
Event camera is an emerging imaging sensor for capturing dynamics of moving objects as events, which motivates our work in estimating 3D human pose and shape from the event signals. Events, on the other hand, have their unique challenges: rather than capturing static body postures, the event signals are best at capturing local motions. This leads us to propose a two-stage deep learning approach, called EventHPE. The first-stage, FlowNet, is trained by unsupervised learning to infer optical flow from events. Both events and optical flow are closely related to human body dynamics, which are fed as input to the ShapeNet in the second stage, to estimate 3D human shapes. To mitigate the discrepancy between image-based flow (optical flow) and shape-based flow (vertices movement of human body shape), a novel flow coherence loss is introduced by exploiting the fact that both flows are originated from the identical human motion. An in-house event-based 3D human dataset is curated that comes with 3D pose and shape annotations, which is by far the largest one to our knowledge. Empirical evaluations on DHP19 dataset and our in-house dataset demonstrate the effectiveness of our approach.
Object Wake-up: 3-D Object Reconstruction, Animation, and in-situ Rendering from a Single Image
Aug 05, 2021

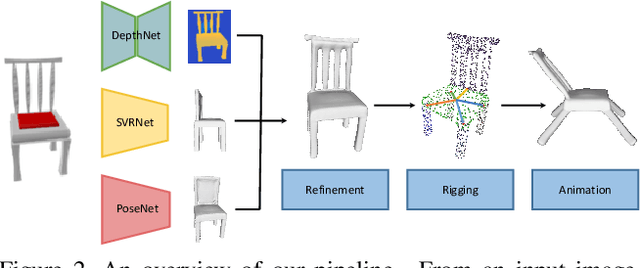
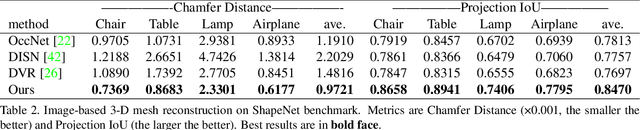
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.
Unsupervised 3D Human Mesh Recovery from Noisy Point Clouds
Jul 15, 2021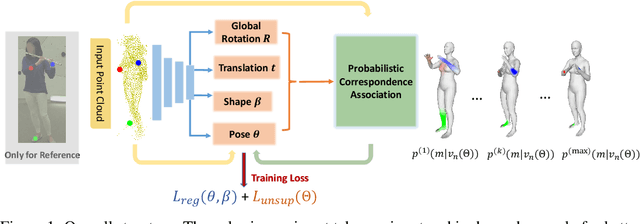
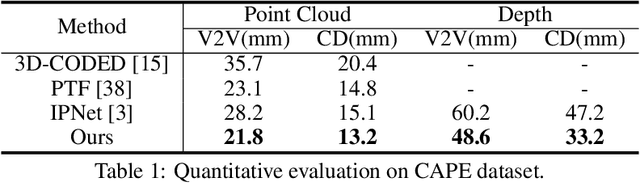
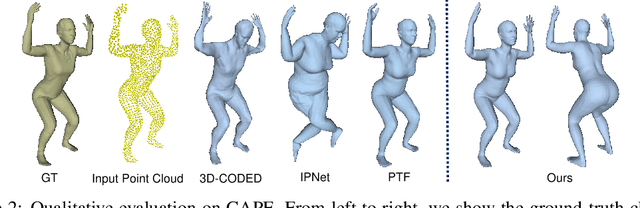
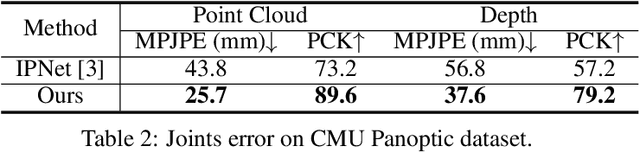
This paper presents a novel unsupervised approach to reconstruct human shape and pose from noisy point cloud. Traditional approaches search for correspondences and conduct model fitting iteratively where a good initialization is critical. Relying on large amount of dataset with ground-truth annotations, recent learning-based approaches predict correspondences for every vertice on the point cloud; Chamfer distance is usually used to minimize the distance between a deformed template model and the input point cloud. However, Chamfer distance is quite sensitive to noise and outliers, thus could be unreliable to assign correspondences. To address these issues, we model the probability distribution of the input point cloud as generated from a parametric human model under a Gaussian Mixture Model. Instead of explicitly aligning correspondences, we treat the process of correspondence search as an implicit probabilistic association by updating the posterior probability of the template model given the input. A novel unsupervised loss is further derived that penalizes the discrepancy between the deformed template and the input point cloud conditioned on the posterior probability. Our approach is very flexible, which works with both complete point cloud and incomplete ones including even a single depth image as input. Our network is trained from scratch with no need to warm-up the network with supervised data. Compared to previous unsupervised methods, our method shows the capability to deal with substantial noise and outliers. Extensive experiments conducted on various public synthetic datasets as well as a very noisy real dataset (i.e. CMU Panoptic) demonstrate the superior performance of our approach over the state-of-the-art methods. Code can be found \url{https://github.com/wangsen1312/unsupervised3dhuman.git}
STNet: Scale Tree Network with Multi-level Auxiliator for Crowd Counting
Dec 18, 2020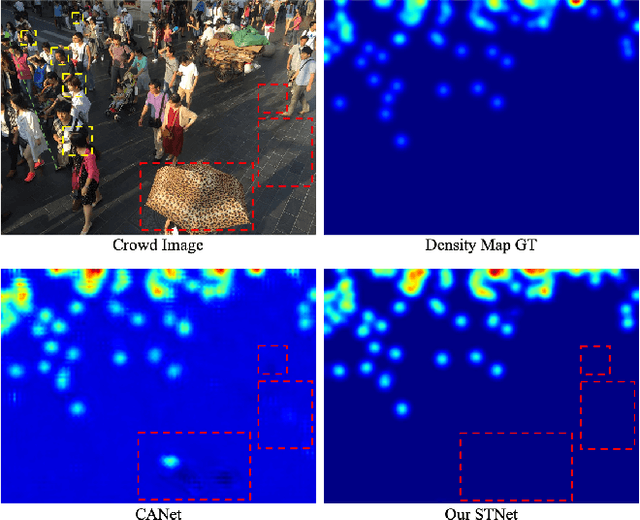
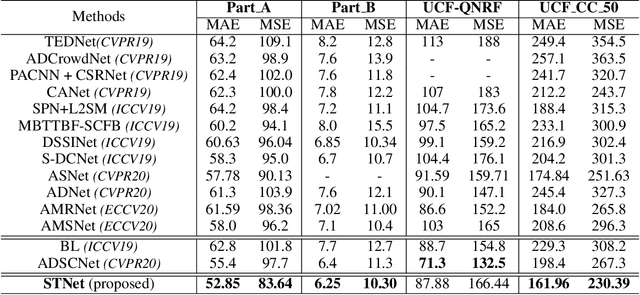
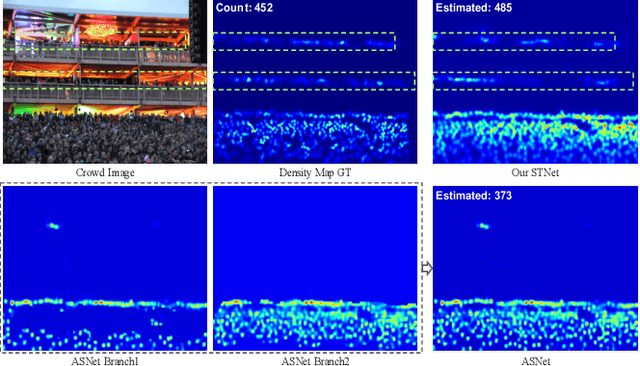
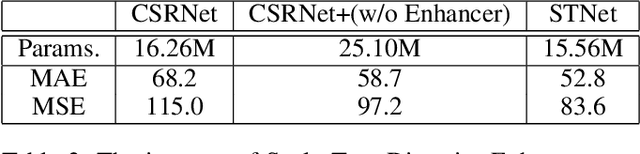
Crowd counting remains a challenging task because the presence of drastic scale variation, density inconsistency, and complex background can seriously degrade the counting accuracy. To battle the ingrained issue of accuracy degradation, we propose a novel and powerful network called Scale Tree Network (STNet) for accurate crowd counting. STNet consists of two key components: a Scale-Tree Diversity Enhancer and a Semi-supervised Multi-level Auxiliator. Specifically, the Diversity Enhancer is designed to enrich scale diversity, which alleviates limitations of existing methods caused by insufficient level of scales. A novel tree structure is adopted to hierarchically parse coarse-to-fine crowd regions. Furthermore, a simple yet effective Multi-level Auxiliator is presented to aid in exploiting generalisable shared characteristics at multiple levels, allowing more accurate pixel-wise background cognition. The overall STNet is trained in an end-to-end manner, without the needs for manually tuning loss weights between the main and the auxiliary tasks. Extensive experiments on four challenging crowd datasets demonstrate the superiority of the proposed method.
TAP-Net: Transport-and-Pack using Reinforcement Learning
Sep 03, 2020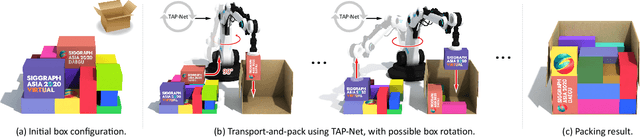
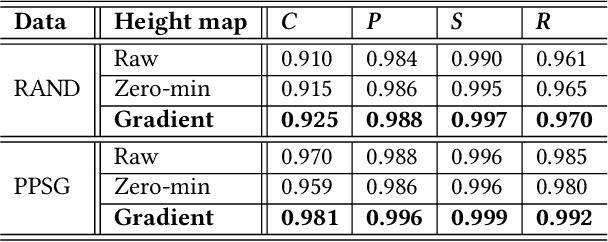
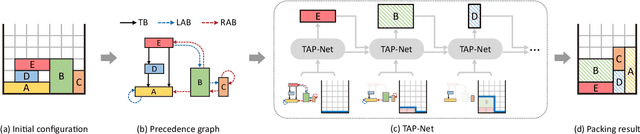
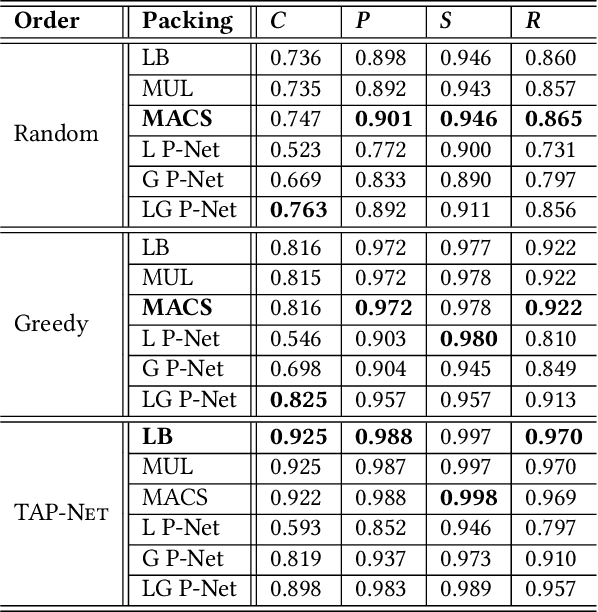
We introduce the transport-and-pack(TAP) problem, a frequently encountered instance of real-world packing, and develop a neural optimization solution based on reinforcement learning. Given an initial spatial configuration of boxes, we seek an efficient method to iteratively transport and pack the boxes compactly into a target container. Due to obstruction and accessibility constraints, our problem has to add a new search dimension, i.e., finding an optimal transport sequence, to the already immense search space for packing alone. Using a learning-based approach, a trained network can learn and encode solution patterns to guide the solution of new problem instances instead of executing an expensive online search. In our work, we represent the transport constraints using a precedence graph and train a neural network, coined TAP-Net, using reinforcement learning to reward efficient and stable packing. The network is built on an encoder-decoder architecture, where the encoder employs convolution layers to encode the box geometry and precedence graph and the decoder is a recurrent neural network (RNN) which inputs the current encoder output, as well as the current box packing state of the target container, and outputs the next box to pack, as well as its orientation. We train our network on randomly generated initial box configurations, without supervision, via policy gradients to learn optimal TAP policies to maximize packing efficiency and stability. We demonstrate the performance of TAP-Net on a variety of examples, evaluating the network through ablation studies and comparisons to baselines and alternative network designs. We also show that our network generalizes well to larger problem instances, when trained on small-sized inputs.
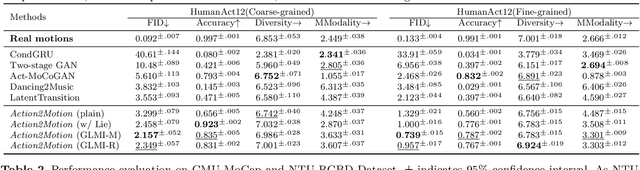
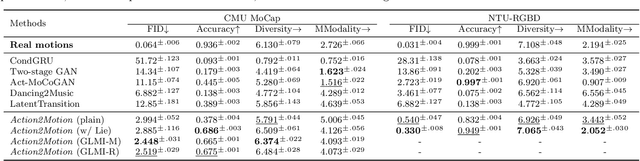
Action2Motion: Conditioned Generation of 3D Human Motions
Jul 30, 2020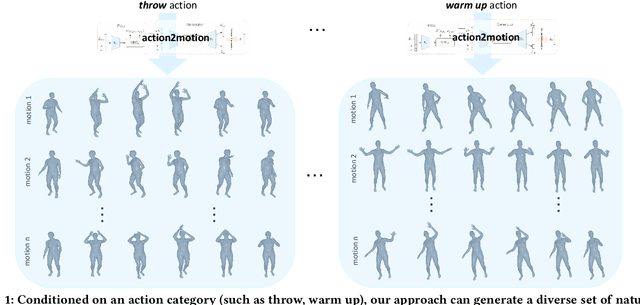
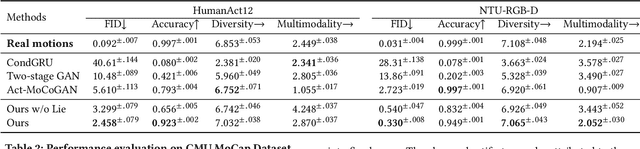
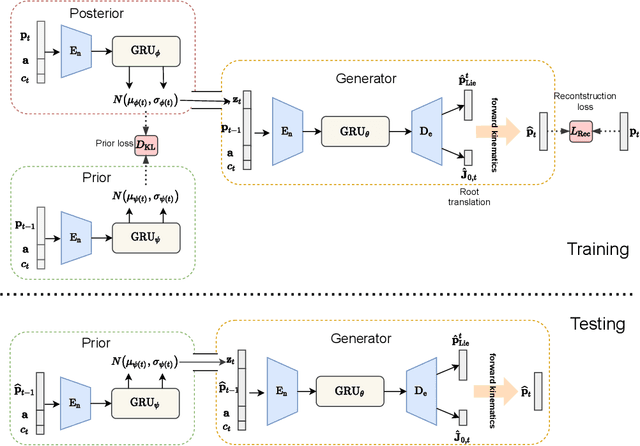
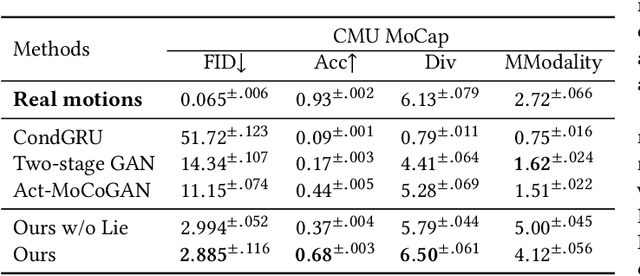
Action recognition is a relatively established task, where givenan input sequence of human motion, the goal is to predict its ac-tion category. This paper, on the other hand, considers a relativelynew problem, which could be thought of as an inverse of actionrecognition: given a prescribed action type, we aim to generateplausible human motion sequences in 3D. Importantly, the set ofgenerated motions are expected to maintain itsdiversityto be ableto explore the entire action-conditioned motion space; meanwhile,each sampled sequence faithfully resembles anaturalhuman bodyarticulation dynamics. Motivated by these objectives, we followthe physics law of human kinematics by adopting the Lie Algebratheory to represent thenaturalhuman motions; we also propose atemporal Variational Auto-Encoder (VAE) that encourages adiversesampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments overthree distinct human motion datasets (including ours) demonstratethe effectiveness of our approach.